

JUC学习总结
JUC
1.JUC概述
1.1 JUC
JUC是java.util.concurrent包,就是java并发编程包。
1.2进程与线程
进程是计算机中程序关于某数据集合的一次运行活动,程序一旦运行起来就是进程
线程是包含在进程之中,是程序执行的最小单位,一个进程内可以并发多个线程
1.3线程的状态
1.3.1线程状态枚举类
Thread.State:NEW(新建)、RUNNABLE(准备就绪)、BLOCK(阻塞)、WAITING(不见不散)、TIME_WAITING(过期不候)、TERMINATED(终结)
1.3.2 wait/sleep的区别
(1)sleep是Thread中的静态方法
wait是Object的方法,任何对象实例都能调用
(2)sleep不会释放锁,它不需要占用锁
wait会释放锁,但是调用它的前提是自己已经被锁住
(3)都会被interrupt方法打断
(4)wait在哪里睡就在哪里醒
1.3.3并发和并行
(1)串行模式:
----口----口----口---
一个一个执行
(2)并行模式
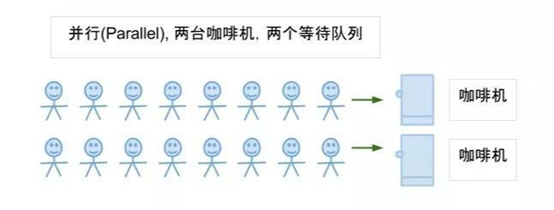
(3)并发模式
会分配时间片,同时访问同一个资源

1.3.4管程(监视器/锁)
是一种同步机制,保证同一时间,只有一个线程访问被保护的资源
Jvm的同步是基于进入和退出,是使用管程对象来实现的,进入的时候加锁,退出的时候解锁
1.3.5用户线程和守护线程
用户线程:自定义的线程
守护(Deamon)线程:比如垃圾回收,运行在后台
当主线程结束了,用户线程还没结束,JVM就不会结束;但是守护线程就算没结束,主线程结束了,JVM就会结束
2.Lock接口(sychronized和ReentrantLock的使用)
2.1 Synchronized锁
Synchronized是Java的一个关键字,是一种同步锁,可以用于修饰一段代码块或者一个方法。当修饰代码块的时候,作用范围就仅仅只是里面的代码块;而修饰方法的时候,作用范围就是整个方法,作用的对象就是调用这个方法的对象,也就是说,锁住的是整个对象。
当修饰方法的时候,Synchronized关键字不能被继承,子类必须显式调用Synchronized关键字才能加锁。
2.2多线程编程步骤
2.2.1创建资源类,在资源类创建属性和操作方法
就类似空调,空调中有自己的元件(属性),也有他的制冷制热等功能(操作方法)。
2.2.2在资源类操作方法中定义:
(1)判断
(2)干活
(3)通知
2.2.3创建多个线程,调用资源类的操作方法
卖出很多空调,每个空调都能制冷制热
2.2.4防止虚假唤醒问题
2.3 Lock接口
JUC中提供的一个接口,可以手动的实现上锁和解锁。
实现类:可重入锁 ReentrantLock
可以使用lock方法和unlock方法进行上锁与解锁
- public class LSellTicket {
- public static void main(String[] args) {
- LTicket ticket = new LTicket();
- new Thread(new Runnable() {
- @Override
- public void run() {
- for (int i=0;i<10;i++) {
- ticket.sell();
- }
- }
- },"first").start();
- new Thread(new Runnable() {
- @Override
- public void run() {
- for (int i=0;i<10;i++) {
- ticket.sell();
- }
- }
- },"second").start();
- new Thread(new Runnable() {
- @Override
- public void run() {
- for (int i=0;i<10;i++) {
- ticket.sell();
- }
- }
- },"third").start();
- }
- }
- class LTicket {
- private int number = 30;
- private final ReentrantLock lock = new ReentrantLock();
- public void sell() {
- // 加锁
- lock.lock();
- try {
- if (number > 0) {
- number-=1;
- System.out.println(Thread.currentThread().getName() + " 剩余票数: " + number);
- }
- } finally {
- // 解锁
- lock.unlock();
- }
- }
- }
Lock和Synchronized的区别:
Lock不是Java语言内置的,通过这个类可以实现同步访问。而Synchronized是Java语言内置的关键字,因此是内置特性。
Lock需要用户去手动解锁,如果不解锁,会产生死锁的情况;而Synchronized是当代码块或者方法执行完之后,自动解锁
Lock可以让等待锁的响应中断,而Synchronize却不行,使用sychronized的时候,等待的线程会一直等待下去
通过Lock可以知道有没有成功获取锁,但synchronized却不可以
Lock可以提高多个线程进行读操作的效率
3.线程间通信(判断 干活 通知)
参照多线程编程第二步:
在多线程编程中,要在方法内做三件事:判断、干活、通知
判断就是判断是否符合操作的条件,如果不符合就调用wait方法或者await方法等待;
干活就是如果符合判断条件了,就进行操作,操作完成后就唤醒其他引用对象,让他们唤醒并判断操作;
