


Python 情人节超强技能 导出微信聊天记录生成词云
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: Python实用宝典
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef


瞧 这是不是一个有声音、有画面的小爱心~
今天 我们采集情侣们之间的聊天日常
用此制作一份只属于你们的小浪漫!
第一步,我们需要导出自己和对象的数据~
微信的备份功能并不能直接给你导出文本格式,它导出来其实是一种叫sqlite的数据库。如果说用网上流传的方法提取文本数据,iOS则需要下载itunes备份整机,安卓则需要本机的root权限,无论是哪种都非常麻烦,在这里给大家介绍一种不需要整机备份和本机root权限,只导出和对象的聊天数据的方法。
那就是使用安卓模拟器导出,这样既能ios/安卓通用,又能够避免对本机造成不良影响,首先需要用电脑版的微信备份你和你对象的聊天记录。以windows系统为例:
-
下载夜神模拟器
-
在夜神模拟器中下载微信
-
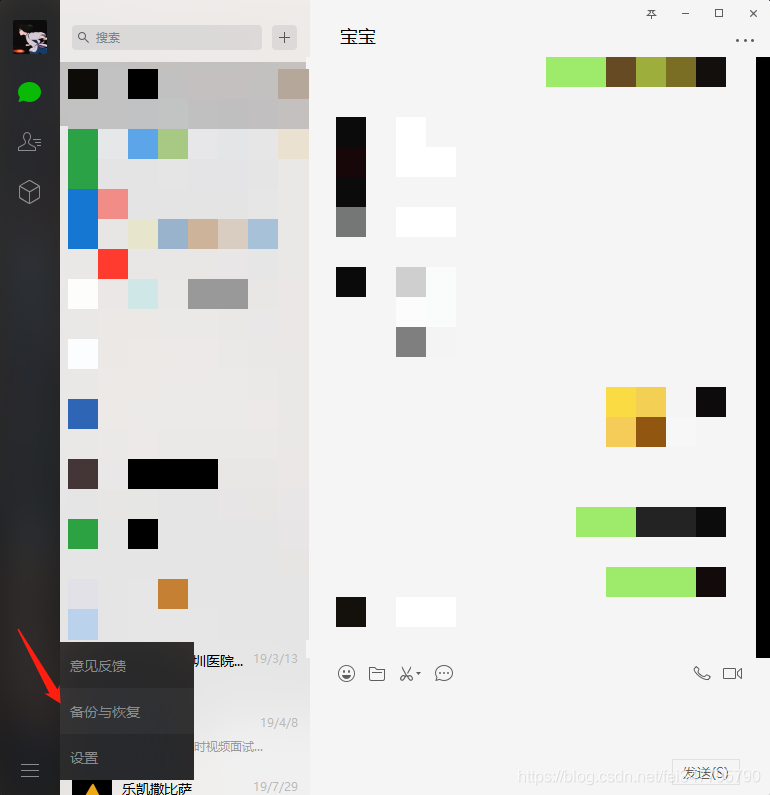
使用windows客户端版的微信进行备份,如图左下角
-
-
点击备份聊天记录至电脑

-
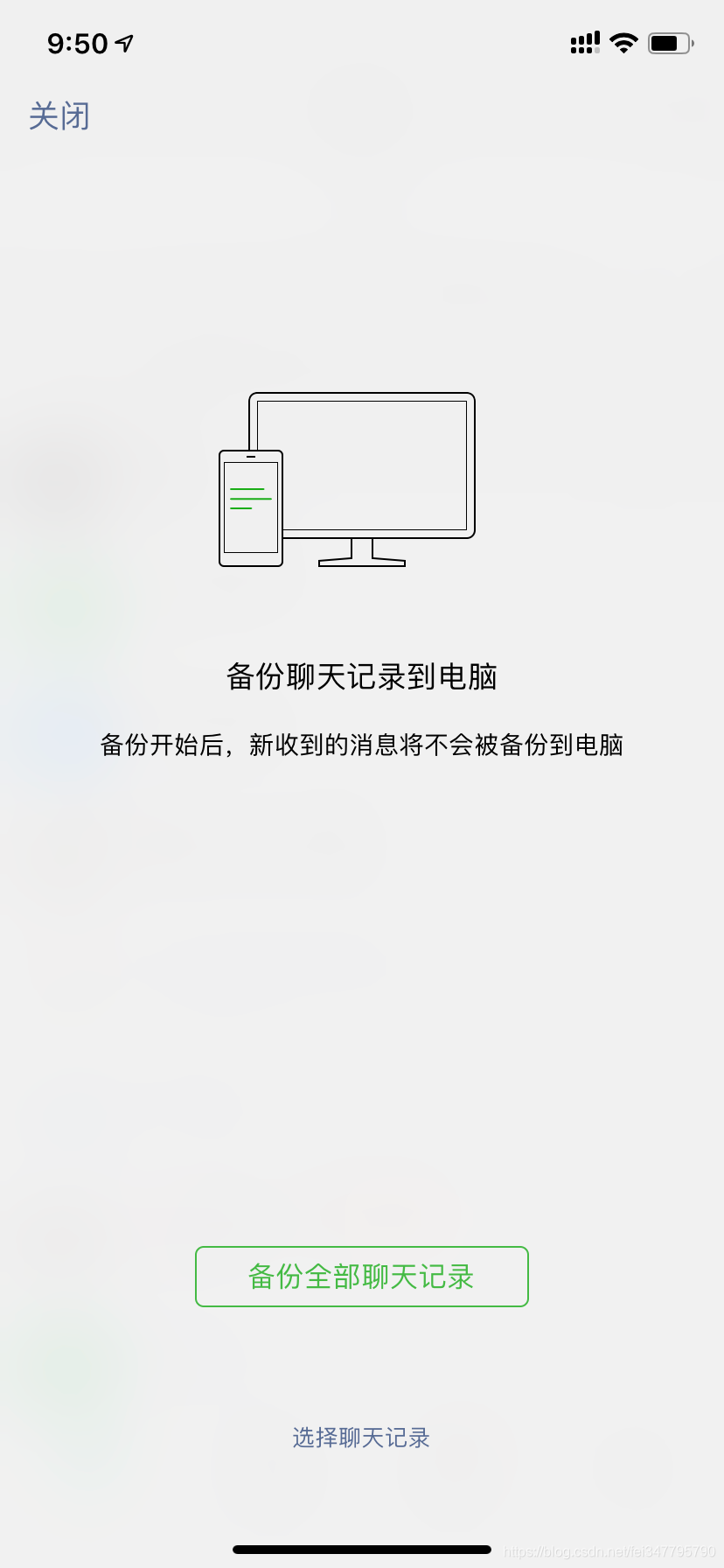
手机端选择备份的对象
点击进入下方的选择聊天记录,然后选择和你对象的记录就可以啦

-
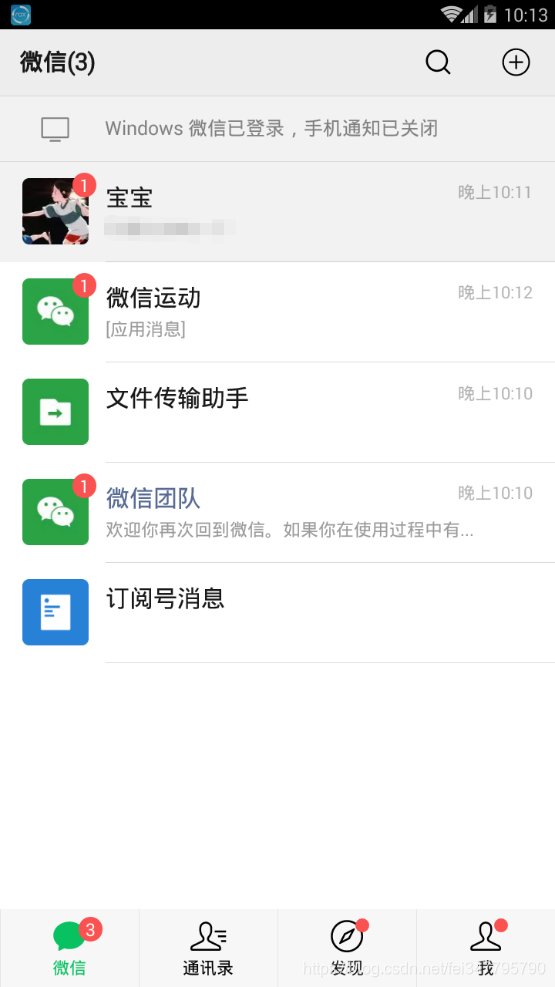
导出完毕后打开模拟器,登录模拟器的微信
-
-
