

JVM: OOP模型 & 对象内存结构 & 计算对象大小 & 指针压缩 & 预估调优
* 以下内容基于64位机 jdk 8。
Oop模型 -- Java中的对象在jvm中的表现形式。
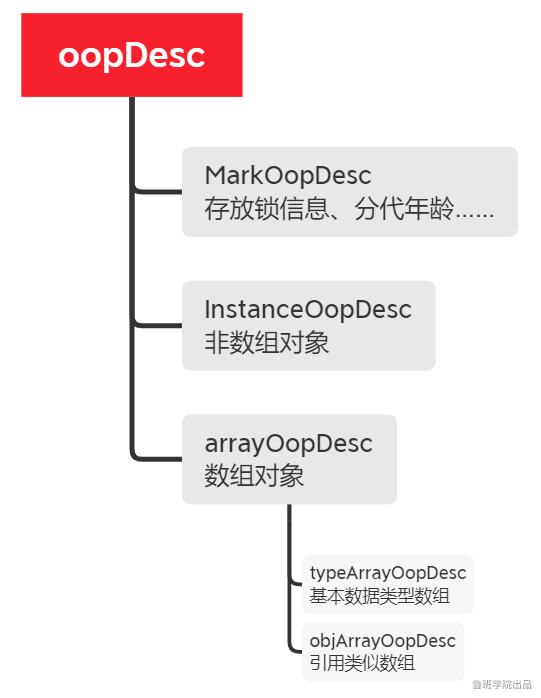
oopDesc: 顶层类。_compressed_klass即为压缩指针。
/openjdk/hotspot/src/share/vm/oops/oop.hpp
class oopDesc { friend class VMStructs; private: volatile markOop _mark; union _metadata { Klass* _klass; narrowKlass _compressed_klass; } _metadata; … }
markOopDesc就是(sync的)锁的底层数据结构。
/openjdk/hotspot/src/share/vm/oops/markOop.hpp
// 64 bits: // -------- // unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object) // JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object) // PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object) // size:64 ----------------------------------------------------->| (CMS free block) … class markOopDesc: public oopDesc { … enum { locked_value = 0, unlocked_value = 1, monitor_value = 2, marked_value = 3, biased_lock_pattern = 5 }; … }
实验1:在HSDB中查看对象的oop信息
public class CountEmptyObjectSize { public static void main(String[] args) { CountEmptyObjectSize obj = new CountEmptyObjectSize(); while (true); } }