通知就是唤醒其他引用对象,调用1.notify或者notifyAll方法,2.signal或者signalAll进行通知
当使用lock的时候,不能直接调用当前方法中的Condition的signalAll方法,而是应该调用你要唤醒的对象的signal或者signalAll方法
Synchronized实现(wait和notify):
- public class ThreadDemo1_sync {
- public static void main(String[] args) {
- Share share = new Share();
- new Thread(()-> {
- for (int i=0;i<10;i++) {
- try {
- share.add();
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- System.out.println("01完毕");
- },"01").start();
- new Thread(()-> {
- for (int i=0;i<10;i++) {
- try {
- share.minus();
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- System.out.println("02完毕");
- },"02").start();
- }
- }
- class Share{
- private int num = 0;
- public synchronized void add() throws InterruptedException {
- if (num != 0) {
- this.wait();
- }else {
- num+=1;
- System.out.println(Thread.currentThread().getName() + " " + num);
- this.notifyAll();
- }
- }
- public synchronized void minus() throws InterruptedException {
- if (num != 1) {
- this.wait();
- }else {
- num-=1;
- System.out.println(Thread.currentThread().getName() + " " + num);
- this.notifyAll();
- }
- }
- }
Lock实现(condition的await和signal):
- public class ThreadDemo1_lock {
- public static void main(String[] args) {
- Share share = new Share();
- new Thread(() -> {
- for (int i=0;i<10;i++) {
- share.add();
- }
- },"first").start();
- new Thread(() -> {
- for (int i=0;i<10;i++) {
- share.minus();
- }
- },"second").start();
- }
- }
- class Share{
- private int number = 0;
- ReentrantLock lock = new ReentrantLock();
- Condition condition = lock.newCondition();
- public void add() {
- lock.lock();
- try {
- while (number != 0) {
- condition.await();
- }
- number+=1;
- System.out.println(Thread.currentThread().getName() + " " + number);
- condition.signalAll();
- } catch (InterruptedException e) {
- e.printStackTrace();
- } finally {
- lock.unlock();
- }
- }
- public void minus() {
- lock.lock();
- try {
- while (number != 1) {
- condition.await();
- }
- number-=1;
- System.out.println(Thread.currentThread().getName() + " " + number);
- condition.signalAll();
- } catch (InterruptedException e) {
- e.printStackTrace();
- } finally {
- lock.unlock();
- }
- }
- }
多线程通信之间存在的问题:
虚假唤醒:
我们进行判断的时候,wait放在if语句中,如果它不符合就等待;当其他线程调用notifyAll方法后,又被原线程抢到,那么就会从wait语句的地方醒来,并继续执行代码。这样if的语句判断就失效了。
正确的方法是把判断语句放入while循环中,这样就不会出现判断失效的问题
4.线程间的定制化通信(使用condition的signal方法)
如果要线程间使用定制化调用的方式,而不是随机抢占,那就需要使用定制化通信。
使用标识位的方法,给每个线程一个特定的标识,当他们开始线程的时候,需要判断当前标识位是否为自己所需要的标识位,如果是才执行,并通知下一个condition,不是就进入等待集await,等待别人唤醒它。
5.集合的线程安全(重点!!!)
