

DBMS-存储和文件结构
物理存储介质概述
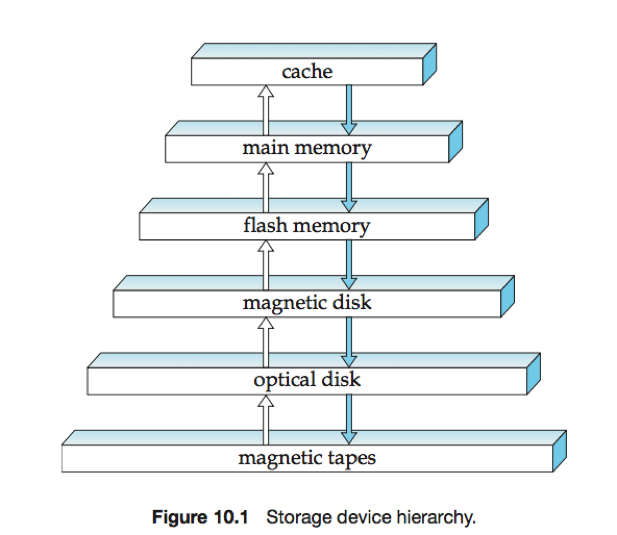
存储介质的层次越高,成本越贵,速度越快。
基本存储(primary storage):最快的存储介质,如高速缓冲存储器cache和主存储器main memory;
辅助存储(secondary storage)/联机存储(online storage): 如磁盘(magnetic disk);
三级存储(tertiary storage)/脱机存储(offline storage):如磁带机(magnetic tapes)和自动光盘机(optical disk)。
易失性存储(volatile storage):在设备端点后将丢失所有内容。在存储介质层次结构中,从main memory向上的存储系统都是易失性存储,主存储器之下的存储都是非易失性存储。
磁盘和快闪存储器
1. 磁盘的物理特性
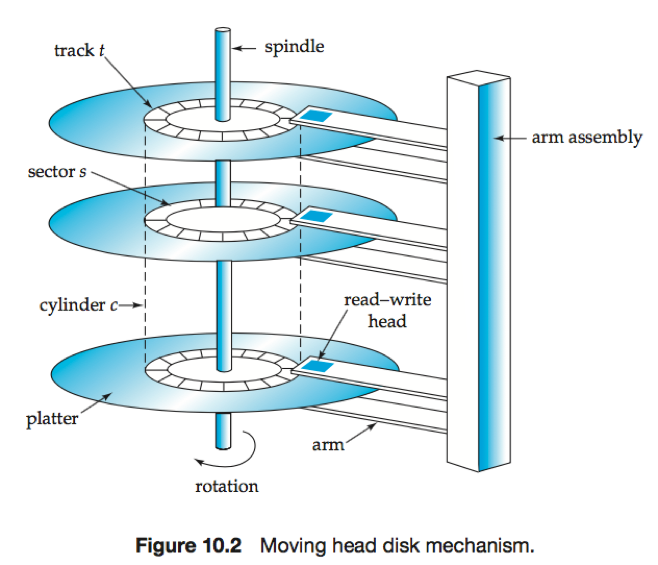
盘片(platter):表面覆盖磁性物质的扁平圆盘,一个磁盘通常包括多个盘片;
磁道(track):盘片表面从逻辑上划分为磁道,外侧磁道长度较大,比内侧磁道拥有更多扇区;
扇区(sector): 从磁盘读出和写入信息的最小单位;
读写头(read-write head):用于将信息磁化存储到扇区。每个盘片的每个面都有一个读写头,在盘片上移动以访问不同磁道;
磁盘臂(disk arm):所有磁道的读写头安装在一个磁盘臂上并一起移动;
磁头-磁盘装置(head-disk assembly):安装在转轴上的所有磁盘盘片和安装在磁盘臂上的所有读写头的统称;
柱面(cylinder):因为所有盘片上的读写头一起移动,所以当某一个盘片的读写头在第i条磁道上时,所有其他盘片的读写头也都在各自盘片的第i条磁道上。所有盘片的第i条磁道合在一起成为第i个柱面。
磁盘控制器(disk controller):计算机系统和实际磁盘驱动器硬件之间的接口,在磁盘驱动单元内部实现。
2. 磁盘性能的度量
磁盘质量的主要度量指标:容量、访问时间、数据传输率和可靠性。
访问时间(access time):从发出读写请求到数据开始传输之间的时间。访问时间是寻道时间和旋转等待时间的总和;
寻道时间(seek time):为访问磁盘上指定扇区的数据,磁盘臂重定位(移动以定位正确磁道)的时间。依赖于目的刺刀距离磁盘臂的初始距离,随磁盘臂移动距离的增大而增大;
平均寻道时间(average seek time):寻道时间的平均值,通过在一个均匀分布的随机请求序列上计算得到;
旋转等待时间(rotational latency time):读写头到达所需磁道后等待磁盘旋转直到访问的指定扇区出现在读写头下的时间。磁盘的平均旋转等待时间是磁盘旋转一周时间的1/2;
