HCIE数据挖掘笔记-007.1Beautiful Soup学习笔记(一)初始化与节点选择器
被莫名其妙地塞了很多的Python基础知识,然后开始讲爬虫,但只讲了Python的re正则表达式模块,但手写爬虫并不现实,他也没有教。无内鬼,整点Beautiful Soup。
因为anaconda+jupyter notebook环境对于数据处理初学者来说已经近乎完美,所以安装与简介部分跳过
from bs4 import BeautifulSoup #从bs4库中引入Beautiful Soup
soup = BeautifulSoup(markup,features) #初始化实例
markup有两种可使用参数类型,一种为html.str,即字符串,另一种为打开文件,通常为:
soup = BeautifulSoup (markup = open (file))
features 为解析器类型,可用指定解析器或者默认解析器,缺省时为默认解析器
初始化实例的例子如下:
soup = BeautifulSoup(markup= open("C:/Users/admin/Desktop/1.html",'r', encoding='utf-8'))
在完成对实例的初始化后,需选择BS选择器对数据进行筛选,分三类:节点选择器(获取数据基本方法)、方法选择器、CSS选择器(定位元素常用选择)
节点选择器根据Tag来选取元素,即<>,包括<body>等标签与<a >标签,通过tag对数据进行选择

我们可以用soup.title 获取soup内的tag,即将html转换成bs4.element,tag类型格式,当有多个时,只提取第一个,如下图所示:
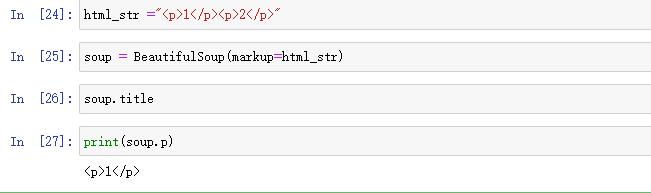
可以用name获取名称,用attrs获取对应值返回的字典,用string获取内容,如:

由于<p>1</p>只是个简单的段落,其attrs方法难以表现的很明显,于是重做一个超链接的:
与此同时,对于形如<head><title>this is a title</title></head>,可以使用如下的定位方法:
from bs4 import BeautifulSoup html_str2='<head><title>this is a title</title></head>' soup = BeautifulSoup(markup=html_str2) soup.title print(soup.head.title) print(type(soup.head.title)) print(soup.head.title.name) print(soup.head.title.string)

对于内部子节点的获取可以使用如下的方法:
from bs4 import BeautifulSoup html_str2='<p><a herf = www.baidu.com>百度</a><a herf = www.bilibili.com>bilibili</a><a herf = www.huawei.com>华为</a><a herf = www.jspi.com>江苏警官学院</a></p>' soup = BeautifulSoup(markup=html_str2) soup.title contents = soup.p.contents print(contents) children = soup.p.children print(children)
其中属性contents用于获取子节点,并以列表形式存储在变量contents中,属性children是一个生成器,用于生成子节点: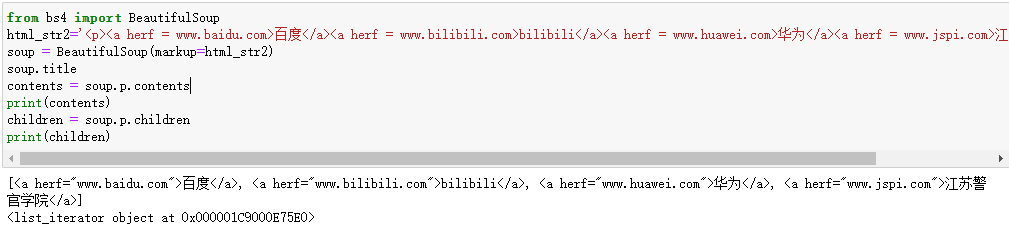
我们可以看到,children属性是一个生成器,因此我们可以用遍历循环得到变量children中的内容:
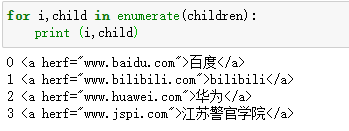
for i,child in enumerate(children): print (i,child)
得到结果为:
对于父节点(属性外最近包裹的tag)需使用parent属性,例如:
from bs4 import BeautifulSoup html_str2='<p><a herf = www.baidu.com>百度</a><a herf = www.bilibili.com>bilibili</a><a herf = www.huawei.com>华为</a><a herf = www.jspi.com>江苏警官学院</a></p>' soup = BeautifulSoup(markup=html_str2) soup.title parent = soup.a.parent print(parent)
得到结果为:

可以看到包裹在<a></a>tag外的<p></p>tag被提取了出来
对于祖先节点(即父节点与父节点的父节点与父节点的父节点的父节点等等等节点)需使用parents属性(注意区分与父节点的parent属性,祖先节点需要带s,父节点不需要),此处使用nj.lianjia.com的部分源代码进行示范,源代码如下:
<html>
<body class="" style="margin-bottom: 130px;"> <li class="clear">
<span class="code-title fl">D</span>
<div class="city-enum fl">
<a href="https://dg.lianjia.com/" title="东莞房产网">东莞</a>
<a href="https://dz.fang.lianjia.com/" title="儋州房产网">儋州</a>
<a href="https://dy.lianjia.com/" title="德阳房产网">德阳</a>
<a href="https://danyang.lianjia.com/" title="丹阳房产网">丹阳</a>