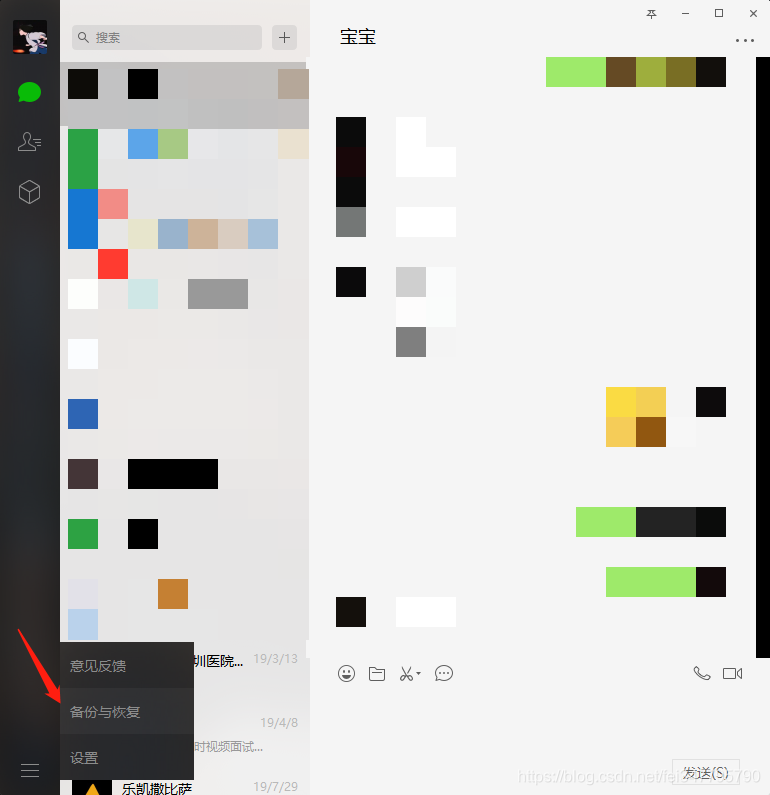
登录成功后返回电脑版微信登录,打开备份与恢复,选择恢复聊天记录到手机
-
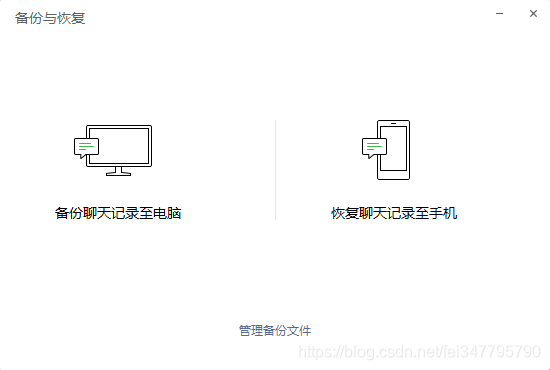
-
勾选我们刚刚导出的聊天记录,并在手机上点击开始恢复
-

-
打开夜神模拟器的root权限
-
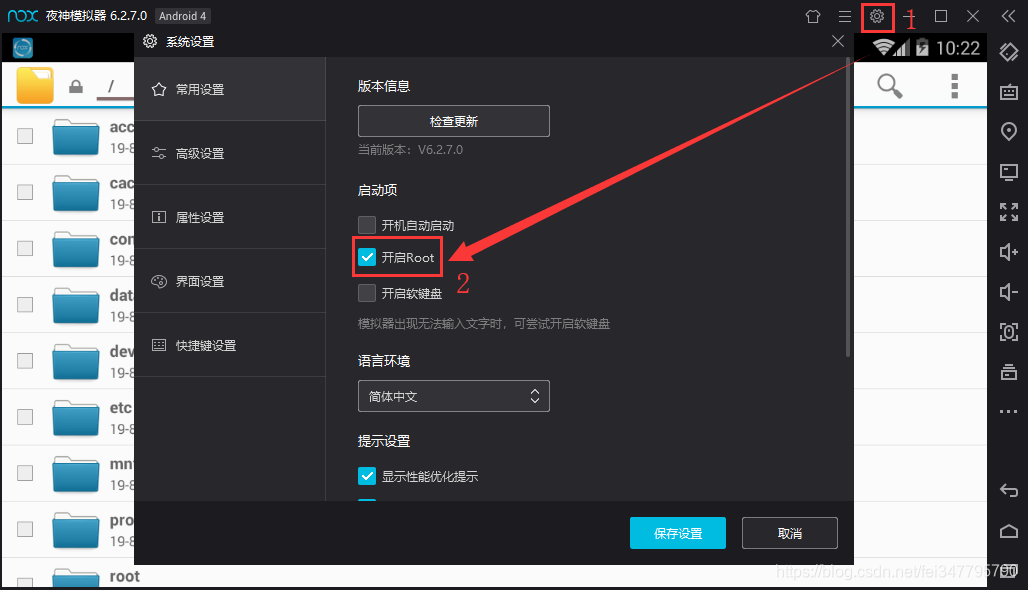
-
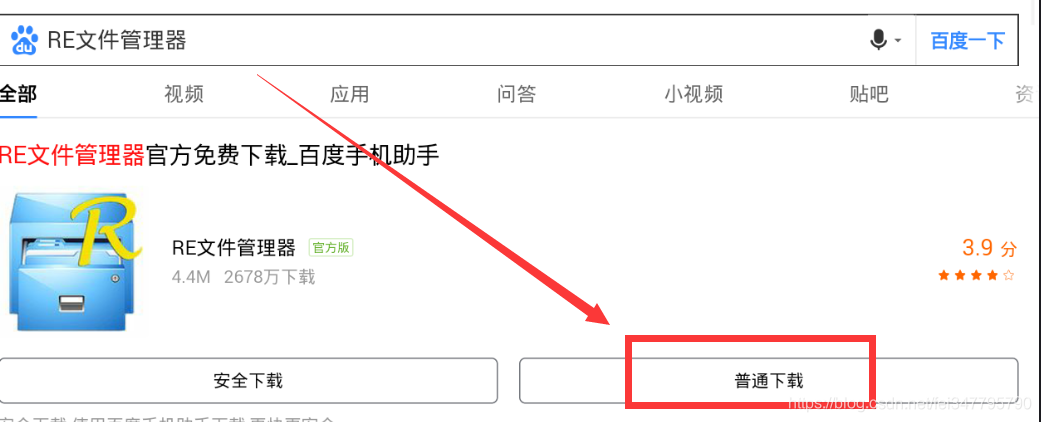
用模拟器的浏览器百度搜索RE文件管理器,下载(图一)安装后打开,会弹出对话框让你给予root权限,选择永久给予,打开RE文件管理器(图二),进入以下文件夹(图三), 这是应用存放数据的地方。
