
手把手教你蜂鸟e203协处理器的扩展
 蜂鸟e203 NICE协处理器
蜂鸟e203 NICE协处理器
NICE协处理器
赛题要求:
对蜂鸟E203 RISC-V内核进行运算算子(譬如加解密算法、浮点运算、矢量运算等)的扩展,可通过NICE协处理器接口进行添加,也可直接实现RISC-V指令子集(譬如P扩展、F/D扩展、V扩展、B扩展、K扩展等)
对于采用NICE协处理器接口进行的扩展实现,需要在蜂鸟软件开发平台HBird SDK中进行相关软件驱动的添加
-
实现思路:
- 1.硬件设计,编写相应的verilog文件,需要注意的是NICE协处理器定义了一些基本的接口;
- 2.编写驱动,通过内联汇编的伪指令.insn配置相关的驱动设置;
- 3.编写用于测试的.C文件。
-
参考示例:
- 背景: 假设有一个3行3列的矩阵按顺序存储在存储器中,每个元素都是32位的整数,目标进行逐行和逐列的累加和,若采用C语言调用主数据通路进行实现,基本思路是循环,按行/列读取各个元素然后相加得到各行/列的累加和,将其转换为汇编语言,则需要约上百个周期才能完成全部运算。

-
硬件实现:
(e203_hbirdv2-master\e203_hbirdv2-master\rtl\e203\subsys\e203_subsys_nice_core.v)->NICE协处理器工作机理:👇
- 请求通道:主处理器在流水线的EXU级时,将指令的编码信息和源操作数传输到协处理器。
- 反馈通道:协处理器告诉主处理器其已完成了该指令,并将结果反馈到主处理器。
- 存储器请求通道:协处理器向主处理器发起存储器读写请求。
- 存储器反馈通道:主处理器向协处理器写回存储器读写结果。
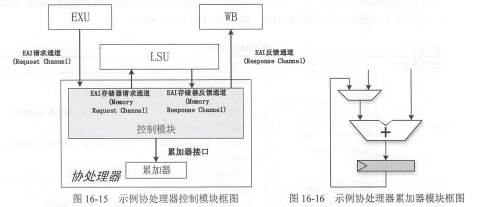
->NICE示例协处理器的设计:
控制模块(和主处理器通过NICE协处理器的接口进行交互)+累加器(累加运算)👆->NICE示例协处理器的自定义指令👇
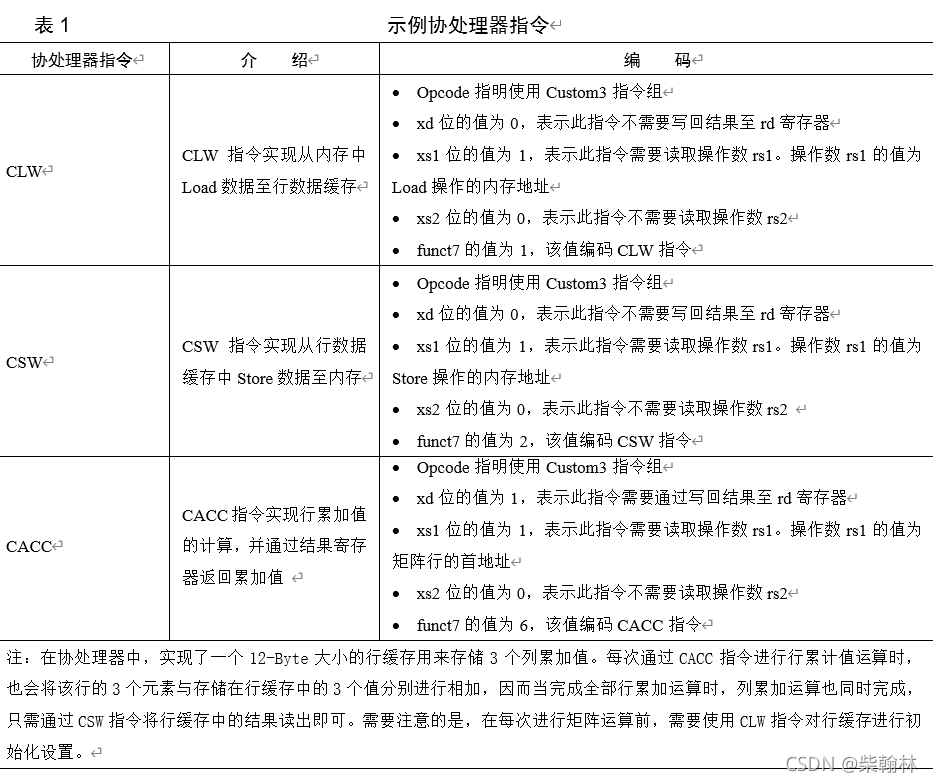
->verilog文件中包含内容:
自定义指令的编码+各模块功能实现(以状态机实现的转换) -
软件驱动:
(nuclei-board-labs-master\nuclei-board-labs-master\e203_hbirdv2\common\demo_nice\insn.h)
基本格式:
.insn r opcode, func3, func7, rd, rs1, rs2 //.insn告知编译器当前的指令是.insn形式的指令 //r用来表示指令类型为R-type //opcode、func3、func7、rd、rs1、rs2分别代表R类型指令格式的各位域具体实现:(累加和)
// custom lbuf __STATIC_FORCEINLINE void custom_lbuf(int addr) { int zero = 0; asm volatile ( ".insn r 0x7b, 2, 1, x0, %1, x0" :"=r"(zero) :"r"(addr) ); } // custom sbuf __STATIC_FORCEINLINE void custom_sbuf(int addr) { int zero = 0; asm volatile ( ".insn r 0x7b, 2, 2, x0, %1, x0" :"=r"(zero) :"r"(addr) ); } // custom rowsum __STATIC_FORCEINLINE int custom_rowsum(int addr) { int rowsum; asm volatile ( ".insn r 0x7b, 6, 6, %0, %1, x0" :"=r"(rowsum) :"r"(addr) ); return rowsum; }- 测试程序:(nuclei-board-labs-master\nuclei-board-labs-master\e203_hbirdv2\common\demo_nice\insn.c --> 功能实现;nuclei-board-labs-master\nuclei-board-labs-master\e203_hbirdv2\common\demo_nice\main.c --> 顶层文件,测试输出)
/***********************************insn.c*********************************/ // normal_case:通过主流水线来实现的累加操作 int normal_case(unsigned int array[ROW_LEN][COL_LEN]) { volatile unsigned char i=0, j=0; volatile unsigned int col_sum[COL_LEN]={0}; volatile unsigned int row_sum[ROW_LEN]={0}; volatile unsigned int tmp=0; for (i = 0; i < ROW_LEN; i++) { tmp = 0; for (j = 0; j < COL_LEN; j++) { col_sum[j] += array[i][j]; tmp += array[i][j]; } row_sum[i] = tmp; } } // nice_case:调用NICE协处理器实现的累加操作 int nice_case(unsigned int