

Python爬虫入门教程13:高质量电脑桌面壁纸爬取
前言💨
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
前文内容💨
PS:如有需要 Python学习资料 以及 解答 的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
基本开发环境💨
- Python 3.6
- Pycharm
相关模块的使用💨
import requests
import re
import os
安装Python并添加到环境变量,pip安装需要的相关模块即可。
一、💥明确需求

如图所示爬取里面的高清壁纸
二、💥网页数据分析

点击下载原图,会自动给你下载壁纸图片。
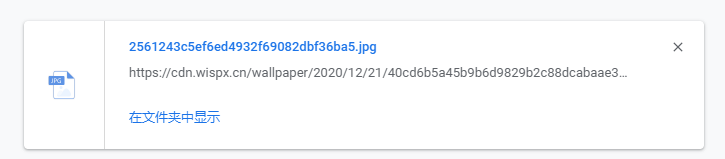

所以只需要获取这个链接就可以了爬取壁纸图片了。
返回列表的可以发现,网页是瀑布流加载方式,当你往下滑才会有数据出现。所以可以在下滑网页的前,先打开开发者工具,当下滑网页的时候新加载出来的数据会出现。

通过对比可以知道,这个数据包中包含了,壁纸图片下载的地址。
需要注意的就是这个数据链接是post请求,并不是get请求
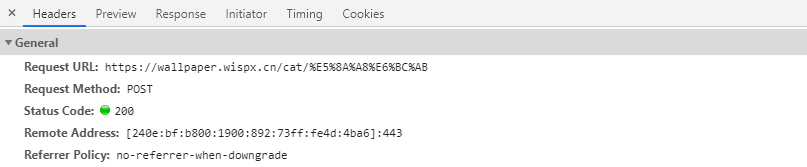

需要提交的data参数,就是对应的页码。
三、💥代码实现
1、获取图片ID
for page in range(1, 11):
url = 'https://wallpaper.wispx.cn/cat/%E5%8A%A8%E6%BC%AB'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
}
data = {
'page': page
}
response = requests.post(url=url, headers=headers)
result = re.findall('detail(.*?)target=', response.text)
for index in result:
image_id = index.replace('\\', '').replace('" ', '')
page_url = f'https://wallpaper.wispx.cn/detail{image_id}'
2、获取壁纸url地址,并保存
def main(page_url):
html_data = get_response(page_url).text
image_url = re.findall('<a class="mdui-ripple mdui-ripple-white" href="(.*?)">', html_data)[0]
image_title = re.findall('<title>(.*?)</title>', html_data)[0].split(' - ')[0]
image_content = get_response(image_url).content
path = 'images\\'
if not os.path.exists(path):
os.makedirs(path)
with open(path + image_title + '.jpg', mode='wb') as f:
f.write(image_content)
print('正在保存:', image_title)
需要注意的点:
请求头里面要防盗链,不然就下载不了。
def get_response(html_url):
header = {
'referer': 'https://wallpaper.wispx.cn/detail/1206',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
resp = requests.get(url=html_url, headers=header)
return resp
四、💥实现效果