数据传输率(data-transfer rate):从磁盘获得数据或向存盘存储数据的速率。对于磁盘的内侧磁道,数据传输率明显低于最大传输率;
平均故障时间(Mean Time To Failure, MTTF):平均可期望系统无故障连续运行的时间量,是磁盘可靠性的度量标准。
存储介质的可靠性由两个因素决定:电源故障或系统崩溃是否导致数据丢失,存储设备发生物理故障的可能性有多大。
3. 磁盘块访问的优化
块(block):数据在磁盘和主存储器之间以块为单位传输。一个块是一个逻辑单元,包含固定数目的连续扇区。
来自磁盘的连续请求可分为顺序访问模式或随机访问模式:
顺序访问(sequential access)模式:连续的请求会请求与处于相同或相邻磁道上连续的块;
随机访问(random access)模式:相继的请求会请求随机位于磁盘上的块,每次请求都需要一次磁盘寻道,数据传输率明显低于顺序访问模式。
提高访问块速度可采用的技术:
·缓冲(buffering):从磁盘读取的块暂时存储在内存缓冲区中,以满足将来的要求;
·预读(read-ahead):当一个磁盘块被访问时,相同磁道的连续块也被读入内存缓冲区找那个,即使没有针对这些块的即将来临的请求;(顺序访问模式下可减少块的访问时间)
·调度(scheduling):如果所需的块在同一柱面上,可按块经过读写头的顺序发出访问块的请求;如果所需的块在不同柱面上,按照使磁盘臂移动最短距离的顺序发出访问块的请求。
磁盘调度算法(disk-arm-scheduling)将对磁道的访问按能增加可以处理的访问数量的方式排序。
·文件组织(file organization):按与预期数据的访问方式最接近的方式来组织磁盘上的块以减少块的访问时间;
非易失性写缓冲区(nonvolatile write buffer):可使用非易失性随机访问存储器(NonVolatile Random-Access Memory, NV-RAM)加速写磁盘操作,NV-RAM的内容在发生电源故障时不会丢失。
·日志磁盘(log disk):一种专门用于写顺序日志的磁盘,对日志磁盘的所有访问都是顺序的。支持日至磁盘的文件系统称作日志文件系统(journaling file system)。
4. 快闪存储
快闪存储器(flash memory)可分为两种:NOR快闪和NAND快闪。
NOR快闪:允许随机访问闪存中的单个字,速度快;
NAND快闪:读取时需要将整个数据页取到主存储器中,比NOR快闪便宜、存储容量高,采用NAND快闪构建的存储系统提供与磁盘存储器相同的面向块的接口。
擦除块(erase block):写入时闪存的页面不能直接覆盖,必须先擦除再重写,一次擦除操作可在多个页面执行,称为擦除块。
一个擦除块的大小通常明显比存储系统的块大很多;
一个闪存页的可擦除次数存在限制,闪存存储器适合缓存频繁访问但很少更新的数据;
闪存系统通过映射逻辑页码到物理页码,限制了慢擦除速度和更新限制的影响。逻辑页更新时刻重新映射到任何已擦除的物理页,原来的位置标记为已删除,可随后擦除。
