
从深度学习1.0到2.0: 新一代AI技术带给工业检测的新机遇https://www.zhihu.com/question/423493635
北京识渊科技有限公司首席科学家、牛津大学博士茹彬鑫
一.前言
从16年DeepMind的围棋AI AlphaGo的腾空出世到如今OpenAI的Chat GPT大杀四方,“深度学习”一跃成为热门词语,这一技术也得到了大量的关注。越来越多的企业提到自己使用了深度学习或人工智能技术,工业制造业尤其如此。本篇文章,我们将深度解析深度学习到底是什么?为什么可以帮助到人工智能技术?深度学习现有的局限性在哪里,未来将往什么样的方向发展?以及深度学习如何解决深度学习现有的问题,为工业视觉应用场景带来新的机遇。
二.深度学习
2.1深度学习是什么
深度学习和传统的机器视觉算法最大的不同就在于特征提取。传统的视觉学习算法,需要依赖人类的专家手动从数据中提取特征,基于这些提取的好的特征,用简单的算法进行判断或分类,选取例如模版匹配这一类的传统算法,进行判断或者处理(图2-1-1)。但是人工特征工程/提取是个很耗时繁琐的过程,往往需要大量反复的尝试,且提取效果因人而异,且总结的规则和经验也无法在不同任务之间复用,提取到的低纬度特征比较难区分不同的缺陷。而深度学习最大的特点便是利用深度神经网络从原始数据中自动学习提取特征,这不但避免了人工特征提取的问题,能学到更复杂抽象和更能泛化的特征,使得深度学习具有更好的通用性,同时特征的学习也会随着数据增加而提升,这使得学习算法会随着数据的质量和数量持续迭代提升性能,在很多任务上能达到更好的精度(图2-1-2)。
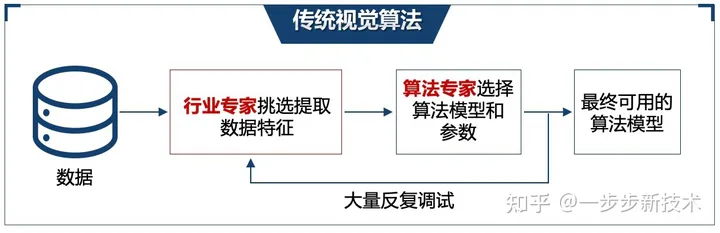
2-1-1 传统视觉算法示意图
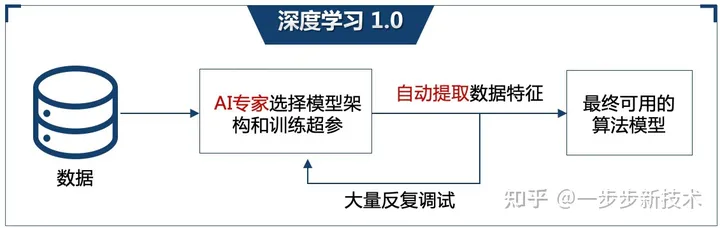
2-1-2 深度学习1.0示意图
2.2当前现状
以SMT AOI中的金板编程阶段为例,目前市面上所有的SMT AOI都需要人工进行金板编程,而这一过程的核心就是基于规则和经验,让编程人员来手动提取金板图片上元器件的各个特征,这些特征包括元器件的外框、焊锡区域、OCR文字区域,以及更详细的用于判断不同缺陷的子区域等等,除了区域选择,编程人员还需要对这些区域设定例如颜色、位移等容忍范围的阈值作为后续判定缺陷的规则。并且不同类型的元器件,这些特征区域和判定规则都不一样,所以需要每类器件都需要重新编程。这导致整个编程过程非常繁琐耗时,一块新金板的编程可能消耗几十分钟到几个小时不等。而且因为后面用于判断缺陷的算法,都依赖于人工编程提取的图片特征,最终AOI的稳定性/误报率也很依赖于编程人员的经验和判断。现在市面上已经有不少厂家尝试在做到一键编程去进行检测,但这些往往都是基于丰富的元器件库的导入达到的加速,所以整个过程的本质依旧是没变(图2-2-1)。这种做法依旧高度依赖于人工提取图片特征来进行缺陷比对,且在遇到新的未知元器件或者料号不准确时,元器件库的作用便无法发挥,又得回归到缓慢繁琐的人工画框调试。检测设备对于元器件库与人力的依赖依旧很高。
