微服务之全局ID解决方案
美团Leaf
美团Leaf 配置
百度UidGenerator
在大型网站中,随着数据量、并发量的提升,我们除了会对业务系统进行微服务的改造,也会在数据库层面进行数据的水平和垂直拆分,当数据分库分表后需要有一个唯一ID来标识一条数据或消息。此时之前单体架构中所用到的像UUID、数据库sequence等技术显然不能满足需求。
一、全局ID需要考虑的问题
1. 传统ID生成方式
-
UUID
a. UUID.randomUUID.toString()方式: 基于时间和MAC地址生成(time & MAC),因此会存在MAC地址被泄露的安全隐患
b. UUID(TIME & posix uid或GID)方式
c. 随机数的UUID
d. UUID(SHA1) -
数据库层面
a. mySqlselect LAST_INSERT_ID()
b. oracleselect USER_ID_SEQ.NEXTVAL as myID from DUAL
c. RedisincreBy/incr
d. MongodbObjectId
2. 全局ID考虑的问题
- 全局唯一性
- 有序递增性
- 高可用性
- 时间上的特性,最好能从时间上看出生成id的先后顺序
二、全局ID的实现方式
目前知名公司都有一套全局ID的生成方式,像美团的Leaf、百度的UIDGenerto等,此处介绍Twitter的雪花算法,美团的Leaf。
世界上没有完全相同的两片雪花/叶子,两个项目的命名也包含了唯一性的含义。
1. 雪花算法 SnowFlake
雪花算法ID是由64个比特位组成:
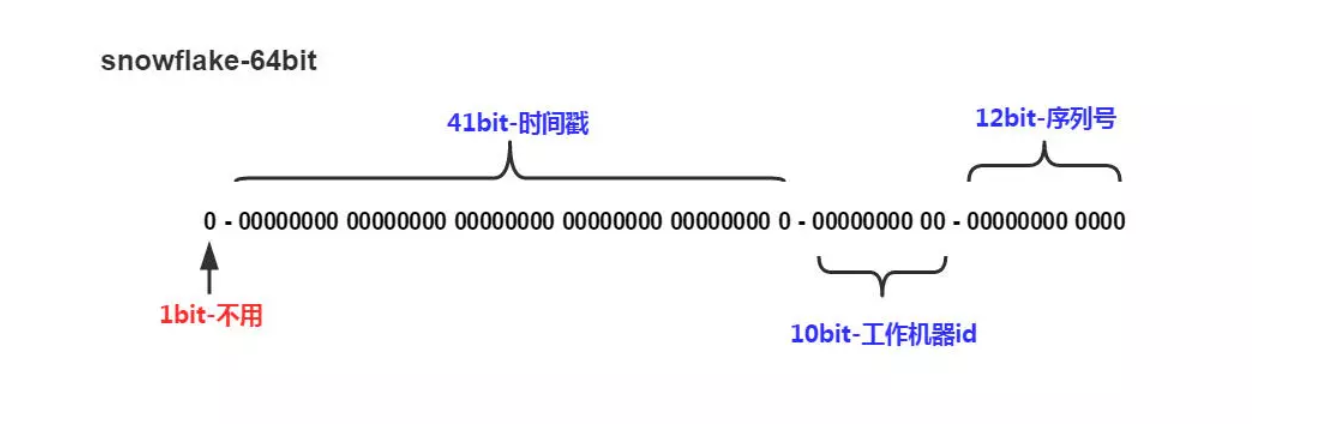
1位标识符:始终是0,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,id一般是正数,最高位是0。
41位时间戳:41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截 )得到的值,这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的。
10位机器标识码:可以部署在1024个节点,如果机器分机房(IDC)部署,这10位可以由 5位机房ID + 5位机器ID 组成。
12位序列:毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号
- 优点
简单高效,生成速度快。
时间戳在高位,自增序列在低位,整个ID是趋势递增的,按照时间有序递增。
灵活度高,可以根据业务需求,调整bit位的划分,满足不同的需求。 - 缺点
依赖机器的时钟,如果服务器时钟回拨,会导致重复ID生成。
在分布式环境上,每个服务器的时钟不可能完全同步,有时会出现不是全局递增的情况。
实现
import java.util.concurrent.TimeUnit;
/**
* snowFlake : 雪花算法 64位
* 1bit不用 + 41bit时间戳 + 10bit机器id + 12bit序列号
*/
public class SnowFlakeGenerator {
private long roomId; // 机房id
