02-爬虫基本库-urllib库
urllib库
urllib库是Python中最基本的网络请求库,可以模拟浏览器的行为,向指定的服务器发送一个请求,并可以保存服务器返回的数据
注意:urllib是python自带的标准库,无需安装,直接可以用
一、基本函数详解
1.urlopen函数详解:创建一个表示远程url的类文件对象,然后像本地文件一样操作这个类文件对象来获取远程数据
1>.url:请求的url
2>.data:请求的data,如果设置了这个值,那么将变成post请求
3>.返回值:返回值是一个http.client.HTTPResponse对象,这对象是一个类文件句柄对象。有read(size),readline,readlines以及getcode等方法
# 在python3的urllib库中,所有和网络请求相关的方法,就被集到urllib.request模块 from urllib.request import urlopen url = "http://www.baidu.com/" # 发送内容 response = urlopen(url) # 读取内容,并转码(将bytes类型转换位utf-8) content = response.read().decode("utf-8") # 打印内容 # print(content) # 打印状态码 print("打印状态码:",response.getcode()) # 打印真实url print("打印真实url:",response.geturl()) # 打印响应头 print("打印响应头:",response.info())
2.urlretrieve函数:这个函数可以方便的将网页上的一个文件保存到本地。以下代码可以将百度的首页下载到本地
需要注意的是,这个方法不能添加请求头,也就是说如果网站有反爬措施,将会受到影响
from urllib.request import urlretrieve url = "http://www.baidu.com/" save_path = "F:/爬虫/第二章-爬虫基本库/baidu.html" urlretrieve(url,save_path)
二、请求(get和post)
from urllib import request # 导入伪造User-Agent库 from fake_useragent import UserAgent # 请求头 user_agent = UserAgent() headers = { "User-Agent":user_agent.chrome } # get请求 url = "https://www.baidu.com/" rq = request.Request(url,headers = headers) response = request.urlopen(rq) # 打印响应的内容 content = response.read().decode("utf-8") print(content)
2.post请求:向服务器发送数据(登录)、上传文件等,会对服务器资源产生影响的时候,会使用post请求
# 发送post请求,模拟登录百度贴吧 from urllib import request # 导入parse.urlencode可以把字典数据转化位URL编码的数据 from urllib import parse # 导入伪造User-Agent库 from fake_useragent import UserAgent # 登录url(post请求) post_url = "https://passport.baidu.com/v2/api/?login" # 表单数据(使用urlencode转码) args = { "username":"15798017910", "password":"ExCK7PIdLq3CyPdOJUQ+YK/mrTIFEvbIWK1tQd+XDBMR2lgpH1Ri9CyhOfX67/DW4Y/9JlFtFYUyqn7enNVAvdSvQ+nflejVX1xMtiOYNeZzUG9u/ZuB0uqqZjYmC+/egHrYd6Jys2b3AjX0JDrcRrnx3zCoksAXZMvx6iu/L38=" } post_data = parse.urlencode(args) # 请求头 user_agent = UserAgent() headers = { "User-Agent":user_agent.chrome, }
# 需要注意的是,之前表单数据通过urlcode转码后,后续需要再使用encode编码,将post_data字符串类型转变为字节类型
# encode()方法以指定的编码格式编码字符串(返回byte类型) rq = request.Request(post_url,headers=headers,data=post_data.encode("utf-8")) resp = request.urlopen(rq) content = resp.read().decode("utf-8") print(content)
拓展:上述post请求中,我们用到了parse.urlencode()用于转化为URL编码