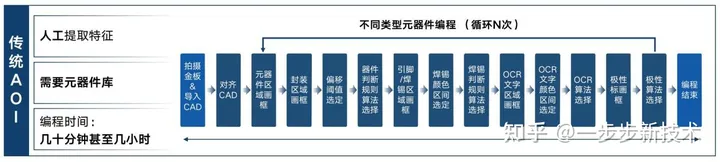
2-2-1 传统AOI流程示意图
2.3现有突破
真正的一键编程,是采用了深度学习来自动提取图片特征后,在不需要元器件库的情况下实现的。AOI中的深度学习算法在不需要任何额外训练的情况下,可以自动准确地检测出客户提供的不同金板上不同元器件以及其重要组成区域(封装、焊盘、引脚、OCR和极性等),而且需要在后续判断缺陷中也使用深度学习算法,这样编程不需要像传统AOI一样人为确定颜色容忍度,进步大大简化了编程流程,提高了编程的效率。所以只有真正基于深度学习的AOI,实现了真正意义上的自动一键编程,将金板编程所需要的时间缩短到了几十秒到几分钟。根据图2-3-1所示,红色代表AI算法自动完成,蓝色是人工参与的部分,可以看到深度学习的AOI设备的金板基本不需要人工参与,因此对编程人员的培训也变得非常简单。此外,在编程阶段深度学习算法的持续训练和提升,也能直接惠及到所有的客户用户的应用上。
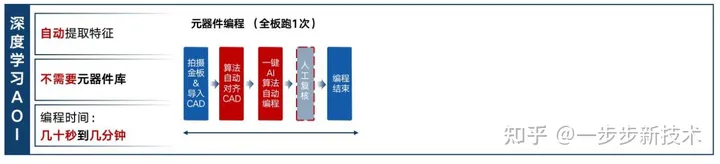
2-3-1 深度学习AOI流程示意图
然而要让深度学习模型达到这个效果,只通过简单地用数据训练一些经典的神经网络是远远不够的。这就衍生到了如何来辨别人工智能的技术门槛:如何区分简单地使用了人工智能,和真正地懂和能自研创新人工智能。 随着人工智能算法的普及和代码工具链的开源,用一些经典的深度神经网络来做一些常规检测、识别、分类等任务已经变得非常容易。基本上了解一些人工智能的背景知识,找到这些经典模型的开源代码,将自己的数据改成对应的格式就可以使用深度学习,但这样简单的使用往往效果不会非常理想。因为这些其实只是AI技术的冰山一角 (图2-3-2),这边我列出了AI顶级会议NeurIPS中的科研课题,可以看到除了纯用标注数据训练的深度神经网络之外, AI技术还包括了很多很多。

2-3-2 AI技术的冰山一角
所以能简单的使用经典深度学习模型很容易,但是要能理解AI众多多元化的技术领域并且能融汇贯通,然后针对特定的应用场景,挑选、定位到合适的算法组合门槛就高很多了,而能改进现有的深度学习算法作出自主创新的解决方案那设计的门槛就非常高,不仅仅需要1-2个专业的个人更需要一整个专业AI团队。下面我就从深度学习的几个关键环节出发结合几个例子来给进一步阐述这一点。
深度学习的开发流程往往包含一下几个关键环节:1)数据处理,2)神经网络模型选择,3)模型训练目标&策略的设计,4)模型推理部署。每一个环节都涵盖了许多深度学习技术。我们在开发SMT-AOI的过程中,对每一个环节都引入了许多前沿的深度学习技术,把每个环节都做到极致。
