英文部分:
一、准备utf-8编码的文本文件file
![]()
二、通过文件读取字符串 str
fo = open('rain.txt','r',encoding='utf-8')
rain = fo.read().lower() #文字转小写
fo.close()
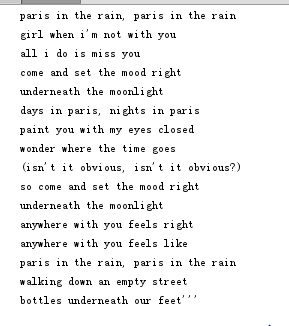
print(rain)
结果如下:
![]()
三、对文本进行预处理
s1=''', . ? ~ ` ' \ '''
for ch in s1:
Rain=rain.replace(ch ,' ')
print(Rain)
![]()
四、分解提取单词 list
strList = rain.split()
print(len(strList),strList)
结果如下:
![]()
五、单词计数字典 set , dict
strSet = set(strList)
print(len(strSet),strSet)
strDict = {}
for word in strSet:
strDict[word] = strList.count(word)
print(len(strDict),strDict)
结果如下:
![]()
六、按词频排序 list.sort(key=)
wcList = list(strDict.items())
wcList.sort(key=lambda x:x[1],reverse=True)
print(wcList)
结果如下:
![]()
七、排除语法型词汇,代词、冠词、连词等无语义词
八、输出TOP(20)
for i in range(20):
print(wcList[i])
结果如下:
![]()
中文部分:
import jieba
hlm = open('HLM.txt','r',encoding='utf-8').read()
print(hlm)
![]()
wordspre = jieba.lcut(hlm)
wcdict = {}
for word in wordspre:
if len(word)==1:
continue
else:
wcdict[word]=wcdict.get(word,0)+1
![]()
wcls = list(wcdict.items())
wcls.sort(key=lambda x:x[1],reverse=True)
for i in range(20):
print(wcls[i])
![]()



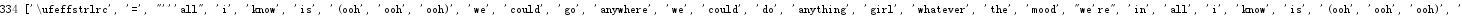

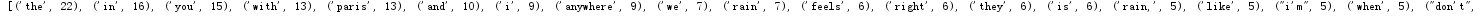





 浙公网安备 33010602011771号
浙公网安备 33010602011771号