1.urlencode函数(编码):urlencode可以把字典数据转化位URL编码的数据
# url = "https://tieba.baidu.com/f?kw=尚学堂&ie=utf-8" content = input("请输入要查询的贴吧内容:") args = { "ie":"utf-8", "kw":content } url = "https://tieba.baidu.com/f?{}".format(urlencode(args))
2.quote函数(编码):quote可以把字符串转化为URL编码的数据
# url = "https://tieba.baidu.com/f?kw=尚学堂&ie=utf-8" content = input("请输入要查询的贴吧内容:") url = "https://tieba.baidu.com/f?kw={}&ie=utf-8".format(quote(content)) print("生成的url:",url)
三、代理IP(ProxyHandler处理器,解决封ip问题)
ProxyHandler处理器(解决封ip问题)
代理原理:在请求目的网站之前,先请求代理服务器,然后让代理服务器去请求目的网站,代理服务器拿到目前的网站的数据后,再转发给我们的代码
很多网站会检测某一时间某个IP的访问次数(通过流量统计,系统日志等),如果访问的次数多的不像正常人,它会禁止这个IP的访问
http://httpbin.org :查看http请求的一些参数
1.查看客户端向服务端发送的User-Agent:
http://httpbin.org/user-agent
2.查看客户端向服务端发送的IP地址:
http://httpbin.org/ip
目前我们常用的代理:至流科技
http://www.zhuzhaiip.com/
# 代理的原理:在请求目的网络之前,先请求代理服务器,然后让代理服务器去请求目的网站,代理服务器拿到目的网站的数据后,再转发给我们的代码 # 我们这里使用至流科技来购买代理ip,http://www.zhuzhaiip.com/#/index from urllib import request from lxml import etree from fake_useragent import UserAgent url = "http://httpbin.org/ip" user_agent = UserAgent() headers = { "User-Agent":user_agent.chrome } # 对获取到的数据进行处理 def get_deal_ip(data): ip = data[0].replace("\n","").strip().split('"')[3] return ip # 1.没有使用代理 rq = request.Request(url,headers= headers) resp = request.urlopen(rq) data = resp.read().decode("utf-8") # 使用xpath提取ip内容 data_content = etree.HTML(data) data_ip = data_content.xpath("//body//text()") ip = get_deal_ip(data_ip) print("没有使用代理时IP为:",ip) # 2.使用代理 # 使用ProxyHandler,传入代理构建一个handler handler = request.ProxyHandler({"http":"182.106.136.81:41480"}) # 使用上面创建好的handler去构建一个opener opener = request.build_opener(handler) rq = request.Request(url,headers=headers) # 使用opener去发送一个请求 resp = opener.open(rq) data = resp.read().decode("utf-8") # 使用xpath提取内容 data_content = etree.HTML(data) data_ip = data_content.xpath("//body//text()") ip = get_deal_ip(data_ip) print("正在使用代理时IP为:",ip)
四、Cookie
什么是cookie:
是指某些网站为了辨别用户身份、进行跟踪二存储再用户本地终端上的数据,cookie存储的数据量有限,不同的游览器有不同的存储大小,但一般不超过4KB。因此使用cookie只能存储一些小量的数据
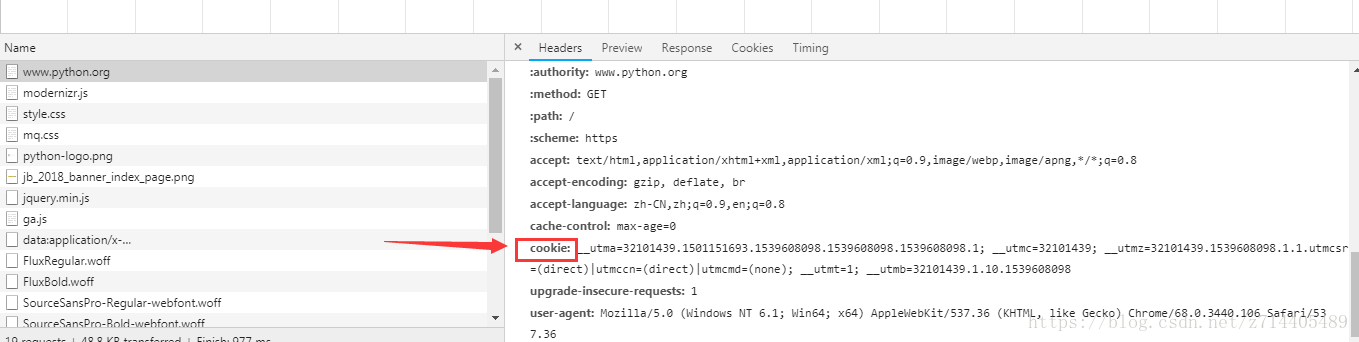
当一个用户user对服务器进行请求时:
1>第一次请求,服务器发现没有id,分配给用户user一个id = 1
2>第二次请求,用户user带上cookie中的id = 1, 服务器看到id是1,取出1的信息
cookie的格式:
Set-Cookie:NAME=VALUE;Expires/Max-age=DATE;Path=PATH;Domain=DOMAIN_NAME;SECURE
参数意义:
NAME:cookie的名字
VALUE:cookie的值