每个物理也都有一个小的存储区域以保存其逻辑地址。逻辑到物理页面的映射被复制到内存的转换表(translation table)中。
损耗均衡(wear leveling):在物理块中均匀分布擦除操作的原则。包含多个删除页面的块将会定期清除,并注意先复制这些块中未删除的页面到其他块(并在转换表中进行更新),擦除多次的物理页面被标记为很少更新的“冷数据”,没有擦除多次的页用于存储频繁更新的“热数据”。
所有上述动作通过闪存转换层(flash translation layer)完成,这一层上提供与磁盘存储器相同的面向页/扇区的接口。
混合硬盘驱动器(hybrid disk drive):结合了小容量闪存存储器的硬盘系统,对频繁访问的数据作为缓存使用。
磁盘和快闪存储器
独立磁盘冗余阵列(Redundant Array of Independent Disk, RAID)多种磁盘组织技术具有高可靠性和执行效率,并且易于管理和操作。
RAID通过把数据拆分到多张磁盘上,可以提高大数据量访问的吞吐率;通过引入多张磁盘上的冗余存储,可以显著提高可靠性。
1. 通过冗余提高可靠性
冗余(redundancy):解决可靠性问题的方法,存储正常情况下不需要的额外信息,可在磁盘故障时用于重建丢失的信息。
镜像(mirroring):实现冗余最简单、昂贵的方法,一张逻辑磁盘由两张逻辑磁盘组成,每一次写操作都要在两张磁盘上执行。采用镜像技术的磁盘的平均故障时间依赖于单张磁盘的平均故障时间和平均修复时间。
平均修复时间(mean time to repair):替换发生故障的磁盘并且恢复这张磁盘上的数据所花费的平均时间。
对于磁盘镜像,如果正在对两张磁盘上相同的块进行写操作时发生电源故障问题,可能导致两个块处于不一致的状态。
解决办法:先写一个拷贝,再写另外一个,保证两个拷贝中有一个总是一致的,并在电源重新启动后做一些额外的动作以从不完全的写操作中恢复。
2. 通过并行提高性能
磁盘系统中并行的两个主要目的:
1)负载平衡多个小的访问操作(块访问),以提高这种访问操作的吞吐量;
2)并行执行大的访问操作,以减少大访问操作的响应时间。
可通过在多张磁盘上进行数据拆分(striping data)来提高传输速率。
比特级拆分(bit-level striping):数据拆分的最简单形式,将每个字节按比特分开,存储到多个磁盘上。
块级拆分(block-level striping):将磁盘阵列看做一张单独的大磁盘,将块拆分到多张磁盘并对块进行逻辑编号。
设块的逻辑编号从0开始,对于n张磁盘的阵列,块级拆分将磁盘阵列逻辑上第i个块存储到第(i mod n)+1张磁盘上(即用第[i/n]个物理块存储逻辑块i)。
3. RAID级别
通过结合奇偶校验位和磁盘拆分思想可以较低代价提供数据冗余,具有不同成本和性能权衡的替换方案可分为若干RAID级别(RAID level)。