private long workerId; // 机器id
private long sequence; // 递增开始的序列
private long lastTimestamp = -1L; // 存储上一次生成的id的时间戳
// 10bit机器id
private long roomIdBit = 5l; // 占用5个bit位
private long workerIdBit = 5l; // 占用5个bit位
// 12bit序列号
private long sequenceBits = 12l; // 12bit的递增序列
/**
* http://c.biancheng.net/view/784.html
* https://www.sojson.com/hexconvert/2to10.html
*
* -1 ^ (-1 << 5) : -1 位异或 (-1 左移 5)
* -1二进制:为1的二进制取反再加一
* int类型的1 二进制(32位): 00000000 00000000 00000000 00000001
* 反码 - 取反: 11111111 11111111 11111111 11111110
* 补码 - 加一: 11111111 11111111 11111111 11111111
* -1<<5,-1左移5位: 低位补零
* 11111111 11111111 11111111 11100000
* -1 ^ (-1<<5), -1异或(-1左移5位):
* 11111111 11111111 11111111 11111111
* 11111111 11111111 11111111 11100000
* 得出: 00000000 00000000 00000000 00011111
* 转10进制: 2^5-1 = 32-1 = 31
*
* -1 ^ (-1<<12) 得出: 2^12-1 = 4096-1 = 4095
*/
private long maxRoomId = -1l ^ (-1l << roomIdBit); // 声明roomId最大的正整数31, 同时支持31个机房
private long maxWorkerId = -1l ^ (-1l << workerIdBit); // 声明workerId最大的正整数31, 同时支持每个机房32台机器
private long maxSequenceMask = -1l ^ (-1l << sequenceBits); // 声明sequence最大的正整数4095, 每毫秒并发量4095
private long twepoch = 1598099282395l; // 初始时间戳
private long workerIdShift = sequenceBits; // workerId位置:左移 12 位
private long roomIdShift = sequenceBits + workerIdBit; // roomId位置:左移 12 + 5 位
private long timeStampShift = sequenceBits + workerIdBit + roomIdBit; // 时间戳的位置: 左移 12 + 5 + 5 位
