17-多线程爬虫-实战多线程下载王者荣耀高清壁纸
实战多线程下载王者荣耀高清壁纸
1.网址:https://pvp.qq.com/web201605/wallpaper.shtml
2.查看网页源代码,发现腾讯将相关图片url信息转换成注释信息,猜测可能通过json动态添加,从Network找到存储高清壁纸文件(发现图片是用url编码的,需要用urllib.parse对获取到的url进行解码)
高清壁纸真实图片网址(workList_inc.cgi?) https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&jsoncallback=jQuery171018799755464476742_1619442228146&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1619442228321
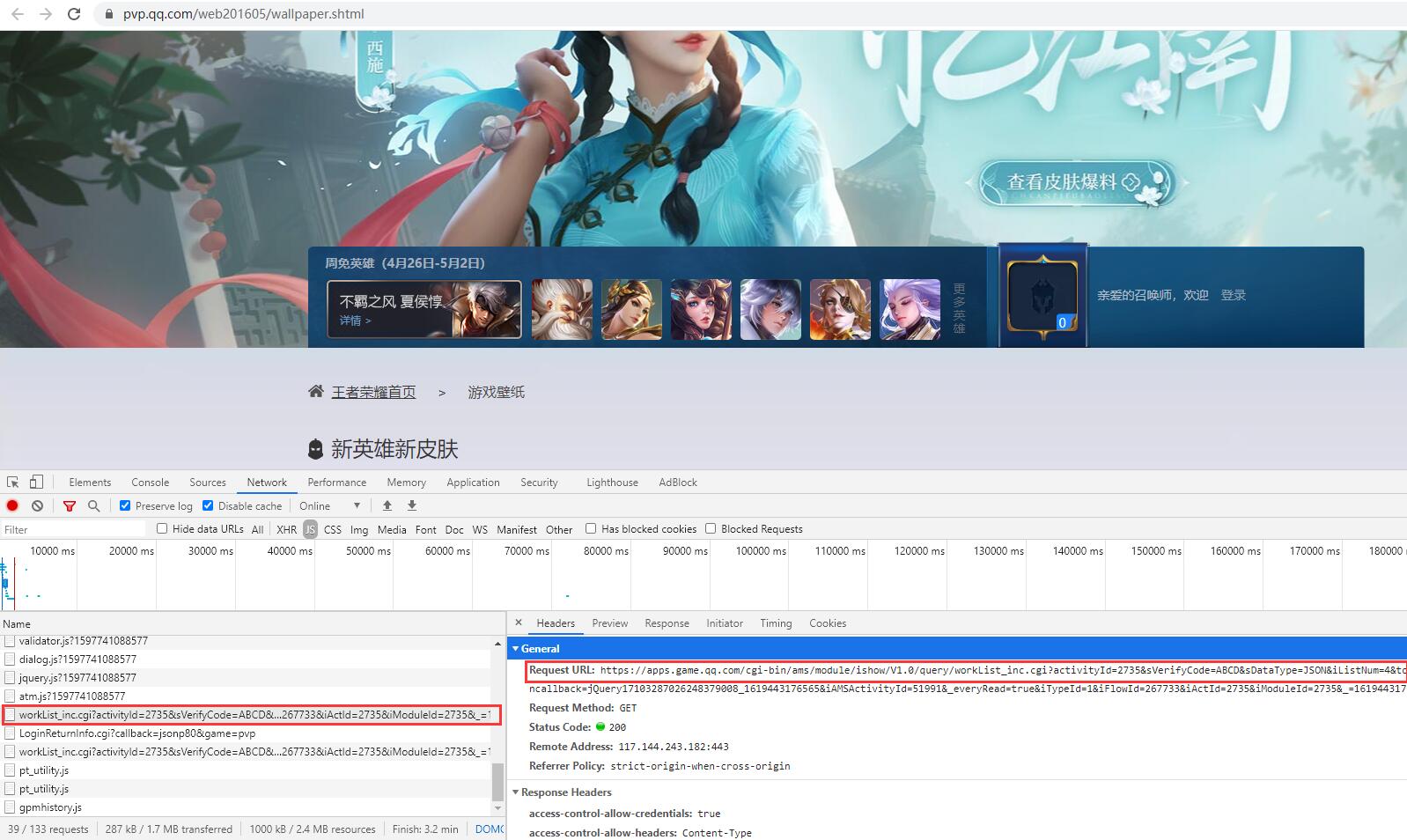
3.通过上面的json文件,获取到高清壁纸的url
4.获取到高清壁纸的url后,通过parse.unquote可以进行解码,然后将最后的/200变成/0,就可以得到真实的高清壁纸的图片了
5.获取图片的url的地址中有一个page参数,通过修改page的值,可以进行翻页。默认page是从0开始的
6.page最多只有25页,因此区间是[0,24]
一、实战多线程下载王者荣耀高清壁纸(单线程)
# 1.实战多线程下载王者荣耀高清壁纸(单线程) import requests from fake_useragent import UserAgent from urllib import parse import json import os user_agent = UserAgent() headers = { "User-Agent":user_agent.chrome, "referer":"https://pvp.qq.com/" } # 定义一个从右往左的rreplace替换函数 def rreplace(self, old, new, *max): count = len(self) if max and str(max[0]).isdigit(): count = max[0] return new.join(self.rsplit(old, count)) # 提取图片的url,并进行处理 def extract_images(data): image_urls = [] # 获取data里每个对象对应的八个高清壁纸url(需要用urllib.parse对获取到的url进行解码,并将/200转换为/0) for x in range(1,9): image_url = parse.unquote(data["sProdImgNo_{}".format(x)]) # 调用rreplace,从右向左进行替换将/200转换为/0 image_url = rreplace(image_url,"/200","/0",1) image_urls.append(image_url) return image_urls def main(): # 在程序开始前,获取F:\爬虫\第五章-多线程爬虫实战\images目录下所有文件夹名称,存储在列表中 name_list = os.listdir("F:\爬虫\第五章-多线程爬虫实战\images") print("请输入当前目录下,已经存在的王者荣耀高清皮肤文件夹:\n",name_list) # 高清壁纸真实图片网址 page = int(input("请输入要爬取的王者荣耀壁纸的第几页:"))-1 page_url = "https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page={}&iOrder=0&iSortNumClose=1&jsoncallback=jQuery171020290982002904112_1612592073295&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1612592073509".format(page) # 通过requests获取到json对象,获取url resp = requests.get(page_url,headers=headers) content = resp.content.decode("utf-8") # print(content) # 对获取到的cotent进行处理,去除前面的jQuery171036102371408234957_1612523399971()函数 index_1 = content.find("(") index_2 = content.find(")") content = content[index_1+1:index_2] # print(type(content)) # 利用json库,将python对象转化为json字符串(str -> 字典) # import json result = json.loads(content) # print(type(result)) # 获取result字典里面key为List的值(存放着对应皮肤的名字和图片) datas = result["List"] # 当前页面的每个皮肤名字,用列表存储 names = [] num = 1 for data in datas: # 调用,提取图片的url并进行处理 image_urls = extract_images(data) # 获取皮肤的名字(注意有些特殊符号,不能作为文件夹名字) name = parse.unquote(data["sProdName"]).replace("·", "-").replace(":", "-").strip() # print(name,image_urls) # 针对当前页面,有重复的名字,进行处理如澜CG《目标》2 if name