不同的RAID组织形式具有不同的成本。性能和可靠性特征。最常用的是RAID 1级和RAID 5级。
e.g.不同RAID级别4张磁盘数据的冗余信息(P表示纠错位,C表示数据的第二个拷贝。)
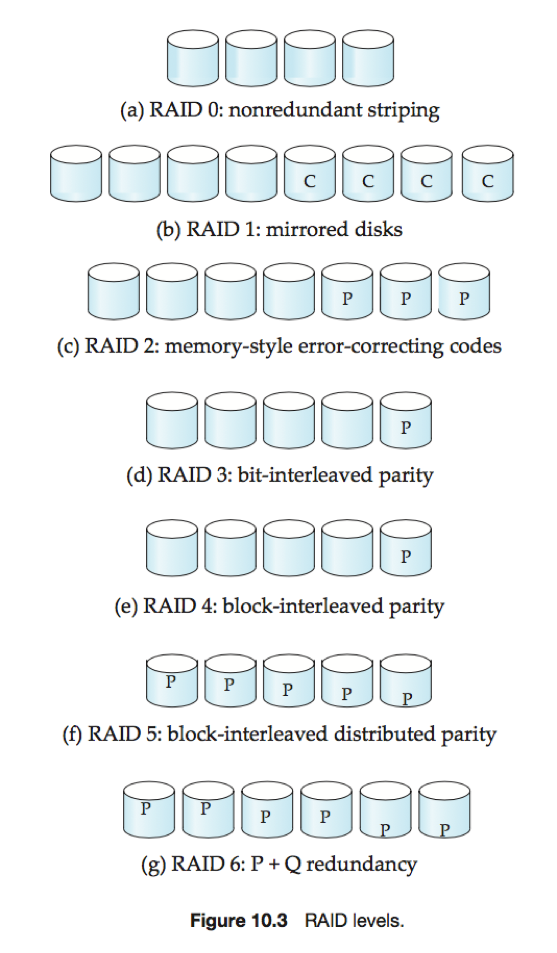
·RAID 0级:块级拆分但没有任何冗余的磁盘阵列;
·RAID 1级:使用块级拆分的磁盘镜像;
·RAID 2级:内存风格的纠错码(Error-Correcting-Code, ECC)组织结构。每个字节有都有一个与之联系的奇偶校验位,字节拆分存储到多张磁盘上,纠错位存储在其余磁盘中。
如果其中一张磁盘发生了故障,可从其他磁盘中读出字节的其余位和相关的纠错位,并用于重建被破坏的数据;
·RAID 3级:位交叉的奇偶校验组织结构。在RAID 2级的基础上改进,可用单一的奇偶校验位进行检错纠错。
可用奇偶校验位判断哪个扇区出错,通过计算其他磁盘上对应扇区的对应位的奇偶值来恢复被破坏扇区上的位。
RAID 3级和RAID 2级一样好,但更节省额外磁盘的开销,因此在实际中并不使用RAID 2。
相比RAID 1级减少存储开销、提高传输率,但每秒钟支持的I/O操作数较少;
·RAID 4级:块交叉的奇偶校验组织结构。块级拆分,并在一张独立磁盘上为其他N张磁盘对应的块保留一个奇偶校验块;
可使用奇偶校验块和其他磁盘上对应的块来恢复故障磁盘上的块;
·RAID 5级:块交叉的分布奇偶校验位的组织结构。在RAID 4的基础上改进,将数据和奇偶校验位分布到所有的N+1张磁盘中,而不是在N张磁盘上存储数据并在一张磁盘上存储奇偶校验位。
注意奇偶校验块不能和其所对应的数据块存储在同一张磁盘上,否则磁盘发生故障时导致数据和奇偶校验位的丢失。
RAID 5级和RAID 4级一样好,但在相同成本下提供了更好的读写性能,因此再实际中并不使用RAID 4;
·RAID 6级:P+Q冗余方案。类似RAID5级,但存储了额外的冗余信息以应对多张磁盘发生故障的情况。RAID 6级不适用奇偶校验,而使用类似Reed-Solomon码的纠错码。
4. RAID级别的选择
选择RAID级别应考虑的因素:所需额外磁盘存储带来的花费、I/O操作数量方面的性能需求、磁盘故障时的性能、数据重建过程中的性能。
对于大量数据传输,比特级拆分(RAID 3级)与块级拆分(RAID 5级)的数据传输率同样好;
对于小量数据传输。RAID5级性能更好,使用更少磁盘;
RAID 0级用于数据安全性不是很重要的高性能应用;
RAID 6级提供比RAID5级更高的可靠性,可用于数据安全十分重要的应用;
RAID 1级提供最好的写操作性能,在数据库系统日志文件的存储等应用中使用广泛,适合中等存储需求和高I/O需求的应用;
RAID5级相比1具有较低存储负载,但写操作时间开销更高,适合经常进行读操作而很少进行写操作的应用。
