Day03 - Python 函数
1. 函数简介
函数是组织好的,可重复使用的,用来实现单一或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。Python提供了许多内建函数,比如print();也可以自己创建函数,这被叫做用户自定义函数。
2. 函数定义
规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()。
- 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串,用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
语法:
1 def functionname( parameters ): 2 "函数_文档字符串" 3 function_suite 4 return [expression]
默认情况下,参数值和参数名称是按函数声明中定义的顺序匹配起来的。
实例:
以下为一个简单的Python函数,它将一个字符串作为传入参数,再打印到标准显示设备上。
1 def printme( str ): 2 "打印传入的字符串到标准显示设备上" 3 print str 4 return
3. 函数调用
定义一个函数只给了函数一个名称,指定了函数里包含的参数,和代码块结构。
这个函数的基本结构完成以后,你可以通过另一个函数调用执行,也可以直接从Python提示符执行。
如下实例调用了printme() 函数:
1 #!/usr/bin/env python 2 # -*- coding: UTF-8 -*- 3 4 5 # 定义函数 6 def printme(str): 7 "打印任何传入的字符串" 8 print(str) 9 return 10 11 # 调用函数 12 printme("我要调用用户自定义函数!") 13 printme("再次调用同一函数")
输出结果:
1 我要调用用户自定义函数! 2 再次调用同一函数
4. 按值传递参数和按引用传递参数
所有参数(自变量)在Python里都是按引用传递。如果你在函数里修改了参数,那么在调用这个函数的函数里,原始的参数也被改变了。例如:
1 #!/usr/bin/env python 2 # -*- coding: UTF-8 -*- 3 4 5 # 可写函数说明 6 def changeme(mylist): 7 "修改传入的列表" 8 mylist.append([1, 2, 3, 4]) 9 print("函数内取值: ", mylist) 10 return 11 12 # 调用 changeme 函数 13 mylist = [10, 20, 30] 14 changeme(mylist) 15 print("函数外取值: ", mylist)
输出结果:
1 函数内取值: [10, 20, 30, [1, 2, 3, 4]] 2 函数外取值: [10, 20, 30, [1, 2, 3, 4]]
传入函数的和在末尾添加新内容的对象用的是同一个引用。
5.参数
以下是调用函数时可使用的正式参数类型:
- 必备参数
- 关键字参数
- 默认参数
- 不定长参数
必备参数
必备参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
调用printme()函数,你必须传入一个参数,不然会出现语法错误:
1 #!/usr/bin/env python 2 # -*- coding: UTF-8 -*- 3 4 # 可写函数说明 5 def printme(str): 6 "打印任何传入的字符串" 7 print(str) 8 return 9 10 # 调用printme函数 11 printme()
输出结果:
1 Traceback (most recent call last): 2 File "D:/PycharmProjects/S15/day04/test.py", line 11, in <module> 3 printme() 4 TypeError: printme() missing 1 required positional argument: 'str'
关键字参数
关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值。
使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
以下实例在函数 printme() 调用时使用参数名:
1 #!/usr/bin/env python 2 # -*- coding: UTF-8 -*- 3 4 5 # 可写函数说明 6 def printme(str): 7 "打印任何传入的字符串" 8 print(str) 9 return 10 11 12 # 调用printme函数 13 printme(str="My string");
输出结果:
1 My string
下例能将关键字参数顺序不重要展示得更清楚:
1 #!/usr/bin/env python 2 # -*- coding: UTF-8 -*- 3 4 5 # 可写函数说明 6 def printinfo(name, age): 7 "打印任何传入的字符串" 8 print("Name: ", name) 9 print("Age ", age) 10 return 11 12 # 调用printinfo函数 13 printinfo(age = 50, name = "miki")
以上实例输出结果:
1 Name: miki 2 Age 50
缺省参数
调用函数时,缺省参数的值如果没有传入,则被认为是默认值。下例会打印默认的age,如果age没有被传入:
1 #!/usr/bin/env python 2 # -*- coding: UTF-8 -*- 3 4 5 # 可写函数说明 6 def printinfo(name, age=35): 7 "打印任何传入的字符串" 8 print("Name: ", name) 9 print("Age ", age) 10 return 11 12 13 # 调用printinfo函数 14 printinfo(age=50, name="miki") 15 printinfo(name="miki")
以上实例输出结果:
1 Name: miki 2 Age 50 3 Name: miki 4 Age 35
