20172310《程序设计与数据结构》(下)实验三:查找与排序实验报告
20172310《程序设计与数据结构》(下)实验三:查找与排序实验报告
报告封面
- 课程:《软件结构与数据结构》
- 班级: 1723
- 姓名: 仇夏
- 学号:20172310
- 实验教师:王志强老师
- 实验日期:2018年11月19日-2018年11月24日
- 必修选修: 必修
实验三-查找与排序-1
实验要求内容
定义一个Searching和Sorting类,并在类中实现linearSearch(教材P162 ),SelectionSort方法(P169),最后完成测试。
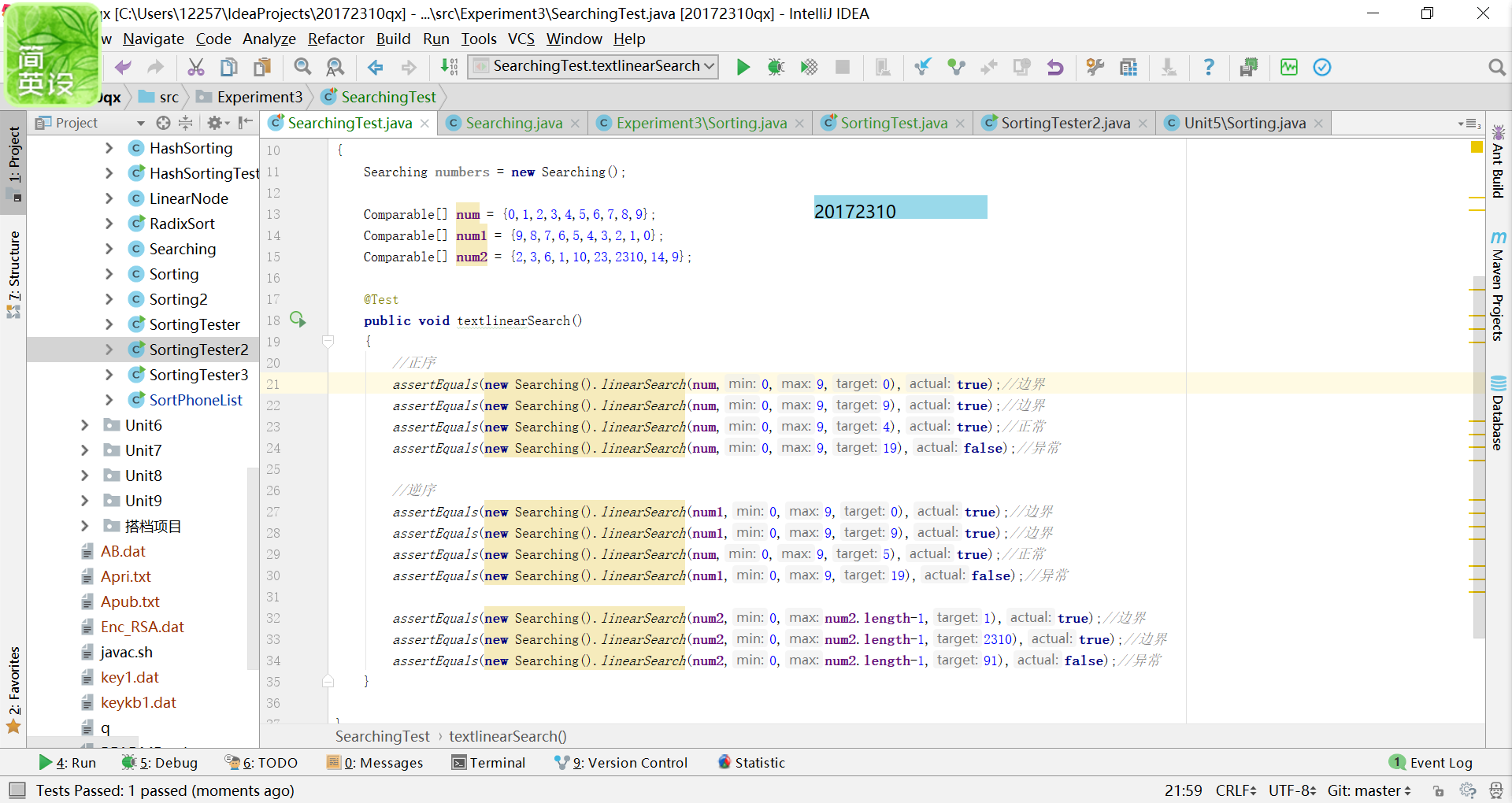
要求不少于10个测试用例,提交测试用例设计情况(正常,异常,边界,正序,逆序),用例数据中要包含自己学号的后四位
