Python爬取入门教程16:音频素材网站的爬取
前言💨
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
前文内容💨
PS:如有需要 Python学习资料 以及 解答 的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
基本开发环境💨
- Python 3.6
- Pycharm
相关模块的使用💨
import os
import concurrent.futures
import requests
import parsel
安装Python并添加到环境变量,pip安装需要的相关模块即可。
一、💥确定需求

虽然上面显示需要付费下载,但是一样可以免费下载。
二、💥网页数据分析
打开开发者工具,点击播放音频,在Media中会加载出音频的url地址。

如果想要验证这个链接是否是音频的真实下载地址,可以复制链接粘贴到新的窗口中。
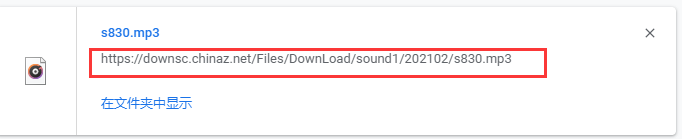
它会自动下载一个音频文件。并且这个音频文件是可以播放的,和网页上面的音频声音是可以对上的。
事实证明这个就是我们要获取音频地址。

https://downsc.chinaz.net/Files/DownLoad/sound1/202102/s830.mp3
老思路了,复制链接中的某些参数在开发者工具中进行搜索,很明显 s830 就是音频的ID了。

搜索 s830 找到来源,发现网页页面中自带有下载地址。获取音频下载地址之后需要自己拼接url。
网页数据不复杂,相对而言还是比较简单的。
1、请求当前网页数据,获取音频地址以及音频标题
2、保存下载就可以了
三、💥代码实现
获取音频ID以及音频标题
def main(html_url):
html_data = get_response(html_url).text
selector = parsel.Selector(html_data)
lis = selector.css('#AudioList .container .audio-item')
for li in lis:
name = li.css('.name::text').get().strip()
src = li.css('audio::attr(src)').get()
audio_url = 'https:' + src
save(name, audio_url)
print(name, audio_url)
保存数据
def save(name, audio_url):
header = {
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
audio_content = requests.get(url=audio_url, headers=header).content
path = 'audio\\'
if not os.path.exists(path):
os.mkdir(path)
with open(path + name + '.mp3', mode='wb') as f:
f.write(audio_content)
这里想要重新给一个headers参数,不然会下载不了。代码会一直运行,但是没有反应
多线程爬取
if __name__ == '__main__':
executor = concurrent.futures.ThreadPoolExecutor(max_workers=5)
for page in range(1, 31):
url = f'https://sc.chinaz.com/yinxiao/index_{page}.html'
# main(url)
executor.submit(main, url)
executor.shutdown()