RAID系统一个阵列中磁盘越多,数据传输率越高,但系统越昂贵;
一个奇偶校验位保护的数据位越多,存储奇偶校验位的空间开销越小,但增加了数据丢失的可能。
5. 硬件问题
软件RAID(software RAID)可在不改变硬件层,只修改软件的基础上实现的RAID。而具有专用硬件支持的系统称为硬件RAID(hardware RAID)系统。
硬件RAID可使用非易失性RAM在执行写操作之前记录它们,如果发生电源故障,系统恢复时刻从非易失性RAM中获得有关未完成的写操作的信息并完成。
潜在故障(latent failure)/位腐(bit rot):个别扇区先前成功写入的数据可能丢失的故障。
擦洗(scrubbing):为减少数据丢失的可能性,良好的RAID控制器会在磁盘空闲时期对每张磁盘的每一个扇区进行读取,如果发现某个扇区无法读取,则数据从RAID组织的其余磁盘中进行恢复,并写回到扇区中。
热交换(hot swapping):在不切断电源的情况下将出错磁盘用新的磁盘替换。(减少了平均恢复时间)
第三级存储
常用的第三级存储介质:光盘、磁带。
1. 光盘
光盘的数据传输率用n×表示,指驱动器支持的传输速率是标准速率的n倍。
可记录一次(不可重写)的光盘(CD-R、DVD-R和DVD+R)适合于数据归档,存储不应更改的信息;可多次重写的光盘(CD-RW、DVD-RW、DVD+RW和DVD-RAM)也可用于数据归档。
自动光盘机(jukebox):存储大量光盘的设备,可按需求自动将光盘装载到少量驱动器中的一个上。
2. 磁带
磁带只能进行顺序存取,不能提供随机访问。主要用于备份存储不经常使用的数据、将数据从一个系统转到另一个系统的脱机截止。
自动磁带机(tape jukebox):存放大量的磁带,并由少量可用于安装磁带的驱动器。
文件组织
文件(file):一个数据库被映射到多个不同的文件,由底层操作系统维护。一个文件在逻辑上组织成为记录的一个序列,这些记录映射到磁盘块上。
块(block):存储分配和数据传输的基本单元。每个文件分成定长的存储单元,称为块。
一个块可能包括多条记录,由使用的物理数据组织形式决定;
一般假定没有记录比块更大,比块更大的大数据项通过指针处理单独存储;
要求每条记录包含在单个块中。
将数据库映射到文件的两种方法:
a. 定长记录:使用多个文件,每个文件中只存储固定长度的记录。
b. 变长记录:构造能够容纳多种长度的记录的文件,使之能适应多种长度的记录。
1. 定长记录
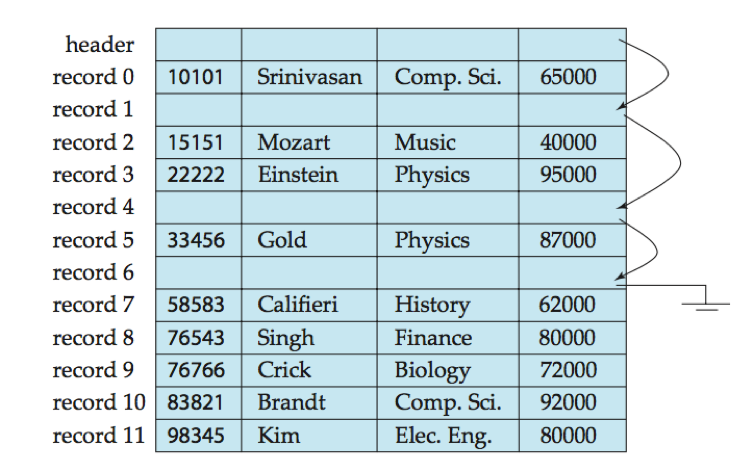
移动记录以占据被删记录所释放空间的做法不理想,可采用让随后插入的新记录重用被删除记录空间的做法。
文件头(file header):在文件的开始出分配一定数量的字节作为文件头,包含有关文件的各种信息。
空闲列表(free list):可在文件头中存储被删除的第一个记录的地址(指针),用这个记录来存储第二个可用记录的地址,依次类推,被删除的记录形成一条链表。