不定长参数
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述2种参数不同,声明时不会命名。基本语法如下:
1 def functionname([formal_args,] *var_args_tuple ): 2 "函数_文档字符串" 3 function_suite 4 return [expression]
加了星号(*)的变量名会存放所有未命名的变量参数。选择不多传参数也可。如下实例:
1 #!/usr/bin/env python 2 # -*- coding: UTF-8 -*- 3 4 5 # 可写函数说明 6 def printinfo(arg1, *vartuple): 7 "打印任何传入的参数" 8 print("输出: ") 9 print(arg1) 10 for var in vartuple: 11 print(var) 12 return 13 14 # 调用printinfo 函数 15 printinfo(10) 16 printinfo(70, 60, 50)
输出结果:
1 输出: 2 10 3 输出: 4 70 5 60 6 50
6. 匿名函数
python 使用 lambda 来创建匿名函数。
- lambda 只是一个表达式,函数体比 def 简单很多。
- lambda 的主体是一个表达式,而不是一个代码块。仅仅能在 lambda 表达式中封装有限的逻辑进去。
- lambda 函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
- 虽然 lambda 函数看起来只能写一行,却不等同于 C 或 C++ 的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
语法
lambda 函数的语法只包含一个语句,如下:
1 lambda [arg1 [,arg2,.....argn]]:expression
如下实例:
1 #!/usr/bin/env python 2 # -*- coding: UTF-8 -*- 3 4 # 可写函数说明 5 sum = lambda arg1, arg2: arg1 + arg2 6 7 # 调用sum函数 8 print("相加后的值为 : ", sum(10, 20)) 9 print("相加后的值为 : ", sum(20, 20))
输出结果:
1 相加后的值为 : 30 2 相加后的值为 : 40
7. return 语句
return 语句[表达式]退出函数,选择性地向调用方返回一个表达式。
不带参数值的 return 语句返回 None。
如下实例:
1 #!/usr/bin/env python 2 # -*- coding: UTF-8 -*- 3 4 5 # 可写函数说明 6 def sum(arg1, arg2): 7 # 返回2个参数的和." 8 total = arg1 + arg2 9 print("函数内 : ", total) 10 return total 11 12 # 调用sum函数 13 total = sum(10, 20)
输出结果:
1 函数内 : 30
8. 变量作用域
一个程序的所有的变量并不是在哪个位置都可以访问的。访问权限决定于这个变量是在哪里赋值的。
变量的作用域决定了在哪一部分程序你可以访问哪个特定的变量名称。
两种最基本的变量作用域如下:
- 全局变量
- 局部变量
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。
调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。
如下实例:
1 #!/usr/bin/env python 2 # -*- coding: UTF-8 -*- 3 4 total = 0 # 这是一个全局变量 5 6 7 # 可写函数说明 8 def sum(arg1, arg2): 9 # 返回2个参数的和." 10 total = arg1 + arg2 # total在这里是局部变量 11 print("函数内是局部变量 : ", total) 12 return total 13 14 # 调用sum函数 15 sum(10, 20) 16 print("函数外是全局变量 : ", total)
以上实例输出结果:
1 函数内是局部变量 : 30 2 函数外是全局变量 : 0
9. 内置参数

1)abs(x)
函数返回数字(可为普通型、长整型或浮点型)的绝对值。若参数是复数,返回值就是该复数的模
1 >>> abs(-2.4) 2 2.4
2)all(iterable)
如果iterable的所有元素不为0、''、False或者iterable为空,all(iterable)返回True,否则返回False(若为空串返回为True)
空元组、空列表、空字典空集合的返回值为True
1 >>> all(['a', 'b', 'c', 'd']) #列表list,元素都不为空或0 2 True 3 >>> all(['a', 'b', '', 'd']) #列表list,存在一个为空的元素 4 False 5 >>> all([0, 1,2, 3]) #列表list,存在一个为0的元素 6 False 7 8 >>> all(('a', 'b', 'c', 'd')) #元组tuple,元素都不为空或0 9 True 10 >>> all(('a', 'b', '', 'd')) #元组tuple,存在一个为空的元素 11 False 12 >>> all((0, 1,2, 3)) #元组tuple,存在一个为0的元素 13 False 14 15 >>> all({'a':"James", 'b':24}) #字典dict,key都不为空 16 True 17 >>>all({'a':"James", '':24}) #字典dict,存在一个key为空的元素 18 False 19 20 >>> all(set(('a','b', 'c', 'd'))) #集合set,元素都不为空或0 21 True 22 >>> all(set(('a', 'b', '', 'd'))) #集合set,存在一个为空的元素 23 False 24 >>> all(set((0, 1, 2, 3))) #集合set,存在一个为0的元素 25 False 26 27 28 >>> all([]) # 空列表 29 True 30 >>> all(()) # 空元组 31 True 32 >>> all({}) # 空字典 33 True 34 >>> all(set()) # 空集合 35 True