List集合:以ArrayList为例
常见的就是ConcurrentModificationException,就好像自己之前在一边遍历一边修改map的时候就会出现这个问题。原因就是迭代器和现在的id不同步,造成了这个异常。
在List的多线程中如果一边放东西一边取出东西,多线程之间就会发生冲突,也会产生如上异常。
解决方法Vector(出现时间JDK1.0):
Vector是一个实现了List接口的类,可以使用vector来替换arraylist,达到线程安全的期望。
Vector的内部方法源码里都加上了synchronized关键字,所以它并不会发生线程之间抢占资源的问题,很好的解决了之前所说的ConcurrentModificationException。
解决方案Collections:
调用Collections静态类里面的静态方法:synchronizedList / synchronizedMap等方法,传入一个对应的集合参数,这个方法可以返回一个线程安全的集合。
解决方案JUC中的CopyOnWriteArrayList:
生成 JUC中的CopyOnWriteArrayList对象,替换ArrayList生成List实现类对象。
除了CopyOnWriteArrayList以外,还有CopyOnWriteArraySet对象可供实例化。
原理:写时复制技术(底层用数组实现)
读:并发读取,可以多个线程一起读取
写:独立写,在写入的时候对之前的数组进行一次复制,往新数组里面添加新的元素,然后下一次读就读新的数组(更改引用)。当在写入的时候去读取,就只能读取到旧数据,写入完成之后才能读取新数据。
HashSet和HashMap的线程安全:
HashSet:
使用CopyOnWriteArraySet进行线程不安全处理,底层也是使用了写时复制技术, 拓展:HashSet底层是使用了HashMap来实现的,Key是HashSet的值,而value只是一个PRESENT常量,表示他是否在集合中。
HashMap:
使用ConcurrentHashMap来解决线程不安全
原理:ConcurrentHashMap在HashMap表头加上了一个锁,当操作当前HashMap的时候,需要读取某个桶的时候,桶头就会开始加锁,不让其他资源访问,等我们在这个桶做完操作了,才能继续访问这个桶。
6.多线程锁(锁范围 公平锁 可重入锁)
Synchronized锁的八种情况的分析:
当在普通方法体上使用了synchronized的时候,锁头锁住的是对象实例,也就是this。
当在普通方法体上没有使用synchronized,就是说该方法与锁无关,可以正常执行。
当在静态方法体上使用了synchronized的时候,锁头锁住的是整个类,而不是对象实例。
当在代码块上使用了synchronized的时候,锁住的只是代码块区域。
公平锁和非公平锁:
在使用ReentrantLock的时候,如果传入了true/false参数,代表了开启/关闭公平锁,默认是关闭公平锁。
公平锁在多线程编程的时候,当一个线程太能干了,已经把工作全干完了,其他线程都没活可以干了,这时候可以启动公平锁。公平锁让其他线程也能参与到干活的流程中,具体内部是通过一个等待队列来公平的获得锁的。
而非公平锁会无视等待队列,直接获取锁。
优缺点:
公平锁:
优点:每个线程都有获得锁的机会
缺点:效率相对较慢
非公平锁:
优点:效率高
缺点:线程饿死
可重入锁:
Lock和synchronized都是可重入锁,synchronized是一种隐式的可重入锁,Lock是一种显式的可重入锁。可重入锁就是当同一线程代码有很多内嵌的时候,比如获取锁方法1包含了获取锁方法2,获取锁方法2包含了获取锁方法3,只要是该线程获得了锁,再次获取锁就不会出现死锁。如果当前线程没有释放锁,其他线程就不能获得这个锁,就会出现死锁。
可重入锁的原理就是当递归获得一次同一个锁的时候,state++,用于统计进去多少次锁,当解锁的时候state--。
如果不是同一个锁的话就有可能成为死锁!