插入一条新纪录时,使用文件头所指向的记录,并改变文件头的指针以指向下一个可用记录。如果没有可用空间,则将新纪录添加到文件末尾。
2. 变长记录
对于记录中的定长属性,分配存储它们的值所需的字节数;
对于记录中的变长属性,在记录的初始部分中存储一个对(偏移量,长度)值,其中偏移量表示在记录中该属性的数据开始的位置,长度表示变长属性的字节长度,然后在定长部分后连续存储。
e.g. 变长记录instructor的表示。
属性ID、name和dept_name为变长字符串,属性salary为定长数值用8个字节存储;
每个属性的偏移量和长度值共占4个字节。
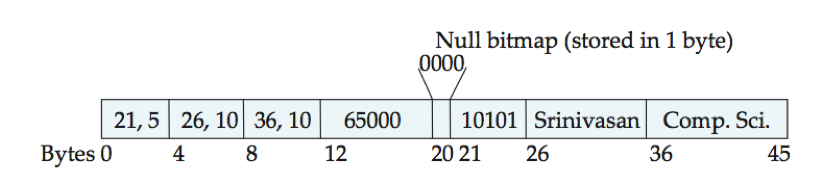
空位图(null bitmap):用于记录哪个属性是空值。在一些表示中空位图存储在记录开头,并且对于空属性不存储数据。
e.g. 记录中有4个属性,因此该记录的空位图只占1个字节。记录中如果salary是空值,则空位图的第4位置1,存储在12~19字节的salary值将被忽略。
分槽的页结构(slotted-page structure):一般用于在块中组织记录。
每个块开始处有一个块头,包含信息1. 块头中记录条目的个数;2. 块中空闲空间的末尾处;3. 一个包含记录位置和大小的记录条目组成的数组。
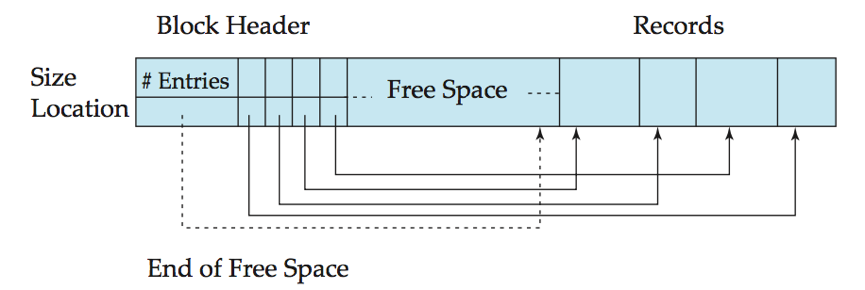
实际记录从块的尾部开始连续排列;
块中空闲空间是连续的,在块头数组的最后一个条目和第一条记录之间。
如果插入一条记录,在空闲空间尾部给这条记录分配空间,将包含这条记录大小和未知的条目添加到块头中,并修改块头中空闲空间末尾指针;
如果删除一条记录,释放它占用的空间,并将它的条目设置成被删除状态(e.g. 大小设置为-1),移动块中被删除记录之前的记录,并修改块头中空闲空间末尾指针。
要求指针不能直接指向记录,而必须指向块头中记有记录实际位置的条目(指向记录的间接指针)。
大对象通常不与记录中其他短属性存储在一起,而是存储到一个特殊文件或文件的集合中,并在包含该大对象的记录中存储一个指向大对象的逻辑指针。
文件中记录的组织
因为数据以块为单位在磁盘存储器和主存储器之间传输,所以才去用一个单独的块包含相关联的记录的方式,将文件记录分配到不同的块中是可取的。如果能够仅使用一次块访问就可以存取想要的多个记录,就能节省磁盘访问次数。因为磁盘访问通常是数据库系统性能的瓶颈,所以仔细设计块中记录的分配可以获得显著的性能提高。
在文件中组织记录的方法:
·堆文件组织(heap file organization):一条记录可放在文件中的任何地方,只要那个地方有空间存放这条记录。记录是没有顺序的,通常每个关系(记录的集合)使用一个单独的文件;
·顺序文件组织(sequential file organization):记录根据其”搜索码”的值顺序存储;
