
Python基础1-----Python简介和入门
☞写在前面
在说Python之前,我想先说一下自己为什么要学Python,我本人之前也了解过Python,但没有深入学习。之前接触的语言都是Java,也写过一些Java自动化用例,对Java语言只能说有所掌握,但离精通还有较大的距离。Java我先前也有学过,但我觉得学起来还是比较吃力的,特别在自学状态下。所以自从我了解了Python后,有种相见恨晚的感觉,觉得Python实在是太好用了,据我了解,目前从事测试和运维工作的同学,都在学习Python语言,本人一直从事测试工作,深刻体验到不会一门语言是多么无奈的一件事,所以此次接着学习自动化的时机,想深入学习一下Python语言。至于我为什么要学Python自动化?主要是因为Java自动化我学不会。。。。。
☞什么是python?
python是一种面向对象、解释型的计算机语言,它的特点是语法简洁、优雅、简单易学。它在哪里都能用,不管是电脑,手机还是网站服务器。世界上无数的人都在使用它。有句话说得好,Life is short, and I use python。它在1989诞生,Guido(龟叔)开发。这里的python并不是蟒蛇的意思,而是龟叔非常喜欢一部叫做《Monty Python飞行马戏团》的电视剧,所以以python命名(老外就是这么任性)。
当你用Python语言编写程序的时候,你无需考虑诸如如何管理你的程序使用的内存一类的底层细节。可移植性
由于它的开源本质,Python已经被移植在许多平台上(经过改动使它能够工作在不同平台上)。如果你小心地避免使用依赖于系统的特性,那么你的所有Python程序无需修改就可以在下述任何平台上面运行。
这些平台包括Linux、Windows、FreeBSD、Macintosh、Solaris、OS/2、Amiga、AROS、AS/400、BeOS、OS/390、z/OS、Palm OS、QNX、VMS、Psion、Acom RISC OS、VxWorks、PlayStation、Sharp Zaurus、Windows CE甚至还有PocketPC!
Python为我们提供了非常完善的基础代码库,覆盖了网络、文件、GUI、数据库、文本等大量内容,Python还有大量的第三方库。用Python开发,许多功能不必从零编写,直接使用现成的即可。
相对于Java、C来说,Python还是有自身的一些缺点,首先它运行速度慢,但这种慢可以忽略,比如一个应用程序如果用C语言0.01秒就能打开,而用Python可能就需要0.1秒才能打开,但由于网络、传输、前端渲染等所花费的时间远大于这点时间,而且基于Python又有这么多有点来说,这点完全可以忽略,don't care.
☞解释型语言和编译型语言
编译型语言就是先把写好的程序翻译成计算机语言然后执行,就是所谓的一次编译到处运行,比如c、c++就是编译型语言,这样的语言特点是运行速度快,但是需要事先把程序编译好才可以。
解释型语言就是程序在运行的时候,通过一个解释器,把代码一句一句的翻译成计算机语言然后运行,也就是你写好代码之后直接就能运行,比如说python、shell、ruby、java、perl等等都是解释型语言,当然这样的语言由于原理不一样,执行速度并没有编译型语言快。
☞选择python2.x还是python3.x?