<a href="https://dl.lianjia.com/" title="大连房产网">大连</a>
<a href="https://dd.lianjia.com/" title="丹东房产网">丹东</a>
<a href="https://dali.lianjia.com/" title="大理房产网">大理</a>
<a href="https://dazhou.lianjia.com/" title="达州房产网">达州</a>
</div>
</li>
</body>
</html>
下面进行Parent属性与Parents属性的比对:
from bs4 import BeautifulSoup soup = BeautifulSoup(markup = open("D:/2.html",'r', encoding='utf-8')) soup.title parent1 = soup.a.parent parents = soup.a.parents print(parent1) print(parents) for i,parent in enumerate(parents): print (i,parent)
得出结果如下:
<div class="city-enum fl"> <a href="https://dg.lianjia.com/" title="东莞房产网">东莞</a> <a href="https://dz.fang.lianjia.com/" title="儋州房产网">儋州</a> <a href="https://dy.lianjia.com/" title="德阳房产网">德阳</a> <a href="https://danyang.lianjia.com/" title="丹阳房产网">丹阳</a> <a href="https://dl.lianjia.com/" title="大连房产网">大连</a> <a href="https://dd.lianjia.com/" title="丹东房产网">丹东</a> <a href="https://dali.lianjia.com/" title="大理房产网">大理</a> <a href="https://dazhou.lianjia.com/" title="达州房产网">达州</a> </div> <generator object PageElement.parents at 0x000001C9024F23C0> 0 <div class="city-enum fl"> <a href="https://dg.lianjia.com/" title="东莞房产网">东莞</a> <a href="https://dz.fang.lianjia.com/" title="儋州房产网">儋州</a> <a href="https://dy.lianjia.com/" title="德阳房产网">德阳</a> <a href="https://danyang.lianjia.com/" title="丹阳房产网">丹阳</a> <a href="https://dl.lianjia.com/" title="大连房产网">大连</a> <a href="https://dd.lianjia.com/" title="丹东房产网">丹东</a> <a href="https://dali.lianjia.com/" title="大理房产网">大理</a> <a href="https://dazhou.lianjia.com/" title="达州房产网">达州</a> </div> 1 <li class="clear"> <span class="code-title fl">D</span> <div class="city-enum fl"> <a href="https://dg.lianjia.com/" title="东莞房产网">东莞</a> <a href="https://dz.fang.lianjia.com/" title="儋州房产网">儋州</a> <a href="https://dy.lianjia.com/" title="德阳房产网">德阳</a> <a href="https://danyang.lianjia.com/" title="丹阳房产网">丹阳</a> <a href="https://dl.lianjia.com/" title="大连房产网">大连</a> <a href="https://dd.lianjia.com/" title="丹东房产网">丹东</a> <a href="https://dali.lianjia.com/" title="大理房产网">大理</a> <a href="https://dazhou.lianjia.com/" title="达州房产网">达州</a> </div> </li> 2 <body><p> </p> <li class="clear"> <span class="code-title fl">D</span> <div class="city-enum fl"> <a href="https://dg.lianjia.com/" title="东莞房产网">东莞</a> <a href="https://dz.fang.lianjia.com/" title="儋州房产网">儋州</a> <a href="https://dy.lianjia.com/" title="德阳房产网">德阳</a> <a href="https://danyang.lianjia.com/" title="丹阳房产网">丹阳</a> <a href="https://dl.lianjia.com/" title="大连房产网">大连</a> <a href="https://dd.lianjia.com/" title="丹东房产网">丹东</a> <a href="https://dali.lianjia.com/" title="大理房产网">大理</a> <a