数据处理难题的一套解决方案
【原创】 数据处理难题的一套解决方案
问题描述:
将学生的各科考试成绩组合为单一的成绩衡量指标、基于相对名次(前20%,下20%,等等)给出从A到F的评分、根据学生姓氏和名字的首字母对花名册进行排序。
代码清单:
options(digits = 2)
Student<-c("John Davis", "Angela Williams", "Bullwinkle Moose"
, "David Jones", "Janice Markhammer", "Cheryl Cushing"
, "Reuven Ytzrhak", "Greg Knox", "Joel England", "Mary Rayburn")
Math<-c(502,600,412,358,495,512,410,625,573,522)
Science<-c(95,99,80,82,75,85,80,95,89,86)
English<-c(25,22,18,15,20,28,15,30,27,18)
roster<-data.frame(Student, Math, Science,English)
roster<-data.frame(Student, Math, Science, English, stringsAsFactors = FALSE)
z=scale(roster[,2:4])
score<-apply(z, 1, mean)
roster=cbind(roster,score)
y <-quantile(score,c(0.8,0.6,0.4,0.2))
roster$grade[score >=y[1]]<-"A"
roster$grade[score <y[1] & score >=y[2]] <-"B"
roster$grade[score <y[2] & score >=y[3]] <-"C"
roster$grade[score <y[3] & score >=y[4]] <-"D"
roster$grade[score <y[4]] <-"F"
name<-strsplit((roster$Student)," ")
lastname<-sapply(name,"[", 2)
firstname<-sapply(name, "[", 1)
roster<-cbind(firstname, lastname, roster[,-1])
roster<-roster[order(firstname, lastname),]
代码解读
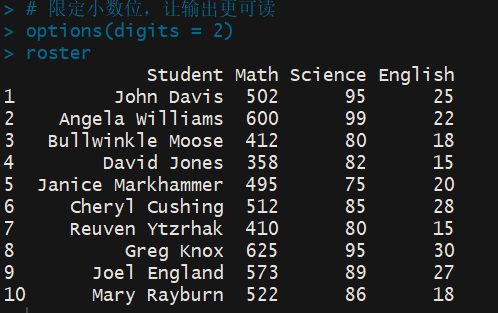
> # 限定小数位,让输出更可读 > options(digits = 2) > roster