现在python有2.x版本和python3.x版本,在选择版本这个事情上,很多人都是比较纠结的。到底选择2还是3,因为2和3代码是不怎么兼容的,现在比较常用的是2.7版本,2.7版本其实是一个过渡版本,在2008年的时候推出了3.0版本,由于3.0版本改动比较大,和2.x的版本不兼容,很多用python2的公司重写代码太费劲了,所以在同年又发行了2.6过渡版本的python,加入了一些3.0的特性,在2010年的时候发行了2.7版本,也是一个过渡版本,在2014年的时候python官方宣布2.7支持到2020年,以后不会再发行2.8版本,尽快把程序迁移到3.x版本。python2的默认字符集是ASCII编码,写中文会报错,字符编码一直是让程序员头疼的一件事情,python2在处理中文的时候的确比较头疼,在python3.x版本中默认字符集是Unicode,省了很多事,so,还是推荐使用python3.x版本。
☞字符集和字符编码
我们都知道,计算机其实只认识二进制0和1这两个数字,其他的都不认识,这样的0或1为一"位",也就是一bit,bit就是位。说完位顺便说一下字节、位、bit、byte、KB、B、M、T、字符之间有什么关系
bit就是位,也叫比特位,是计算机表示数据最小的单位
byte就是字节,1byte=8bit,1byte就是1B;
一个字符=2字节;
1T=1024M
1M=1024KB
1KM=1024B
1B=8bit
既然计算机只认识0和1,那怎么表示这些英文字母、以及汉字、标点符号呢?在回答这个问题前,先说一下字符集和字符集编码
那么什么是字符集呢?前面说到计算机只认识0和1,而我们在计算机上看到的有各国语言文字,这些文字最终都是通过二进制0和1转化过来的,这两者之间的转换就是通过字符集转换的,所以说字符集就是规定了某个文字对应的二进制数字存放方式(编码)和某串二进制数值代表了哪个文字(解码)的转换关系
字符集只是一个规则集合的名字,例如我们常见的UTF-8、Unicode、GB2312等这些都是字符集,对于一个字符集来说要正确编码转码一个字符需要三个关键元素:字库表(character repertoire)、编码字符集(coded character set)、字符编码(character encoding form)。其中字库表是一个相当于所有可读或者可显示字符的数据库,字库表决定了整个字符集能够展现表示的所有字符的范围。编码字符集,即用一个编码值code point来表示一个字符在字库中的位置。字符编码,将编码字符集和实际存储数值之间的转换关系。
简单来说,包括各国家文字、标点符号、图形符号、数字就相当于字符集,而将这些符号转换为计算机可以接受的数字系统编码就是字符编码
字符集有很多种,
我们知道,计算机是由美国发明的,所以最早的字符集也是有美国发明的ASCII字符集,它主要是基于拉丁字母的一套电脑编码系统,主要包括控制字符(回车键、退格、换行键等);可显示字符(英文大小写字符、阿拉伯数字和西文符号)
ASCII编码使用7位(bits)表示一个字符,共128字符,为了表示更多的欧洲常用字符对ASCII进行了扩展,ASCII扩展字符集使用8位(bits)表示一个字符,共256字符。ASCII字符集映射到数字编码规则如下图所示:
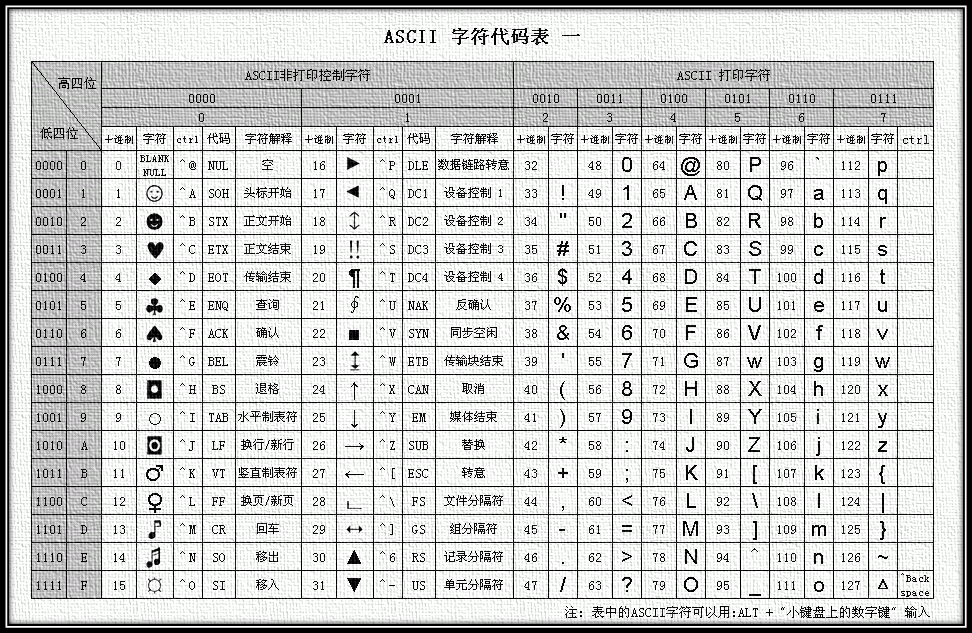
图1 ASCII编码表

图2 扩展ASCII编码表
ASCII的最大缺点是只能显示26个基本拉丁字母、阿拉伯数目字和英式标点符号,因此只能用于显示现代美国英语(而且在处理英语当中的外来词如naïve、café、élite等等时,所有重音符号都不得不去掉,即使这样做会违反拼写规则)。而EASCII虽然解决了部份西欧语言的显示问题,但对更多其他语言依然无能为力。因此现在的苹果电脑已经抛弃ASCII而转用Unicode。