array[ROW_LEN][COL_LEN]) { volatile unsigned char i, j; volatile unsigned int col_sum[COL_LEN]={0}; volatile unsigned int row_sum[ROW_LEN]={0}; volatile unsigned int init_buf[3]={0}; custom_lbuf((int)init_buf); for (i = 0; i < ROW_LEN; i++) { row_sum[i] = custom_rowsum((int)array[i]); } custom_sbuf((int)col_sum); } /***********************************main.c*********************************/ // 主要就是调用两个函数然后输出结果 int main(void) { int i=100; int arr[4]={1,2,3,4}; unsigned int array[ROW_LEN][COL_LEN]= {{10,20,30}, {20,30,40}, {30,40,50} }; unsigned int begin_instret, end_instret, instret_normal, instret_nice; unsigned int begin_cycle, end_cycle, cycle_normal, cycle_nice; printf("**********************************************\n"); printf("** begin to sum the array using ordinary add sum\n"); begin_instret = __get_rv_instret(); begin_cycle = __get_rv_cycle(); normal_case(array); end_instret = __get_rv_instret(); end_cycle = __get_rv_cycle(); instret_normal = end_instret - begin_instret; cycle_normal = end_cycle - begin_cycle; printf("\n\n"); printf("**********************************************\n"); printf("** begin to sum the array using nice add sum\n"); begin_instret = __get_rv_instret(); begin_cycle = __get_rv_cycle(); nice_case(array); end_instret = __get_rv_instret(); end_cycle = __get_rv_cycle(); instret_nice = end_instret - begin_instret; cycle_nice = end_cycle - begin_cycle; printf("**********************************************\n"); printf("** performance list \n"); printf("\t normal: \n"); printf("\t instret: %d, cycle: %d \n", instret_normal, cycle_normal); printf("\t nice : \n"); printf("\t instret: %d, cycle: %d \n", instret_nice , cycle_nice ); printf("**********************************************\n\n"); printf("* * * * ***** * ******* *** \n"); printf("** * * * * * * * * \n"); printf("* * * * * * * * * \n"); printf("* * * * * * * ***** * \n"); printf("* * * * * * * * * \n"); printf("* ** * * * * * * * \n"); printf("* * ***** ***** ******* ******* *** \n"); printf("\n\n**********************************************"); return 0; }- 实际测试:
-
法一:(不推荐)通过.c文件配置工程,参考这里(5.3. 无模板手动创建项目)
-
法二:(推荐)
- 创建HelloWorld例程,删除左侧相应工程目录下application/main.c文件

- 将我们所编写的软件驱动文件和测试文件放入该目录下
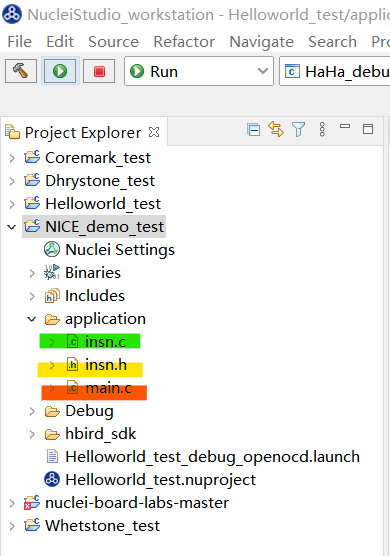
- 点击锤子🔨进行编译,做好硬件连接后,点击️️绿色的三角运行。
-
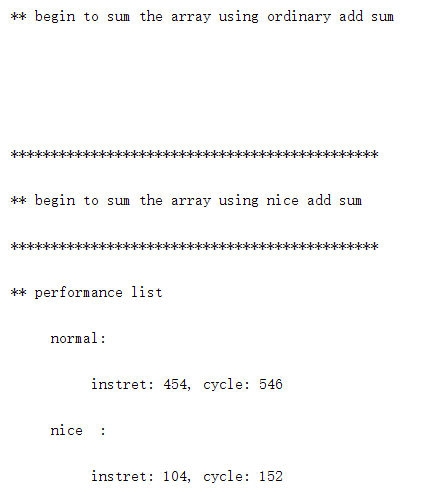
采用NICE协处理器进行的累加所用的指令数和周期数都远小于普通情况,如下图所示👇。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号