

7. Spark SQL
1.分析SparkSQL出现的原因,并简述SparkSQL的起源与发展。

一、spark产生的目的
spark产生:为了替代Mapreduce,解决Mapreduce计算短板
Hadoop生态体系:hdfs+zokeeper +mareduce/hive+hbase+storm+mahot+其他 工具;
spark体系:hdfs+zokeeper +spark+hbase+storm+mahot+其他 工具。
二、spark的设计初衷:
设计一个统一的计算引擎解决所有的各类型计算,包含计算类型:
1.离线批处理;
2.交互式查询
3.图计算
4.流失计算
5.机器学习/迭代计算
6.Spark R 科学计算,数据分析
三、spark和Mapreduce的对比之后的优势:
1.减少磁盘IO
MapReduce:基于磁盘
Spark 基于内存(尽量把临时数据缓存到内存)
2.增加并行度:
MapReduce:MapTask ReduceTask 一个进程一个Task(默认)
spark:ShuffleMapTask ResultTask 使用的是一个线程
3.避免重复计算:
可以吧把数据强制缓存到内存中,以供其他的task使用。
4.可选的shuffle和排序
4.1可选的shuffle
MapReduce:提供一种通用的shuffle
Combiner Partitioner sorter
shuffle的策略是一个固定的套路
如果设置了combiner会执行Combiner
如果设置的ReduceTask的个数超过1,那么Partitioner就会执行数据的分区;
如果有reducer节段的话,那么sortre的数据排序就一定会执行。
Spark的suffle:
提供了四重shuffle策略,分别适用不同的场景;
HaahShuffle,SortShuffle
4.2可选的排序:
MapReduce:如果有reducer节段的话,那么sortre的数据排序就一定会执行;
Spark:用户指定执行,否则不排序;
5.灵活的内存管理策略
要多少给多少,可以合理的分配到底哪个阶段哦,哪个组件,使用多少。
MapReduce:MapTask JVM在启动的时候就指定了最多能使用多少内存,如果超出OOM
Spark:worker启动了很多个进程executor,每个executor并发运行多个线程,每个线程执行一个程序;
每个executor和每一个task都会指定固定的内存大小去使用,如果excutor的内存固定,task的内存也有上限,也可能出现OOM
但是:spark的任务线程,出来能使用JVM的内存之外,还可以使用操作系统的内存。
Hadoop刚开始出来的时候,使用的是hadoop自带的分布式计算系统MapReduce,但是MapReduce的使用难度较大,所以就开发了Hive,Hive编程用的是类SQL的HQL的语句,这样编程的难度就大大的降低了,Hive的运行原理就是将HQL语句经过语法解析、逻辑计划、物理计划转化成MapReduce程序执行。当Spark出来以后,Spark团队也开发了一个Shark,就是在Spark集群上安装一个Hive的集群,执行引擎是Hive转化成Mapreduce的执行引擎,这样的框架就是Hive on Spark,但是这样是有局限性的,因为Shark的版本升级是依赖Hive的版本的,所有2014年7月1日spark团队就将Shark转给Hive进行管理,Spark团队开发了一个SparkSQL,这个计算框架就是将Hive on Spark的将SQL语句转化为Spark RDD的执行引擎换成自己团队从新开发的执行引擎。Spark SQL经历了几次的更新,演变历程如下:
-1 1.0版本以前
Hive on Spark Shark
-2 1.0.x版本
Spark SQL
Alpha版本(测试版本,不建议商业项目使用)
这个版本让Spark升为了Apache的顶级项目。
-3 1.3.x版本
SparkSQL DataFrame
Release(成熟,可以使用)
-4 spark 1.5.x版本
钨丝计划(底层代码的优化)