那么问题来了,计算机认识英文了,那咱们天朝怎么办,天朝专家把那些127号之后的奇异符号们(即EASCII)取消掉,规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,取了127后面的一些数字后,只要遇到这个区间的数字,就知道是中文,去另一个编码表里面找,这个里面存的都是中文,还有其他国家的文件,比如说日文,韩文等等,这个叫做gb2312编码,它收录了6000+个汉字,这样的话,就可以解决计算机不认识中文的问题了。但是中国文化,博大精深,岂止有6000+个汉字,然后又有了gbk、Unicode、UTF-8等等编码,Unicode编码也叫万国码,哪个国家的文字都适用,但是它不管你是一个英文字母,还是一个汉字都是占2个字节大小,原来ASCII码一个英文字母就占一个字节,这一下变大了,原来100G的东西,现在可能得200G才存的下,这可不行,然后就又出现了UTF-8字符集,它也属于Unicode,和Unicode的不一样的是,它对Unicode做了压缩,比如说英文字母的还是占一个字节,这样的话,就节省的很多的空间,这就是为啥现在大家都用utf8的原因。

图3 GB2312编码表的开始部分
☞python安装
python怎么安装呢,这个是一个没有营养的话题,我就不写了,百度一下一堆堆的,要注意的就是,如果想使用python命令需要把python的安装目录加到环境变量中,windows下还要把python安装目录下的scripts目录加入到环境变量中,因为一些python的可执行命令,比如说pip,是安装在这个目录下的,linux下因为默认带python了,如果要升级版本的,要先把系统自带的python改名或者卸载掉,再安装你要的python版本,centos下由于yum依赖自带的python2.6,所有不能卸载,修改下yum脚本里面的python环境变量位置即可。
☞运行python代码X
Windows下,安装好python并且配置好环境变量之后,直接在命令行里面输入python就可以进入python交互式命令行了,linux下面也是一样,什么叫交互式呢,交互就是你给我说一句话,我回应你一句,这个就是交互,看下面的图,安装完python之后Python也自带了一个idle,也就是可以在它里面写代码,但是那个比较不好用,这里就不赘述了。

但是这样写代码实在是太不方便了,怎么把代码都写好了,然后一起运行呢,就是把代码都写到文件里面,然后运行文件,以.py结尾的就是python文件,有很多python的编辑器,比如说pycharm、sublime text、notepad++等等,都可以使用,使用编辑器有代码提示,可以很方便调试和运行,这里我推荐使用pycharm。新建一个python文件,然后写上代码,运行即可。
在linux下运行也是如此,和Windows下有一点不一样的是,liunx下可以直接运行python文件,前面不需要加python命令,加上执行权限即可,但是需要在python文件最前面指定python解释器,加上python解释器的路径即可,有两种写法,代码看下面,两种的区别是第一种是直接去你指定的目录下找python解释器,第二种是在自己配置的环境变量中去找python解释器,现在新建一个test.py的python文件
#!/usr/bin/python #这种写法是去/usr/bin目录下去找python的解释器,如果在这个目录下没有python解释器或者python解释器在别的目录下,就会报错了 print('Hello world!')</span><span style="color: rgba(0, 128, 0, 1)">#</span><span style="color: rgba(0, 128, 0, 1)">!/usr/bin/env python#这种写法是去环境变量中找你配置的python解释器目录,你配置在哪个目录下,它就去哪个目录下找python解释器</span> <span style="color: rgba(0, 0, 255, 1)">print</span>(<span style="color: rgba(128, 0, 0, 1)">'</span><span style="color: rgba(128, 0, 0, 1)">Hello world!</span><span style="color: rgba(128, 0, 0, 1)">'</span>)</pre>
下面是linux下的运行
[root@ebs-32534 ~]# chmod +x test.py [root@ebs-32534 ~]# ./test.py Hello world!