死锁:

 两个或者两个以上的进程在执行过程中,由于争夺资源而造成了一种互相等待的现象,就是死锁。
两个或者两个以上的进程在执行过程中,由于争夺资源而造成了一种互相等待的现象,就是死锁。






当线程A持有锁L1,线程B持有锁L2的时候,还没出现死锁。这时候线程A想要获取锁L2,同时线程B想要获取锁L1,那两边都等待对方释放锁,就造成了死锁的情况。
产生死锁的原因:
系统资源不足;
进程运行推进顺序不合适;
资源分配不当;
死锁验证方式:
JVM说过的jps+jstack或者jconsole
7.Callable接口(可以返回一个值):
创建线程方式
继承Thread类;
实现Runnable接口(完成时没有返回值);
实现Callable接口(完成时可以有返回值);
线程池获取;
Callable与Runnable的对比:
- Callable有返回值,Runnable没有返回值
- Callable如果没有返回值,会抛出异常,而Runnable不会抛出异常
- 实现方法中Callable使用call方法,而Runnable使用run方法
FutureTask类(可以创建Callable或者Runnable):
可以使用FutureTask来创建实现了Callable接口或者Runnable接口的线程,也可以在里面使用Lambda表达式创建Callable线程,最后使用Thread来start这个线程
FutureTask:在不影响主线程的情况下,可以单开几个线程来做比较复杂的事情,最后把东西用get方法获得到就好了
不能用run方法,futuretask并不是一个线程,必须要用new Thread.start来开启
注意:当调用get方法的时候,如果futuretask还没完成,就会阻塞主线程
8.辅助类(计数器 循环栅栏 信号灯)
减少计数(CountDownLatch类):
使用CountDownLatch可以给线程设置一个计数器,调用countDown方法可以给给当前计数器的值-1。计数器不为0的时候,调用await方法使当前线程阻塞,当计数器的值为0的时候自动唤醒,并继续执行。
- public class CountDownLatchDemo {
- public static void main(String[] args) {
- // 定义初始值
- CountDownLatch latch = new CountDownLatch(6);
- for (int i = 0; i < 6; i++) {
- new Thread(() -> {
- try {
- TimeUnit.SECONDS.sleep(1);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- System.out.println(Thread.currentThread().getName() + "号同学离开了");
- // 使计数器-1
- latch.countDown();
- },String.valueOf(i)).start();
- }
- new Thread(() -> {
- try {
- // 阻塞当前线程,当latch=0的时候自动唤醒
- latch.await();
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- System.out.println("班长锁门了");
- }).start();
- }
- }
循环栅栏(CyclicBarrier) :
一个同步辅助类,当CyclicBarrier里面的等待线程到达一定数量之后,就会自动开始一个新线程,并执行里面的方法。
CyclicBarrier的构造方法第一个参数就是目标障碍数,当CyclicBarrier的等待数到达这个目标障碍数的时候才会进行await之后的操作,并执行CyclicBarrier第二个构造参数的方法(如果有的话,没有就只执行其他线程的await之后的方法)
- public class CyclicBarrierDemo {
- public static void main(String[] args) {
- // 新建CyclicBarrier,第一个构造参数使目标障碍数,第二个参数是要执行的新线程
- CyclicBarrier cyclicBarrier = new CyclicBarrier(7,new Thread(() -> {
- System.out.println("召唤神龙");
- }));
- for (int i = 0; i < 7; i++) {
- new Thread(() -> {
- System.out.println(Thread.currentThread().getName() + "龙珠获取");
- try {
- // 使线程阻塞,并加入等待队列
- cyclicBarrier.await();
- } catch (InterruptedException e) {
- e.printStackTrace();
- } catch (BrokenBarrierException e) {
- e.printStackTrace();
- }
- }).start();
- }
- }
- }
信号灯(Semaphore):
这是一个计数信号量,信号量维护了一个许可集。如果需要的话,在许可可用之前会阻塞一个线程内的acquire方法,然后再获取该许可。使用release可以添加一个许可,并进行放行。
- public class SemaphoreDemo {
- public static void main(String[] args) {
- // 构造Semaphore信号灯对象,参数为有多少个许可
- Semaphore semaphore = new Semaphore(3);
- for (int i = 0; i < 6; i++) {
- new Thread(() -> {
- try {
- semaphore.acquire();
- System.out.println(Thread.currentThread().getName() + " 停车了");
