NMS和Soft-NMS的代码实现,数据可视化
这部分代码主要参考这位博主的讲解,原文链接:https://blog.csdn.net/AliceH1226/article/details/123429849
为什么要使用NMS
在目标检测中,模型输出的预测框数量往往远大于实际的真实框数量,并且是堆叠在一起的,非极大值抑制(Non-Maximum Suppression,NMS)可以从中筛选出符合要求的预测目标。因此,NMS通常往往作为目标检测中的后处理算法。
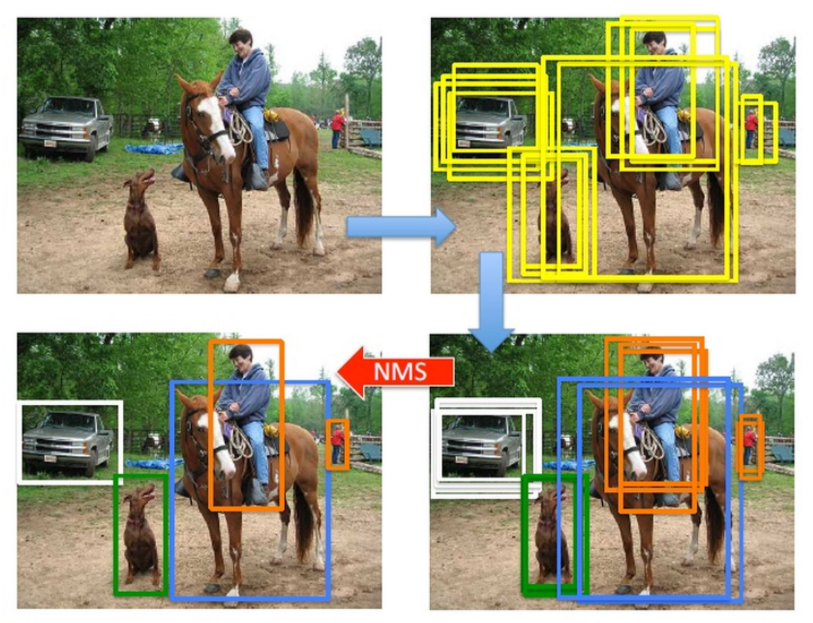
NMS算法流程
1> 根据检测框的置信度得分进行降序排序,选取分数最高的检测框A,
2> 分别计算检测框A与相邻检测框的重叠度IOU,对大于阈值的检测框得分直接置零,也就是扔掉;并标记将检测框A保留下来
3> 重复这个过程,找到所有被保留下来的检测框
Soft-NMS算法流程
1> 根据检测框的置信度得分进行降序排序,选取分数最高的检测框A,
2> 分别计算检测框A与相邻检测框的重叠度IOU,对大于阈值的检测框设置一个惩罚函数,降低这些检测框的置信度得分
3> 重复这个过程,找到所有被保留下来的检测框
import numpy as np import numpy as np import cv2 # 定义一个nms函数 def nms(boxes, threshold): x1 = boxes[:, 0] y1 = boxes[:, 1] x2 = boxes[:, 2] y2 = boxes[:, 3] scores = boxes[:, 4] areas = (x2 - x1 + 1) * (y2 - y1 + 1) keep = [] idxs = scores.argsort()[::-1] # 从大到下排序,argsort函数返回从小到大的索引,[::-1]反序变成从大到小 while (idxs.size > 0): i = idxs[0] keep.append(i) x11 = np.maximum(x1[i], x1[idxs[1:]]) y11 = np.maximum(y1[i], y1[idxs[1:]]) x22 = np.minimum(x2[i], y2[idxs[1:]]) y22 = np.minimum(y2[i], y2[idxs[1:]]) w = np.maximum(0, x22 - x11 + 1) h = np.maximum(0, y22 - y11 + 1) overlaps = w * h ious = overlaps / (areas[i] + areas[idxs[1:]] - overlaps) idxs2 = np.where(ious < threshold)[0] # np.where函数 idxs = idxs[idxs2 + 1] # 注意这个+1 return keep # 定义一个soft_nms函数 def soft_nms(dets, thresh=0.3, sigma=0.5): # score大于thresh的才能存留下来,当设定的thresh过低,存留下来的框就很多,所以要根据实际情况调参 ''' input: dets: dets是(n,5)的ndarray,第0维度的每个元素代码一个框:[x1, y1, x2, y2, score] thresh: float sigma: flaot output: index ''' x1 = dets[:, 0] # dets:(n,5) x1:(n,) dets是ndarray, x1是ndarray y1 = dets[:, 1] x2 = dets[:, 2] y2 = dets[:, 3] scores = dets[:, 4] # scores是ndarray # 每一个候选框的面积 areas = (x2 - x1 + 1) * (y2 - y1 + 1) # areas:(n,) # order是按照score降序排序的 order = scores.argsort()[::-1] # order:(n,) 降序下标 order是ndarray keep = [] while order.size > 0: i = order[0] # i 是当下分数最高的框的下标 # print(i) keep.append(i) # 计算当前概率最大矩形框与其他矩形框的相交框的坐标,会用到numpy的broadcast机制,得到的是向量 # 当order只有一个值的时候,order[1]会报错说index out of range,而order[1:]会是[],不报错,[]也可以作为x1的索引,x1[[]]为[] xx1 = np.maximum(x1[i], x1[order[1:]]) # xx1:(n-1,)的ndarray x1[i]:numpy_64浮点数一个,x1[order[1:]]是个ndarray,可以是空的ndarray,如果是空ndarray那么xx1为空ndarray,如果非空,那么x1[order[1:]]有多少个元素,xx1就是有多少个元素的ndarray。