
Python基础5--文件操作和集合
这篇博客来说一下python对文件的操作。
在Python中实现文件的读写操作其实非常简单,通过Python内置的open函数,我们可以指定文件名、操作模式、编码信息等来获得操作文件的对象,接下来就可以对文件进行读写操作了。这里所说的操作模式是指要打开什么样的文件(字符文件还是二进制文件)以及做什么样的操作(读、写还是追加),具体的如下表所示。
| 操作模式 | 具体含义 |
|---|---|
'r' |
读取 (默认) |
'w' |
写入(会先截断之前的内容) |
'x' |
写入,如果文件已经存在会产生异常 |
'a' |
追加,将内容写入到已有文件的末尾 |
'b' |
二进制模式 |
't' |
文本模式(默认) |
'+' |
更新(既可以读又可以写) |
对文件的操作分三步:
1、打开文件获取文件的句柄,句柄就理解为这个文件
2、通过文件句柄操作文件
3、关闭文件。
文件基本操作:

f = open('file.txt','r') #以只读方式打开一个文件,获取文件句柄,如果是读的话,r可以不写,默认就是只读,
#在python2中还有file方法可以打开文件,python3中file方法已经没有了,只有open
frist_line = f.readline()#获取文件的第一行内容,返回的是一个list
print(frist_line)#打印第一行
res = f.read()#获取除了第一行剩下的所有文件内容
print(res)
f.close()#关闭文件
请注意上面的代码,如果open函数指定的文件并不存在或者无法打开,那么将引发异常状况导致程序崩溃。为了让代码有一定的健壮性和容错性,我们可以使用Python的异常机制对可能在运行时发生状况的代码进行适当的处理,如下所示。
def main(): f = None try: f = open('file.txt', 'r', encoding='utf-8') print(f.read()) except FileNotFoundError: print('无法打开指定的文件!') except LookupError: print('指定了未知的编码!') except UnicodeDecodeError: print('读取文件时解码错误!') finally: if f: f.close()if name == 'main':
main()
打开文件时,需要指定文件路径和以何等方式打开文件,打开后,即可获取该文件句柄,后面通过此文件句柄对该文件操作,
打开文件的模式有:
r,只读模式(默认)。
w,只写模式。【不可读;不存在则创建;存在则删除内容;】
a,追加模式。【不可读; 不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
r+,【可读、可写;可追加,如果打开的文件不存在的话,会报错】
w+,【写读模式,使用w+的话,已经存在的文件内容会被清空,可以读到已经写的文件内容】
a+,【追加读写模式,不存在则创建;存在则只追加内容;】
"U"表示在读取时,可以将 \r \n \r\n自动转换成 \n (与 r 或 r+ 模式同使用)
rU
r+U
"b"表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注)
rb
wb
ab
文件操作方法:
f = open('file.txt','r+',encoding='utf-8')#encoding参数可以指定文件的编码
f.read()#读取文件所有内容,返回的是一个字符串
f.readline()#读一行
f.readable()#判断文件是否可读
f.writable()#判断文件是否可写
f.write('jmysdfsdf')#write是写内容,只能写字符串
f.writelines(['123\n','346'])#他写的是list
res = f.readlines()#返回的是一个list,list每个元素是文件的每一行
print(f.readline())#每次只取一行的内容
fr.encoding#打印文件的编码
f.read()#读取所有内容,大文件时不要用,因为会把文件内容都读到内存中,内存不够的话,会把内存撑爆
f.readlines()#读取所有文件内容,返回一个list,元素是每行的数据,大文件时不要用,因为会把文件内容都读到内存中,内存不够的话,会把内存撑爆
f.tell()#获取当前文件的指针指向
f.seek(0)#把当前文件指针指向哪
f.write('爱情证书')#写入内容
f.fulsh()#写入文件后,立即从内存中把数据写到磁盘中
f.truncate()#清空文件内容
f.writelines(['爱情证书','孙燕姿'])#将一个列表写入文件中
f.close()关闭文件
大文件时,读取文件高效的操作方法:
用上面的read()和readlines()方法操作文件的话,会先把文件所有内容读到内存中,这样的话,内存数据一多,非常卡,高效的操作,就是读一行操作一行,读过的内容就从内存中释放了
f = open('file.txt')
for line in f:
print(line)
这样的话,line就是每行文件的内容,读完一行的话,就会释放一行的内存
循环一个文件对象的时候,循环的是文件的每一行
for循环字典的时候,循环是他的key
i=1
for line in f:
print('第{hang}行:{line}'.format(hang=i,line=line))
i+=1
f.close()
with使用:
在操作文件的时候,经常忘了关闭文件,这样的就可以使用with,它会在使用完这个文件句柄之后,自动关闭该文件,使用方式如下:
with open('file.txt','r') as f:#打开一个文件,把这个文件的句柄付给f
for line in f:
print(line)
with open('file.txt') as fr,open('file_bak','w') as fw: #这个是多文件的操作,打开两个文件,fr是读file.txt,fw是新建一个file_bak文件
for line in fr:#循环file.txt中的每一行
fw.write(line)#写到file_bak文件中
修改文件:
修改文件的话,有两种方式,一种是把文件的全部内容都读到内存中,然后把原有的文件内容清空,重新写新的内容;第二种是把修改后的文件内容写到一个新的文件中
第一种
#修改文件的方式 # 1、先读出来所有的内容 # 2、修改内容 # 3、把原来的内容清空 # 4、把修改后的写入 f = open('a.txt','a+',encoding='utf-8') f.seek(0) res = eval(f.read()) res['wjx']=123456 f.seek(0) f.truncate() f.write(str(res)) f.flush()#将缓冲区内容写到磁盘中 print(res)
第二种
#1、打开俩文件,一个是要修改文件 文件1 第二个是一个空文件 文件2 #2、从要修改的文件1里读,把读到东西做修改,然后写到文件2里面 #3、文件1每一行的内容都处理完之后,文件2里面的东西就是修改之后的内容 #4、把文件名改一下,把旧的文件删掉 import os with open('file.txt') as fr,open('file_new.txt', 'w') as fw: # 这个是多文件的操作,打开两个文件,fr是读file.txt,fw是新建一个file_bak文件 for line in fr: # 循环file.txt中的每一行 new_line = line.replace('2', '3') fw.write(new_line) # 写到file_bak文件中 os.remove('file.txt') os.rename('file_new.txt','file.txt')
读写二进制文件
知道了如何读写文本文件要读写二进制文件也就很简单了,下面的代码实现了复制图片文件的功能。
def main(): try: with open('guido.jpg', 'rb') as fs1: data = fs1.read() print(type(data)) # <class 'bytes'> with open('吉多.jpg', 'wb') as fs2: fs2.write(data) except FileNotFoundError as e: print('指定的文件无法打开.') except IOError as e: print('读写文件时出现错误.') print('程序执行结束.')if name == 'main':
main()
读写JSON文件
JSON是“JavaScript Object Notation”的缩写,它本来是JavaScript语言中创建对象的一种字面量语法,现在已经被广泛的应用于跨平台跨语言的数据交换,原因很简单,因为JSON也是纯文本,任何系统任何编程语言处理纯文本都是没有问题的。目前JSON基本上已经取代了XML作为异构系统间交换数据的事实标准。关于JSON的知识,更多的可以参考JSON的官方网站,从这个网站也可以了解到每种语言处理JSON数据格式可以使用的工具或三方库,下面是一个JSON的简单例子。
{ 'name': '尘世风', 'age': 38, 'qq': 957658, 'friends': ['王大锤', '白元芳'], 'cars': [ {'brand': 'BYD', 'max_speed': 180}, {'brand': 'Audi', 'max_speed': 280}, {'brand': 'Benz', 'max_speed': 320} ] }