-5 spark 1.6.x版本
DataSet(alpha版本)
-6 Spark 2.x.x版本
DataSet(正式的)
Structrued Streaming
从发展历史来看会发现Spark的重要版本的变更都跟SparkSQL有关
2. 简述RDD 和DataFrame的联系与区别。
DataFrame和RDD之间相互转化
结构的区别
RDD 和 DataFrame 均为 Spark 平台对数据的一种抽象,一种组织方式,但是两者的地位或者说设计目的却截然不同。
RDD 是整个 Spark 平台的存储、计算以及任务调度的逻辑基础,更具有通用性,适用于各类数据源,
而 DataFrame 是只针对结构化数据源的高层数据抽象,其中在 DataFrame 对象的创建过程中必须指定数据集的结构信息( Schema ),
所以 DataFrame 生来便是具有专用性的数据抽象,只能读取具有鲜明结构的数据集
下图直观地体现了 DataFrame 和 RDD 的区别。
左侧的 RDD[Person] 虽然以 Person 类为类型参数,但 Spark 平台本身并不了解 Person 类的内部结构。
而右侧的 DataFrame 却提供了详细的结构信息,使得 Spark SQL 可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。
DataFrame 多了数据的结构信息,即 schema 。
RDD 是分布式的 Java 对象的集合, DataFrame 则是分布式的 Row 对象的集合。
DataFrame 除了提供了比 RDD 更丰富的算子操作以外,更重要的特点是利用已知的结构信息来提升执行效率、减少数据读取以及执行计划的优化,比如 filter 下推、裁剪等。
正是由于 RDD 并不像 DataFrame 提供详尽的结构信息,所以 RDD 提供的 API 功能上并没有像 DataFrame 强大丰富且自带优化,所以又称为 Low - levelAPI ,相比之下, DataFrame 被称为 high - level 的抽象,其提供的 API 类似于 SQL 这种特定领域的语言( DSL )来操作数据集。
使用场景的区别
RDD 是 Spark 的数据核心抽象, DataFrame 是 Spark 四大高级模块之一 Spark SQL 所处理数据的核心抽象,
所谓的数据抽象,就是当为了解决某一类数据分析问题时,根据问题所涉及的数据结构特点以及分析需求在逻辑上总结出的典型、普适该领域数据的一种抽象,一种泛型,一种可表示该领域待处理数据集的模型。
而 RDD 是作为 Spark 平台一种基本、通用的数据抽象,基于其不关注元素内容及结构的特点,我们对结构化数据、半结构化数据、非结构化数据一视同仁,都可转化为由同一类型元素组成的 RDD 。
但是作为一种通用、普适的工具,其必然无法高效、便捷地处理一些专门领域具有特定结构特点的数据,因此,这就是为什么, Spark 在推出基础、通用的 RDD 编程后,
还要在此基础上提供四大高级模块来针对特定领域、特定处理需求以及特定结构数据,
比如 SparkStreaming 负责处理流数据,进行实时计算(实时计算),
而 Spark SQL 负责处理结构化数据源,更倾向于大规模数据分析,
而 MLlib 可用于在 Spark 上进行机器学习。
因此,若需处理的数据是上述的典型结构化数据源或可通过简易处理可形成鲜明结构的数据源,且其业务需求可通过典型的 SQL 语句来实现分析逻辑,我们可以直接引入 Spark SQL 模块进行编程。
使用 RDD 的一般场景
你需要使用 low - level 的转化操作和行动操作来控制你的数据集;
你得数据集非结构化,比如,流媒体或者文本流;
你想使用函数式编程来操作你得数据,而不是用特定领域语言( DSL )表达;
你不在乎 schema ,比如,当通过名字或者列处理(或访问)数据属性不在意列式存储格式;
你放弃使用 DataFrame 和 DataSet 来优化结构化和半结构化数据集。
3.DataFrame的创建与保存
spark.read.text(url)

