



【转】你必须知道的EF知识和经验
注意:以下内容如果没有特别申明,默认使用的EF6.0版本,code first模式。
推荐MiniProfiler插件
工欲善其事,必先利其器。
我们使用EF和在很大程度提高了开发速度,不过随之带来的是很多性能低下的写法和生成不太高效的sql。
虽然我们可以使用SQL Server Profiler来监控执行的sql,不过个人觉得实属麻烦,每次需要打开、过滤、清除、关闭。
在这里强烈推荐一个插件MiniProfiler。实时监控页面请求对应执行的sql语句、执行时间。简单、方便、针对性强。
如图:(具体使用和介绍请移步)
数据准备
新建实体:Score(成绩分数表)、Student(学生表)、Teacher(老师表)
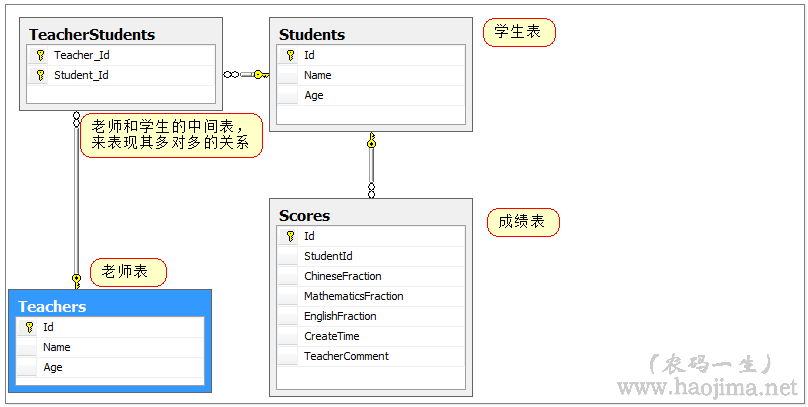
后面会给出demo代码下载链接
foreach循环的陷进
1.关于延迟加载

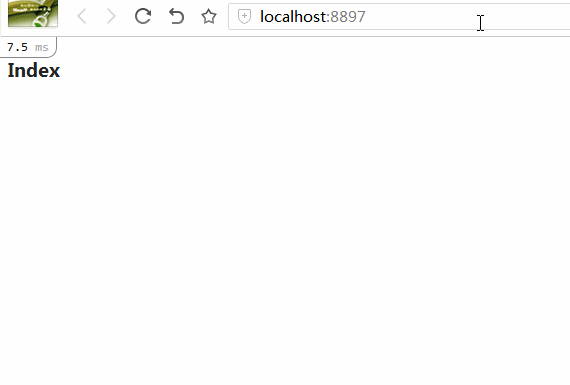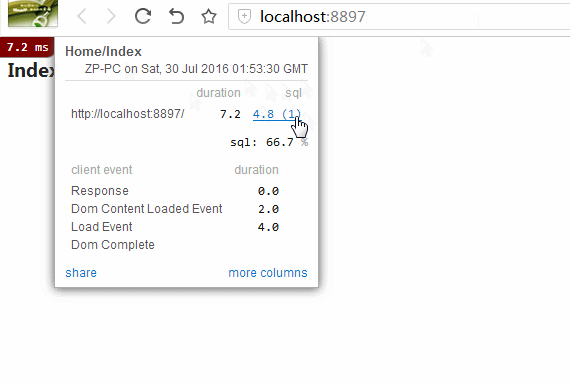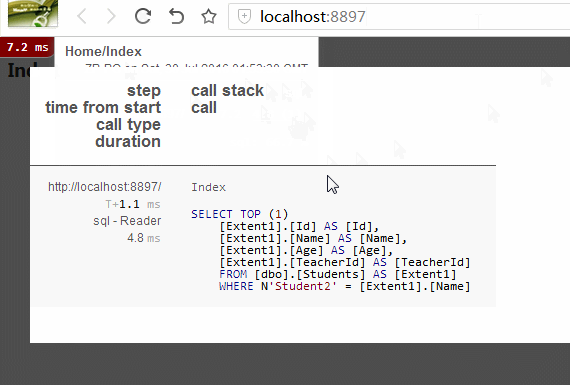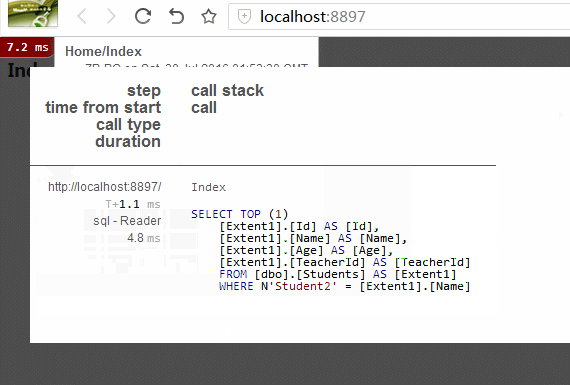
请看上图红框。为什么StudentId有值,而Studet为null?因为使用code first,需要设置导航属性为virtual,才会加载延迟加载数据。