3)any(iterable)
如果iterable的任何元素不为0、''、False,all(iterable)返回True。如果iterable为空,返回False
1 >>> any(['a', 'b', 'c', 'd']) #列表list,元素都不为空或0 2 True 3 >>> any(['a', 'b', '', 'd']) #列表list,存在一个为空的元素 4 True 5 >>> any([0, '', False]) #列表list,元素全为0,'',false 6 False 7 8 >>> any(('a', 'b', 'c', 'd')) #元组tuple,元素都不为空或0 9 True 10 >>> any(('a', 'b', '', 'd')) #元组tuple,存在一个为空的元素 11 True 12 >>> any((0, '', False)) #元组tuple,元素全为0,'',false 13 False 14 15 >>> any({'name':"James", '':24}) #字典dict,key有一个为空 16 True 17 >>> any({'name':"James", False:1}) #字典dict,key有一个为False 18 True 19 >>> any({False:1}) #字典dict,key为False 20 False 21 >>> any({'':24}) #字典dict,key为空 22 False 23 24 >>> any(set(('a', 'b', 'c', 'd'))) #集合set,元素都不为空或0 25 True 26 >>> any(set(('a', 'b', '', 'd'))) #集合set,元素都不为空或0 27 True 28 >>> any(set((0, '', False))) #集合set,元素全为0,'',false 29 False 30 31 32 >>> any([]) # 空列表 33 False 34 >>> any(()) # 空元组 35 False 36 >>> any({}) # 空字典 37 False 38 >>> any(set()) # 空集合 39 False
4)ascii()
返回一个可打印的对象字符串方式表示。当遇到非ASCII码时,就会输出\x,\u或\U等字符来表示
1 >>> ascii(10) 2 '10' 3 >>> ascii(9000000000) 4 '9000000000' 5 >>> ascii('b\31') 6 "'b\\x19'" 7 >>> ascii('0x\1000') 8 "'0x@0'"
5)bin()
将整数x转换为二进制字符串,如果不为Python中int类型,x必须包含方法__index__(),并且返回值为integer
参数x:整数或者包含__index__()方法切返回值为integer的类型
1 # 整数的情况 2 >>> bin(521) 3 # 显示结果形式与平时习惯有些差别,前面多了0b,表示二进制的意思 4 '0b1000001001' 5 # 非整型的情况,必须包含 __index__() 方法,且返回值为 integer 类型 6 >>> class myType: 7 ... def __index__(self): 8 ... return 35 9 ... 10 >>> myvar = myType() 11 >>> bin(myvar) 12 '0b1000001001'
6)bool([x])
将x转换为Boolean类型,如果x缺省,返回False,bool也为int的子类
参数x:任意对象或缺省
1 >>> bool(0) 2 False 3 >>> bool("abc") 4 True 5 >>> bool("") 6 False 7 >>> bool([]) 8 False 9 >>> bool() 10 False 11 >>> issubclass(bool, int) # bool 是int的一个subclass 12 True
7)bytearray([source [, encoding [, errors]]])
bytearray([source [, encoding [, errors]]])返回一个byte数组。Bytearray类型是一个可变的序列,并且序列中的元素的取值范围为 [0 ,255]。
参数source:
如果 source 为整数,则返回一个长度为 source 的初始化数组;
如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
如果 source 为可迭代类型,则元素必须为[0 ,255]中的整数;
如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray 。
1 >>> a = bytearray(3) 2 >>> a 3 bytearray(b'\x00\x00\x00') 4 >>> a[0] 5 0 6 >>> a[1] 7 0 8 >>> a[2] 9 0 10 11 >>> c = bytearray([1, 2, 3]) 12 >>> c 13 bytearray(b'\x01\x02\x03') 14 >>> c[0] 15 1 16 >>> c[1] 17 2 18 >>> c[2] 19 3
8)bytes([source[, encoding[, errors]]])
返回一个新的数组对象,这个数组对象不能对数组元素进行修改。每个元素值范围: 0 <= x < 256。bytes函数与bytearray函数主要区别是bytes函数产生的对象的元素不能修改,而bytearray函数产生的对象的元素可以修改。因此,除了可修改的对象函数跟bytearray函数不一样之外,其它使用方法全部是相同的。最后它的参数定义方式也与bytearray函数是一样的。
1 >>> a = bytes('abc', 'utf-8') 2 >>> a 3 b'abc' 4 >>> b = bytes(1) 5 >>> b 6 b'\x00' 7 >>> c = bytes([2,3,6,8]) 8 >>> c 9 b'\x02\x03\x06\x08'