-> 运行程序后 jps –l查目标对象的进程ID;
-> HSDB attach到该进程,查看main线程的堆栈;
-> 找到对象指针的内存地址,Inspector输入该地址;
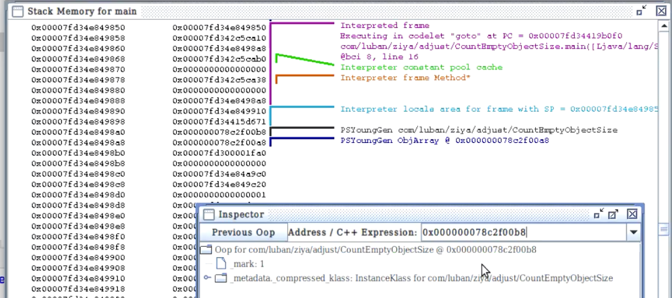
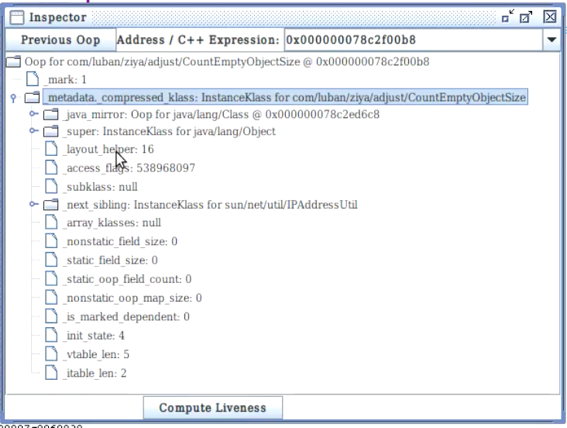
-> metadata为类的元信息,layout_helper为对象大小(例中为空对象,所以大小为16);
* 可用jol (在Java层面打印出对象大小)验证。
* layout_helper表示的对象大小基本准确,但仅局限于非数组对象。
Layout_helper的值有三层含义:
a) 如果是非数组对象,该值为类生成的对象大小;
b) 如果是数组对象,该值为负数;(因为数组是动态生成的,编译时不知道长度)
c) =0 待查资料补充。
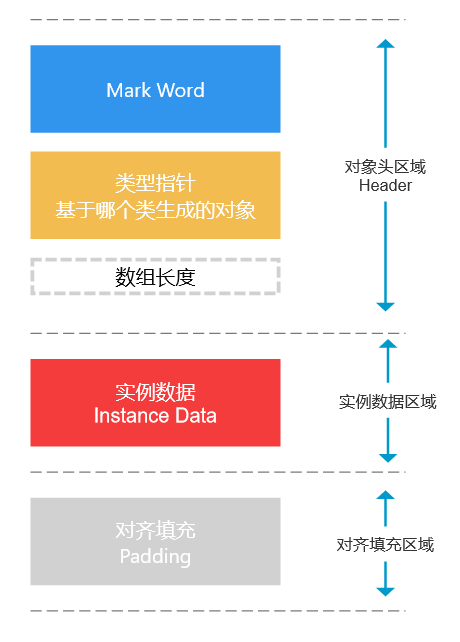
对象的内存结构
Mark Word
在32位机占4B,在64位机占8B。
类型指针
Klass Pointer,对象所属的类的元信息的实例指针,即InstanceKlass在方法区的地址。
e.g. HSDB Inspector查看对象时显示的metadata_compressed_klass
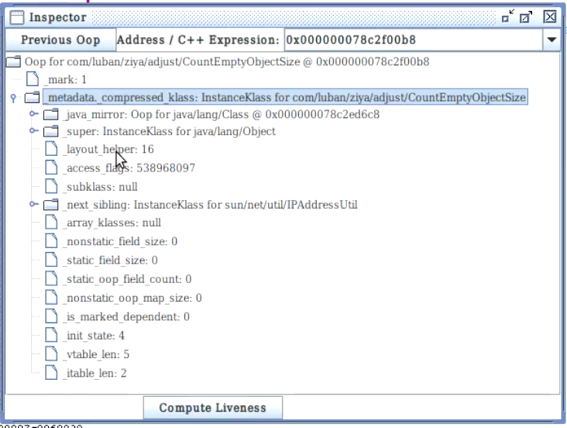
大小跟指针压缩有关。如果指针压缩开启则占4B;如果指针压缩关闭则占8B。
数组长度
如果该对象不是数组,大小占0B;如果该对象是数组,大小占4B(用1个int存储)。
由此可推出Java中数组的最大长度的计算方法 为232-1。
实例数据
类的非静态属性,生成对象时就是实例数据。不同数据类型所占大小不同。E.g.
Boolean 占 1B;
byte 占 1B;
char 占 2B;
short 占 2B;
int 占 4B;
float 占 8B;
double 占 8B;
long 占 8B;
对于引用类型,如果开启指针压缩占4B,关闭指针压缩占8B。
对齐填充
因为Java中所有的对象大小都是8字节对齐的(i.e. 8的整数倍,至少16B)。e.g. 16B, 24B, 32B … .,有时需要填充一些字节(补0)以达到对齐。
e.g. 如果一个对象占30B,jvm底层会补2个字节。
为什么要做对齐填充?
