04-爬虫数据提取-XPath
什么是XPth?
xpath(XML Path Language)是一门在XML和HTML文档中查找信息的语言,可用来在XML和HTML文档中对元素和属性进行遍历
XPath开发工具:Chrome插件XPath Helper
XPath节点
在XPath中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。
XML文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。

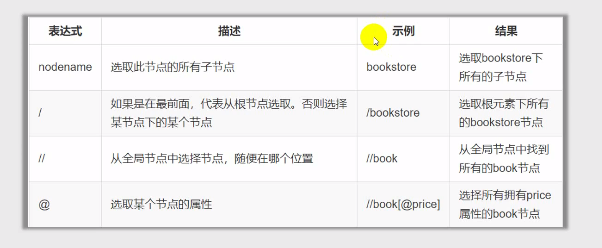
XPath语法:
XPath使用路径表达式来选取XML文档中的节点或节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
(这里需要弄清楚"//"和".//"的区别,前面代表从全部节点查找,后面代表从当前节点查找)
例如:获取所有属性class="name"的div标签
//div[@class="name"]
谓语:
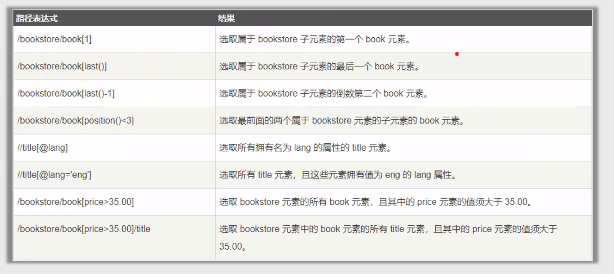
谓语用来查找某个特定的节点或者包含某个指定的值的节点,被嵌套在方括号中。
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果
例如:获取第一个div标签
//div[1]
通配符:
选取html下的所有子元素
/html/*
选取book所有属性元素
//book[@*]

选取多个路径:通过在路径表达式中使用"|"运算符,可以选取若干个路径
选取所有book元素以及book元素下的所有title元素
//bookstore/book | //book/title
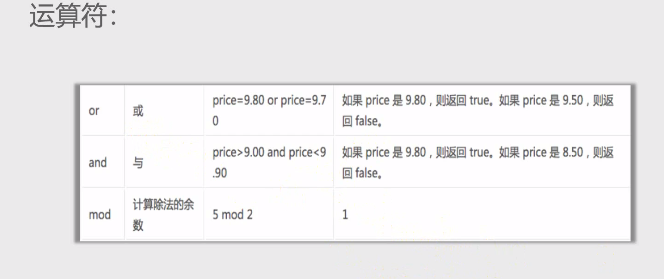
运算符:
拓展:
1.not的使用,当标签中不包含什么属性时,才进行获取
# 获取所有的li标签,而不包含class="item-0"
li_list = html.xpath("//li[not(@class='item-0')]")
2.contains:有时候某个属性中包含了多个值,那么可以使用contains函数
# 获取属性lang中包含”en“的title标签
//title[contains(@lang,"en")]
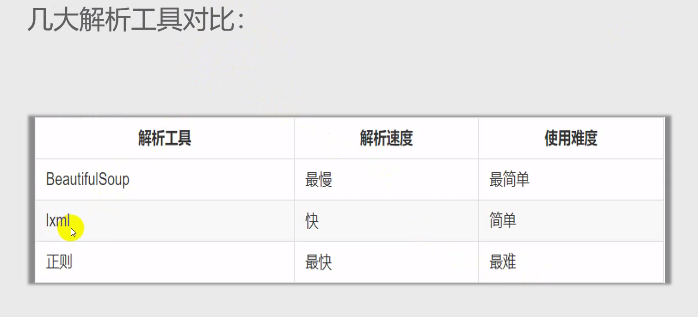
lxml库:
lxml是一个HTML/XML的解析器,主要的功能是如何解析和提取HTML/XML数据。
lxml库不是python自带的标准库,需要安装
pip install lxml
需要注意的是,上述方法都是通过Xpath+语法获取指定标签,但实际中我们可以需要获取标签的文本或者属性值
from lxml import etree text = """ <div> <ul> <li class="item-0"><a href="link1.html">first item</li> <li class="item-1"><a href="link2.html">second item</li> <li class="item-inactive"><a href="link3.html">third item</li> <li class="item-1"><a href="link4.html">fourth item</li> <li class="item-0"><a href="link5.html">fifth item</li> </ul> </div> """ # 将字符串解析为html文档 html = etree.HTML(text) print(html) # 按字符串序列化html文档(bytes类型转换为utf-8) result = etree.tostring(html) print(result.decode("utf-8")) # 1.获取第一个class属性值为"item-1"的li标签 li_tag = html.xpath("//li[@class='item-1']")[0] print("\n第一个li标签:",etree.tostring(li_tag).decode("utf-8")) # 2.获取第一个li标签的class属性 # "./"和".//"代表从当前节点查找 print("获取第一个li标签的class属性") li_class_1 = li_tag.get("class") print(li_class_1) li_class_2 = li_tag.xpath("./@class")[0] print(li_class_2) li_class_3 = html.xpath("//li[@class='item-1']/@class")[0] print(li_class_3) # 3.获取第一个li标签下的a标签,里面的文本 # "./"和".//"代表从当前节点查找 print("\n获取第一个li标签下的a标签,里面的文本") content_1 = li_tag.xpath("./a/text()")[0] print(content_1) content_2 = li_tag.xpath("./a")[0].text print(content_2) content_3 = html.xpath("//li[@class='item-1']/a/text()")[0] print(content_3) content_4 = html.xpath("//li[@class='item-1']/a")[0].text print(content_4) # 4.获取所有的li标签,而不包含class="item-0" li_list = html.xpath("//li[not(@class='item-0')]") print(li_list)
这里需要强调的是,XPath解析和提取HTML/XML数据的功能是十分强大的
1.使用etree.HTML(),将字符串解析为HTML文档,进行XPath提取
