

Linux之7——性能调优命令之top
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。
在linux系统下输入top命令如下: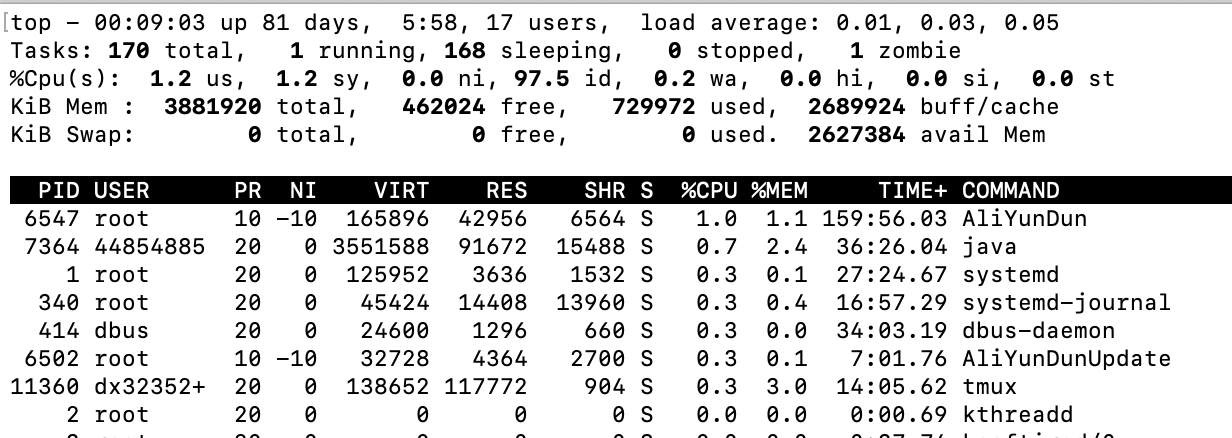
参数含义