例如:神经网络模型选择环节。随着在过去几年中,海量的、多元化的视觉模型被开发出来,(从经典的ResNet到轻量级的MobileNet/EfficientNet到新兴的Vision Transformer),不同神经网络架构有不同的优势特点、适用于不同应用场景,广泛的选择也意味着需要更专业的知识才能根据应用场景选择出正确的网络。 例如针对SMT电路板上不同类型元器件的外形特征差异巨大,有的有OCR极性有的没有,一个单一的神经网络往往无法适用所有类型的器件 。因此,我们识渊设计了混合专家模型mix of experts(图2-3-3), (单个大模型中包含了擅长不同检测任务的子网络/小专家),整个模型能根据不同的输入图片,激活不同子模型,从而应对不同类型的器件的检测
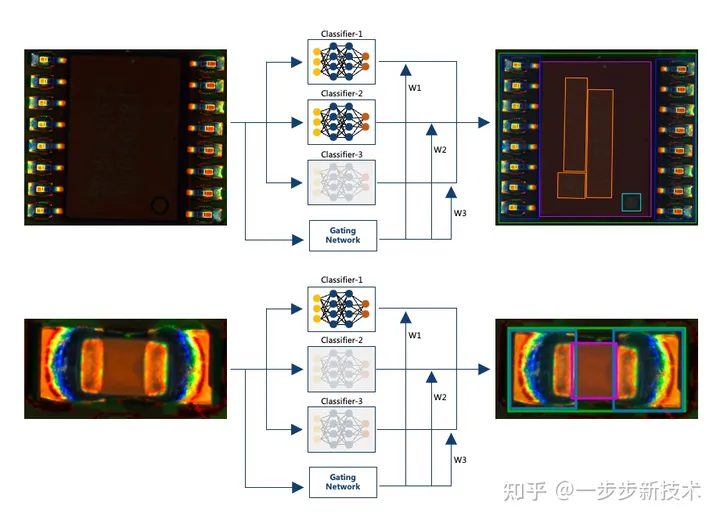
2-3-3 mix of experts模型
又例如模型推理部署:训练好的深度学习模型会部署到工控机进行实时预测。我们根据工控机的硬件限制,对模型进行了进一步优化(图2-3-4),通过知识蒸馏和量化减枝等技术,让模型在保持精度的同时,变得更轻便更快速,提高检测的效率。
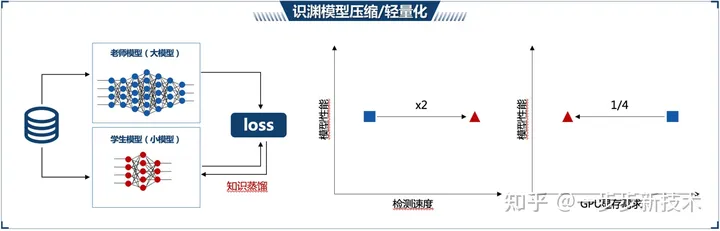
2-3-4 模型优化
正是以为我们具备足够的AI自研能力和技术积累, 我们才能通过这一系列的AI技术巧妙的融合和创新改进,让深度学习算法在SMT AOI这个产品中发挥作用,让产品达到满意的效果,真正突破性地解决AOI检测中困扰已久的难题。三.深度学习的局限性与未来3.1深度学习的局限3.1.1对模型架构和超参极度敏感 上一章的内容展现了深度学习的开发流程的每个环节都涉及到很多模型架构和超级参数的选择,他们就像一个个的转扭,对深度学习算法的最终性能影响很大,如果调试的不好,往往无法让深度学习达到预期的效果,甚至发现深度学习的性能还不如传统算法。想要准确地设计优化它们其实需要较高的AI专业知识、项目经验以及耗时耗力的反复尝试。这一痛点在工业视觉场景中会进一步放大,因为:工业检测任务往往高度碎片化、多样化的需求,不同人物差异巨大,需要定制,而定制AI解决方案所需要的人力和时间成本非常昂贵;工业检测任务的数据与常用的深度学习研究数据差异比较大,意味着其他深度场景下最优的模型和参数并不一定适用于工业检测任务;工业场景往往需要优化多个需求目标和/或多个硬件限制(例如,检测精度,检测速度,工控机算力上限),大大增加了优化的难度,因为人工调试时很难同时平衡多个指标;这个局限性导致大家在工业检测任务上用深度学习时,往往无法达到预期的效果。3.1.2对误判过度自信目前常见的深度学习算法普遍以一个黑盒的形式呈现:根据输入的数据,算法反馈给用户一个预测的答案,但是无法解释其判断的依据,且在遇到训练数据类型不同的未知数据或异常样本时,深度学习容易盲目自信,很肯定地给你一个错误的判断,误导人类用户。(图3-1-2)(例子,狗,猫,熊猫),并对自己的错误判断表示极度自信。