/data/data/com.tencent.mm/MicroMsg
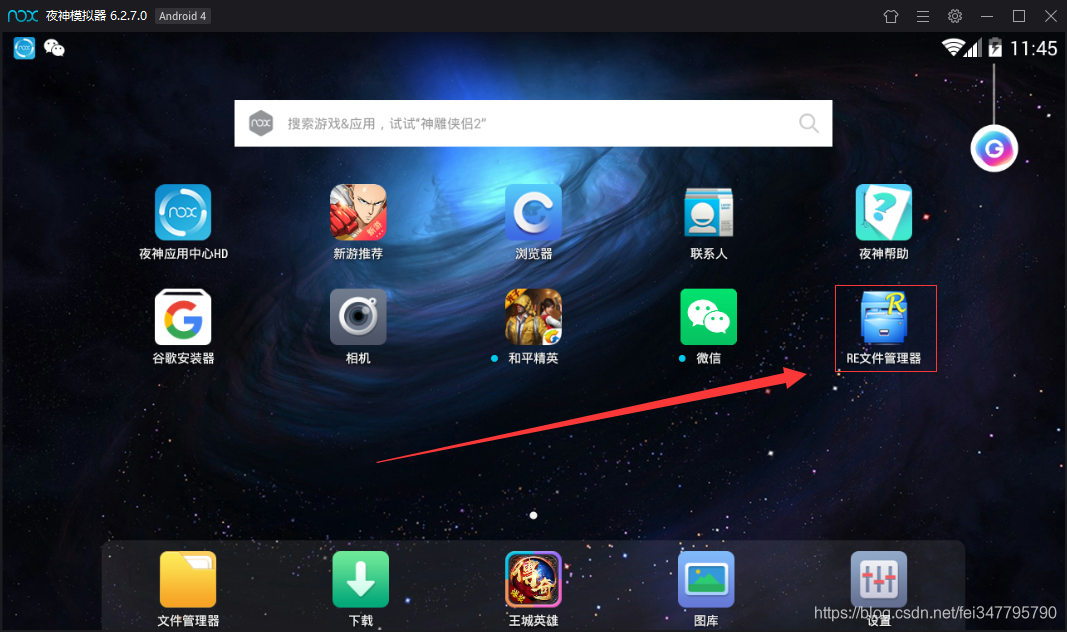

然后进入一个由数字和字母组合而成的文件夹,如上 图三 的 4262333387ddefc95fee35aa68003cc5
-
找到该文件夹下的EnMicroMsg.db文件,将其复制到夜神模拟器的共享文件夹(图四)。共享文件夹的位置为 /mnt/shell/emulated/0/others ( 图五 ),现在访问windows的 C:\Users\你的用户名\Nox_share\OtherShare 获取该数据库文件( EnMicroMsg.db )
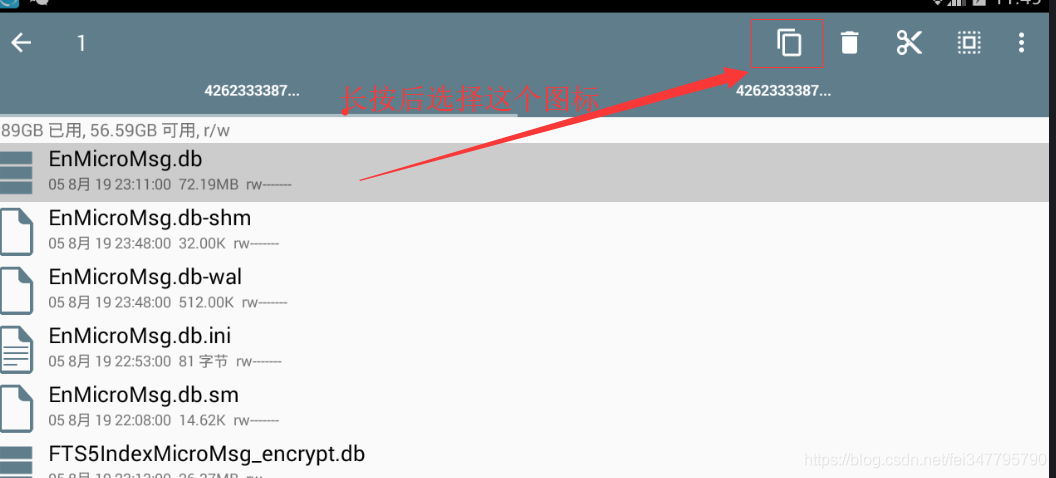

-