- // 设置随机停车时间
- TimeUnit.SECONDS.sleep(new Random().nextInt(5));
- System.out.println(Thread.currentThread().getName() + " 走了");
- } catch (InterruptedException e) {
- e.printStackTrace();
- } finally {
- // 释放许可给Semaphore
- semaphore.release();
- }
- },String.valueOf(i)).start();
- }
- }
- }
9.JUC读写锁(ReentrantLockReadWriteLock):
乐观锁与悲观锁(MybatisPlus可以使用乐观锁插件):
乐观锁就是在需要操作的数据里面加入一个版本号,如果操作了版本号自增,如果再此同时发生了一样的操作,后面提交的发现版本号对应不上,就放弃操作;
悲观锁就是在操作数据是把资源阻塞,其他的人操作不了这个资源,除非是等操作者释放了才能操作。加了悲观锁的地方不支持并发操作。
表锁和行锁:
当操作数据库某一行的时候,如果是表锁,就会把整张表上锁;如果是行锁,就会把正在操作的行上锁。两个(或以上)的Session加锁的顺序不一致,行锁会发生死锁。那么对应的解决死锁问题的关键就是:让不同的session加锁有次序。
读写锁:
读锁:共享锁
写锁:独占锁
使用读写锁的获取规则:
1.如果有一个线程已经占用了读锁,则此时其他线程如果要申请读锁,可以申请成功。
2.如果有一个线程已经占用了读锁,则此时其他线程如果要申请写锁,则申请写锁的线程会一直等待释放读锁,因为读写不能同时操作。
3.如果有一个线程已经占用了写锁,则此时其他线程如果申请写锁或者读锁,都必须等待之前的线程释放写锁,同样也因为读写不能同时,并且两个线程不应该同时写。
读锁和写锁都有可能发生死锁
读锁死锁:当线程1读取的时候想要修改,需要等线程2读取完才能修改,但是线程2也想修改,所以必须要等线程1读完,导致死锁。
写锁死锁:当线程1在修改记录1,线程2在修改记录2的时候,如果线程1修改完记录1想修改记录2,而线程2修改完记录2想修改记录1的时候,就会发生死锁。
读写锁缺点:
- 容易造成锁饥饿,只有读操作但没有写操作。
- 读的时候不能写,读完才能写,但是写操作的时候可以读,这样就会造成脏读
锁升降级(写的时候可以读):
即一个线程在获取到写锁之后,可以获取读锁,当把写锁释放之后就变成了共享的读锁了。而当获取了读锁的时候,是不能再获取写锁的,不然就会死锁。
把写锁降级为读锁:先获取写锁,再获取读锁,然后释放写锁,这样就降级为读锁了
读锁不能升级为写锁
- public class Demo1 {
- public static void main(String[] args) {
- ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock();
- ReentrantReadWriteLock.ReadLock readLock = readWriteLock.readLock();
- ReentrantReadWriteLock.WriteLock writeLock = readWriteLock.writeLock();
- writeLock.lock();
- System.out.println("写锁获取");
- readLock.lock();
- System.out.println("读锁获取");
- writeLock.unlock();
- System.out.println("写锁释放");
- }
- }
扩展:volatile关键字修饰一个变量。从规则的定义可知,如果多个线程同时操作volatile变量,那么对该变量的写操作必须在读操作之前执行(禁止重排序),并且写操作的结果对读操作可见(强缓存一致性)。即被volatile修饰的变量能够保证每个线程能够获取该变量的最新值,从而避免出现数据脏读的现象。
读写锁案例:

由图可见,写完之前就开始读了,这明显不符合读写锁的设计。需要添加ReentrantReadWriteLock来进行读写锁操作。
在ReentrantReadWriteLock中,调用其中的readLock方法可以获得写锁,调用writeLock可以获得读锁。两种锁里面都有各自的lock和unlock方法。

代码:
- // 模拟数据库
- class MyDB{
- private volatile Map<String, Object> map = new HashMap<>();
- ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock();
- public void put(String key,Object obj) throws InterruptedException {
- readWriteLock.writeLock().lock();
- System.out.println(Thread.currentThread().getName() + "正在写操作");
- map.put(key,obj);
- TimeUnit.SECONDS.sleep(1);
- System.out.println(Thread.currentThread().getName() + "写完了");
- readWriteLock.writeLock().unlock();
- }
- public Object get(String key) {
- readWriteLock.readLock().lock();
- try {
- System.out.println(Thread.currentThread().getName() + "正在读操作");
- return map.get(key);
- } finally {
- readWriteLock.readLock().unlock();
- }
- }
- }
- public class ReadWriteLockDemo {