·散列文件组织(hashing file organization):在每条记录的某些属性上计算一个散列函数,散列函数的结果确定记录应放到文件的哪个块中。
通常每个关系的记录用一个单独的文件存储。但在多表聚簇文件组织(multitable clustering file organization)中,几个不同关系的记录存储在同一个文件中。
1. 顺序文件组织
搜索码(search key):任何一个属性或属性的集合,无须是主码或超码。
顺序文件(sequential file):用于高效处理按某个搜索码的顺序排序的记录。通过指针把记录链接起来,每条记录的指针指向搜索码顺序排列的下一跳记录,并在物理上按搜索码顺序或尽可能接近按搜索码顺序存储记录。
e.g. instructor记录组成的顺序文件,用ID作为搜索码。
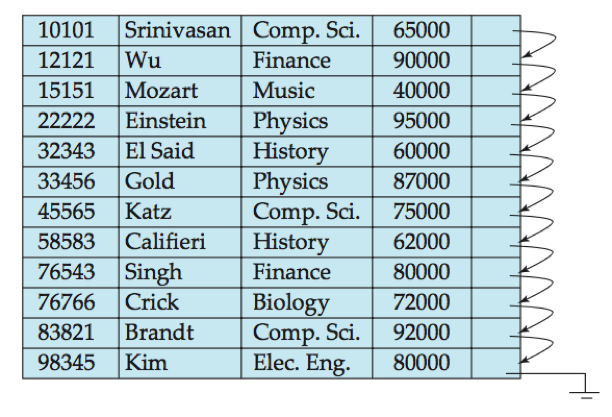
对于删除操作,使用指针链表来管理;
对于插入操作,在文件中定位按搜索码顺序处于待插入记录之前的一条记录,如果该记录所在块中有一条空闲记录(删除后留下的空间)则直接插入新纪录,否则将新纪录插入到一个溢出块中。调整指针,使其能按搜索码顺序链接记录。
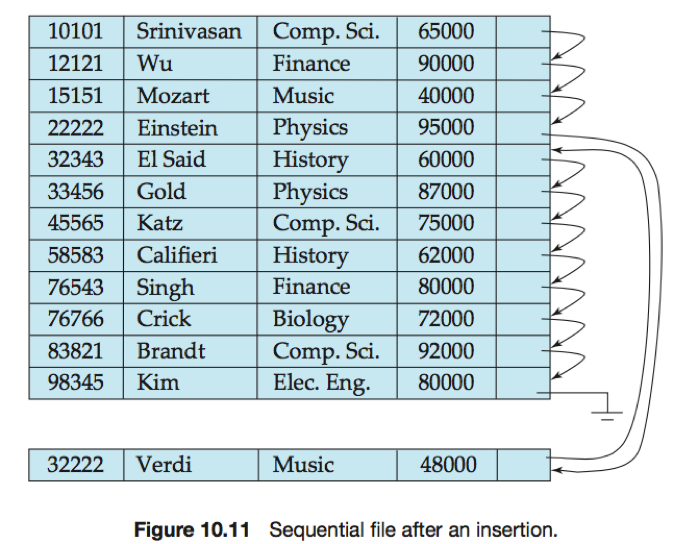
如果存储在溢出块中的记录较多,会丧失搜索码顺序和物理顺序之间的一致性,降低顺序处理效率。此时文件应该重组(reorganized),使其再一次在物理上顺序存放。重组代价很高,必须在系统负载很低时执行。
2. 多表聚簇文件组织
多表聚簇文件组织(multitable clustering file organization):一种在每一块中存储两个或多个关系的相关记录的文件组织。该文件组织允许使用一次块的读操作来读取满足连接条件的记录。
多表聚簇文件组织加速了对特定连接的处理,何时使用多表聚簇依赖于数据库设计者所认为的最频繁的查询类型。
e.g.
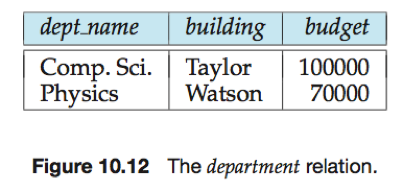
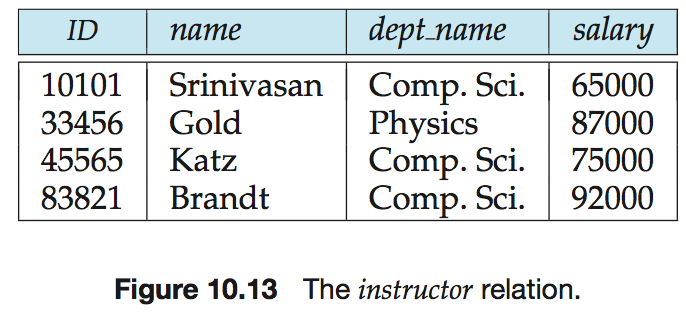
对于计算department关系和instrutor关系的连接的查询,可设计一个高效执行涉及department自然连接instructor查询的文件结构,该文件结构中,每个系的instructor元组存储在具有相应dept_name的department元组附近,因此将两个关系的元组混合在一起,允许对连接的高效处理。
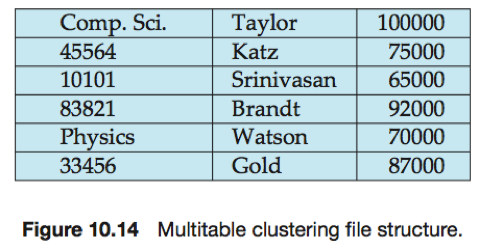
(假定每条记录包含它所属关系的标识符)
(如果记录太多不能存储在一个块中,则其余记录出现在临近块中。)
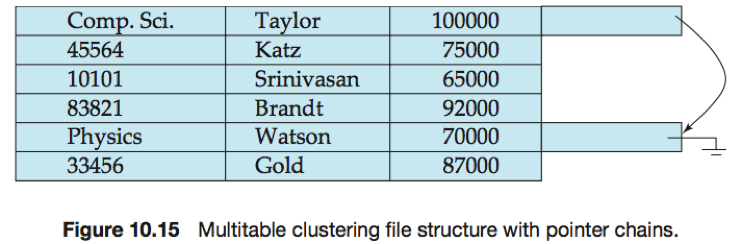