- 为了(底层)程序更好写,性能更高。
对象的两种内存布局
a) b)

计算三种类型对象大小
没实例数据的对象 -- 占16字节
实验2:查看没实例数据的对象大小
//需要jol.core包 import org.openjdk.jol.info.ClassLayout; public class CountEmptyObjectSize { public static void main(String[] args) { CountEmptyObjectSize obj = new CountEmptyObjectSize(); System.out.println(ClassLayout.parseInstance(obj).toPrintable()); } }
-> Run/Debug Configurations / VM options填-XX:+UseCompressedOops开启指针压缩并运行程序;
结果:开启指针压缩时,对象大小占16B;
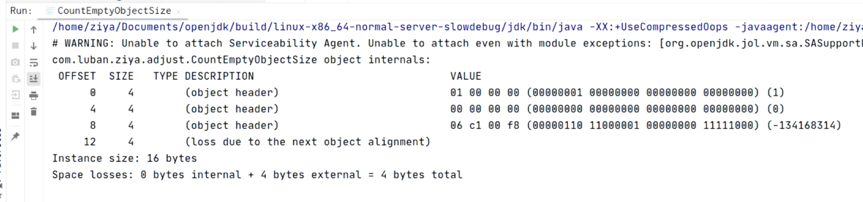
-> VM options填-XX:-UseCompressedOops关闭指针压缩并运行程序;
结果:关闭指针压缩时,对象大小也占16B;

计算
开启指针压缩时,
16B = 8B (Mark Word) + 4B (类型指针) + 0B (数组长度) + 0B (实例数据) + 4B (对齐填充)
关闭指针压缩时,
16B = 8B (Mark Word) + 8B (类型指针) + 0B (数组长度) + 0B (实例数据) + 0B (对齐填充)
普通对象
e.g.
import org.openjdk.jol.info.ClassLayout; public class CountObjectSize { int a = 10; int b = 20; public static void main(String[] args) { CountObjectSize object = new CountObjectSize(); System.out.println(ClassLayout.parseInstance(object).toPrintable()); } }
计算
开启指针压缩时,
24B = 8B (Mark Word) + 4B (类型指针) + 0B (数组长度) + 4*2B (实例数据) + 4B (对齐填充)
关闭指针压缩时,
24B = 8B (Mark Word) + 8B (类型指针) + 0B (数组长度) + 4*2B (实例数据) + 0B (对齐填充)
数组对象
实验3:查看数组对象的大小
import org.openjdk.jol.info.ClassLayout; public class CountSimpleObjectSize { static int[] arr ={0, 1, 2}; public static void main(String[] args) { CountSimpleObjectSize test1 = new CountSimpleObjectSize(); System.out.println(ClassLayout.parseInstance(arr).toPrintable()); } }
-> VM option开启/关闭指针压缩运行程序,对比两次对象大小;
结果:
开启指针压缩时,对象大小占32B;
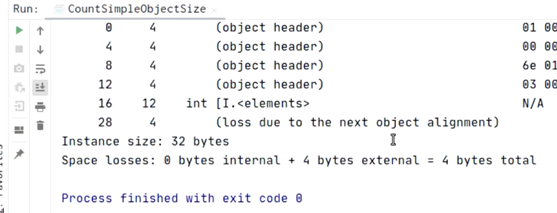
关闭指针压缩时,对象大小占40B;
并且可以看到有两段字节填充(alignment/padding gap和loss due to the next object alignment)。
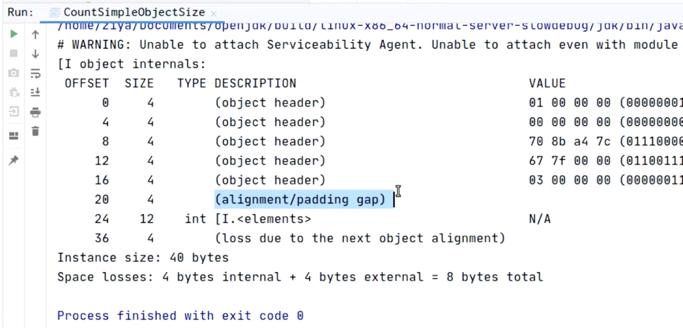
说明数组对象在指针关闭的情况下会出现两段填充。
计算
开启指针压缩时,
32B = 8B (Mark Word) + 4B (类型指针) + 4B (数组长度) + 4*3B (实例数据) + 4B (对齐填充)
关闭指针压缩时,
40B = 8B (Mark Word) + 8B (类型指针) + 4B (数组长度) + + 4B (对齐填充) + 4*3B (实例数据) + 4B (对齐填充)
指针压缩
e.g. 64位机操作系统一个地址占8B,JVM开启指针压缩将一个OOP压缩成了4B表示。
指针压缩的目的? - 节省内存,提高寻址效率。
jdk 6以后默认开启指针压缩。
* 没实例数据对象(实验2)和普通对象大小计算案例中开启指针压缩并没有节省到内存是因为例中对象较简单,实验list、array等复杂对象可证明开启指针压缩的效果。
指针压缩的实现原理
因为Java中对象都是8字节对齐的,所以所有对象的指针后3位永远是0。
1) 存储的时候,后3位0抹除;
2) 使用的时候,后3位0补齐;
e.g.