在工业缺陷检测场景中,也是如此,一旦产线上可能会出现之前训练数据中从未出现过的缺陷类型类型,深度算法会将这些样本盲目地归类到训练数据中已知的缺陷类型,并对自己的错误判断表示极度自信,而不是提醒人类用户有异常样本的存在,可能需要分开处理或更新模型。
这个局限性让大家对AI解决方案的可靠性产生质疑,导致一些高风险、高成本的工业视觉应用不敢直接用深度学习。
3.1.3对数据量需求高
先前提到深度学习的最大优势就是能从数据中自动学习提取特征,而发挥这个优势往往需要依靠大量的数据进行训练,这也是大家最熟知的深度学习的一个痛点。不同于数据丰富的安防或者互联网场景,工业检测场景通常是数据量很少,我们称为小样本场景:尤其是缺陷样本更加稀缺,且不同缺陷类别样品数量的分布非常不均衡,有的比较常见,有的非常少见。这大大增加了深度学习在工业检测场景的应用难度和数据收集成本,甚至直接劝退了很多人来考虑使用深度学习。
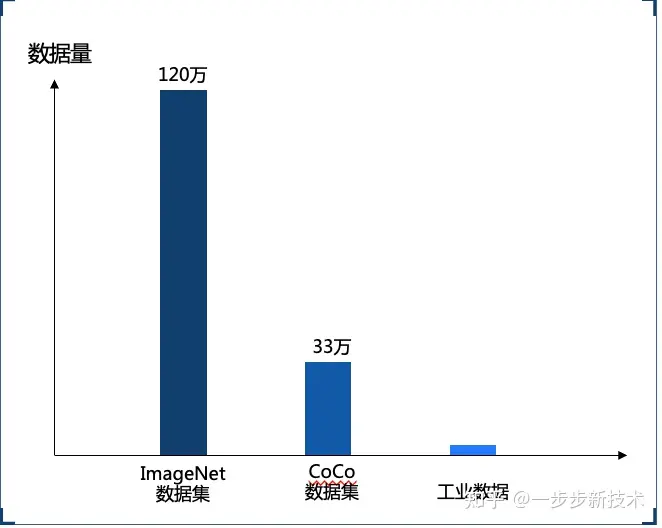
3-1-3 需要大量标注数据来训练模型
3.2 深度学习2.0的未来
伴随着深度学习以及其他AI领域关键技术的进步,新一代的深度学习技术(深度学习2.0) 已经很大程度上解决了这些局限性,让深度学习更易用、好用且适用于工业视觉应用场景。接下来我将会介绍几个我称之为深度学习2.0技术的方向,不会深入技术本身,而是解释主要的核心概念并结合例子与大家探讨深度学习2.0在工业检测领域的应用前景。
3.2.1让AI开发更自动化
AutoML算法(自动化机器学习)旨在让AI算法来代替人类AI工程师,自动高效地完成这些深度学习开发过程的重要环节。这为工业检测场景带来的变革是:
- 降低AI方案的开发门槛,加速定制效率:之前我们需要了解很多AI模型的知识才能准确地根据任务数据类型和需求选择对的模型,现在可以利用AutoML,只需要十几小时就可以个让AI自己根据任务数据和目标,设计最优的模型结构,且性能能超越人类AI专家手动设计的网络。这大大降低定制化AI方案所需要的专业知识门槛,以及开发所需的时间和成本。
- 平衡多个目标,辅助硬件适配。不同深度学习算子在不同芯片硬件上的部署效果不同。对于有国产化硬件要求的工业任务,我们识渊的AutoML算法AutoML可以辅助我们,针对不同国产AI芯片的特点和限制,高效优化深度学习模型,提高其在不同国产硬件上的部署性能。
- 底层黑盒优化算法应用潜力巨大:不仅局限于优化深度学习的多个环节,在材料筛选、EDA、工业/半导体设计、生产流程优化等众多场景都可解决高难度优化问题。例如在我们自研的智能光源中,我们就利用AutoML的底层算法优化了100多个维度的光照参数,能根据不同的被测物体,快速自动找到了最优的缺陷打光。