9) callable(object)
检查对象object是否可调用。如果返回True,object仍然可能调用失败;但如果返回False,调用对象ojbect绝对不会成功。
注意:类是可调用的,而类的实例实现了__call__()方法才可调用。
1 >>> callable(0) 2 False 3 >>> callable("mystring") 4 False 5 >>> def add(a, b): 6 ... return a + b 7 ... 8 >>> callable(add) 9 True 10 >>> class A: 11 ... def method(self): 12 ... return 0 13 ... 14 >>> callable(A) 15 True 16 >>> a = A() 17 >>> callable(a) 18 False 19 >>> class B: 20 ... def __call__(self): 21 ... return 0 22 ... 23 >>> callable(B) 24 True 25 >>> b = B() 26 >>> callable(b) 27 True
10) chr(i)
返回整数i对应的ASCII字符。与ord()作用相反。
参数x:取值范围[0, 255]之间的正数。
1 >>> chr(97) 2 'a' 3 >>> chr(97) 4 'a' 5 >>> ord('a') 6 97 7 >>> ord('b') 8 98
11) classmethed(function)
classmethod是用来指定一个类的方法为类方法,没有此参数指定的类的方法为实例方法
1 class C: 2 @classmethod 3 def f(cls, arg1, arg2, ...): ...
类方法既可以直接类调用(C.f()),也可以进行实例调用(C().f())
1 >>> class C: 2 ... @classmethod 3 ... def f(self): 4 ... print("This is a class method") 5 ... 6 >>> C.f() 7 This is a class method 8 >>> c = C() 9 >>> c.f() 10 This is a class method 11 >>> class D: 12 ... def f(self): 13 ... print(" This is not a class method ") 14 ... 15 >>> D.f() 16 Traceback (most recent call last): 17 File "<stdin>", line 1, in <module> 18 TypeError: f() missing 1 required positional argument: 'self' 19 >>> d = D() 20 >>> d.f() 21 This is not a class method
12) compile(source, filename, mode[, flags[, dont_inherit]])
将source编译为代码或者AST对象。代码对象能够通过exec语句来执行或者 eval() 进行求值。
参数source:字符串或者AST(Abstract Syntax Trees)对象。
参数 filename:代码文件名称,如果不是从文件读取代码则传递一些可辨认的值。
参数mode:指定编译代码的种类。可以指定为 ‘exec’,’eval’,’single’。
参数flag和dont_inherit:这两个参数暂不介绍,可选参数
1 >>> code = "for i in range(0, 10): print(i)" 2 >>> cmpcode = compile(code, '', 'exec') 3 >>> exec(cmpcode) 4 0 5 1 6 2 7 3 8 4 9 5 10 6 11 7 12 8 13 9 14 >>> str = "3 * 4 + 5" 15 >>> a = compile(str,'','eval') 16 >>> eval(a) 17 17
13) complex([real[, imag]])
创建一个值为 real + imag * j 的复数或者转化一个字符串或数为复数。如果第一个参数为字符串,则不需要指定第二个参数。
参数real: int, long, float或字符串
参数imag: int, long, float
1 >>> complex(1, 2) 2 (1+2j) 3 >>> complex(1) #数字 4 (1+0j) 5 >>> complex("1") #当做字符串处理 6 (1+0j) 7 >>> complex("1+2j") #注意:在“+”号两边不能有空格,不能写成"1 + 2j",否则会报错 8 (1+2j)
14) delattr(object, name)
删除 object 对象名为 name的 属性。
参数object:对象
参数name:属性名称字符串
1 >>> class Person: 2 ... def __init__(self, name, age): 3 ... self.name = name 4 ... self.age = age 5 ... 6 >>> tom = Person("Tom", 35) 7 >>> dir(tom) 8 ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'age', 'name'] 9 >>> delattr(tom, "age") 10 >>> dir(tom) 11 ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'name'] 12 >>>
15) dict(iterable, **kwarg)
创建数据字典
从可迭代对象来创建新字典。比如一个元组组成的列表,或者一个字典对象。
