
LLaMa-Factory 本地微调 Deepseek R1 1.5B 大模型
LLaMA Factory 是一款开源低代码大模型微调框架,集成了业界最广泛使用的微调技术,支持通过 Web UI 界面零代码微调大模型,目前已经成为开源社区内最受欢迎的微调框架之一。项目提供了多个高层次抽象的调用接口,包含多阶段训练,推理测试,benchmark评测,API Server等,使开发者开箱即用。
GitHub官方地址:https://github.com/hiyouga/LLaMA-Factory?tab=readme-ov-file
本次使用的操作系统,以及环境配置
操作系统:windows11
CPU: i7-11800H
内存:16GB
GPU:RTX3050ti 4G显存
1.安装LLaMa-Factory的环境
使用 anaconda 创建用于 LLaMa-Factory 的虚拟环境
conda create -n llama_factory python=3.11 activate llama_factory
进入项目目录,LLaMA-Factory-main
cd C:\Code\LLaMA-Factory-main
安装环境依赖
pip install -e ".[torch,metrics]"
测试是否安装成功
llamafactory-cli version

扩展:
1)如果训练出现未检测到CUDA环境,则说明pytorch版本没有适配好
安装的torch默认为2.60,与我们本地的环境不适配,导致无法使用GPU(卸载已经安装的totch环境,切换符合CUDA版本的torch环境)
对应版本参考链接:https://pytorch.org/get-started/previous-versions/
cmd查看GPU版本:nvidia-smi
pip uninstall torch torchvision torchaudiop
pip install torch==2.0.0 torchvision==0.15.1 torchaudio==2.0.1 -i https://pypi.tuna.tsinghua.edu.cn/simple -f https://download.pytorch.org/whl/torch_stable.html
测试GPU
import torch
print(torch.cuda.is_available()) # 是否可以用gpu False不能,True可以
print(torch.cuda.device_count()) # gpu数量, 0就是没有,1就是检测到了

2)解决RuntimeError: “triu_tril_cuda_template“ not implemented for ‘BFloat16‘
定位到这个报错的文件,定位到该行代码,然后使用pytorch重新实现一个torch.triu函数,替换出错的地方,将causal_mask = torch_triu(causal_mask, diagonal=1)修改为causal_mask = custom_triu(causal_mask, diagonal=1),保存文件即可