from lxml import etree text = """ <div> <ul> <li class="item-0"><a href="link1.html">first item</li> <li class="item-1"><a href="link2.html">second item</li> <li class="item-inactive"><a href="link3.html">third item</li> <li class="item-1"><a href="link4.html">fourth item</li> <li class="item-0"><a href="link5.html">fifth item</li> </ul> </div> """ # 将字符串解析为html文档 html = etree.HTML(text) # 按字符串序列化html文档(bytes类型转换为utf-8) result = etree.tostring(html) # 获取第一个class属性值为"item-1"的li标签 li_tag = html.xpath("//li[@class='item-1']")[0] print("\n第一个li标签:",etree.tostring(li_tag).decode("utf-8"))
2.使用etree.parse(),读取本地的html文档
from lxml import etree # 使用etree.parse()读取 F:\爬虫\第三章-xpath库\hello.html文档 html = etree.parse("F:/爬虫/第三章-xpath库/hello.html") # 查看内容 result = etree.tostring(html).decode("utf-8") # print(result) # 获取li标签下,属性为href='link3.html'的a标签(获取的是标签) tag_1 = html.xpath("//li/a[@href='link3.html']")[0] print(etree.tostring(tag_1).decode("utf-8")) # 获取所有li的a的href属性对应的值(获取的是对应属性的值) tag_2 = html.xpath("//li/a/@href") print(tag_2)
3.通过requests,获取网页源代码html文档(即通过requests将网页源代码保存为第1种形式,再进行XPath提取)
import requests # 导入伪造User-Agent库 from fake_useragent import UserAgent # 导入lxml库,使用XPath进行提取 from lxml import etree url = "https://www.baidu.com/" # 添加请求头 user_agent = UserAgent() headers = { "User-Agent":user_agent.chrome } response = requests.get(url,headers=headers) content = response.content.decode("utf-8") html = etree.HTML(text) # 获取div标签下的文本,百度知道 tag = html.xpath("//div[contains(@class,'title-text')]/text()") print(tag)
实战-爬取瓜子二手车(利用requests)
# 对爬取瓜子二手车网站,进行封装 import requests from lxml import etree import csv import pandas as pd import time # 使用列表存储总数据 result_datas = [] class GuaZi(): def __init__(self): pass # 获取详情页面url def get_detail_urls(self,url,headers): response = requests.get(url,headers=headers) text = response.content.decode("utf-8") html = etree.HTML(text) result = html.xpath("//ul[@class='carlist clearfix js-top']/li/a/@href") detail_urls = [] for x in result: detail_url = "https://www.guazi.com"+x detail_urls.append(detail_url) return detail_urls # 将xpath获取到的数据进行处理 def get_deal_data(self,data): initial_data = "" for x in data: initial_data += x return initial_data.replace(r"\r\n","").strip() # 解析详情页面内容 def parse_detail_url(self,detail_url,headers): response = requests.get(detail_url,headers=headers) text = response.content.decode("utf-8") html = etree.HTML(text) # 获取标题内容 result_title = html.xpath("//div[@class='product-textbox']/h1/text()") # 调用get_deal_data()函数,对用xpath获取到的标题数据进行处理 result_title = GuaZi.get_deal_data(self,result_title) result_data["标题"] = result_title # 获取每一个li属性的class num = html.xpath("//ul[@class='basic-eleven clearfix']/li/@class") # 获取车辆详情内容 for x in num: data_key = html.xpath("//ul[@class='basic-eleven clearfix']/li[@class='{}']/text()".format(x)) # 调用get_deal_data()函数,对用xpath获取到的data_key进行处理 data_key = GuaZi.get_deal_data(self,data_key) data_value = html.xpath("//ul[@class='basic-eleven clearfix']/li[@class='{}']/div/text()".format(x)) # 调用get_deal_data()函数,对用xpath获取到的data_value进行处理 data_value = GuaZi.get_deal_data(self,data_value) result_data[data_key] = data_value return result_data def main(self): print("---------------欢迎使用瓜子二手车爬虫小程序-------------------") # 1.