☞编写第一个程序
我相信,每个一个程序员在学习语言的时候,第一个写的程序肯定都是hello world,OK,那来写第一个程序吧,其实很简单,python的语法就是简单、优雅,一个print就搞定。
print('Hello world!')
在pycharm中执行如下:

注意:Python对空格很敏感,不同的域空格一定要保持一致,子域的空格一定要多于父域,在父域的后面,切记!
如下图所示,每个框都代表一个子域,每个域内的缩进必须相同,且子域要包含在父域内!

☞PyCharm快捷键
既然选择了用pycharm做Python开发,那么一些常用的快捷键还是要了解的
Ctrl + D 复制选定的区域或行
Ctrl + / 行注释
Ctrl + Alt + I 自动缩进行
Ctrl + Y 删除当前插入符所在的行
Ctrl + Delete 删除到字符结尾
Ctrl + Backspace 删除到字符的开始
Ctrl+t SVN更新
Ctrl+k SVN提交
Ctrl + 鼠标 简介
F8 跳过
F7 进入
Shift + F8 退出
Alt + F9 运行游标
Alt + F8 验证表达式
Ctrl + Alt + F8 快速验证表达式
F9 恢复程序
Ctrl + F8 断点开关
Ctrl + Shift + F8 查看断点
☞变量及调用
变量是干嘛的呢?说的简单点,就是存东西,供后面来用的。值得一提的是python变量里面存的是内存地址,如果再把这个变量赋值给另一个变量的话,新的变量通过之前那个变量知道那个变量值的内存地址存起来,而不是指向的之前那个变量。代码如下:
name = 'sriba' new_name = name #new_name存的也是sriba的内存地址
正常情况下,变量调用是传地址的,但可以用[:] 来只复制值
a = [1, 2, 3] b = a c = a[:] print(a,b,c,) print(id(a),id(b),id(c))#输出变量的地址
输出结果为
[1, 2, 3] [1, 2, 3] [1, 2, 3]
33432392 33432392 33431752
可以看出变量b和a的地址一样,也就是说b调用的是a的地址,若b的值改变,a的值也会改变,而c的地址已经变了,它调用的只是a的值,后面无论c的值怎么改变都不影响a的值。
变量的定义规则:
变量名最好要能见名知其意,不要随意起名,在Python中:
变量名可以是 字母、数字汉字或下划线的任意组合,变量名的第一个字符不能是数字
对,你没看错,Python可以用汉字当变量名,就是这么任性!比这还任性的是,python中定义变量很简单,一个等号搞定,也不需要指定数据类型,直接定义就好,如下图所示:

另外,Python中,多个变量可以同时定时定义,如下
a,b,c = 'chenshifeng','尘世风',666 print(a) print(b) print(c)
输出结果为
chenshifeng
尘世风
666
python中定义变量的时候字符串都用用引号括起来,单引号和双引号没有区别,用啥都行,如果说这个字符串里面有单引号的话,那你外面就用双引号,里面有双引号的话,外面就用单引号,如果既有单又有双,那么用三引号,三引号也可以多行注释代码,单行注释,使用#,代码如下:

1 print('我们,学python') 2 print("let's go")#有单引号,所以外面用双引号 3 print('"孤独"是生命的礼物')#有双引号,所以外面用单引号 4 print('''let's go "哇哈哈"''')#有双引号和双引号,所以外面用三引号 5 ''' 6 这里是注释 7 人生苦短,我要学Python 8 '''

和其他语言一样,Python也有它自己的关键字,以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally',
'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return',
'try', 'while', 'with', 'yield']
☞输入、输出
python怎么来接收用户输入呢,使用input函数,python2中使用raw_input,接收的是一个字符串,输出呢,第一个程序已经写的使用print,代码入下:
1 name=input('Please enter your name:') #把接收到的值赋给name变量 2 print(name)#输出接收到的输入
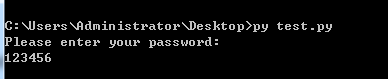
input在接收输入的时候,是可以看到你输入的值的,如果是输入密码这样的呢,不想让别人看到你的密码,怎么办呢,就需要用到一个标准库,getpass,什么是标准库呢,就是不需要你再去安装,装完python就有的库,就是标准库,getpass就是一个标准库,导入进来之后,直接使用getpass.getpass方法就可以在输入的时候,不回显了,代码如下:
1 import getpass #导入getpass模块 2 password = getpass.getpass('Please enter your password:') #接收输入的密码 3 print(password)