- public static void main(String[] args) {
- MyDB db = new MyDB();
- // 模拟写操作
- for (int i = 0; i < 5; i++) {
- int num = i;
- new Thread(() -> {
- try {
- db.put(num+"",num);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- },String.valueOf(i)).start();
- }
- // 模拟读操作
- for (int i = 0; i < 5; i++) {
- int num = i;
- new Thread(() -> {
- System.out.println(db.get(num+""));
- },String.valueOf(i)).start();
- }
- }
- }
读写锁的演变(读写互斥、读读共享):
一个资源可以被多个读线程访问,或者可以被一个写线程访问,但是不能同时存在读写线程。
第一阶段:无锁
会导致线程间操作混乱
第二阶段:synchronized和ReentrantLock
两个都是独占锁,不能做共享。当发生读读的时候,独占锁并不适合。
第三阶段:读写锁ReentrantReadWriteLock
读读共享,读写互斥
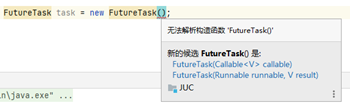
10.阻塞队列BlockingQueue
线程1往阻塞队列里面添加元素,而线程2从阻塞队列中移除元素。
当队列是空的时候,获取元素操作的线程会被阻塞,除非有外力作用;
当队列是满的时候,添加元素操作的线程会被阻塞,除非有外力作用;
使用BlockingQueue的好处在于不用自己操作阻塞和唤醒,都由阻塞队列来做了
常用的阻塞队列:

1.ArrayBlockingQueue(常用)
基于数组的阻塞队列实现,由于是数组实现,所以长度是固定的。里面还维护了两个整型变量,分别标识了队头和队尾。
2.LinkedBlockingQueue(常用)
基于链表的阻塞队列实现,长度不固定,由链表来实现。
3.DelayQueue
DelayQueue没有大小限制,生产者永远不会被阻塞,但是只有当其指定的延迟时间到了,才能从队列里面拿出东西,所以只有消费者会被阻塞。
一句话总结:使用优先级队列实现的延迟无界阻塞队列
4. PriorityBlockingQueue
基于优先级的阻塞队列,通过构造函数传入的Compator来进行比较优先级。它并不会阻塞生产者,而会在没有可消费的数据的时候,阻塞消费者。
需要注意的是,生产者生产数据的速度不可以大于消费者消费的速度,不然会耗尽内存。
5.SynchronousQueue
一种无缓冲的等待队列,类似于无中介的直接交易,不存储元素,是一个单元素的阻塞队列。
6.LinkedTransferQueue
一种基于链表实现的无界阻塞队列。
7.LinkedBlockingDeque
一种基于链表实现的双向阻塞队列,可以从两端插入或取出元素。不像以上阻塞队列一样,都需要从一边输入从另一边输出。
常用的方法:
1.抛出异常:当队满或队空或者队无此元素的时候抛出异常
插入:add(IllegalStatementException)
移除:remove(NoSuchElementException)
检查:element(NoSuchElementException)
2.特殊值:当队满或队空或者队无此元素的时候返回值
插入:offer(true/false)
移除:poll(值/null)
检查:peek(值/null)
3.阻塞:当队满或队空的时候阻塞队列
插入:put
移除:take
4.超时:当队满或队空的时候阻塞并设定超时,超时退出
插入:put
移除:take
代码示例:
- public class BlockQueueDemo {
- // 创建阻塞队列
- static BlockingQueue<String> queue = new ArrayBlockingQueue<>(3,true);
- public static void main(String[] args) throws InterruptedException {
- // 计数器启动take线程
- CountDownLatch countDownLatch = new CountDownLatch(1);
- new Thread(() -> {
- try {
- countDownLatch.await();
- System.out.println(queue.take());
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }).start();
- // 添加数据
- System.out.println(queue.add("a"));
- System.out.println(queue.add("b"));
- System.out.println(queue.add("c"));
- // 审查元素
- System.out.println(queue.element());
- // 继续添加 输出:Exception in thread "main" java.lang.IllegalStateException: Queue full
- //System.out.println(queue.add("d"));
- // 继续添加 输出:false
- System.out.println(queue.offer("d"));
- // 使用队列阻塞方法添加 程序持续运行
- //queue.put("d");
- // 使用计数器来启动 take 线程
- countDownLatch.countDown();
- queue.put("d");
- }
- }
11.线程池ThreadPool
线程池概述:
线程池就像一个以线程为泛型的阻塞队列,里面维护了多个线程,当需要调用线程的时候,就可以从线程池中取出线程,如果线程数量超过了线程池的大小,就会把需要开启的线程进行阻塞。避免了短时间内多次创建与销毁线程,保证了内核的充分利用和防止线程的过分调度。
