关于json接口返回的数据不是json格式的处理方法——正则匹配
今天尝试爬取一个小视频网站的视频(当然不是大家想的那个小视频):www.vmovier.com
一开始以为直接进去网页后使用xpath匹配链接就行 测试发现该网站使用懒加载技术 所以直接爬的方法行不通 不能完全匹配所有视频链接
于是我抓取了它的加载接口:https://www.vmovier.com/post/getbytab?tab=new&page=3&pagepart=1
其中page参数是页数、pagepart参数是每页的第几次加载,经过测试发现每一页都有三次加载,这里可以使用循环来实现
page = int(input("请输入您要爬取的页数:")) #将捕获接口拿过来 因为是动态的页面 所以捕获接口 向接口发送数据 #page=页数 pagepart=每页的第几次刷新 每页有三次刷新分别是1 2 3 可以写一个循环 for T in range (1,4): url = "https://www.vmovier.com/post/getbytab?tab=new&page=% s&pagepart=%d" %(page,T) #print(url) # exit()
然后本文的主要问题是这个接口说是返回的是json数据格式,但是我打开发现根本不是标准json格式:
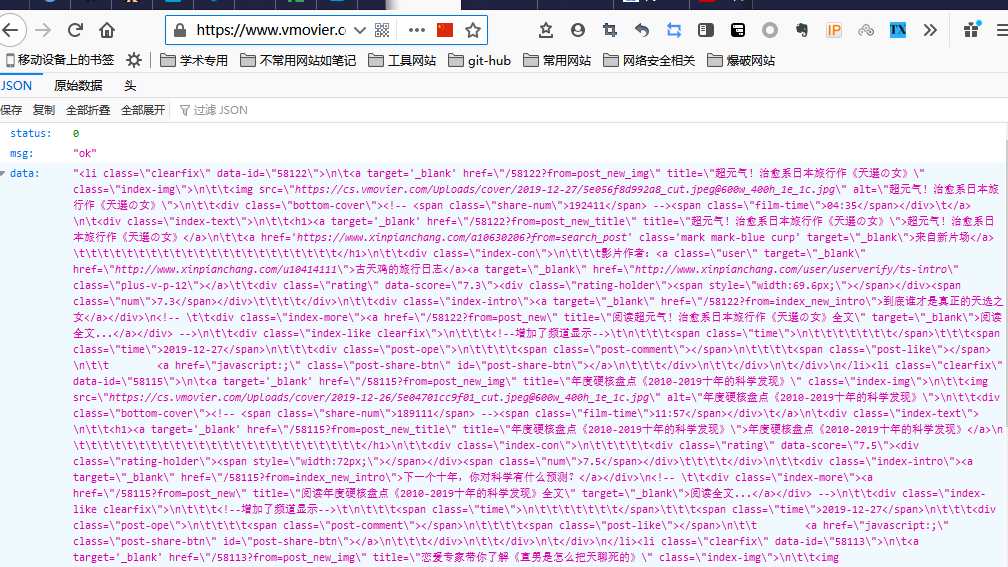
这里我强烈谴责开发这个接口的程序员,耗费了我好长时间去寻找别的解决方法
下面这一块是我想过滤出的东西:

一开始想的是获取data字典的部分,转化为HTML格式, 使用xpath来过滤我需要的标题和视频链接,但是实验发现行不通,最后我选择使用了正则匹配的方法,不得不说正则真滴强:
import requests from bs4 import BeautifulSoup import time from lxml import etree import re import json #添加头部 作为全局 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36' } url = "https://www.vmovier.com/post/getbytab?tab=new&page=3&pagepart=1" r = requests.get(url=url,headers=headers) #print(r.text) obj = json.loads(r.text) # print(obj) # exit() #取出所有和视频相关的数据 标题和url data是一个列表 里面存放的都是字典 data = obj['data'] #print(data) # # exit() # tree = etree.HTML(data) # title = tree.xpath('//div[@class ="index-more"]') # print(title) match_obj_url = re.compile(r'<a href="(.*)" title=".*全文" target="_blank">阅读全文...</a>') url = re.findall(match_obj_url,data) print(url) match_obj_title = re.compile(r'<a href=".*" title="(.*)全文" target="_blank">阅读全文...</a>') title = re.findall(match_obj_title,data) print(title) exit()

费了2个多小时的时间,可算搞出来了后面获得这个url还不是最终视频的url 竟然还有个跳转 真是块难啃的骨头,但是应该问题不大,先记录一下这个问题,以后遇到再看看 不管开发人员多么狡猾 我都要攻克你们
作者:求知鱼
-------------------------------------------
个性签名:你有一个苹果,我有一个苹果,我们交换一下,一人还是只有一个苹果;你有一种思想,我有一种思想,我们交换一下,一个人就有两种思想。
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!
独学而无友,则孤陋而寡闻,开源、分享、白嫖!