2.关于在循环中访问导航属性的异常处理(接着上面,加上virtual后会报以下异常)
"已有打开的与此 Command 相关联的 DataReader,必须首先将它关闭。"
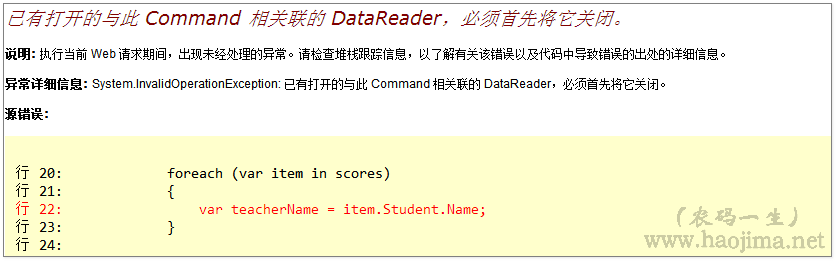
解决方案:
- 方案1、设定ConnectionString加上MultipleActiveResultSets=true,但只适用于SQL 2005以后的版本
- 方案2、或者先读出放置在List中
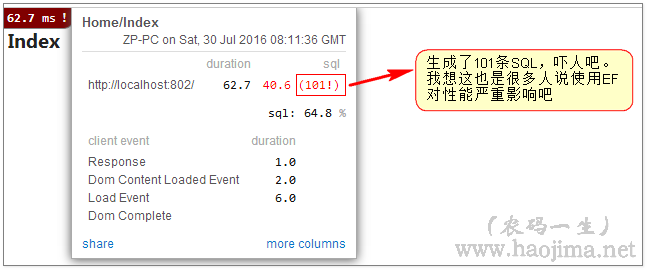
3.以上两点仅为热身,我们说的陷阱才刚刚开始!

然后我们点击打开MiniProfiler工具(不要被吓到)

解决方案:使用Include显示连接查询(注意:需要手动导入using System.Data.Entity 不然Include只能传表名字符串)。

再看MiniProfiler的监控(瞬间101条sql变成了1条,这其中的性能可想而知。)
AutoMapper工具
上面我们通过Include显示的执行表的连接查询显然是不错的,但还不够。如果我们只需要查询数据的某些字段呢,上面查询所有字段岂不是很浪费内存存储空间和应用程序与数据库数据传输带宽。
我们可以:

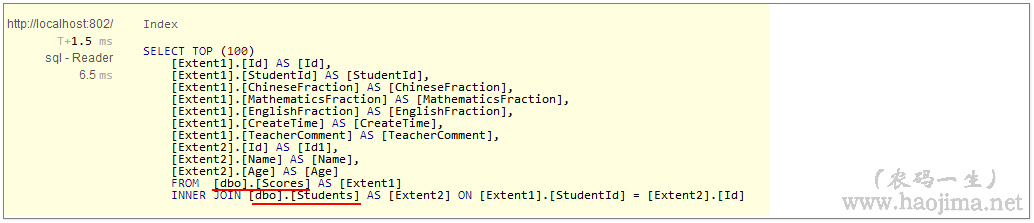
对应监控到的sql:

我们看到生成的sql,查询的字段少了很多。只有我们显示列出来字段的和一个StudentId,StudentId用来连接查询条件的。
是的,这样的方式很不错。可是有没有什么更好的方案或方式呢?答案是肯定的。(不然,也不会在这里屁话了。)如果表字段非常多,我们需要使用的字段也非常多,导航属性也非常多的时候,这样的手动映射就显得不那么好看了。那么接下来我们开始介绍使用AutoMapper来完成映射:
注意:首先需要NuGet下载AutoMapper。(然后导入命名空间 using AutoMapper; using AutoMapper.QueryableExtensions;)


我们看到上面查询语句没有一个个的手动映射,而映射都是独立配置了。其中CreateMap应该是要写到Global.asax文件里面的。(其实也就是分离了映射部分,清晰了查询语句。细心的同学可能注意到了,这种方式还免去了主动Include)

我们看到了生成的sql和前面有些许不同,但只生成了一条sql,并且结果也是正确的。(其实就是多了一条CASE WHEN ([Extent2].[Id] IS NOT NULL) THEN 1 END AS [C1]。看起来这条语句并没有什么实际意义,然而这是AutoMapper生成的sql,同时我也表示不理解为什么和EF生成的不同)
这样做的好处?
- 避免在循环中访问导航属性多次执行sql语句。
- 避免了查询语句中太多的手动映射,影响代码的阅读。
关于AutoMapper的其他一些资料:
http://www.cnblogs.com/xishuai/p/3712361.html
http://www.cnblogs.com/xishuai/p/3700052.html
http://www.cnblogs.com/farb/p/AutoMapperContent.html
联表查询统计
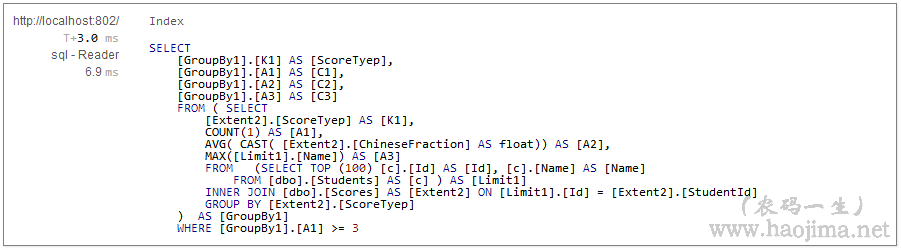
要求:查询前100个学生考试类型(“模拟考试”、“正式考试”)、考试次数、语文平均分、学生姓名,且考试次数大于等于3次。(按考试类型分类统计)
代码如下:
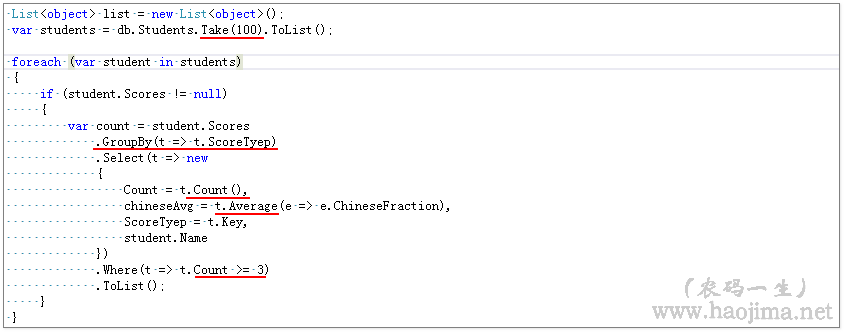
看到这样的代码,我第一反应是惨了。又在循环执行sql了。监控如下:

其实,我们只需要稍微改动就把101条sql变成1条,如下:

马上变1条。
我们打开查看详细的sql语句
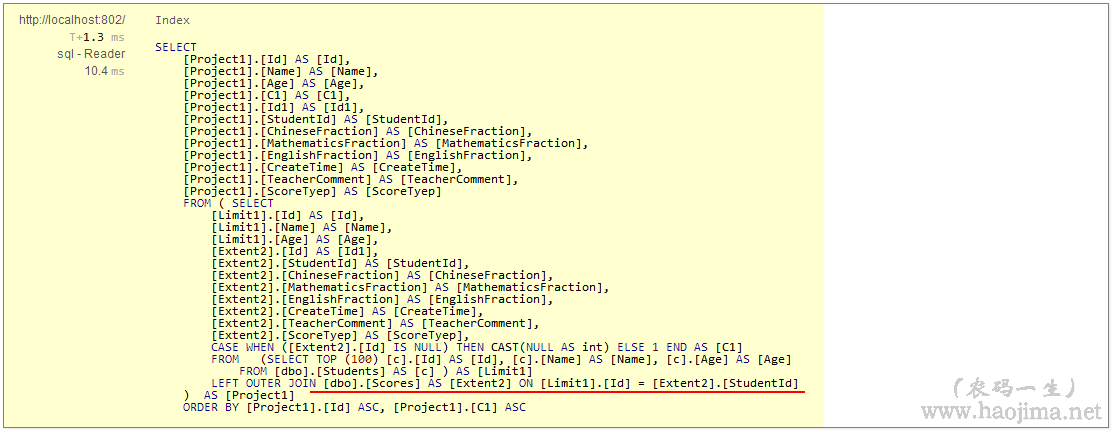
发现这仅仅只是查询结果集合而已,其中的按考试类型来统计是程序拿到所有数据后在计算的(而不是在数据库内计算,然后直接返回结果),这样同样是浪费了数据库查询数据传输。
关于连接查询分组统计我们可以使用SelectMany,如下:
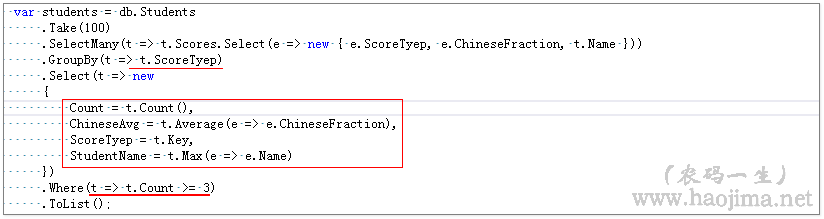
监控sql如下:(是不是简洁多了呢?)
关于SelectMany资料:
http://www.cnblogs.com/lifepoem/archive/2011/11/18/2253579.html
http://www.cnblogs.com/heyuquan/p/Linq-to-Objects.html
性能提升之AsNonUnicode

监控到的sql
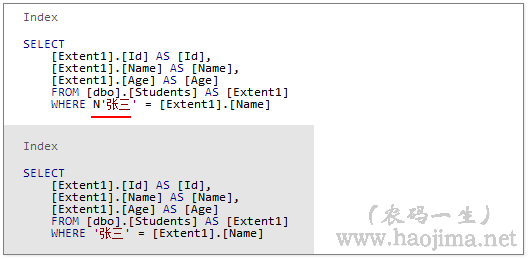
我们看到EF正常情况生成的sql会在前面带上“N”,如果我们加上DbFunctions.AsNonUnicode生成的sql是没有“N”的,当你发现带上“N”的sql比没有带“N”的 sql查询速度慢很多的时候那就知道该怎么办。
(以前用oracle的时候带不带“N”查询效率差别特别明显,今天用sql server测试并没有发现什么差别 。还有我发现EF6会根据数据库中是nvarchar的时候才会生成带“N”的sql,oracle数据库没测试,有兴趣的同学可以测试下)
。还有我发现EF6会根据数据库中是nvarchar的时候才会生成带“N”的sql,oracle数据库没测试,有兴趣的同学可以测试下)
性能提升之AsNoTracking

我们看生成的sql

sql是生成的一模一样,但是执行时间却是4.8倍。原因仅仅只是第一条EF语句多加了一个AsNoTracking。
注意:
- AsNoTracking干什么的呢?无跟踪查询而已,也就是说查询出来的对象不能直接做修改。所以,我们在做数据集合查询显示,而又不需要对集合修改并更新到数据库的时候,一定不要忘记加上AsNoTracking。
- 如果查询过程做了select映射就不需要加AsNoTracking。如:db.Students.Where(t=>t.Name.Contains("张三")).select(t=>new (t.Name,t.Age)).ToList();
多字段组合排序(字符串)
要求:查询名字里面带有“张三”的学生,先按名字排序,再按年龄排序。