线程池架构:
Java中的线程池是通过Executor框架实现的,该框架使用了Executor,Executors,ExecutorService,ThreadPoolExecutor这几个类
线程池的使用:
一池多线程:Executor.newFixedThreadPool(int)
开一个池,如果没满可以取,满了必须等待。构造函数的int标识线程池大小
- public class ThreadPoolDemo1 {
- public static void main(String[] args) {
- // 一池多线程
- ExecutorService executorService1 = Executors.newFixedThreadPool(5);
- try {
- for (int i = 0; i < 10; i++) {
- // 当execute方法执行完之后,线程就会返回线程池
- executorService1.execute(() -> {
- try {
- System.out.println(Thread.currentThread().getName() + " 正在运行");
- TimeUnit.SECONDS.sleep(1);
- }
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- });
- }
- } finally {
- // 关闭线程池
- executorService1.shutdown();
- }
- }
- }
一池一线程:Executor.newSingleThreadExecutor
开一个池,里面容量为1,也就是开启线程的顺序是轮流开的。
- public class ThreadPoolDemo2 {
- public static void main(String[] args) {
- // 一池一线程
- ExecutorService executorService = Executors.newSingleThreadExecutor();
- //调用线程
- try {
- for (int i = 0; i < 10; i++) {
- executorService.execute(() -> {
- System.out.println(Thread.currentThread().getName() + " 正在运行");
- });
- }
- } finally {
- executorService.shutdown();
- }
- }
- }
根据需求扩容线程池:Executor.newCachedThreadPool
开一个池,如果没满可以取,满了线程池就可以自动扩容,如果线程关闭了就可以自动缩小,取决于内存大小。
- public class ThreadPoolDemo3 {
- public static void main(String[] args) {
- // 缓存线程池
- ExecutorService executorService = Executors.newCachedThreadPool();
- try {
- // 调用线程
- for (int i = 0; i < 30; i++) {
- executorService.execute(() -> {
- System.out.println(Thread.currentThread().getName() + " 正在运行");
- });
- }
- } finally {
- executorService.shutdown();
- }
- }
- }
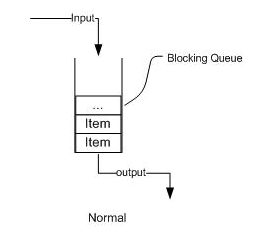
七个参数:
在每一种线程池的底层,都是通过一个ThreadPoolExecutor来进行实现的。在ThreadPoolExecutor中,有着七个参数,分别是:
- 常驻(核心)线程数 int corePoolSize
- 最大线程数 int maximumPoolSize
- 线程存活时长 long keepAliveTime
- 线程存活时长单位(Second或者MillionSecond)TimeUnit unit
- 以哪种阻塞队列来实现 BlockingQueue<Runnable> workQueue
- 线程工厂(用于创建线程)ThreadFactory threadFactory
- 拒绝策略(当满了的时候拒绝服务的策略) RejectedExecutionHandler handler
AbortPolicy(默认):常驻满了,队列也满了,也超过了最大请求数,就直接抛异常
CallerRunsPolicy:不会抛弃任务也不会抛出异常,而是把某些任务回退到调用者,从而降低新任务的流量
DiscardOldestPolicy:抛弃队列中等待最久的任务
DiscardPolicy:默默丢弃无法处理的任务,如果允许丢失,这是最好的策略
底层工作流程:
自定义线程池(重点):
日常开发不使用以上方式,自己使用ThreadPoolExecutor传入7个参数来新建线程池
原因:线程池最大数量为Integer.MAX_VALUE,会造成OOM
- public class CustomThreadPool {
- public static void main(String[] args) {
- // 自定义线程池
- ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(2, 7,
- 60L, TimeUnit.SECONDS,
- new ArrayBlockingQueue<>(3),
- Executors.defaultThreadFactory(),
- new ThreadPoolExecutor.AbortPolicy());
- try {
- for (int i = 0; i < 10; i++) {
- threadPoolExecutor.execute(() -> {
