
1115作业
一、理解分类与监督学习、聚类与无监督学习。
1、简述分类与聚类的联系与区别。
分类就是按照某种标准给对象贴标签(label),再根据标签来区分归类。聚类是指事先没有“标签”而通过某种成团分析找出事物之间存在聚集性原因的过程。区别是,分类是事先定义好类别 ,类别数不变 。分类器需要由人工标注的分类训练语料训练得到,属于有指导学习范畴。聚类则没有事先预定的类别,类别数不确定。 聚类不需要人工标注和预先训练分类器,类别在聚类过程中自动生成 。分类适合类别或分类体系已经确定的场合,比如按照国图分类法分类图书;聚类则适合不存在分类体系、类别数不确定的场合,一般作为某些应用的前端,比如多文档文摘、搜索引擎结果后聚类(元搜索)等。分类的目的是学会一个分类函数或分类模型(也常常称作分类器 ),该模型能把数据库中的数据项映射到给定类别中的某一个类中。聚类(clustering)是指根据“物以类聚”原理,将本身没有类别的样本聚集成不同的组,这样的一组数据对象的集合叫做簇,并且对每一个这样的簇进行描述的过程。
2、简述什么是监督学习与无监督学习。
监督学习,就是人们常说的分类,通过已有的训练样本(即已知数据以及其对应的输出)去训练得到一个最优模型(这个模型属于某个函数的集合,最优则表示在某个评价准则下是最佳的),再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的,也就具有了对未知数据进行分类的能力。监督学习里典型的例子就是KNN、SVM。无监督学习(也有人叫非监督学习,反正都差不多)则是另一种研究的比较多的学习方法,它与监督学习的不同之处,在于我们事先没有任何训练样本,而需要直接对数据进行建模。无监督学习里典型的例子就是聚类了。聚类的目的在于把相似的东西聚在一起,而我们并不关心这一类是什么。
二、朴素贝叶斯分类算法 实例
利用关于心脏情患者的临床数据集,建立朴素贝叶斯分类模型。
有六个分类变量(分类因子):性别,年龄、KILLP评分、饮酒、吸烟、住院天数
目标分类变量疾病:–心梗–不稳定性心绞痛
新的实例:–(性别=‘男’,年龄<70, KILLP=‘I',饮酒=‘是’,吸烟≈‘是”,住院天数<7)
最可能是哪个疾病?
上传演算过程。
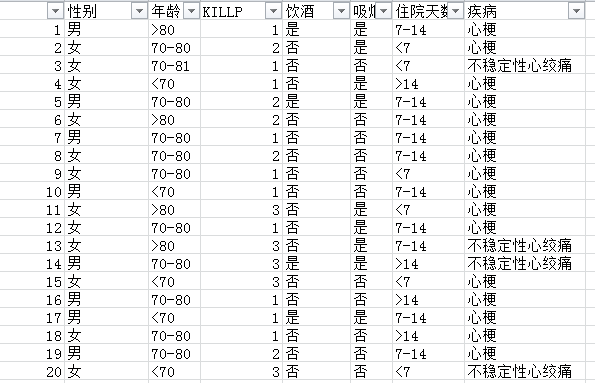
 样本数:20
样本数:20
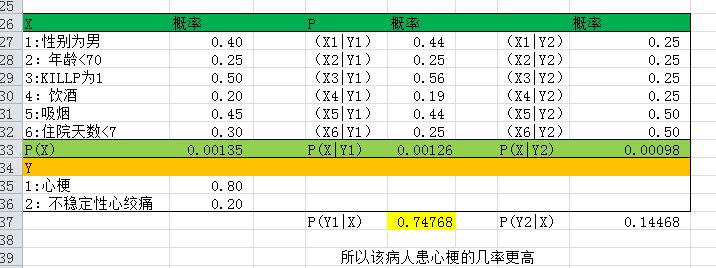
3.编程实现朴素贝叶斯分类算法
利用训练数据集,建立分类模型。
输入待分类项,输出分类结果。
可以心脏情患者的临床数据为例,但要对数据预处理。
import numpy as np import pandas data=pandas.read_excel('心脏病患者临床数据.xlsx') data #对性别进行处理 (男为0,女为1) sex=[] for i in data['性别']: if i =='男': sex.append(0) else: sex.append(1) #对年龄段进行预处理 (<70为1,70-80为2,>80为3) ages=[] for j in data['年龄']: if j =='<70': ages.append(1) elif j =='70-80': ages.append(2) else: ages.append(3) #对住院天数进行处理 (<7为1,7-14为2,>14为3) days=[] for k in data['住院天数']: if k=='<7': days.append(1) elif k=='7-14': days.append(2) else: days.append(3) #处理后的数据 data1=data data1['性别']=sex data1['年龄']=ages data1['住院天数']=days #将数据转成数组 data_arr=np.array(data1) data_arr

 浙公网安备 33010602011771号
浙公网安备 33010602011771号