深度学习1.0带来的变革是将传统算法中的特征提取自动化,从而不需要人类专家手动提取特征,那么AutoML驱动下的深度学习2.0,解放我们的双手,将深度学习模型的选择、设计和优化自动化,不需要AI专家手动调试,将会让深度学习在工业视觉方向的通用性和泛化性迈上一个新的台阶。
3.2.2 让 AI更可信和更安全
第二类深度学习2.0算法,旨在让。这些AI算法通过改进深度学习的模型或者处理模型的输出,能让深度学习在给出预测的同时,也告诉我们算法对自身判断有多不确定,从而帮助人类用户精准识别出产线上的异常数据,在高风险应用中提示引入额外人工复检的必要,保障方案的可靠性。例如,算法之前只见过虚焊、歪斜和OK,在遇到错件时,我们的可解释算法虽然会给出一个错误的缺陷分类,但也会输出更高的不确定性,来提示我们这些异常/未知缺陷。
此外,随着一些可解释AI技术的发展,我们现在也可以在很多情况下打开深度学习的黑盒,让算法进一步向人类用户提供/解释其判断的依据,辅助人工复查,进一步提升深度学习在高风险高成本的工业视觉领域的可信度。
在很多类似军工这类的对数据保密有需求的场景,联邦学习等隐私计算相关的AI技术近年来也有了很大的进步和突破。例如我们在不同客户处部署同一个AI模型,然后只让模型回传更新的梯度信息而非数据,在云端整合信息统一更新模型后,再将新模型更新下发到各个客户本地。让我们可以在无需获取客户真实数据的前提下,依然对AI模型进行分布式训练和更新。
3.2.3 让AI数据依赖更低
深度学习对于数据的依赖也已经从供给和需求侧被大幅度缓解。
在供给侧,AI内容生成算法AIGC(例如:近期爆火的StableDiffusion和ChatGPT)在艺术创作、内容生成方面引起了巨大的反响,在工业检测方面,这类生成算法也有很大的应用前景。例如,我们就自研AIGC模型,根据SMT缺陷描述,生成逼真的缺陷数据,来辅助检测模型训练,缓解了SMT缺陷检测中不同真实数据样本分布不均衡、采集成本高的痛点。
在需求侧,无监督/自监督/半监督等学习策略的持续进步也让深度学习算法本身对数据的依赖大大减少。例如,在一个锂电池表面缺陷检测任务上,我们自研的无监督缺陷检测算法,只依赖ok样本,不需要任何缺陷数据,进行训练,就可以准确地检测表面缺陷区域。而在我们的另一个智能光源项目中,我们设计的无监督目标也让我们在不知道缺陷具体位置和类型的情况下,高效自动地优化打光,怕出高质量的缺陷图。
以上这些深度学习1.0和2.0的技术,我们也会集成到我们识渊科技自研的算法平台和训练平台中,帮助我们的客户更好地完成多种定制化工业检测项目,并且提供无代码模式,方便用户使用平台进行开发。






【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2020-10-16 设置工控机,避免相机休眠等造成取图报错