可能大家已经注意到了,上面的JSON跟Python中的字典其实是一样一样的,事实上JSON的数据类型和Python的数据类型是很容易找到对应关系的,如下面两张表所示。
| JSON | Python |
|---|---|
| object | dict |
| array | list |
| string | str |
| number (int / real) | int / float |
| true / false | True / False |
| null | None |
| Python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str | string |
| int, float, int- & float-derived Enums | number |
| True / False | true / false |
| None | null |
我们使用Python中的json模块就可以将字典或列表以JSON
import jsondef main():
mydict = {
'name': '尘世风,
'age': 38,
'qq': 957658,
'friends': ['王大锤', '白元芳'],
'cars': [
{'brand': 'BYD', 'max_speed': 180},
{'brand': 'Audi', 'max_speed': 280},
{'brand': 'Benz', 'max_speed': 320}
]
}
try:
with open('data.json', 'w', encoding='utf-8') as fs:
json.dump(mydict, fs)
except IOError as e:
print(e)
print('保存数据完成!')if name == 'main':
main()
json模块主要有四个比较重要的函数,分别是:
dump- 将Python对象按照JSON格式序列化到文件中dumps- 将Python对象处理成JSON格式的字符串load- 将文件中的JSON数据反序列化成对象loads- 将字符串的内容反序列化成Python对象
集合:
集合也是一种数据类型,一个类似列表东西,它的特点是无序的,不重复的,也就是说集合中是没有重复的数据
集合的作用:
1、它可以把一个列表中重复的数据去掉,而不需要你再写判断
2、可以做关系测试,比如说有两个班,一个性能测试班,一个是接口测试班的,想找出来既学习了性能又学习了接口测试的同学,就可以用集合
定义集合
list = [2,3,1,2,3,4]
s_list = set(list)#这样就定义了一个集合
set1 = set([1,3,4,5,6])#这种方式和上面的都是把list转换成一个集合
set2={'hehe','hehe1','hehe3'}#这种方式是直接定义一个集合
集合操作
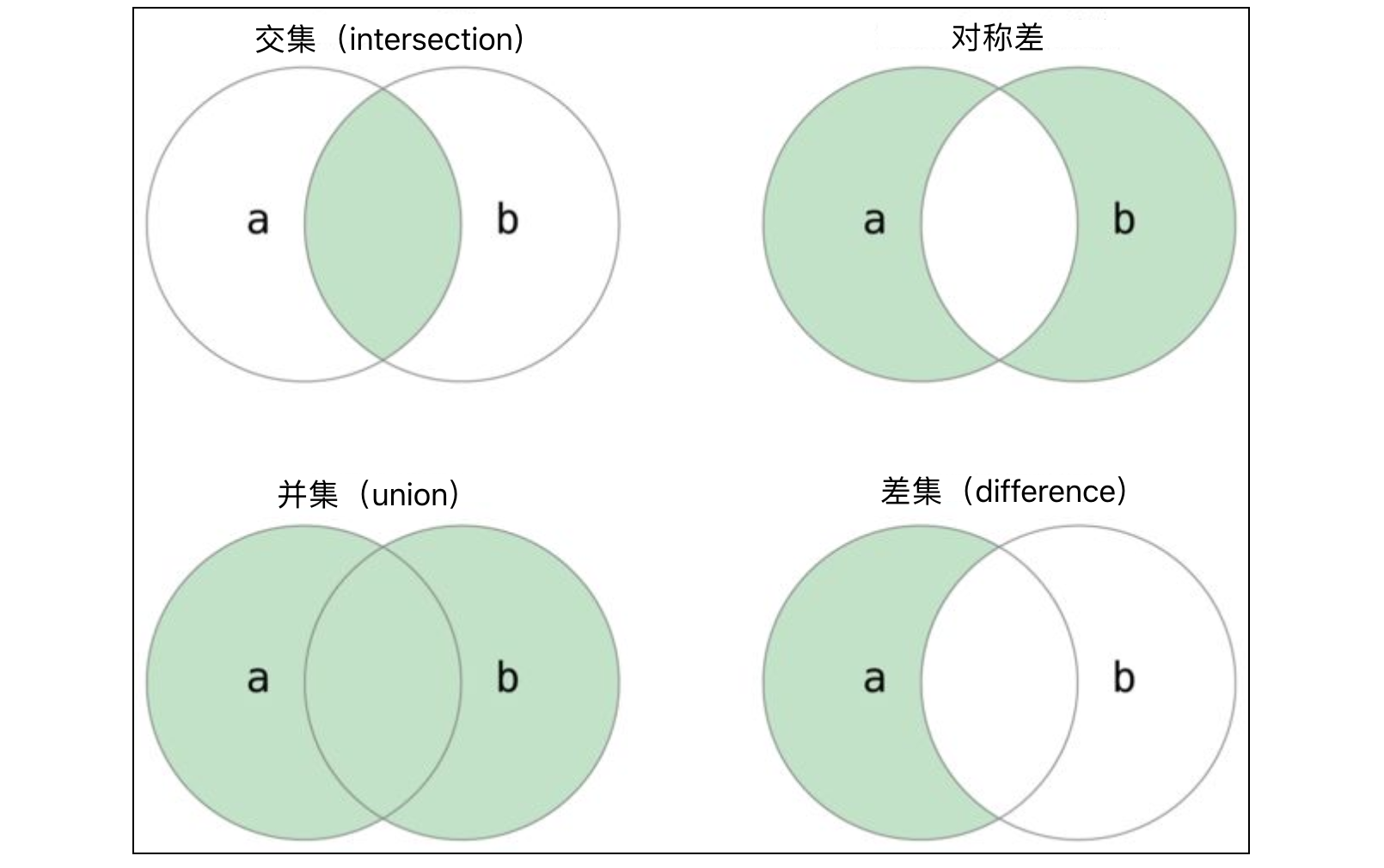
list1 = {1, 2, 3, 4, 5, 6, 9}
list2 = {2, 3, 4, 6, 1}
list3 = {1, 2, 3}
print(list1.intersection(list2)) # 取交集,也就是取list1和list2中都有的
print(list1 & list2)# 取交集
print(list1.union(list2)) # 取并集,也就是把list1和list2合并了,然后去除重复的
print(list1 | list2)# 取并集
print(list1.difference(list2)) #取差集 在list中存在,在list2中没有的
print(list1 - list2)
print(list3.issubset(list1))#判断list3是不是list1的子集
print(list1.issuperset(list3))#判断list1是不是list3的父集
print(list1.isdisjoint(list3))#判断list1和list3是否有交集,如果没有交集,返回True,否则返回False
print(list1.symmetric_difference(list2))#对称差集,输出两个列表中都没有的值,也就是把两个集合中相同的去掉
print(list1 ^ list2)#对称差集
list1.add(888)#添加元素
list1.update([777,666,666])#添加元素
list1.remove(777)#删除元素,如果元素不存在会报错
list1.pop()#删除一个随机的元素,并返回删除的元素
list1.discard('dddd')#如果删除的元素存在,删除,不存在不做处理
转载自https://www.cnblogs.com/feng0815/p/7588081.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号