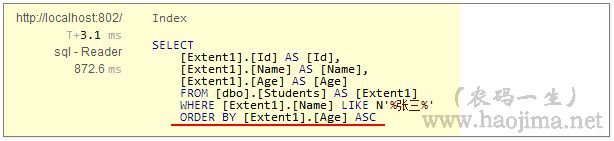
咦,不对啊。按名字排序被年龄排序覆盖了。我们应该用ThenBy来组合排序。


不错不错,正是我们想要的效果。如果你不想用ThenBy,且都是升序的话,我们也可以:


生成的sql是一样的。与OrderBy、ThenBy对应的降序有OrderByDescending、ThenByDescending。
看似好像很完美了。其实不然,我们大多数情况排序是动态的。比如,我们会更加前端页面不同的操作要求不同字段的不同排序。那我们后台应该怎么做呢?

当然,这样完成是没问题的,只要你愿意。可以这么多可能的判断有没有感觉非常SB?是的,我们当然有更好的解决方案。要是OrderBy可以直接传字符串???
解决方案:
- guget下载System.Linq.Dynamic
- 导入System.Linq.Dynamic命名空间
- 编写OrderBy的扩展方法

然后上面又长又臭的代码可以写成:

我们看下生成的sql:

和我们想要的效果完全符合,是不是感觉美美哒!!
【注意】:传入的排序字段后面要加排序关键字 asc或desc
lamdba条件组合
要求:根据不同情况查询,可能情况
- 查询name=“张三” 的所有学生
- 查询name=“张三” 或者 age=18的所有学生
实现代码:

是不是味到了同样的臭味 。下面我们来灵活组装Lamdba条件。
。下面我们来灵活组装Lamdba条件。
解决方案:
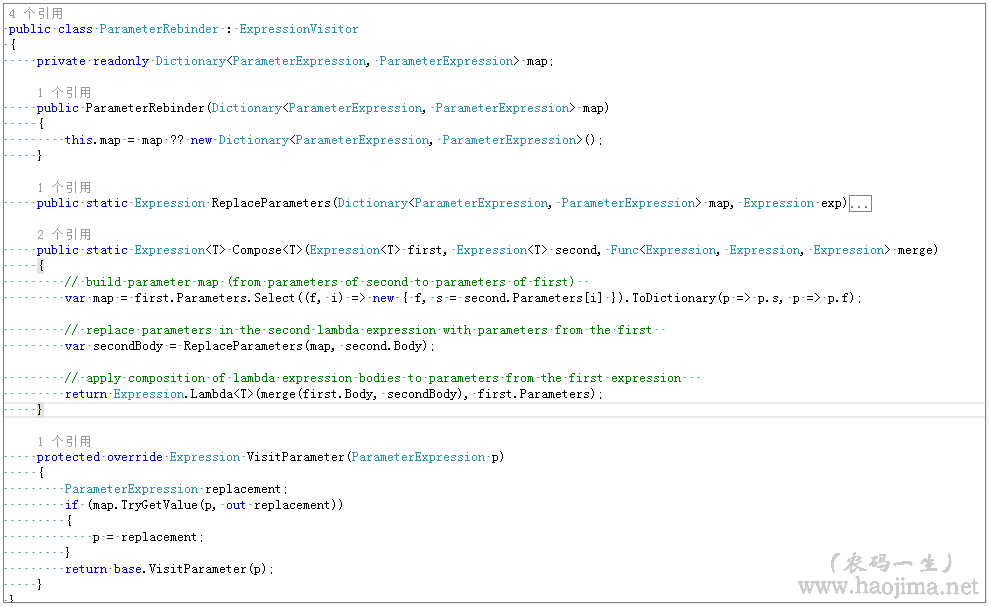

这段代码我也是从网上偷的,具体链接找不到了。
然后我们的代码可以写成:

有没有美美哒一点 。然后我们看看生成的sql是否正确:
。然后我们看看生成的sql是否正确:

EF的预热
http://www.cnblogs.com/dudu/p/entity-framework-warm-up.html
count(*)被你用坏了吗(Any的用法)
要求:查询是否存在名字为“张三”的学生。(你的代码会怎样写呢?)