多表聚簇文件结构可能导致某些其他类型的查询处理变慢。
e.g. 与在单一文件中存储单一关系的策略相比,多表聚簇文件结构中SELECT * FROM department查询需要访问更多的块。可用指针把多表聚簇文件结构中所有department关系的记录链接起来。
数据字典存储
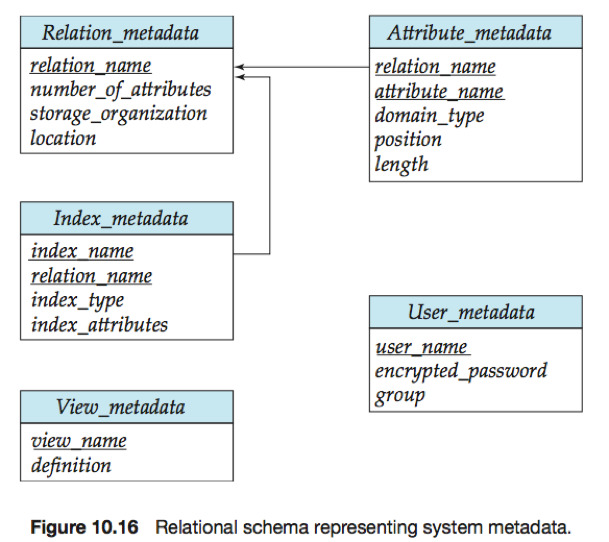
元数据(metadata):关系数据库需要维护的关于关系的数据。(关于数据的数据)
关于关系的关系模式和其他元数据存储在数据字典(data dictionary)a.k.a.系统目录(system catalog)中。
存储的信息类型包括:
·关系的名字;每个关系中属性的名字、域和长度;视图的名字和视图的定义;
·授权用户的名字;关于用户的授权和账户信息;用于认证用户的密码或其他信息;
·关于关系的统计数据和描述数据(e.g. 每个关系中元组的总数、每个关系所使用的存储方法);
·关系的存储组织(顺序、散列或堆)和每个关系的存储位置;
·关于每个关系的每个索引的信息(e.g. 索引的名字、被索引关系的名字、在其上定义索引的属性、构造的索引的类型)。
数据字典通常存储成非规范化的形式,以便进行快速的存取。
e.g. 描述系统元数据的一种关系模式
数据库缓冲区
数据库系统的一个主要目标是尽量减少磁盘和存储器之间传输的块数目。
减少磁盘访问数量的一种方法是在主存储器中保留尽可能多的块。因为在主存储器中保留所有的块是不可能的,所以需要为块的存储而管理主存储器中可用空间的分配。
缓冲区(buffer):主存储器中的一部分,用于存储磁盘块拷贝。每个块总有一个拷贝存放在磁盘上,但在磁盘上的拷贝可能更旧。
缓冲区管理器(buffer management):负责缓冲区空间分配的子系统。
1. 缓冲区管理器
当数据库系统中的程序需要磁盘上的块时,向缓冲区管理器发出请求(调用);
→如果这个块已经在缓冲区中,缓冲区管理器将这个块在主存储器中的地址传给请求者。
如果这个块不在缓冲区中,缓冲区管理器先在缓冲区中为这个块分配空间;
→如果需要,可将其他块移出主存储器为新块腾出空间(移出的块仅当它自最近一次写回磁盘后被修改过才被写回磁盘);
→缓冲区管理器把请求的块从磁盘读入缓冲区,将这个块在主存储器中的地址传回给请求者。
缓冲区管理器使用比典型的虚拟存储器管理策略更复杂的技术:
·缓冲区替换策略(buffer replacement strategy):当缓冲区中没有剩余空间时,在新块读入缓冲区之前必须把一个块从缓冲区中移除。可采用改进的最近最少使用(LRU)策略。
·被钉住的块(pinned block):当一个块上的更新操作正在进行时,大多数恢复系统不允许将该块写回磁盘。该特性对从崩溃中恢复十分重要。
·块的强制写出(forced output of block):在某些情况下,尽管不需要一个块所占用的缓冲区空间,但必须把这个块写回磁盘的写操作。