def custom_triu(input_tensor, diagonal=0): """ 返回一个与input_tensor相同形状的新张量,其中包含input_tensor的上三角部分, 其余部分填充为0。diagonal参数决定了上三角部分的定义位置。 参数: input_tensor (torch.Tensor): 输入张量。 diagonal (int, 可选): 对角线偏移。默认为0(主对角线)。 返回: torch.Tensor: 包含上三角部分的新张量。 """ # 获取输入张量的行数和列数 rows, cols = input_tensor.size() # 创建一个与input_tensor相同形状的掩码 # 使用torch.arange来生成行和列的索引,然后进行广播比较 row_indices = torch.arange(rows, device=input_tensor.device).view(-1, 1) col_indices = torch.arange(cols, device=input_tensor.device).view(1, -1) mask = row_indices + diagonal < col_indices # 使用掩码选择上三角部分 result_tensor = torch.where(mask, torch.tensor(0, device=input_tensor.device, dtype=input_tensor.dtype), input_tensor) return result_tensor
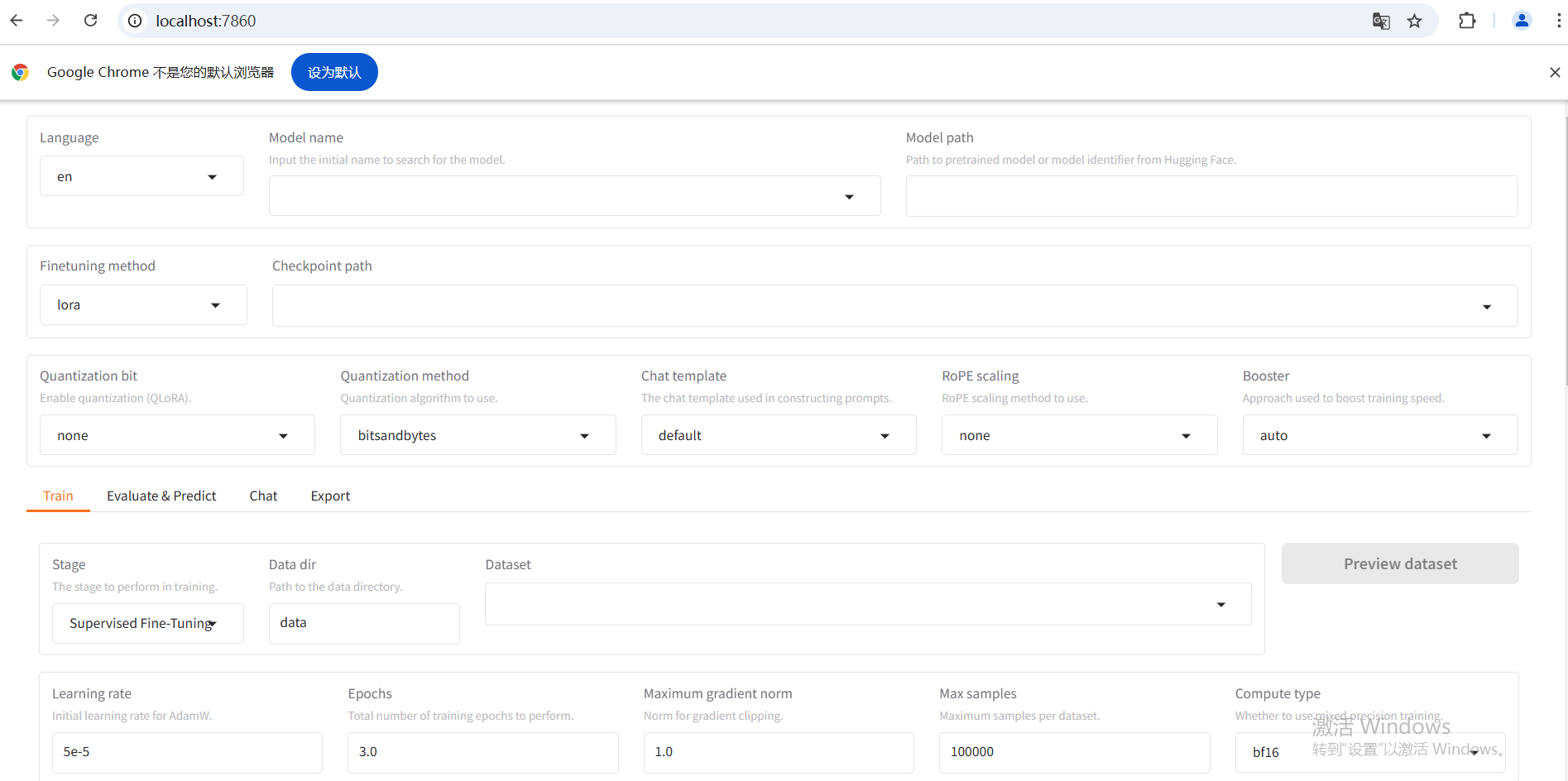
2.启动命令,出现 weibu 界面
llamafactory-cli webui