not in names: names.append(name) else: num += 1 name = name+str(num) names.append(name) # 判断name是否在name_list,再决定是否创建 if name not in name_list: # 利用os库,在F:/爬虫/第五章-多线程爬虫实战/images创建文件夹,名字为name # import os path = "F:\爬虫\第五章-多线程爬虫实战\images" # 创建文件夹 path_name = os.path.join(path,name) os.mkdir(path_name) print("创建文件夹{}成功!".format(name)) # 在相应的文件夹中,创建图片文件,enumerate()同时返回数据下标和数据 for index,image_url in enumerate(image_urls): path_img = os.path.join(path_name,"{}.jpg".format(index+1)) # 下载文件,图片要以wb二进制的方式写入 with open(path_img,"wb") as f: # response.content返回的是bytes类型 content_img = requests.get(image_url,headers=headers).content f.write(content_img) print("正在写入高清壁纸{}...".format(path_img)) if __name__ == "__main__": main()
二、实战多线程下载王者荣耀高清壁纸(多线程)
# 2.实战多线程下载王者荣耀高清壁纸(多线程) import requests from fake_useragent import UserAgent from urllib import parse import json import os import threading import queue user_agent = UserAgent() headers = { "User-Agent":user_agent.chrome, "referer":"https://pvp.qq.com/" } # 生产者(获取队列中每一个page_url,已经创建皮肤名字的文件夹) class Producer(threading.Thread): def __init__(self,page_queue,image_queue,name_list,*args,**kwargs): # 调用父类的__init__函数 super(Producer,self).__init__(*args,**kwargs) self.page_queue = page_queue self.image_queue = image_queue self.name_list = name_list def run(self) -> None: # 当前线程的对象 the_thread = threading.current_thread() # 当page_queue队列不为空时,一直循环 while not self.page_queue.empty(): # 从队列中取出page_url page_url = self.page_queue.get() name_list = self.name_list # 通过requests获取到json对象,获取url resp = requests.get(page_url,headers=headers) content = resp.content.decode("utf-8") # print(content) # 对获取到的cotent进行处理,去除前面的jQuery171036102371408234957_1612523399971()函数 index_1 = content.find("(") index_2 = content.find(")") content = content[index_1+1:index_2] # print(type(content)) # 利用json库,将python对象转化为json字符串(str -> 字典) # import json result = json.loads(content) # print(type(result)) # 获取result字典里面key为List的值(存放着对应皮肤的名字和图片) datas = result["List"] # 当前页面的每个皮肤名字,用列表存储 names = [] num = 1 for data in datas: # 调用,提取图片的url并进行处理 image_urls = extract_images(data) # 获取皮肤的名字(注意有些特殊符号,不能作为文件夹名字) name = parse.unquote(data["sProdName"]).replace("·", "-").replace(":", "-").strip() # print(name,image_urls) # 针对当前页面,有重复的名字,进行处理如澜CG《目标》2 if name not in names: names.append(name) else: num += 1 name = name+str(num) names.append(name) # 判断name是否在name_list,再决定是否创建 if name not in name_list: # 利用os库,在F:/爬虫/第五章-多线程爬虫实战/images2创建文件夹,名字为name # import os path = "F:\爬虫\第五章-多线程爬虫实战\images2" # 创建文件夹 path_name = os.path.join(path,name) os.mkdir(path_name) print("当前线程{0}\t创建文件夹{1}成功!".format(the_thread.name,name)) # 