导出该数据库后,使用一款叫 sqlcipher 的软件读取数据 将该字符串进行MD5计算后的前七位便是该数据库的密码,如 "355757010761231 857456862" 实际上中间没有空格,然后放入MD5计算取前面七位数字,后续会详细介绍。
哇,真是“简单易懂”啊,没关系,接下来告诉大家IMEI和UIN怎么获得。
首先是IMEI,在模拟器右上角的系统设置 —— 属性设置里就可以找得到啦,如图所示。
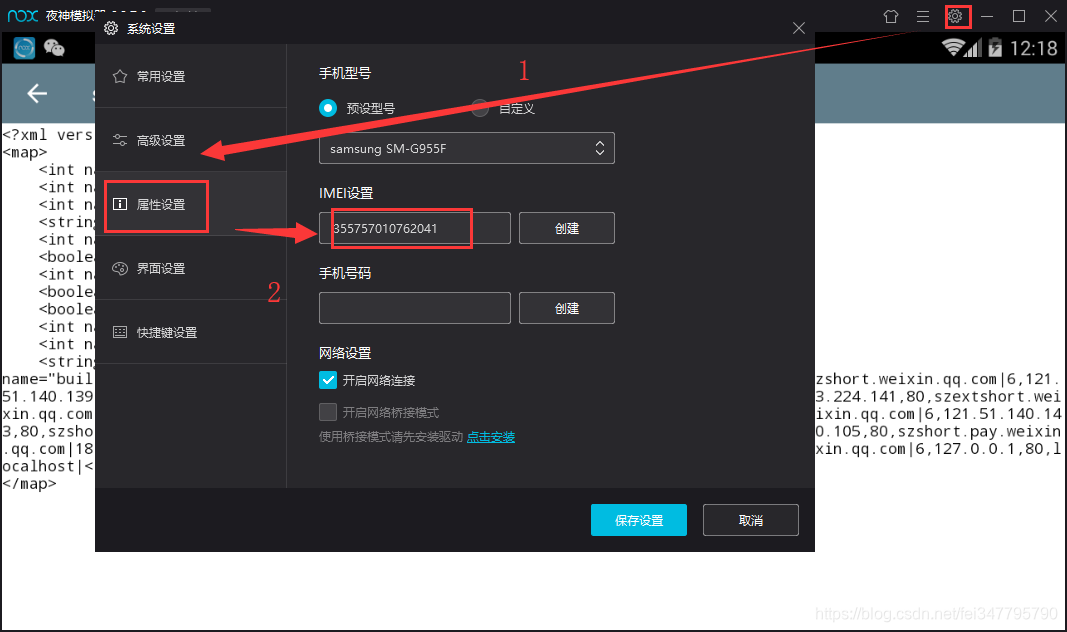
现在我们获得了IMEI号,那UIN号呢?
同样地,用RE文件管理器打开这个文件
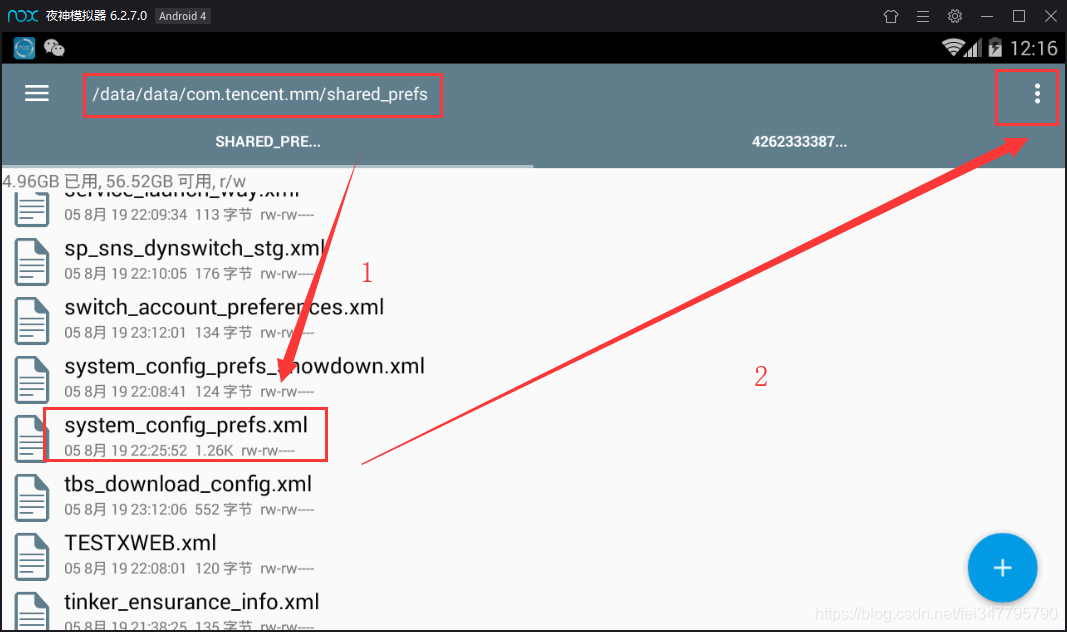
长按改文件,点击右上角的三个点—选择打开方式—文本浏览器,找到default_uin,后面的数字就是了 !