第一种?第二种?第三种?呵呵,我以前就是使用的第一种,然后有人说“你count被你用坏了”,后来我想了想了怎么就被我用坏了呢?直到对比了这三个语句的性能后我知道了。

性能之差竟有三百多倍,count确实被我用坏了。(我想,不止被我一个人用坏了吧。)
我们看到上面的Any干嘛的?官方解释是:

我反复阅读这个中文解释,一直无法理解。甚至早有人也提出过同样的疑问《实在看不懂MSDN关于 Any 的解释》
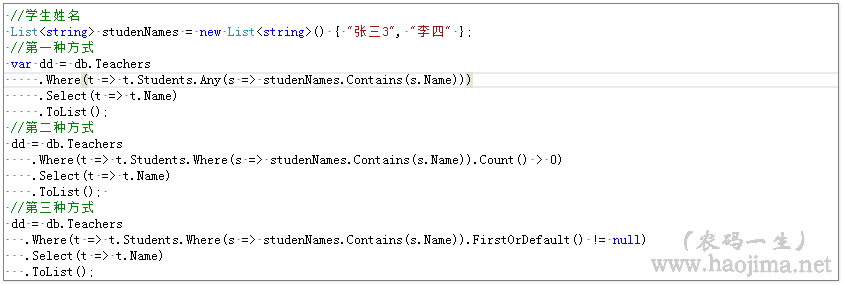
所以我个人理解也是“确定集合中是否有元素满足某一条件”。我们来看看any其他用法:
要求:查询教过“张三”或“李四”的老师
实现代码:

两种方式,以前我会习惯写第一种。当然我们看看生成过的sql和执行效率之后,看法改变了。
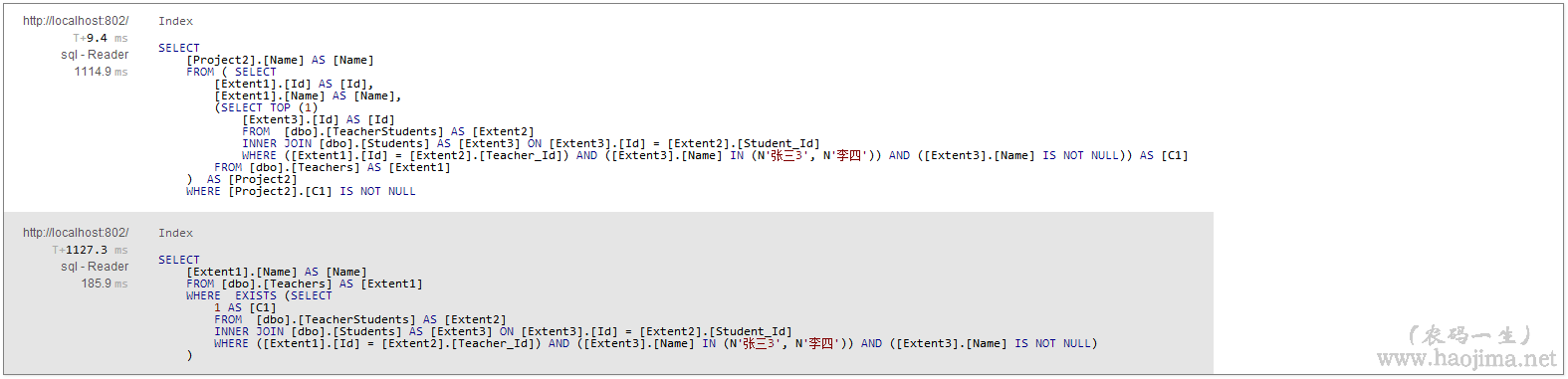
效率之差竟有近六倍。
我们再对比下count:
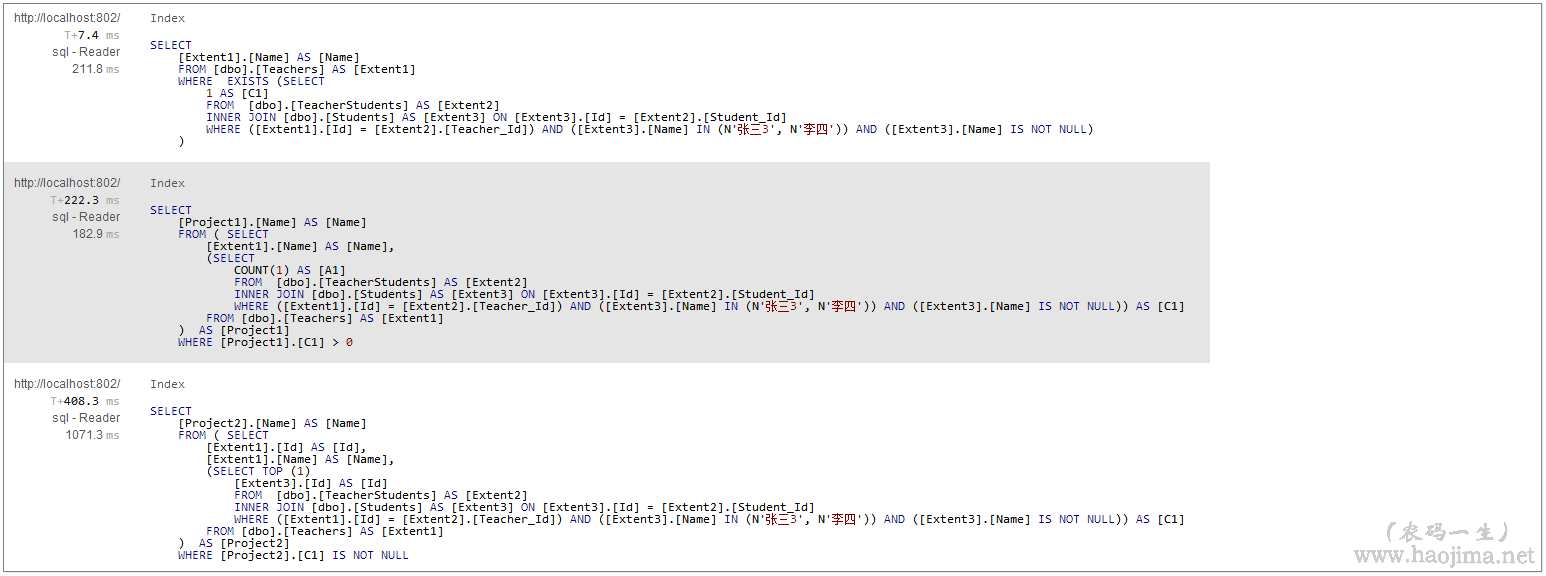
得出奇怪的结论:
- 在导航属性里面使用count和使用any性能区别不大,反而FirstOrDefault() != null的方式性能最差。
- 在直接属性判断里面any和FirstOrDefault() != null性能区别不大,count性能要差的多。
- 所以,不管是直接属性还是导航属性我们都用any来判断是否存在是最稳当的。
透明标识符
假如由于各种原因我们需要写下面这样逻辑的语句