将图片对应的image_url放入到image_queue队列中(字典类型,不仅传入image_url,还传入文件名) for index,image_url in enumerate(image_urls): image_path = os.path.join(path_name,"{}.jpg".format(index+1)) self.image_queue.put({"image_url":image_url,"image_path":image_path}) # 消费者(将王者荣耀高清壁纸下载) class Consumer(threading.Thread): def __init__(self,image_queue,*args,**kwargs): # 调用父类的__init__函数 super(Consumer,self).__init__(*args,**kwargs) self.image_queue = image_queue def run(self) -> None: # 当前线程的对象 the_thread = threading.current_thread() # 因为消费者和生产者进程同时开始,但由于生产者需要访问页面,导致消费者进程的img_queue队列一开始就是空的,需要一直循环执行 while True: try: # 获取图片对象,字典{"image_url":image_url,"image_path":image_path} # timeout = 10指的是img_queue队列十秒钟一直处于阻塞状态,抛出异常(当队列为空时,还进行get()操作,进程会发生阻塞) image_obj = self.image_queue.get(timeout = 10) image_url = image_obj.get("image_url") image_path = image_obj.get("image_path") # 下载文件,图片要以wb二进制的方式写入 with open(image_path,"wb") as f: # response.content返回的是bytes类型 content_img = requests.get(image_url,headers=headers).content f.write(content_img) print("当前线程{0}\t正在写入高清壁纸{1}...".format(the_thread.name,image_path)) except: # 获取到进程发生的异常,一般是生产者不再产生数据,消费者无法从空的img_queue队列获取数据 break # 定义一个从右往左的rreplace替换函数 def rreplace(self, old, new, *max): count = len(self) if max and str(max[0]).isdigit(): count = max[0] return new.join(self.rsplit(old, count)) # 提取图片的url,并进行处理 def extract_images(data): image_urls = [] # 获取data里每个对象对应的八个高清壁纸url(需要用urllib.parse对获取到的url进行解码,并将/200转换为/0) for x in range(1,9): image_url = parse.unquote(data["sProdImgNo_{}".format(x)]) # 调用rreplace,从右向左进行替换将/200转换为/0 image_url = rreplace(image_url,"/200","/0",1) image_urls.append(image_url) return image_urls def main(): # 在程序开始前,获取F:\爬虫\第五章-多线程爬虫实战\images2目录下所有文件夹名称,存储在列表中 name_list = os.listdir("F:\爬虫\第五章-多线程爬虫实战\images2") print("请输入当前目录下,已经存在的王者荣耀高清皮肤文件夹:\n",name_list) # 高清壁纸真实图片网址 page = int(input("请输入要爬取的王者荣耀壁纸的前几页:")) # 创建一个页面队列对象,大小为page(先进先出) page_queue = queue.Queue(page) # 创建一个图片队列对象,默认大小大一点(先进先出) image_queue = queue.Queue(1000) for x in range(page): page_url = "https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page={}&iOrder=0&iSortNumClose=1&jsoncallback=jQuery171020290982002904112_1612592073295&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1612592073509".format(x) # 往队列里放入page_url page_queue.put(page_url) # 创建三个生产者进程 for x in range(3): th = Producer(page_queue,image_queue,name_list,name="生产者{}".format(x+1)) th.start() # 创建三个消费者进程 for x in range(3): th = Consumer(image_queue,name="消费者{}".format(x+1)) th.start() if __name__ == "__main__": main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号