注,此模块在pycharm中无法使用,在命令提示符中可以使用,如下图
还有一点,在Python2.x中,由于默认编码不是utf-8,所以首行需加#coding=utf-8,而且输出可以用下面两种写法
#print xxx #在python2里面是的可以
# print("hello world!")
☞条件判断
python中条件判断使用if else来判断,多分支的话使用if elif ... else,也就是如果怎么怎么样就怎么怎么样,否则就怎么怎么这样,格式如下:
1 if 明天下雨: 2 那么明天带伞 3 else: 4 明天不带伞
python中是以缩进来表示代码块的,这样看起来代码很有条理,比如说上面的例子,如果明天下雨,那么明天才会带伞,明天带伞就相当于if的儿子,所以也可以认为有缩进的都是有父子关系的,写个实际点的例子,如下:
1 score = int(input('请输入你的分数:')) #接收输入,因为input接收的是一个字符串,所以需要用int函数强制类型转换成整数类型 2 if score==100: #如果成绩等于100分的话 3 print('小天才,你是满分') 4 elif score >=90 and score < 100: #如果成绩大于等于90分小于100分的话 5 print('兄弟,你的分数不低啊,不错') 6 elif score > 60 and score <90:#如果成绩大于60分小于90分的话 7 print('兄弟,这次考试马马虎虎啊') 8 else: #如果分数小于60分的话 9 print('兄弟,你在搞什么,该努力了')
☞循环
循环是干嘛的呢,说白了就是为你重复的去做事情,比如说你想建1000个文件夹,一个个建累死你, 这样就可以写段代码,使用循环给你创建1000个就省事了,python中有两种循环,while和for,两种循环的区别是,while循环之前,先判断一次,如果满足条件的话,再循环,for循环的时候必须有一个可迭代的对象,才能循环,比如说得有一个数组,值得一提的是,别的语言中,for循环的时候需要先定义一个计数器变量,然后从0开始加,直到这个计数器达到你预设的一个值,然后停止循环,取数据的时候也是通过数组的下标从0开始取,这样就很麻烦,python中for循环很简单,循环的是一个可迭代对象中的元素,你这个对象中有多少个元素,就循环多少次,比如说一个数组list,list = ['a','b','c'],在别的语言中要想获取到list中所有的值,必须得使用循环取下标这种方式去取数据,就得这样写list[x],list[x],list[x]这样,在Python里面就不需要直接循环就取的是这个list里面的值,循环里面还有两个比较重要的关键字,continue和break,continue的意思是,跳出本次循环,继续进行下一次循环,break的意思是停止循环,也就是说在continue和break下面的代码都是不执行的,格式如下:
1 #while 循环 2 count = 0 3 while count<10: #如果count小于10的话,就执行下面的代码,如果不小于3就走else 4 print(count) 5 if count==5: 6 break#如果count等于5的话,就结束循环 7 count+=1 #这个意思是每次循环完,count的值就加一,如果不加的话,条件就一直为真了,就死循环了,一直不停的循环 8 else:#这个else是可以不写的,意思就是说,如果条件不满足了去干嘛 9 print('条件没满足') 10 #for 循环 11 names = ['marry','lily','lilei'] 12 for name in names: 13 if name == 'lily': 14 contiune #如果名字等于lily的话,就不执行continue下面的代码了,再循环下一次 15 print(name) 16 else:#for也有个else,不过这个一般没人写它,意思是如果正常循环完了去做什么 17 print('over')
☞小练习
既然我们已经学了条件判断和循环,那就用它来练习练习,写个小游戏,猜数字的游戏,要求是这样,产生一个随机数字,1-100之间,接收用户输入,如果猜对了,游戏结束,猜大了,提示猜大了,小了提示猜小了。产生随机数模块使用random.randint(1,101),是一个标准包,导入使用即可,代码如下:
1 while True: 2 guess = input('请输入一个1-100之间的数字:') 3 guess = int(guess) 4 if guess>src_num: 5 print('你输入的太大了!') 6 elif guess<src_num: 7 print('你输入的太小了!') 8 else: 9 print('恭喜你,猜对了,数字是%d'%src_num) 10 break
☞格式化输出
什么是格式化输出呢,就是说把你的输出都格式化成一个样子的,比如说登录的欢迎信息,都是welcome to login,Marry. 每个用户登录都是这样欢迎,但是每个用户的用户名都是一样的,你不能一个用户就写一行代码吧,这就需要用到格式化输出了,有三种方式。