-> 给定3个对象,大小分别为test1=16B,test2=24B,test3=32B。
-> 假设从地址0开始顺序存储,则内存地址分别为:
test 1: 0 000
test2:10 000 //10进制16转2进制
test3: 101 000 //10进制40转2进制
-> 存储时后3位抹0:
test 1: 0
test2:10
test3: 101
-> 使用时后3位补0:
test 1: 0 000
test2:10 000
test3: 101 000
指针存储在_metadata中。如果不是指针压缩,存储在klass;如果是指针压缩,存储在compressed_klass。
/openjdk/hotspot/src/share/vm/oops/oop.hpp
class oopDesc { friend class VMStructs; private: volatile markOop _mark; union _metadata { Klass* _klass; narrowKlass _compressed_klass; } _metadata; … }
实验4:证明指针压缩关闭/开启时对象内存地址是用klass/compressed_klass指向的
import org.openjdk.jol.info.ClassLayout; public class Test { public static void main(String[] args) { Test obj = new Test(); while (true); } }
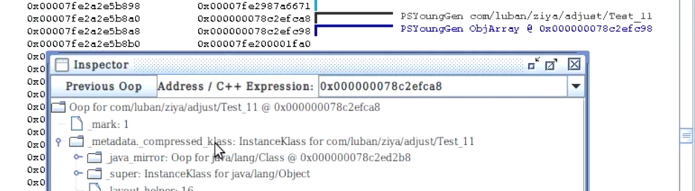
-> 关闭指针压缩,运行程序,查看虚拟机栈找到对象地址;
-> Inspector查看到该对象的metadata为klass;
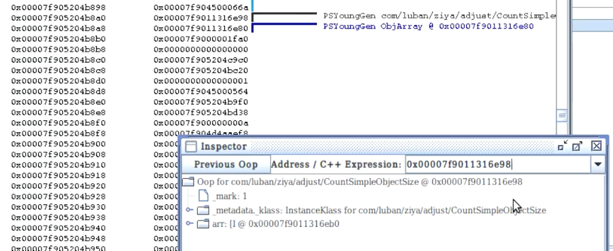
-> 开启指针压缩,运行程序,查看虚拟机栈找到对象地址;(可看出此时对象地址明显比关闭指针压缩时短)
-> Inspector查看到该对象的metadata为compressed_klass;
对象地址的计算底层实现 –> 参考 /openjdk/hotspot/src/share/vm/oops/oop_inline.hpp
一个OOP能表示的最大堆空间?
-> 如果是32位机, 一个OOP存储时占4B(32bits),使用时补了3位0,变为35位。所以能表示的最大堆空间为235=32G。 a.k.a. 32G瓶颈 / 堆瓶颈
不关闭指针压缩的情况下,如果32G不够用,需要扩容,怎么做?
-> 8字节对齐改为16字节对齐
因为当Java中所有对象都16字节对齐时,每个OOP使用时补4位0,能表示的最大堆空间变为236=64G。
-> 此项扩容操作是通过修改jdk源码(oop_inline.hpp中的decode_heap_oop系列函数)完成,而不是通过修改操作系统,因为指针压缩是jdk的特性。
jdk底层为什么没有采用16字节对齐?
-> CPU计算性能有限,现在的GC算法处理32G大小的堆空间已经达到吞吐极限。(由于CPU的计算能力的瓶颈,即使改为16字节对齐也不能提升性能)
JVM调优
为什么要调优?