spark.read.json(url)

spark.read.format("text").load("people.txt")

spark.read.format("json").load("people.json")

4. PySpark-DataFrame各种常用操作
基于df的操作:
打印数据 df.show()默认打印前20条数据
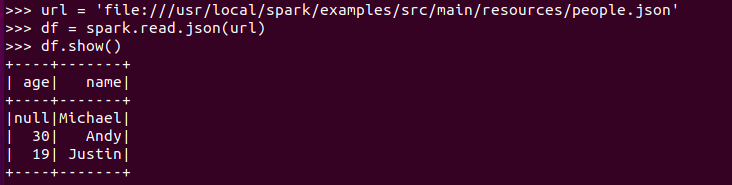
打印概要 df.printSchema()

查询总行数 df.count()
df.head(3) #list类型,list中每个元素是Row类
输出全部行 df.collect() #list类型,list中每个元素是Row类
查询概况 df.describe().show()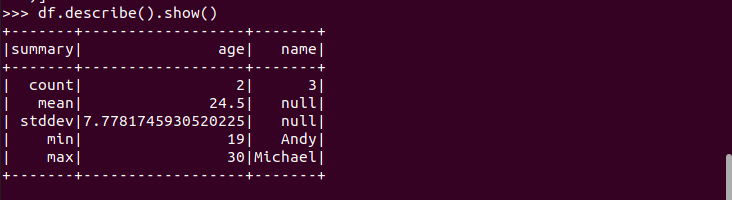
取列 df[‘name’], df.name, df[1]
基于sparksql的操作:
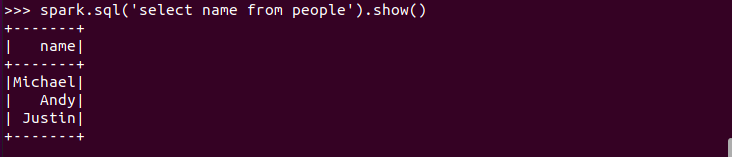
创建临时表虚拟表 df.registerTempTable('people')
spark.sql执行SQL语句 spark.sql('select name from people').show()
5. Pyspark中DataFrame与pandas中DataFrame
分别从文件创建DataFrame
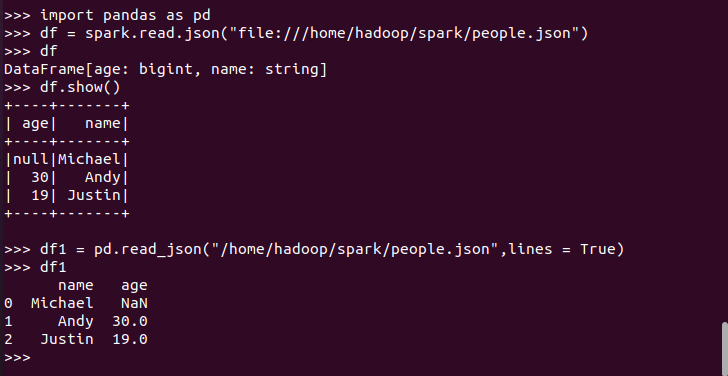
比较两者的异同
- 地址写法不同
- pyspark的df要通过操作查看结果
- pandas的df自动加索引
pandas中DataFrame转换为Pyspark中DataFrame
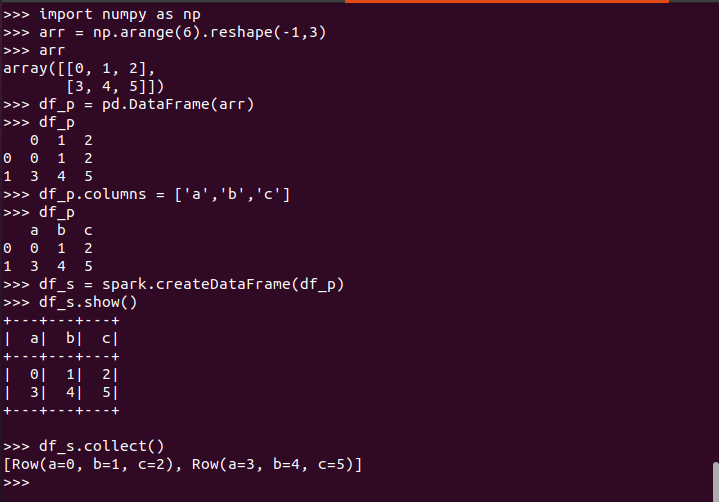
Pyspark中DataFrame转换为pandas中DataFrame

6.从RDD转换得到DataFrame
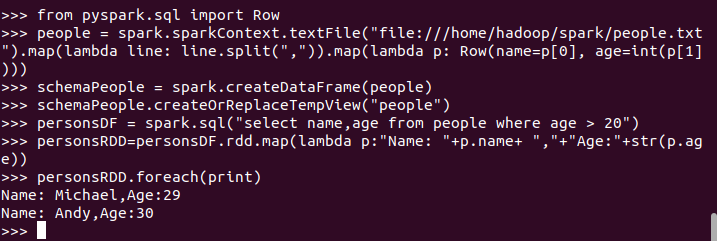
6.1 利用反射机制推断RDD模式
创建RDD sc.textFile(url).map(),读文件,分割数据项
每个RDD元素转换成 Row
由Row-RDD转换到DataFrame
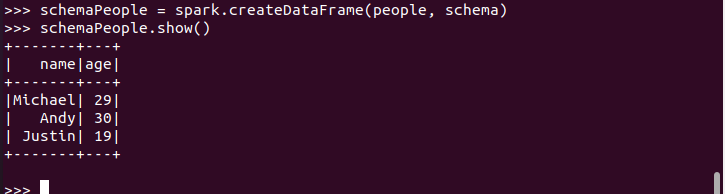
6.2 使用编程方式定义RDD模式
#下面生成“表头”