1 >>> d1 = dict(one = 1, tow = 2, a = 3) #以键对方式构造字典 2 >>> print(d1) 3 {'one': 1, 'tow': 2, 'a': 3} 4 >>> d2 = dict(zip(['one', 'two', 'three'], [1, 2, 3])) #以映射函数方式来构造字典 5 >>> print(d2) 6 {'one': 1, 'two': 2, 'three': 3} 7 >>> d3 = dict([('one', 1), ('two', 2), ('three', 3)]) #可迭代对象方式来构造字典 8 >>> print(d3) 9 {'one': 1, 'two': 2, 'three': 3} 10 >>> d4 = dict(d3) #字典对象方式来构造字典 11 >>> print(d4) 12 {'one': 1, 'two': 2, 'three': 3}
16)dir()
不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表。如果参数包含方法__dir__(),该方法将被调用。如果参数不包含__dir__(),该方法将最大限度地收集参数信息。
参数object: 对象、变量、类型
1 >>> dir() 2 ['__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__'] 3 >>> import struct 4 >>> dir() 5 ['__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'struct'] 6 >>> dir(struct) 7 ['Struct', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '_clearcache', 'calcsize', 'error', 'iter_unpack', 'pack', 'pack_into', 'unpack', 'unpack_from'] 8 >>> class Person(object): 9 ... def __dir__(self): 10 ... return ["name", "age", "country"] 11 ... 12 >>> dir(Person) 13 ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__'] 14 >>> tom = Person() 15 >>> dir(tom) 16 ['age', 'country', 'name']
17) divmod(a,b)函数
divmod(a,b)方法返回的是a//b(除法取整)以及a对b的余数
返回结果类型为tuple
参数:a,b可以为数字(包括复数)
1 >>> divmod(9,2) 2 (4, 1) 3 >>> divmod(11,3) 4 (3, 2) 5 >>> divmod(1+2j,1+0.5j) 6 ((1+0j), 1.5j)
18) enumerate()
用于遍历序列中的元素以及它们的下标
1 >>> for i,j in enumerate(('a','b','c')): 2 ... print(i,j) 3 ... 4 0 a 5 1 b 6 2 c 7 >>> for i,j in enumerate([1,2,3]): 8 ... print(i,j) 9 ... 10 0 1 11 1 2 12 2 3 13 >>> for i,j in enumerate({'a':1,'b':2}): 14 ... print(i,j) 15 ... 16 0 a 17 1 b 18 >>> for i,j in enumerate('abc'): 19 ... print(i,j) 20 ... 21 0 a 22 1 b 23 2 c
19) eval()
将字符串str当成有效的表达式来求值并返回计算结果
1 >>> a = "[[1,2], [3,4], [5,6], [7,8], [9,0]]" 2 >>> a 3 '[[1,2], [3,4], [5,6], [7,8], [9,0]]' 4 >>> type(a) 5 <class 'str'> 6 >>> b = eval(a) 7 >>> b 8 [[1, 2], [3, 4], [5, 6], [7, 8], [9, 0]] 9 >>> type(b) 10 <class 'list'> 11 >>> a = "{1: 'a', 2: 'b'}" 12 >>> a 13 "{1: 'a', 2: 'b'}" 14 >>> type(a) 15 <class 'str'> 16 >>> b = eval(a) 17 >>> b 18 {1: 'a', 2: 'b'} 19 >>> type(b) 20 <class 'dict'> 21 >>> a = "([1,2], [3,4], [5,6], [7,8], (9,0))" 22 >>> a 23 '([1,2], [3,4], [5,6], [7,8], (9,0))' 24 >>> type(a) 25 <class 'str'> 26 >>> b = eval(a) 27 >>> b 28 ([1, 2], [3, 4], [5, 6], [7, 8], (9, 0)) 29 >>> type(b) 30 <class 'tuple'>
20) exec()
3.嵌套函数
4.递归
5.匿名函数
6.函数式编程介绍
7.高阶函数
本节作业
有以下员工信息表
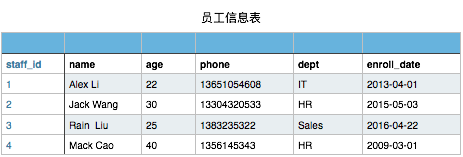
当然此表你在文件存储时可以这样表示
|
1
|
1,Alex Li,22,13651054608,IT,2013-04-01 |
现需要对这个员工信息文件,实现增删改查操作
- 可进行模糊查询,语法至少支持下面3种:
- select name,age from staff_table where age > 22
- select * from staff_table where dept = "IT"
- select * from staff_table where enroll_date like "2013"
- 查到的信息,打印后,最后面还要显示查到的条数
- 可创建新员工纪录,以phone做唯一键,staff_id需自增
- 可删除指定员工信息纪录,输入员工id,即可删除
- 可修改员工信息,语法如下:
- UPDATE staff_table SET dept="Market" WHERE where dept = "IT"
注意:以上需求,要充分使用函数,请尽你的最大限度来减少重复代码!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号