- 防止出现OOM、解决OOM、减少full GC出现的频率。
JVM调优的3个阶段
1) 项目部署到线上之前,基于可能的并发量做预估调优;
2) 项目运行过程(初期)中,部署监控收集性能数据,分析日志做一些基础调优;
3) 线上出现OOM、频繁full GC时,进行问题排查做彻底调优。
调优涉及的区域
1) 方法区
2) 虚拟机栈
3) 堆区
4) 热点代码缓冲区
案例:亿级流量电商系统预估调优
* 此处假设数据为大部分电商系统的通用概率,有一定代表性。现实中的电商系统并发流量可参考电商公司发布的财报。
· 每个用户(uv)平均访问20个商品详情页(pv),则用户数约为1亿/20=500w;
· 电商系统转换率一般在9%~12%,如果取10%为转换率,则下单用户数(订单数)约为50w;
· 如果40%的订单是在秒杀前两分钟完成的,则每秒产生50w*30%/120≈1200笔订单;
// 此处计算时将40%误填为30%,暂时先按30%继续计算。
· 订单支付又涉及到发起支付流程、物流、优惠券、推荐、积分等环节导致产生大量对象,假设整个支付流程生成对象数约20k,则每秒在Eden区生成对象数1200*20k≈20M;
· 在生产环境中,订单模块还涉及到百万商家查询订单、改价、包邮、发货等其他操作,又会产生大量对象,我们放大10倍,即每秒在Eden区生成的对象约200M;
* 做预估时可以将数据预估得稍大一些,使系统能兼容的并发量更大,减少系统出问题的概率。
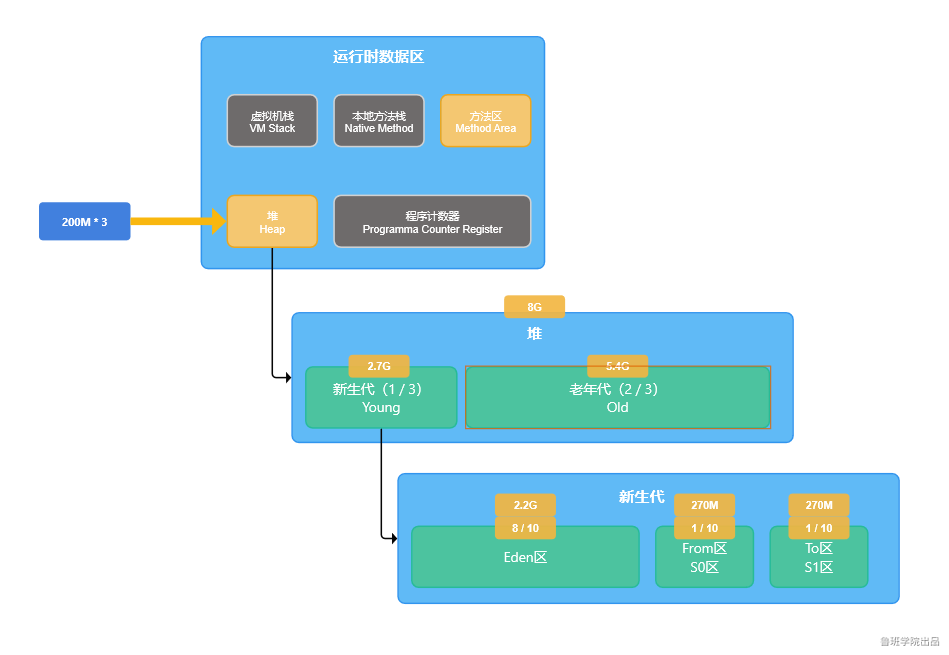
单机物理内存32G,堆内存最大占32*1/4=8G(新生代和老年代分别占1/3和2/3)。
· 假设操作流程3秒完成,则每3秒有600M对象进入新生代Eden区;
假设新生代大小2.7G(2700M),多长时间会发生Young GC?
- 每2700/200≈14秒发生一次Young GC。(问题不大,因为Eden区对象回收概率本身就很大)
-> young GC发生时会触发垃圾回收,但有600M对象(因为还在使用)无法被回收,而且from区和to区都存不下,则会触发空间担保直接进入老年代(5400M);
老年代多长时间触发一次full GC?
- 因为每14秒有600M对象进入老年代,每5400/600*14=126秒触发一次full GC。
所以有的系统频繁full GC,本质上是因为有对象在young GC时未被清理,触发空间担保或动态年龄判断或度过15次GC所以进入了老年代。
如果你是这个系统的架构师,你如何调优?
- 加机器;
- 如果只有一台机器,尽量让这些对象在young GC阶段就能被回收,少触发full GC(因为full GC成本很高)
* 分析日志时先看是在哪个区发生OOM。通常原因是频繁创建对象、gc回收速度比不上创建的速度。