x1[]是不是ndarray看中括号内的是不是ndarray,看中括号内的是不是ndarray看中括号内的order[]的中括号内有没有冒号,有冒号的是ndarray,没有的是一个数。 yy1 = np.maximum(y1[i], y1[order[1:]]) xx2 = np.minimum(x2[i], x2[order[1:]]) yy2 = np.minimum(y2[i], y2[order[1:]]) # 计算相交框的面积,注意矩形框不相交时w或h算出来会是负数,用0代替 w = np.maximum(0.0, xx2 - xx1 + 1) # xx2-xx1是(n-1,)的ndarray,w是(n-1,)的ndarray, n会逐渐减小至1 # 当xx2和xx1是空的,那w是空的 h = np.maximum(0.0, yy2 - yy1 + 1) inter = w * h # inter是(n,)的ndarray # 当w和h是空的,inter是空的 # 计算重叠度IOU:重叠面积/(面积1+面积2-重叠面积) eps = np.finfo(areas.dtype).eps # 除法考虑分母为0的情况,np.finfo(dtype).eps,np.finfo(dtype)是个类,它封装了机器极限浮点类型的数,比如eps,episilon的缩写,表示小正数。 ovr = inter / np.maximum(eps, areas[i] + areas[order[1:]] - inter) # n-1 #一旦(面积1+面积2-重叠面积)为0,就用eps进行替换 # 当inter为空,areas[i]无论inter空不空都是有值的,那么ovr也为空 # 更新分数 weight = np.exp(-ovr*ovr/sigma) scores[order[1:]] *= weight # 更新order score_order = scores[order[1:]].argsort()[::-1] + 1 order = order[score_order] keep_ids = np.where(scores[order]>thresh)[0] order = order[keep_ids] return keep # 数据可视化 def plot(img,boxes,title): font = cv2.FONT_HERSHEY_SIMPLEX font_scale = 0.5 thickness = 1 for box in boxes: x1, y1, x2, y2, score = int(box[0]), int(box[1]), int(box[2]), int(box[3]), box[4] # x:col y:row (w, h), baseline = cv2.getTextSize(str(score), font, font_scale, thickness) cv2.rectangle(img, (x1, y1), (x2, y2), (0,255,0), 2) cv2.rectangle(img, (x1, y1 - (2 * baseline + 5)), (x1 + w, y1), (0, 255, 0), -1) cv2.putText(img, str(score), (x1, y1), font, font_scale, (0, 0, 0), thickness) cv2.imshow('demo', img) cv2.imwrite("{}.jpg".format(title), img) cv2.waitKey(0) if __name__=="__main__": # 读入图片,录入原始人框([x1, y1, x2, y2, score]) image = cv2.imread('person.jpg') boxes = np.array([[149,149,282,546, 0.9874], [116,103,303,565, 0.9356], [59,133,474,620, 0.8898]]) # 将预测框绘制在图像上 image_for_nms_box = image.copy() plot(image_for_nms_box,boxes,"Image") # 1.使用nms对预测框进行筛选 keep_1 = nms(boxes,threshold=0.3) nms_boxes = boxes[keep_1] # 将筛选过后的预测框绘制在图像上 image_for_nms_box = image.copy() plot(image_for_nms_box,nms_boxes,"NMS") # 2.使用soft_nms对框进行筛选 keep_2 = soft_nms(boxes) soft_nms_boxes = boxes[keep_2] # 将筛选过后的预测框绘制在图像上 image_for_nms_box = image.copy() plot(image_for_nms_box,soft_nms_boxes,"Soft_NMS") cv2.destroyAllWindows()




 浙公网安备 33010602011771号
浙公网安备 33010602011771号