top - 00:10:55 up 81 days, 6:00, 17 users, load average: 0.00, 0.02, 0.05 Tasks: 155 total, 1 running, 153 sleeping, 0 stopped, 1 zombie %Cpu(s): 0.7 us, 0.3 sy, 0.0 ni, 99.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 3881920 total, 467472 free, 724592 used, 2689856 buff/cache KiB Swap: 0 total, 0 free, 0 used. 2632956 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9 root 20 0 0 0 0 S 0.3 0.0 20:17.67 rcu_sched
400 root 20 0 1381588 37088 5316 S 0.3 1.0 247:34.50 CmsGoAgent.linu
6547 root 10 -10 165896 42956 6564 S 0.3 1.1 159:56.44 AliYunDun
7364 44854885 20 0 3551588 91672 15488 S 0.3 2.4 36:26.60 java
11880 root 20 0 116268 15576 4424 S 0.3 0.4 128:42.67 node_exporter
1 root 20 0 125952 3636 1532 S 0.0 0.1 27:24.68 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.69 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:37.74 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
7 root rt 0 0 0 0 S 0.0 0.0 0:49.07 migration/0
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
统计信息区前五行是系统整体的统计信息。
第一行是任务队列信息,同 uptime 命令的执行结果。其内容如下:
00:10:55 当前时间 up 81 days, 6:00, 系统已运行时间(天:时:分) 17 users, 当前登录用户数 load average: 0.00, 0.02, 0.05 系统负载,即任务队列的平均长度。三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值
load average:负载,相当于进程排队的队列,比如有一条一百米长的公路,公路上面有车,一辆车长3米,那么一百米长的公路最多放33辆车
一只单核的处理器可以形象得比喻成一条单车道。设想下,你现在需要收取这条道路的过桥费 — 忙于处理那些将要过桥的车辆。你首先当然需要了解些信息,例如车辆的载重、以及 还有多少车辆正在等待过桥。如果前面没有车辆在等待,那么你可以告诉后面的司机通过。 如果车辆众多,那么需要告知他们可能需要稍等一会。
因此,需要些特定的代号表示目前的车流情况,例如:
0.00 表示目前桥面上没有任何的车流。 实际上这种情况与 0.00 和 1.00 之间是相同的,总而言之很通畅,过往的车辆可以丝毫不用等待的通过。
1.00 表示刚好是在这座桥的承受范围内。 这种情况不算糟糕,只是车流会有些堵,不过这种情况可能会造成交通越来越慢。
超过 1.00,那么说明这座桥已经超出负荷,交通严重的拥堵。 那么情况有多糟糕? 例如 2.00 的情况说明车流已经超出了桥所能承受的一倍,那么将有多余过桥一倍的车辆正在焦急的等待。3.00 的话情况就更不妙了,说明这座桥基本上已经快承受不了,还有超出桥负载两倍多的车辆正在等待。
上面的情况和处理器的负载情况非常相似。一辆汽车的过桥时间就好比是处理器处理某线程 的实际时间。Unix 系统定义的进程运行时长为所有处理器内核的处理时间加上线程 在队列中等待的时间。
load average值的含义
1) 单核处理器
假设我们的系统是单CPU单内核的,把它比喻成是一条单向马路,把CPU任务比作汽车。当车不多的时候,load <1;当车占满整个马路的时候 load=1;当马路都站满了,而且马路外还堆满了汽车的时候,load>1
2) 多核处理器
我们经常会发现服务器Load > 1但是运行仍然不错,那是因为服务器是多核处理器(Multi-core)。
假设我们服务器CPU是2核,那么将意味我们拥有2条马路,我们的Load = 2时,所有马路都跑满车辆。
注:查看cpu 核数命令:
grep 'model name' /proc/cpuinfo | wc -l
3. 什么样的Load average值要提高警惕
- 0.7 < load < 1: 此时是不错的状态,如果进来更多的汽车,你的马路仍然可以应付。
- load = 1: 你的马路即将拥堵,而且没有更多的资源额外的任务,赶紧看看发生了什么吧。
- load > 5: 非常严重拥堵,我们的马路非常繁忙,每辆车都无法很快的运行
4. 三种Load值,应该看哪个
通常我们先看15分钟load,如果load很高,再看1分钟和5分钟负载,查看是否有下降趋势。
1分钟负载值 > 1,那么我们不用担心,但是如果15分钟负载都超过1,我们要赶紧看看发生了什么事情。所以我们要根据实际情况查看这三个值。
第二、三行为进程和CPU的信息。当有多个CPU时,这些内容可能会超过两行。内容如下:
total 进程总数 running 正在运行的进程数 sleeping 睡眠的进程数 stopped 停止的进程数 zombie 僵尸进程数 Cpu(s): 0.3% us 用户空间占用CPU百分比 1.0% sy 内核空间占用CPU百分比 0.0% ni 用户进程空间内改变过优先级的进程占用CPU百分比 98.7% id 空闲CPU百分比 0.0% wa 等待输入输出的CPU时间百分比 0.0%hi:硬件CPU中断占用百分比 0.0%si:软中断占用百分比 0.0%st:虚拟机占用百分比
最后两行为内存信息。内容如下:
Mem: 191272k total 物理内存总量 173656k used 使用的物理内存总量 17616k free 空闲内存总量 22052k buff/cache 用作内核缓存的内存量 Swap: 192772k total 交换区总量 0k used 使用的交换区总量 192772k free 空闲交换区总量 123988k cached 缓冲的交换区总量,内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖,该数值即为这些内容已存在于内存中的交换区的大小,相应的内存再次被换出时可不必再对交换区写入。
进程信息区统计信息区域的下方显示了各个进程的详细信息。首先来认识一下各列的含义。
序号 列名 含义 a PID 进程id b PPID 父进程id c RUSER Real user name d UID 进程所有者的用户id e USER 进程所有者的用户名 f GROUP 进程所有者的组名 g TTY 启动进程的终端名。不是从终端启动的进程则显示为 ? h PR 优先级 i NI nice值。负值表示高优先级,正值表示低优先级 j P 最后使用的CPU,仅在多CPU环境下有意义 k %CPU 上次更新到现在的CPU时间占用百分比 l TIME 进程使用的CPU时间总计,单位秒 m TIME+ 进程使用的CPU时间总计,单位1/100秒 n %MEM 进程使用的物理内存百分比 o VIRT 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES p SWAP 进程使用的虚拟内存中,被换出的大小,单位kb。 q RES 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA r CODE 可执行代码占用的物理内存大小,单位kb s DATA 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb t SHR 共享内存大小,单位kb u nFLT 页面错误次数 v nDRT 最后一次写入到现在,被修改过的页面数。 w S 进程状态(D=不可中断的睡眠状态,R=运行,S=睡眠,T=跟踪/停止,Z=僵尸进程) x COMMAND 命令名/命令行 y WCHAN 若该进程在睡眠,则显示睡眠中的系统函数名 z Flags 任务标志,参考 sched.h
以下2个命令会很大的CPU使用,可以通过以下2个命令结合top命令观察CPU使用率
{ yes > /dev/null & } && sleep 30 && ps -ef|grep yes|awk '{print $2}' |xargs kill
for i in $(seq 0 $(($(cat /proc/cpuinfo |grep processor|wc -l)-1)));do taskset -c $i yes > /dev/null & done && sleep 30 && ps -ef|grep yes|awk '{print $2}'|xargs kill
常用命令
- -d 时间间隔
- -n 执行次数
- -p 查看指定端口的进程数据
- -b 批处理输出
- h 显示帮助画面,给出一些简短的命令总结说明
- k 终止一个进程。
- i 忽略闲置和僵死进程。这是一个开关式命令。
- q 退出程序
- r 重新安排一个进程的优先级别
- S 切换到累计模式
- s 改变两次刷新之间的延迟时间(单位为s),如果有小数,就换算成m s。输入0值则系统将不断刷新,默认值是5 s
- f或者F 从当前显示中添加或者删除项目
- o或者O 改变显示项目的顺序
- l 切换显示平均负载和启动时间信息
- m 切换显示内存信息
- t 切换显示进程和CPU状态信息
- c 切换显示命令名称和完整命令行
- M 根据驻留内存大小进行排序
- P 根据CPU使用百分比大小进行排序
- T 根据时间/累计时间进行排序
- W 将当前设置写入~/.toprc文件中
查看某进程下消耗CPU比较高的线程:
top -H -p pid
性能统计 perf_avg
统计某进程的cpu与mem,
- 要求统计n次,一次间隔1s,
- 最后输出平均cpu与mem数据。
- 字段之间用tab隔开,平均数与之前的数据错开一行
- 支持输入不同的进程标记来统计不同进程的数据
perf_avg() { top -b -d 1 -n $2 | grep -i "$1" \ --color=auto \ --line-buffered | awk ' BEGIN{OFS="\t"} { cpu+=$9; mem+=$10; print $9,$10 } END{ print ""; print cpu/NR, mem/NR } ' }
统计AliYunDun 5次的平均CPU与men
$ perf_avg AliYunDun 5 0.0 0.1 0.0 1.2 2.0 1.2 0.0 0.1 4.0 1.2 0.0 0.1 2.0 1.2 0.0 0.1 1.0 0.1 1.0 1.21 0.65

 浙公网安备 33010602011771号
浙公网安备 33010602011771号