第一种是用“+”连接,直接把输出的字符串和变量连接起来就可以了;
第二种是用占位符,占位符有常用的有四种,%s、%d、%f和%r
- %s是后面的值是一个字符串
- %d是后面的值必须是一个整数
- %f后面是小数
- %r 万能统配符 (可以将后面给的参数原样打印出来,带有类型信息)
第三种是使用{}和fromat方法,这三种呢,官方推荐是使用format方法,不推荐使用第一种,第一种用加号的,会在内存里面开辟多个内存空间,而后面两种是只开辟一块内存空间,使用方式如下:
name = input('请输入你的名字:') print('你的名字是'+name) #使用加号连接 print('你的名字是%s'%name)#使用占位符 age = 18 print('我的名字是%s,年龄是%d岁.'%(name,age))#这种是里面有多个格式化内容的,前面那个是字符串,后面这个是整数,多个变量的后面跟值的时候必须要加上括号 print('我的名字是%r,年龄是%r岁.'%(name,age))#万能统配符 可以将后面给的参数原样打印出来,带有类型信息,输出name为字符串,age为整数 print('你的名字是{your_name}'.format(your_name=name)) #使用format格式化输出,{}里面的名字可以随便写但是要和后面的format中的名字保持一致,然后再把你前面定义的变量写到等号后面就可以了。 print('我的名字是{your_name},年龄是{your_age}岁.'.format(your_age=age,your_name=name))#{}format后的参数可以不按照顺序写 print('你的名字是{}'.format(name)) #{}里可以为空,format后直接填参数即可 print('我的名字是{},年龄是{}岁.'.format(name,age)) #{}为空时,参数默认按照顺序传递 print('我的名字是{1},年龄是{0}岁.'.format(age,name)) #{}里有数字时,参数按照数字大小从小到大传递,该方法可以多次调用
输出:
请输入你的名字:chenshifeng 你的名字是chenshifeng 你的名字是chenshifeng 我的名字是chenshifeng,年龄是18岁. 我的名字是'chenshifeng',年龄是18岁. 你的名字是chenshifeng 我的名字是chenshifeng,年龄是18岁. 你的名字是chenshifeng 我的名字是chenshifeng,年龄是18岁. 我的名字是chenshifeng,年龄是18岁.Process finished with exit code 0
扩展:关于format输出,还支持列表、字典的解包传递
namelist=['chenchen','lili','mingming','zhenzhen'] namedic={'name':'chenchen','gender':'male','age':18,'love':'running'} print('we name are:{}、{} and {}'.format(*namelist)) #列表的解包用*,数据按照顺序传递,多余的数据不传递 print('my name is {name},gender is {gender},age is {age}'.format(**namedic)) #字典的解包用**,{}里需写上参数,数据按照顺序传递,多余的数据不传递
输出:
we name are:chenchen、lili and mingming my name is chenchen,gender is male,age is 18Process finished with exit code 0
注:对于3.6及以上版本,新增了一个F-strings字符串格式化方式,使用方法如为 f'{变量名},具体如下
namelist=['chenchen','lili','mingming','zhenzhen'] namedic={'name':'chenchen','gender':'male','age':18,'love':'running'}name='chenshifeng'
age=18
print(f'my name is {name},age is {age},love{namedic["love"]},my friend are {namelist}')# 大括号里可以是表达式或函数
大括号内不能转义,不能使用''
print(f'my name is {name.upper()}')
print(f'result:{(lambda x:x+1)(2)}')
输出:
my name is chenshifeng,age is 18,loverunning,my friend are ['chenchen', 'lili', 'mingming', 'zhenzhen'] my name is CHENSHIFENG result:3
转载至https://www.cnblogs.com/feng0815/p/7531483.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号