public SnowFlakeGenerator(long roomId, long workerId, long sequence) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException("Worker Id不符合规范!");
}
if (roomId > maxRoomId ||roomId < 0) {
throw new IllegalArgumentException("Room Id不符合规范!");
}
this.roomId = roomId;
this.workerId = workerId;
this.sequence = sequence;
}
public synchronized long nextVal() {
// 毫秒级内序列号不能相同
long timestamp = System.currentTimeMillis();
if (timestamp < lastTimestamp) {
throw new RuntimeException("时间戳异常,可能存在时钟回拨!");
}
if (lastTimestamp == timestamp) {
// 同一毫秒内,递增
sequence = (sequence+1) & maxSequenceMask;
if(sequence == 0) {
// 为0,同一毫秒内超过最大并发量4095,等待至下一毫秒
timestamp = waitToNextMills(timestamp);
}
} else {
// 新的毫秒,sequence重置
// sequence = 0; //如果直接重置为0,如果并发量没那么高,每毫秒只生产1个id,会发现生产的id都是偶数,在分库分表根据id落地时,数据会都偏向一张表
sequence = timestamp&1;
}
lastTimestamp = timestamp;
// 1bit不用 + 41bit时间戳 + 10bit机器id + 12bit序列号
return ( ((timestamp - twepoch) << timeStampShift) | (roomId<<roomIdShift) | (workerId<<workerIdShift) | sequence );
}
// 执行到下一个时间毫秒
private long waitToNextMills(long lastTimeStamp) {
long timeStamp = System.currentTimeMillis();
while (timeStamp <= lastTimeStamp) {
timeStamp = System.currentTimeMillis();
}
return timeStamp;
}
public static void main(String[] args) {
SnowFlakeGenerator generator = new SnowFlakeGenerator(1, 1, 1);
for (int i = 0; i < 111; i++) {
// try {
// TimeUnit.MILLISECONDS.sleep(1);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