Expires:cookie的过期时间
Path:cookie作用的路径
Domain:cookie作用的域名
SECURE:是否只在https协议下起作用
Request Headers请求头的Cookie,它表示的是http请求报文通过Cookie字段通知我们的服务端(给服务端通知的数据)
Response Headers响应头的Set-Cookie,它指的是http响应报文通过Set-Cookie通知我们的客户端,需要保存的cookie数据(通知客户端保存数据)
在爬虫时,爬取一些需要登录认证的网页,如何解决使用cookie模拟登录
1.第一种解决方案,用浏览器访问,将浏览器中Request Headers请求头的Cookie信息保存下来,放到我们的请求头
2.第二种解决方法:http.cookiejar模块(类似于ProxyHandler代理)
该模块主要的类有CookieJar、fileCookieJar、MozillaCookieJar、LWPCookieJar.
1>.CookieJar:管理HTTP cookie值、存储HTTP请求生成的cookie、向传出的HTTP请求添加cookie的对象。整个cookie都存储在内存中,对CookieJar实例进行垃圾回收后cookie也将丢失
2>.FileCookieJar(filename,delayload=None,policy=None):从CookieJar派生而来,用来创建FileCookieJar实例,检索cookie信息,并将cookie存储到文件中。
filename是存储cookie的文件名。delayload为True时支持延迟访问访问文件,即只有在需要时才读取文件或在文件中存储数据
3>.MozillaCooklieJar(filename,delayload=None,policy=None):从FileCookieJar派生而来,创建与Mozilla游览器cookies.txt兼容的FileCookieJar实例
4>.LWPCookieJar(filename,delayload=None,policy=None):从FileCookieJar派生而来,创建与libwww-perl标准的Set-Cookie3文件格式兼容的FileCookieJar实例
注意:request.ProxyHandler()是代理IP,request.HTTPCookieProcessor()是代理Cookie
# 练习1,使用cookiejar模拟登录百度贴吧 from urllib import request from urllib import parse from http.cookiejar import CookieJar from fake_useragent import UserAgent # 1.登录,获取cookie # 1.1创建cookiejar对象 cookiejar = CookieJar() # 1.2使用cookiejar创建一个HTTPCookieProcess对象 handler = request.HTTPCookieProcessor(cookiejar) # 1.3使用上一步创建的handler创建一个opener opener = request.build_opener(handler) # 登录url(post请求) post_url = "https://passport.baidu.com/v2/api/?login" # 表单数据(使用urlencode转码) args = { "username":"15798017910", "password":"ExCK7PIdLq3CyPdOJUQ+YK/mrTIFEvbIWK1tQd+XDBMR2lgpH1Ri9CyhOfX67/DW4Y/9JlFtFYUyqn7enNVAvdSvQ+nflejVX1xMtiOYNeZzUG9u/ZuB0uqqZjYmC+/egHrYd6Jys2b3AjX0JDrcRrnx3zCoksAXZMvx6iu/L38=" } post_data = parse.urlencode(args) # 注意,需要将post_data字符串类型转变为字节类型 rq = request.Request(post_url,data=post_data.encode("utf-8")) # 使用opener发送登录请求(账号和密码),访问登录页面 resp = opener.open(rq) # print(resp.read().decode("utf-8")) # 2.访问个人网页 # 个人url url = "https://tieba.baidu.com/index.html" user_agent = UserAgent() headers = { "User-Agent":user_agent.chrome, } rq2 = request.Request(url,headers=headers) # 使用opener再次发送请求,访问个人网页 resp2 = opener.open(rq2) print(resp2.read().decode("gbk"))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号