href="https://dazhou.lianjia.com/" title="达州房产网">达州</a> </div> </li> </body> 3 <html><body><p> </p> <li class="clear"> <span class="code-title fl">D</span> <div class="city-enum fl"> <a href="https://dg.lianjia.com/" title="东莞房产网">东莞</a> <a href="https://dz.fang.lianjia.com/" title="儋州房产网">儋州</a> <a href="https://dy.lianjia.com/" title="德阳房产网">德阳</a> <a href="https://danyang.lianjia.com/" title="丹阳房产网">丹阳</a> <a href="https://dl.lianjia.com/" title="大连房产网">大连</a> <a href="https://dd.lianjia.com/" title="丹东房产网">丹东</a> <a href="https://dali.lianjia.com/" title="大理房产网">大理</a> <a href="https://dazhou.lianjia.com/" title="达州房产网">达州</a> </div> </li> </body></html> 4 <html><body><p> </p> <li class="clear"> <span class="code-title fl">D</span> <div class="city-enum fl"> <a href="https://dg.lianjia.com/" title="东莞房产网">东莞</a> <a href="https://dz.fang.lianjia.com/" title="儋州房产网">儋州</a> <a href="https://dy.lianjia.com/" title="德阳房产网">德阳</a> <a href="https://danyang.lianjia.com/" title="丹阳房产网">丹阳</a> <a href="https://dl.lianjia.com/" title="大连房产网">大连</a> <a href="https://dd.lianjia.com/" title="丹东房产网">丹东</a> <a href="https://dali.lianjia.com/" title="大理房产网">大理</a> <a href="https://dazhou.lianjia.com/" title="达州房产网">达州</a> </div> </li> </body></html>
我们可以看到parent属性结果仅为父节点,而parents属性结果为生成器,用循环遍历打印其中内容,可以看到结果为由第一个父节点开始逐渐向上一层父节点求节点的各个阶段结果
对于兄弟节点(即在同一个父节点之内的节点),可以用sibling等属性:
from bs4 import BeautifulSoup soup = BeautifulSoup(markup = open("D:/2.html",'r', encoding='utf-8')) soup.title n_sibling = soup.a.next_sibling p_sibling = soup.a.previous_sibling n_siblings = soup.a.next_siblings p_siblings = soup.a.previous_siblings print(n_sibling) print(p_sibling) print(n_siblings) print(p_siblings) for i1,ne_sibling in enumerate(n_siblings): print (i1,ne_sibling) for i2,pr_sibling in enumerate(p_siblings): print (i2,pr_sibling)
在这之前我们在2.html文件的第一个<a></a>tag前后各加一段<p></p>tag以示区分
其中previous/next_sibling属性分别获取<a></a>tag前后的一个属性,而previous/next_siblings属性分别可获取其前后的所有兄弟节点
得到的结果如下:
<generator object PageElement.next_siblings at 0x000001C903315A50> <generator object PageElement.previous_siblings at 0x000001C902F29D60> 0 1 <p>123</p> 2 3 <a href="https://dz.fang.lianjia.com/" title="儋州房产网">儋州</a> 4 5 <a href="https://dy.lianjia.com/" title="德阳房产网">德阳</a> 6 7 <a href="https://danyang.lianjia.com/" title="丹阳房产网">丹阳</a> 8 9 <a href="https://dl.lianjia.com/" title="大连房产网">大连</a> 10 11 <a href="https://dd.lianjia.com/" title="丹东房产网">丹东</a> 12 13 <a href="https://dali.lianjia.com/" title="大理房产网">大理</a> 14 15 <a href="https://dazhou.lianjia.com/" title="达州房产网">达州</a> 16 0 1 <p>456</p> 2
最开始的空行是是表示回车键,即第一个<a></a>tag的前后兄弟节点,siblings类属性的结果均为生成器,因此用循环遍历打印其结果。