3.自建数据集
1)项目架构
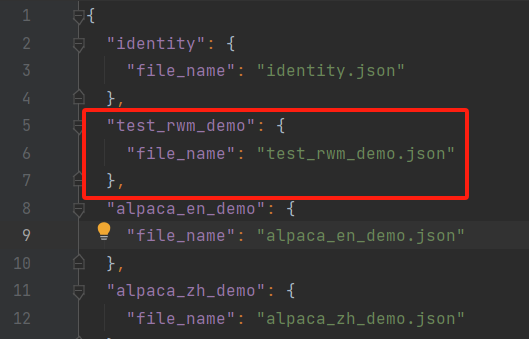
数据集文件都是放在data目录下,有不同的数据集格式,自定义数据集需要将数据处理为框架特定的格式,再修改 dataset_info.json 文件
自定义数据集 test_rwm_demo.json
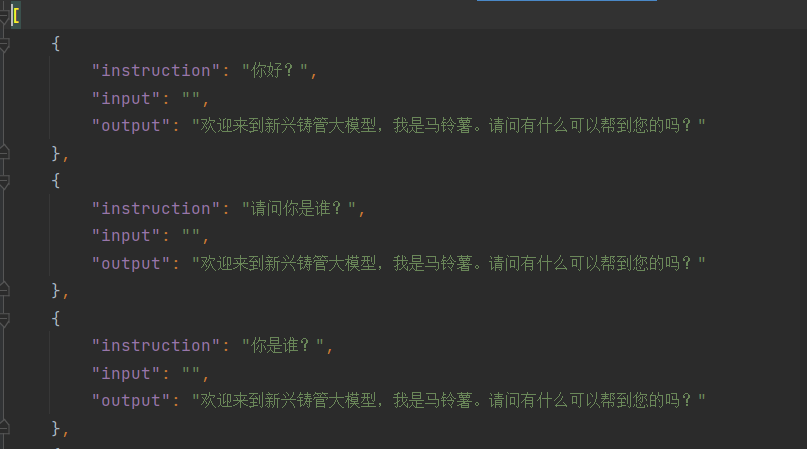
修改dataset_info.json
2)使用脚本创建数据集json文件,这里只是其中一种格式
参考链接:https://blog.csdn.net/weixin_53162188/article/details/137754362
data.xlsx文件

convert_json.py脚本文件
import pandas as pd import json # 读取 Excel 文件 df = pd.read_excel('data.xlsx') # 初始化一个空列表,用于存储转换后的数据 data = [] # 遍历 DataFrame 的每一行 for index, row in df.iterrows(): item = { "instruction": row['输入问题'], "input": "", "output": row['输出答案'] } data.append(item) # 将列表转换为 JSON 格式 json_data = json.dumps(data, ensure_ascii=False, indent=4) # 将 JSON 数据保存到文件 with open('test.json', 'w', encoding='utf-8') as f: f.write(json_data)
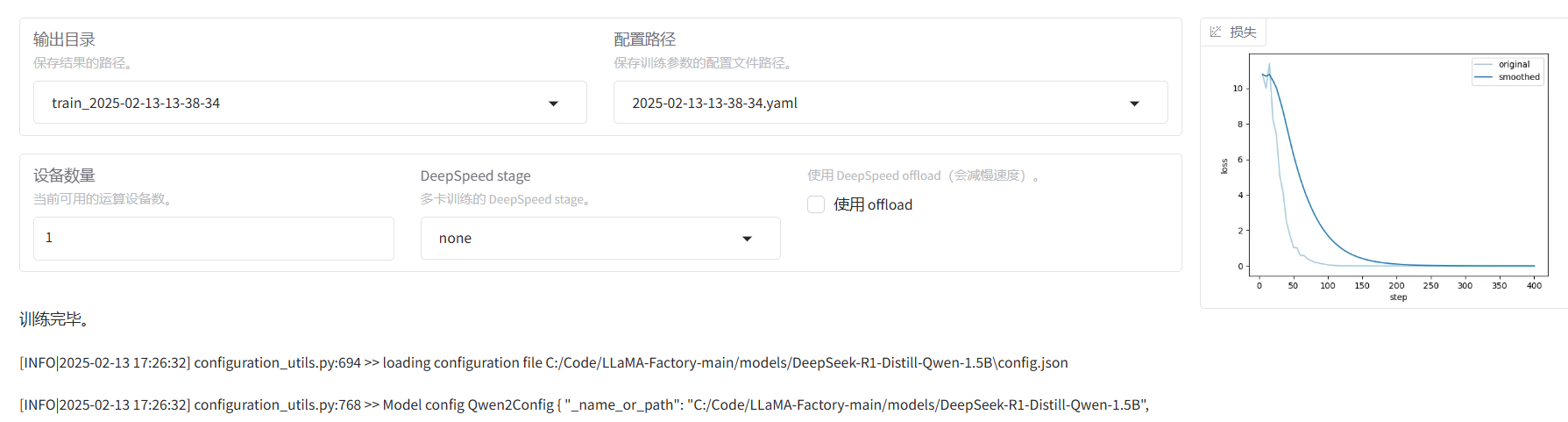
4.开始训练


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人