创建文件对象(newline=""消除多余空行,添加ignore忽略报错) f = open(r"F:/爬虫/第三章-xpath库/南昌二手车.csv","a",encoding="gbk",newline="",errors="ignore") # 2.第一个url,瓜子二手车网站中的南昌二手车 page = int(input("请输入要爬取瓜子二手车网站中,南昌二手车的第多少页:")) url = "https://www.guazi.com/nc/buy/o{}".format(page) headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36", "Cookie":"track_id=166177713727074304; uuid=eae00602-90e9-4c00-dfac-a60eccf72976; ganji_uuid=4092458132253975552378; lg=1; antipas=1h8O019h09840H243X554ltS4Ap; clueSourceCode=%2A%2300; sessionid=b0601c17-e5cc-4df7-cdff-77a8973d8668; Hm_lvt_bf3ee5b290ce731c7a4ce7a617256354=1610775054,1610775070,1611110074; cainfo=%7B%22ca_a%22%3A%22-%22%2C%22ca_b%22%3A%22-%22%2C%22ca_s%22%3A%22seo_baidu%22%2C%22ca_n%22%3A%22default%22%2C%22ca_medium%22%3A%22-%22%2C%22ca_term%22%3A%22-%22%2C%22ca_content%22%3A%22%22%2C%22ca_campaign%22%3A%22%22%2C%22ca_kw%22%3A%22-%22%2C%22ca_i%22%3A%22-%22%2C%22scode%22%3A%22-%22%2C%22keyword%22%3A%22-%22%2C%22ca_keywordid%22%3A%22-%22%2C%22ca_transid%22%3A%22%22%2C%22platform%22%3A%221%22%2C%22version%22%3A1%2C%22track_id%22%3A%22166177713727074304%22%2C%22display_finance_flag%22%3A%22-%22%2C%22client_ab%22%3A%22-%22%2C%22guid%22%3A%22eae00602-90e9-4c00-dfac-a60eccf72976%22%2C%22ca_city%22%3A%22nc%22%2C%22sessionid%22%3A%22b0601c17-e5cc-4df7-cdff-77a8973d8668%22%7D; close_finance_popup=2021-01-20; user_city_id=214; preTime=%7B%22last%22%3A1611110155%2C%22this%22%3A1610775054%2C%22pre%22%3A1610775054%7D; _gl_tracker=%7B%22ca_source%22%3A%22-%22%2C%22ca_name%22%3A%22-%22%2C%22ca_kw%22%3A%22-%22%2C%22ca_id%22%3A%22-%22%2C%22ca_s%22%3A%22self%22%2C%22ca_n%22%3A%22-%22%2C%22ca_i%22%3A%22-%22%2C%22sid%22%3A38391528579%7D; Hm_lpvt_bf3ee5b290ce731c7a4ce7a617256354=1611110511; cityDomain=nc", "Host":"www.guazi.com", "Referer":"https://www.guazi.com/cs/buy/" } # 3.调用,获取详情页面url detail_urls = GuaZi.get_detail_urls(self,url,headers) count = 0 # 4.解析详情页面的内容 for detail_url in detail_urls: count +=1 # 使用字典存储详情页面每一条车辆的内容信息(global全局变量) global result_data result_data = {} # 调用,解析详情页面内容 print("正在解析瓜子二手车网站中,南昌二手车的第{0}页的第{1}条数据...".format(page,count)) result_data = GuaZi.parse_detail_url(self,detail_url,headers) result_datas.append(result_data) # time.sleep()推迟调用线程的运行 time.sleep(1) # 5.保存数据(csv文件) count = 0 for data in result_datas: count +=1 all_keys = data.keys() all_values = data.values() # print("正在下载瓜子二手车网站中,南昌二手车的第{0}页的第{1}条数据...".format(page,count)) # 基于文件对象构建 csv写入对象 csv_writer = csv.writer(f) # 构建列表头(只进行一次) if count ==1: csv_writer.writerow(all_keys) # 写入csv文件内容 csv_writer.writerow(all_values) # 6.关闭文件 f.close() print("下载完成!") # 7.打开保存的文件 file = open(r"F:/爬虫/第三章-xpath库/南昌二手车.csv") file_data = pd.read_csv(file) print(file_data) file.close() if __name__ == "__main__": guazi = GuaZi() guazi.main()