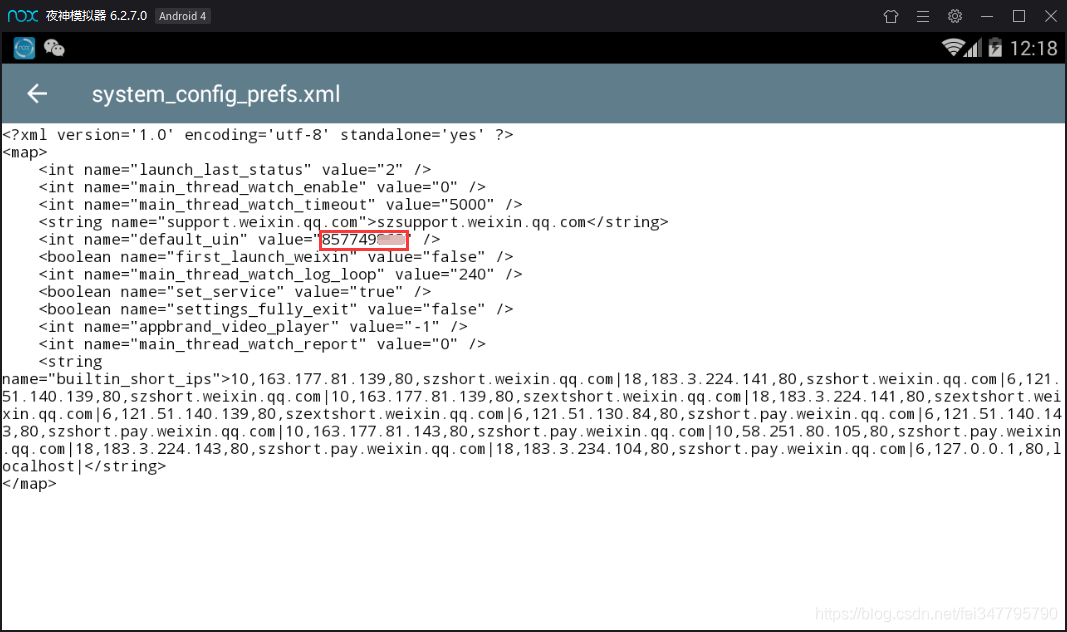
得到这两串数字后,就可以开始计算密码啦,如果我的IMEI是355757010762041,Uin是857749862,那么合起来就是355757010762041857749862,将这串数字放入免费MD5在线计算
得到的数字的前七位就是我们的密码了,像这一串就是 6782538.
然后我们就可以进入我们的核心环节:使用 sqlcipher 导出聊天文本数据!
点击 File - open database - 选择我们刚刚的数据库文件,会弹出框框让你输入密码,我们输入刚刚得到的七位密码,就可以进入到数据库了,选择message表格,这就是你与你的对象的聊天记录! 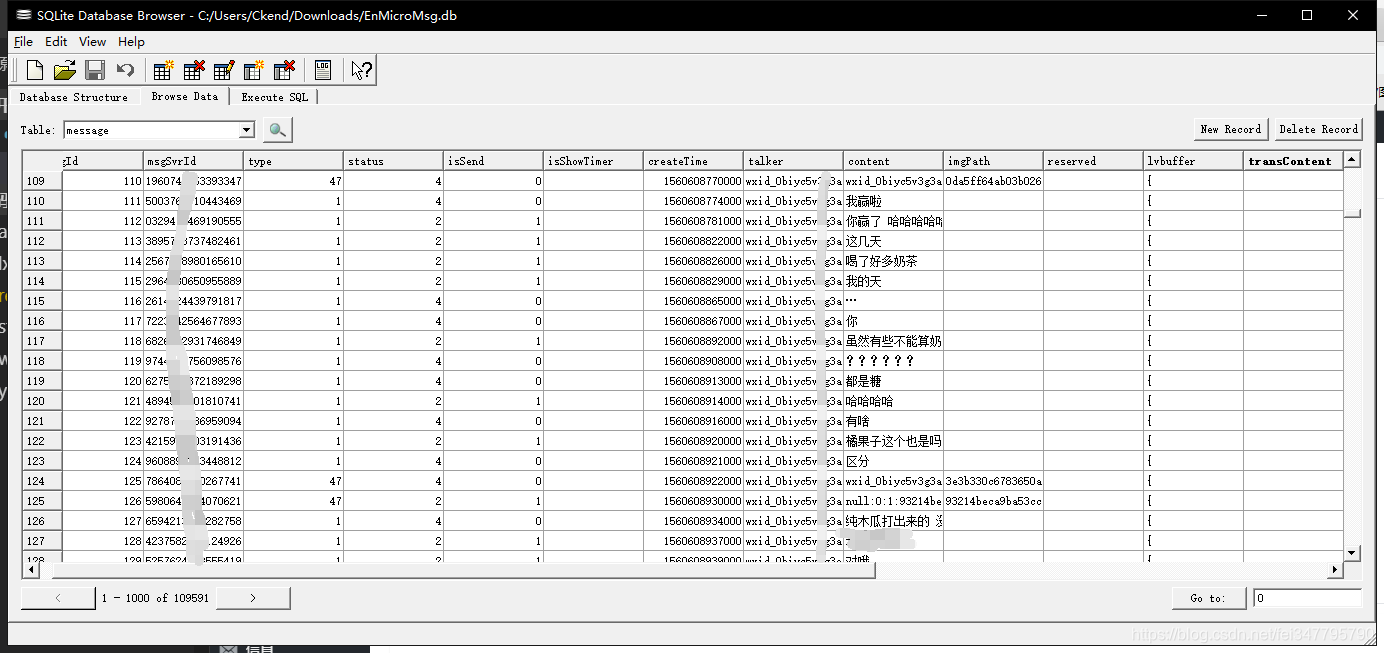
我们可以将它导出成csv文件:File - export - table as csv.