#下面生成“表中的记录”

#下面把“表头”和“表中的记录”拼装在一起
4.选择题:
4.1单选(2分)关于Shark,下面描述正确的是:C
A.Shark提供了类似Pig的功能
B.Shark把SQL语句转换成MapReduce作业
C.Shark重用了Hive中的HiveQL解析、逻辑执行计划翻译、执行计划优化等逻辑
D.Shark的性能比Hive差很多
4.2单选(2分)下面关于Spark SQL架构的描述错误的是:B
A.在Shark原有的架构上重写了逻辑执行计划的优化部分,解决了Shark存在的问题
B.Spark SQL在Hive兼容层面仅依赖HiveQL解析和Hive元数据
C.Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责
D.Spark SQL执行计划生成和优化需要依赖Hive来完成
4.3单选(2分)要把一个DataFrame保存到people.json文件中,下面语句哪个是正确的:A
A.df.write.json("people.json")
B.df.json("people.json")
C.df.write.format("csv").save("people.json")
D.df.write.csv("people.json")
4.4多选(3分)Shark的设计导致了两个问题:AC
A.执行计划优化完全依赖于Hive,不方便添加新的优化策略
B.执行计划优化不依赖于Hive,方便添加新的优化策略
C.Spark是线程级并行,而MapReduce是进程级并行,因此,Spark在兼容Hive的实现上存在线程安全问题,导致Shark不得不使用另外一套独立维护的、打了补丁的Hive源码分支
D.Spark是进程级并行,而MapReduce是线程级并行,因此,Spark在兼容Hive的实现上存在线程安全问题,导致Shark不得不使用另外一套独立维护的、打了补丁的Hive源码分支
4.5 多选(3分)下面关于为什么推出Spark SQL的原因的描述正确的是:AB
A.Spark SQL可以提供DataFrame API,可以对内部和外部各种数据源执行各种关系操作
B.可以支持大量的数据源和数据分析算法,组合使用Spark SQL和Spark MLlib,可以融合传统关系数据库的结构化数据管理能力和机器学习算法的数据处理能力
C.Spark SQL无法对各种不同的数据源进行整合
D.Spark SQL无法融合结构化数据管理能力和机器学习算法的数据处理能力
4.6多选(3分)下面关于DataFrame的描述正确的是:ABCD
A.DataFrame的推出,让Spark具备了处理大规模结构化数据的能力
B.DataFrame比原有的RDD转化方式更加简单易用,而且获得了更高的计算性能
C.Spark能够轻松实现从MySQL到DataFrame的转化,并且支持SQL查询
D.DataFrame是一种以RDD为基础的分布式数据集,提供了详细的结构信息
4.7多选(3分)要读取people.json文件生成DataFrame,可以使用下面哪些命令:AC
A.spark.read.json("people.json")
B.spark.read.parquet("people.json")
C.spark.read.format("json").load("people.json")
D.spark.read.format("csv").load("people.json")
6.选择题:
6.1单选(2分)以下操作中,哪个不是DataFrame的常用操作:D
A.printSchema()
B.select()
C.filter()
D.sendto()
6.2多选(3分)从RDD转换得到DataFrame包含两种典型方法,分别是:AB
A.利用反射机制推断RDD模式
B.使用编程方式定义RDD模式
C.利用投影机制推断RDD模式
D.利用互联机制推断RDD模式
6.3多选(3分)使用编程方式定义RDD模式时,主要包括哪三个步骤:ABD
A.制作“表头”
B.制作“表中的记录”
C.制作映射表
D.把“表头”和“表中的记录”拼装在一起
4.选择题:

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!