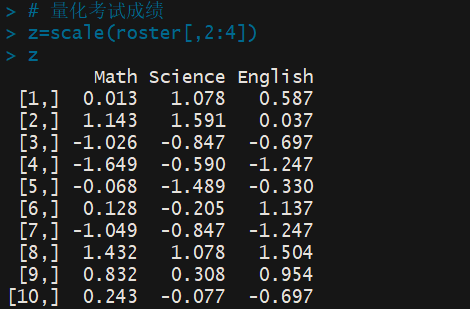
> # 量化考试成绩 > z=scale(roster[,2:4]) > z
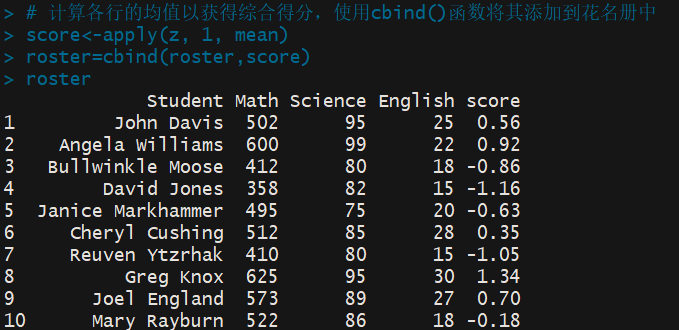
> # 计算各行的均值以获得综合得分,使用cbind()函数将其添加到花名册中 > score<-apply(z, 1, mean) > roster=cbind(roster,score) > roster
> # 函数quantile()给出了学生综合得分的百分位数,可以看到,成绩为A的分界点为0.74,B的分界点为0.44,等等。 > y <-quantile(score,c(0.8,0.6,0.4,0.2)) > y

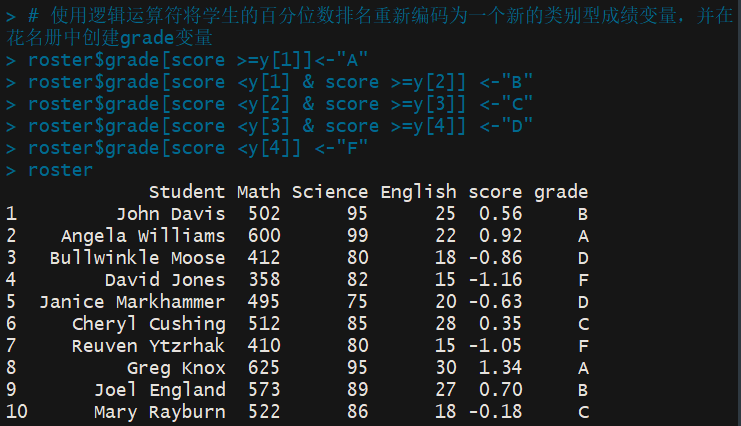
> # 使用逻辑运算符将学生的百分位数排名重新编码为一个新的类别型成绩变量,并在花名册中创建grade变量 > roster$grade[score >=y[1]]<-"A" > roster$grade[score <y[1] & score >=y[2]] <-"B" > roster$grade[score <y[2] & score >=y[3]] <-"C" > roster$grade[score <y[3] & score >=y[4]] <-"D" > roster$grade[score <y[4]] <-"F" > roster
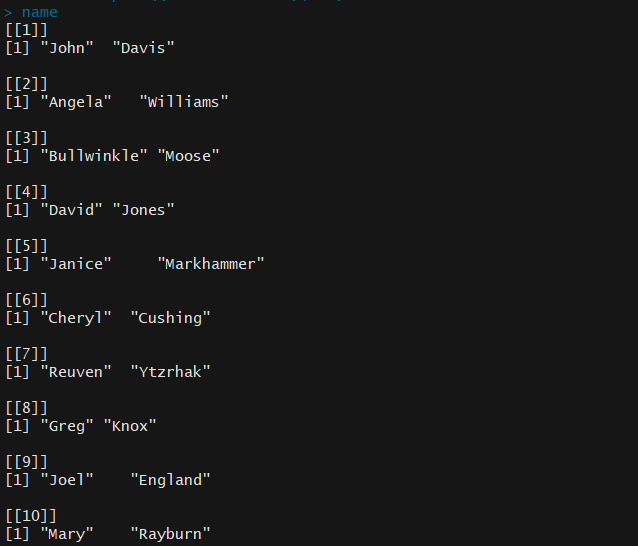
> # 使用strsplit()以空格为分隔符,把学生姓名分割为姓氏和名字,返回值为列表 > name<-strsplit((roster$Student)," ") > name
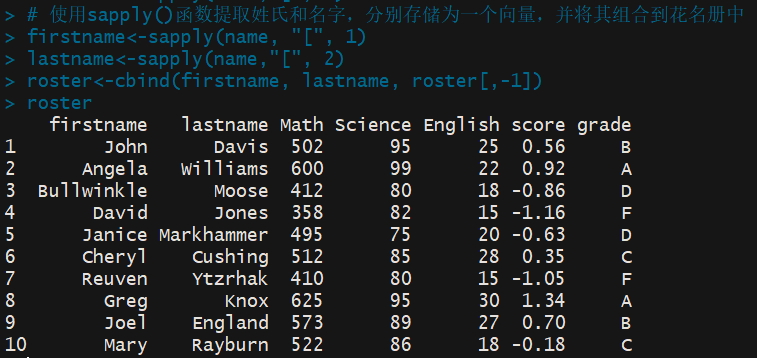
> # 使用sapply()函数提取姓氏和名字,分别存储为一个向量,并将其组合到花名册中 > firstname<-sapply(name, "[", 1) > lastname<-sapply(name,"[", 2) > roster<-cbind(firstname, lastname, roster[,-1]) > roster
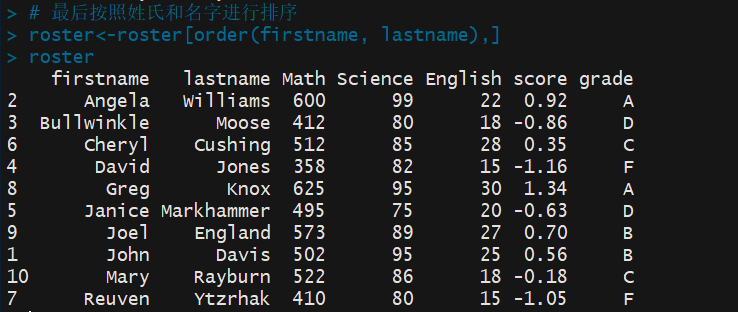
> # 最后按照姓氏和名字进行排序 > roster<-roster[order(firstname, lastname),] > roster

 浙公网安备 33010602011771号
浙公网安备 33010602011771号