接下来,我们将使用Python代码,将里面真正的聊天内容:content信息提取出来,如下所示。虽然这个软件也允许select,但是它select后不允许导出,非常不好用,因此还不如我们自己写一个:
1 import pandas 2 import csv, sqlite3 3 conn= sqlite3.connect('chat_log.db') 4 # 新建数据库为 chat_log.db 5 df = pandas.read_csv('chat_logs.csv', sep=",") 6 # 读取我们上一步提取出来的csv文件,这里要改成你自己的文件名 7 df.to_sql('my_chat', conn, if_exists='append', index=False) 8 # 存入my_chat表中 9 10 conn = sqlite3.connect('chat_log.db') 11 # 连接数据库 12 cursor = conn.cursor() 13 # 获得游标 14 cursor.execute('select content from my_chat where length(content)<30') 15 # 将content长度限定30以下,因为content中有时候会有微信发过来的东西 16 value=cursor.fetchall() 17 # fetchall返回筛选结果 18 19 data=open("聊天记录.txt",'w+',encoding='utf-8') 20 for i in value: 21 data.write(i[0]+'\n') 22 # 将筛选结果写入 聊天记录.txt 23 24 data.close() 25 cursor.close() 26 conn.close() 27 # 关闭连接
记得把csv文件的编码格式转换成utf-8哦,不然可能会运行不下去: 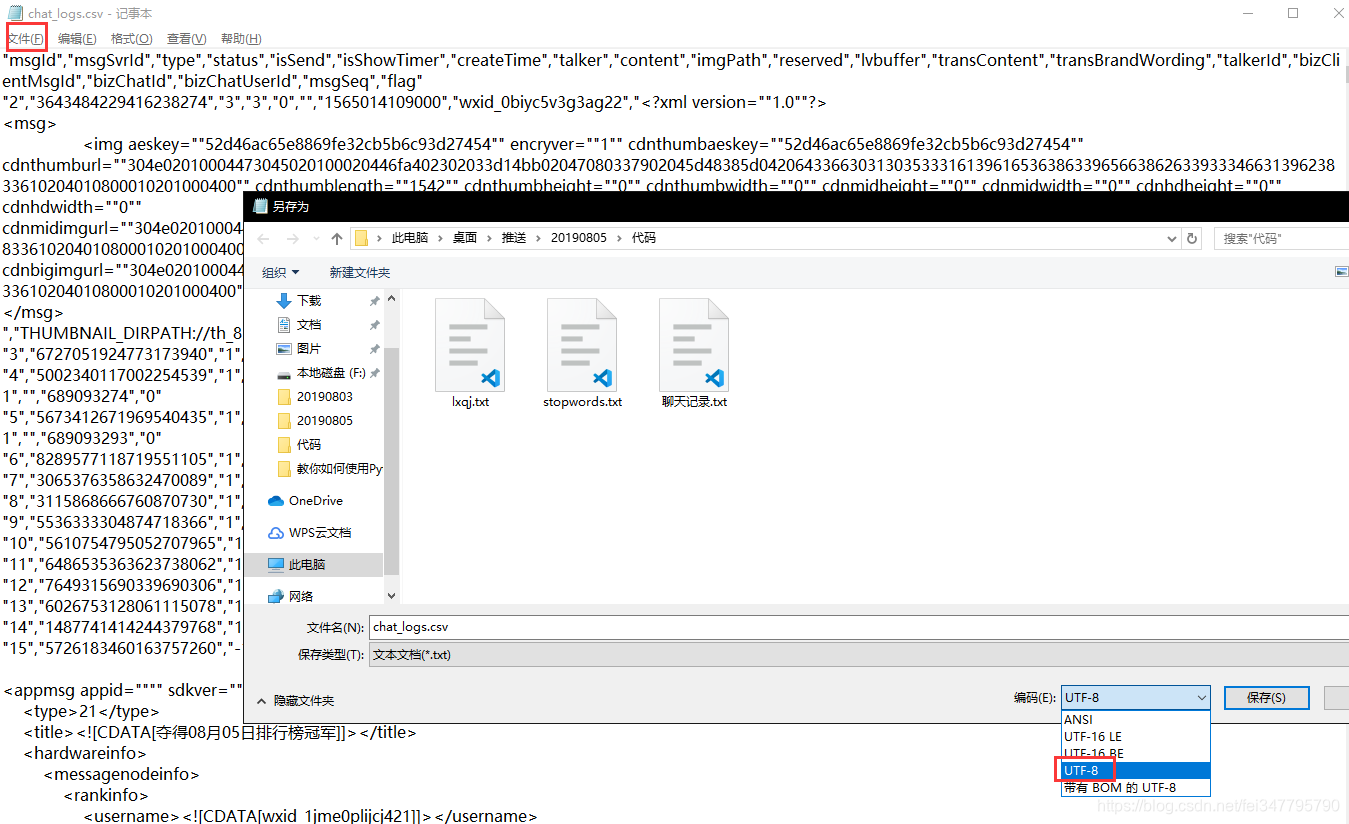
第二步,根据第一步得到的聊天数据生成词云
. 导入我们的聊天记录,并对每一行进行分词
聊天记录是一行一行的句子,我们需要使用分词工具把这一行行句子分解成由词语组成的数组,这时候我们就需要用到结巴分词了。
分词后我们还需要去除词语里一些语气词、标点符号等等(停用词),然后还要自定义一些词典,比如说你们之间恩恩爱爱的话,一般结巴分词是无法识别出来的,需要你自行定义,比如说:小傻瓜别感冒了,一般分词结果是
小/傻瓜/别/感冒/了
如果你把“小傻瓜”加入到自定义词典里(我们下面的例子里是mywords.txt),则分词结果则会是
小傻瓜/别/感冒/了
下面对我们的聊天记录进行分词:
1 import jieba 2 import codecs 3 def load_file_segment(): 4 # 读取文本文件并分词 5 jieba.load_userdict("mywords.txt") 6 # 加载我们自己的词典 7 f = codecs.open(u"聊天记录.txt",'r',encoding='utf-8') 8 # 打开文件 9 content = f.read() 10 # 读取文件到content中 11 f.close() 12 # 关闭文件 13 segment=[] 14 # 保存分词结果 15 segs=jieba.cut(content) 16 # 对整体进行分词 17 for seg in segs: 18 if len(seg) > 1 and seg != '\r\n': 19 # 如果说分词得到的结果非单字,且不是换行符,则加入到数组中 20 segment.append(seg) 21 return segment 22 print(load_file_segment())
-
计算分词后的词语对应的频数
为了方便计算,我们需要引入一个叫pandas的包,然后为了计算每个词的个数,我们还要引入一个叫numpy的包,cmd/terminal中输入以下命令安装pandas和numpy:
pip install pandas
pip install numpy
1 import pandas 2 import numpy 3 def get_words_count_dict(): 4 segment = load_file_segment() 5 # 获得分词结果 6 df = pandas.DataFrame({'segment':segment}) 7 # 将分词数组转化为pandas数据结构 8 stopwords = pandas.read_csv("stopwords.txt",index_col=False,quoting=3,sep="\t",names=['stopword'],encoding="utf-8") 9 # 加载停用词 10 df = df[~df.segment.isin(stopwords.stopword)] 11 # 如果不是在停用词中 12 words_count = df.groupby(by=['segment'])['segment'].agg({"计数":numpy.size}) 13 # 按词分组,计算每个词的个数 14 words_count = words_count.reset_index().sort_values(by="计数",ascending=False) 15 # reset_index是为了保留segment字段,排序,数字大的在前面 16 return words_count 17 print(get_words_count_dict())