- System.out.println(Thread.currentThread().getName() + " 正在运行");
- });
- }
- } catch (Exception e) {
- e.printStackTrace();
- } finally {
- threadPoolExecutor.shutdown();
- }
- }
- }
12.Fork/Join分支合并框架(ForkJoinPool):
Fork/Join可以把一个大的任务拆分成多个子任务进行并行处理,最后将子任务结果合并返回成最后的结果并进行输出。
Fork:把一个复杂任务进行分拆
Join:把分拆任务的结果进行合并
Fork/Join框架就是分治法,把大的问题拆分成小的问题。也差不多像递归一样,调用fork就是里面的compute方法,最后可以join在一起。
ForkJoinPool:
ForkJoinTask需要通过ForkJoinPool来执行,任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。当一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程的队列的尾部获取一个任务。
ForkJoinTask:
我们要使用Fork/Join框架,必须首先创建一个Fork/Join任务。它提供在任务中执行fork和join操作的机制,通常情况下我们不需要直接继承ForkJoinTask类,而只需要继承它的子类:
RecursiveAction:无返回值的任务。
RecursiveTask:有返回值的任务。
CountedCompleter:完成任务后将触发其他任务。
代码示例:
- public class ForkAndJoin {
- public static void main(String[] args) throws ExecutionException, InterruptedException {
- ForkJoinPool forkJoinPool = new ForkJoinPool();
- ForkJoinTask<Integer> submit = forkJoinPool.submit(new MyTask(0, 100));
- System.out.println(submit.get());
- }
- }
- // 继承ForkJoinTask子类
- class MyTask extends RecursiveTask<Integer> {
- private static final Integer VALUE = 10;
- private int begin;
- private int end;
- private int result;
- public MyTask(int begin, int end) {
- this.begin = begin;
- this.end = end;
- }
- @Override
- protected Integer compute() {
- // 判断
- if (end - begin <= VALUE) {
- for (int i =begin; i < end; i++) {
- result+=i;
- }
- }else {
- int mid = (begin + end) / 2;
- MyTask myTask01 = new MyTask(begin,mid);
- // 递归调用
- myTask01.fork();
- MyTask myTask02 = new MyTask(mid, end);
- // 递归调用
- myTask02.fork();
- // 合并结果
- result = myTask01.join() + myTask02.join();
- }
- // 返回到ForkJoinTask.get里面
- return result;
- }
- }
13.异步回调(CompuletableFuture):
如上所述,在FutureTask中,当调用get方法的时候,如果futuretask还没完成,就会阻塞主线程。我们需要使用CompletableFuture来进行更强大的异步处理。
实例化方式:
supplyAsync(Supplier<U> supplier);
supplyAsync(Supplier<U> supplier, Executor executor);
runAsync(Runnable runnable);
runAsync(Runnable runnable, Executor executor);
有两种格式,一种是supply开头的方法,一种是run开头的方法
*supply开头:这种方法,可以返回异步线程执行之后的结果
*run开头:这种不会返回结果,就只是执行线程任务
代码示例:
- public class CompletableFutureDemo {
- public static void main(String[] args) throws ExecutionException, InterruptedException {
- // 异步调用 没有返回值
- CompletableFuture<Void> future1 = CompletableFuture.runAsync(() -> {
- System.out.println("Running");
- });
- // 异步调用 有返回值
- CompletableFuture<Integer> future2 = CompletableFuture.supplyAsync(() -> {
- return 1;
- });
- // 不会导致阻塞
- future2.whenComplete((integer, throwable) -> {
- System.out.println(integer + " " + throwable);
- });
- }
- }


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)