我们可以写成这样更好

看生成的sql就知道了
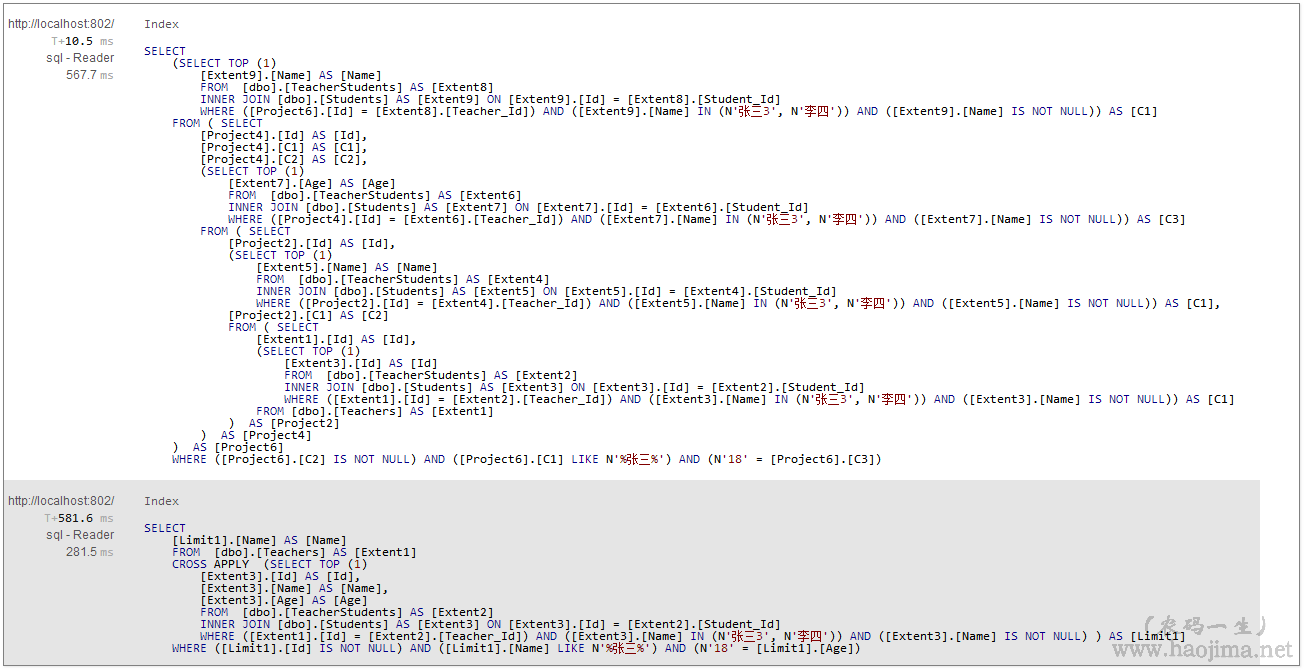
第二种方式生成的sql要干净得多,性能也更好。
EntityFramework.Extended
这里推荐下插件EntityFramework.Extended,看了下,很不错。
最大的亮点就是可以直接批量修改、删除,不用像EF默认的需要先做查询操作。
至于官方EF为什么没有提供这样的支持就不知道了。不过使用EntityFramework.Extended需要注意以下几点:
- 只支持sql server
- 批量修改、删除时不能实现事务(也就是出了异常不能回滚)
- 没有联级删除
- 不能同EF一起SaveChanges (详见)
http://www.cnblogs.com/GuZhenYin/p/5482288.html
在此纠正个问题EntityFramework.Extended并不是说不能回滚,感谢@GuZhenYin园友的指正(原谅我之前没有动手测试)。
注意:需要NuGet下载EntityFramework.Extended, 并导入命名空间: using EntityFramework.Extensions ;
测试代码如下:(如果注释掉手抛异常代码是可以直接更新到数据库的)
using (var ctxTransaction = db.Database.BeginTransaction()) { try { db.Teachers.Where(t => true).Update(t => new Teacher { Age = "1" }); throw new Exception("手动抛出异常"); ctxTransaction.Commit();//提交事务 } catch (Exception) { ctxTransaction.Rollback();//回滚事务 } }
自定义IQueryable扩展方法
最后整理下自定义的IQueryable的扩展。


补充1:
First和Single的区别:前者是TOP(1)后者是TOP(2),后者如果查询到了2条数据则抛出异常。所以在必要的时候使用Single也不会比First慢多少。
补充2:
已打包nuget提供直接安装 Install-Package Talk.Linq.Extensions 或nuget搜索 Talk.Linq.Extensions
https://github.com/zhaopeiym/Talk/wiki/Talk.Linq.Extensions_demo
结束:
源码下载:http://pan.baidu.com/s/1o8MYozw
本文以同步至《C#基础知识巩固系列》
欢迎热心园友补充!