System.out.println(generator.nextVal());
}
}
}
微服务架构中不同机器部署,可以在服务启动时将机房id及机器id作为参数传入,将算法类作为单例对象放入Spring容器。
2. 美团Leaf
这里仅是简单总结,详细文章参照
美团Leaf 介绍
美团Leaf 使用配置
提供了基于数据库的Leaf-segment方案和基于snowflake的方案来生成全局Id。
- 数据库的高可用(master-slave)
- 多主,步长 step
设置步长,每个id都从数据库中取
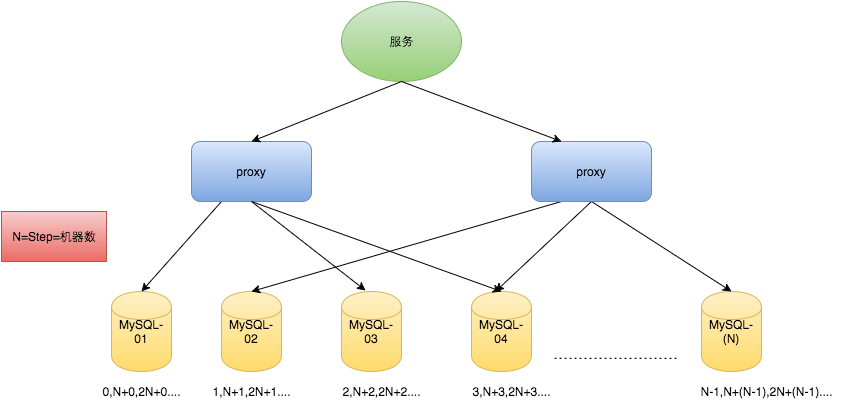
因为每次生成id都要频繁与数据库做交互,数据库压力会很大,网络IO耗时,因此引入了 Leaf-segment方案。
a. Leaf-segment 方案
数据库表设计如下:
+-------------+--------------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+--------------+------+-----+-------------------+-----------------------------+
| biz_tag | varchar(128) | NO | PRI | | |
| max_id | bigint(20) | NO | | 1 | |
| step | int(11) | NO | | NULL | |
| desc | varchar(256) | YES | | NULL | |
| update_time | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |
+-------------+--------------+------+-----+-------------------+-----------------------------+
Buffer缓存:
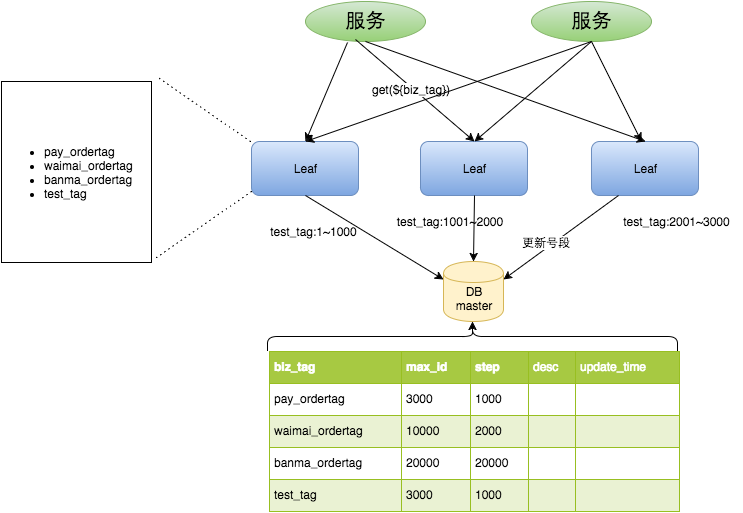
不需要每个ID都与数据库做交互,提前读取一个批次的id,并将max_id更新;
存在问题:每个step用完才去获取下一号段,此时与数据库交互时如果出现网络抖动或数据库查询慢会造成获取id的线程阻塞,可能存在影响性能的情况。
双Buffer优化:
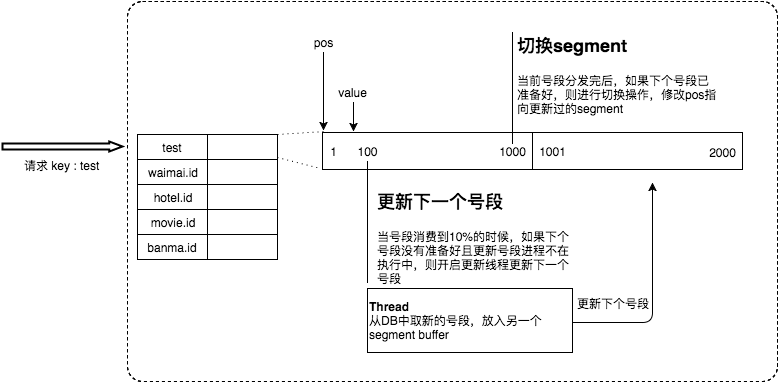
当第一个Buffer使用了10%时,启动线程异步从数据库中读取下一步长step,缓存入第二个buffer备用。
Leaf-segment方案可以生成趋势递增的ID,同时ID号是可计算的,不适用于订单ID生成场景,比如竞对在两天中午12点分别下单,通过订单id号相减就能大致计算出公司一天的订单量,这个是不能忍受的。面对这一问题,美团提供了 Leaf-snowflake方案。
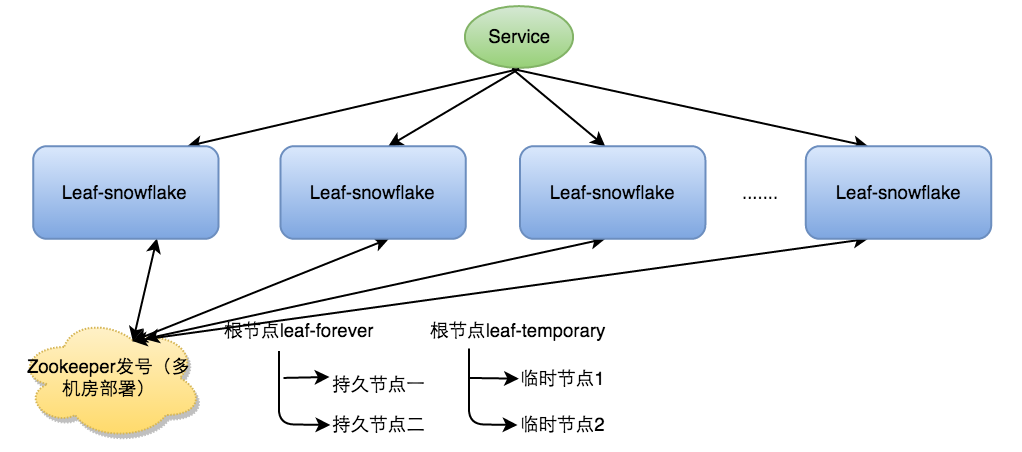
b.Leaf-snowflake 方案
基于 Snowflake,结合zookeeper生成全局id

 浙公网安备 33010602011771号
浙公网安备 33010602011771号