完整代码,wordCloud.py 如下,附有详细的解析:
1 import jieba 2 import numpy 3 import codecs 4 import pandas 5 import matplotlib.pyplot as plt 6 from scipy.misc import imread 7 import matplotlib.pyplot as plt 8 from wordcloud import WordCloud, ImageColorGenerator 9 from wordcloud import WordCloud 10 11 def load_file_segment(): 12 # 读取文本文件并分词 13 jieba.load_userdict("mywords.txt") 14 # 加载我们自己的词典 15 f = codecs.open(u"聊天记录.txt",'r',encoding='utf-8') 16 # 打开文件 17 content = f.read() 18 # 读取文件到content中 19 f.close() 20 # 关闭文件 21 segment=[] 22 # 保存分词结果 23 segs=jieba.cut(content) 24 # 对整体进行分词 25 for seg in segs: 26 if len(seg) > 1 and seg != '\r\n': 27 # 如果说分词得到的结果非单字,且不是换行符,则加入到数组中 28 segment.append(seg) 29 return segment 30 31 def get_words_count_dict(): 32 segment = load_file_segment() 33 # 获得分词结果 34 df = pandas.DataFrame({'segment':segment}) 35 # 将分词数组转化为pandas数据结构 36 stopwords = pandas.read_csv("stopwords.txt",index_col=False,quoting=3,sep="\t",names=['stopword'],encoding="utf-8") 37 # 加载停用词 38 df = df[~df.segment.isin(stopwords.stopword)] 39 # 如果不是在停用词中 40 words_count = df.groupby(by=['segment'])['segment'].agg({"计数":numpy.size}) 41 # 按词分组,计算每个词的个数 42 words_count = words_count.reset_index().sort_values(by="计数",ascending=False) 43 # reset_index是为了保留segment字段,排序,数字大的在前面 44 return words_count 45 46 words_count = get_words_count_dict() 47 # 获得词语和频数 48 49 bimg = imread('ai.jpg') 50 # 读取我们想要生成词云的模板图片 51 wordcloud = WordCloud(background_color='white', mask=bimg, font_path='simhei.ttf') 52 # 获得词云对象,设定词云背景颜色及其图片和字体 53 54 # 如果你的背景色是透明的,请用这两条语句替换上面两条 55 # bimg = imread('ai.png') 56 # wordcloud = WordCloud(background_color=None, mode='RGBA', mask=bimg, font_path='simhei.ttf') 57 58 words = words_count.set_index("segment").to_dict() 59 # 将词语和频率转为字典 60 wordcloud = wordcloud.fit_words(words["计数"]) 61 # 将词语及频率映射到词云对象上 62 bimgColors = ImageColorGenerator(bimg) 63 # 生成颜色 64 plt.axis("off") 65 # 关闭坐标轴 66 plt.imshow(wordcloud.recolor(color_func=bimgColors)) 67 # 绘色 68 plt.show()