提交运行结果图。
实验过程及结果
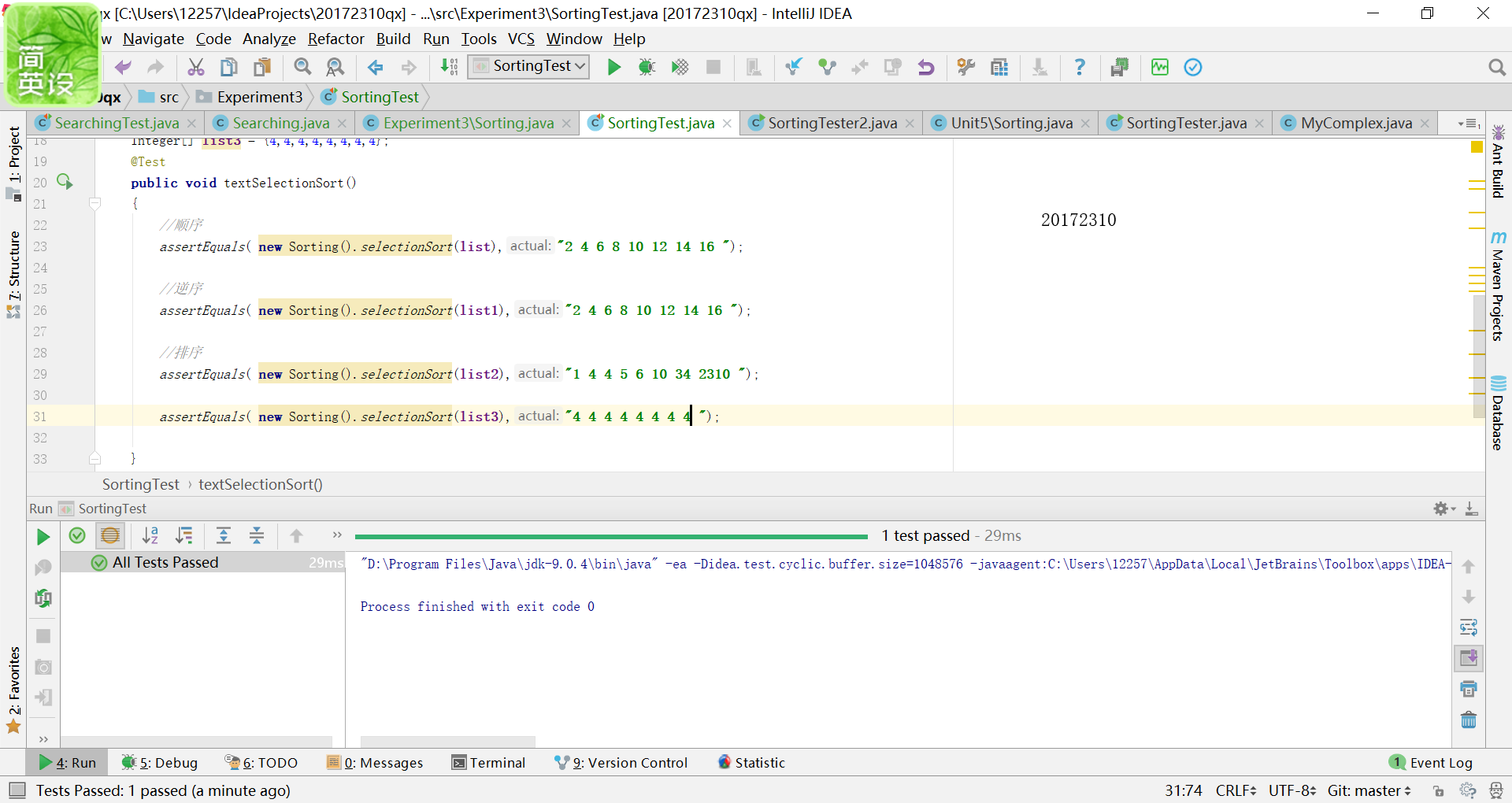
- 这次的测试让我们用的Junit编写的,其实这方面的知识已经忘得差不多了,于是又翻出老师给的博客重新学习了一遍。
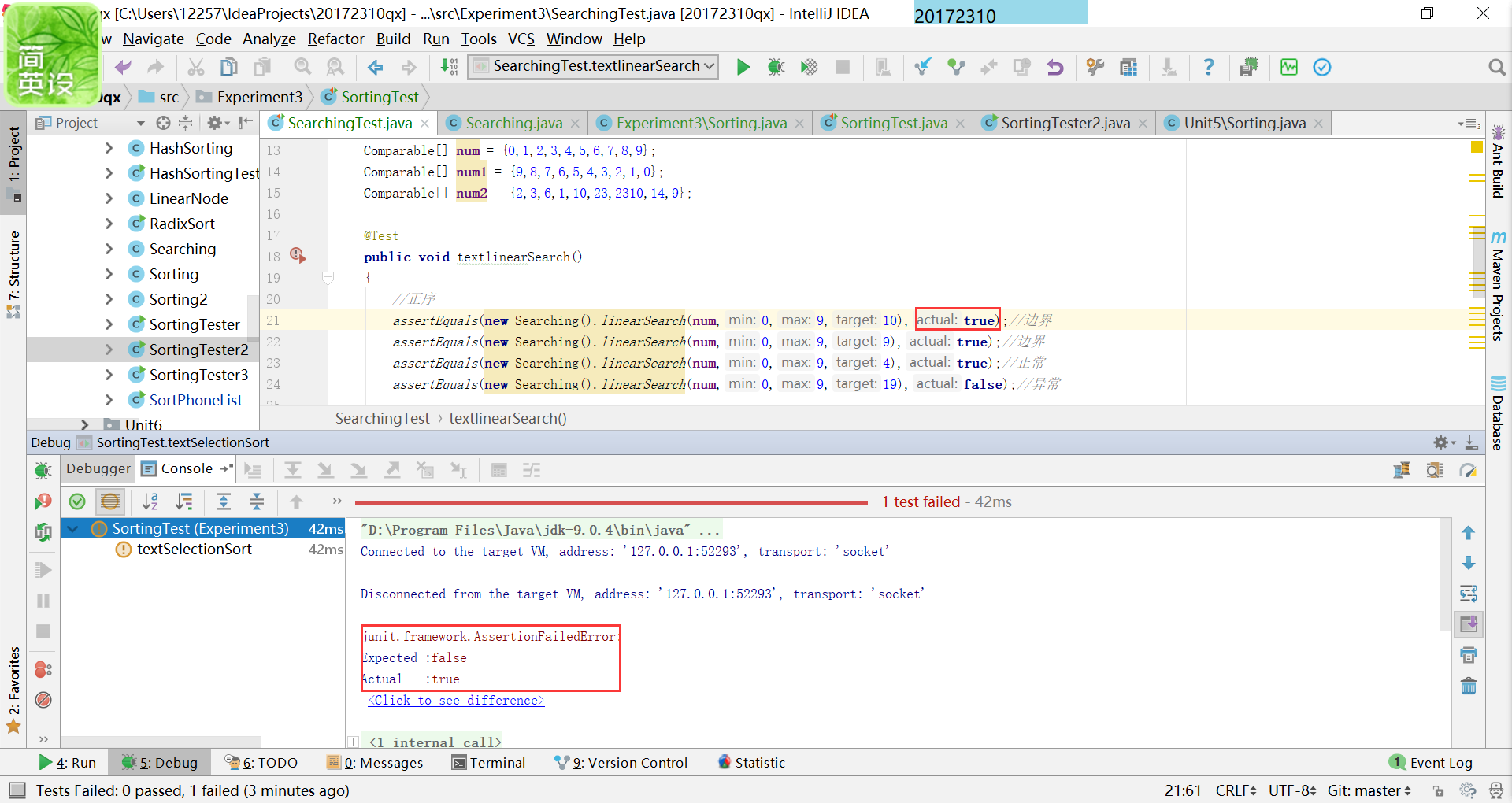
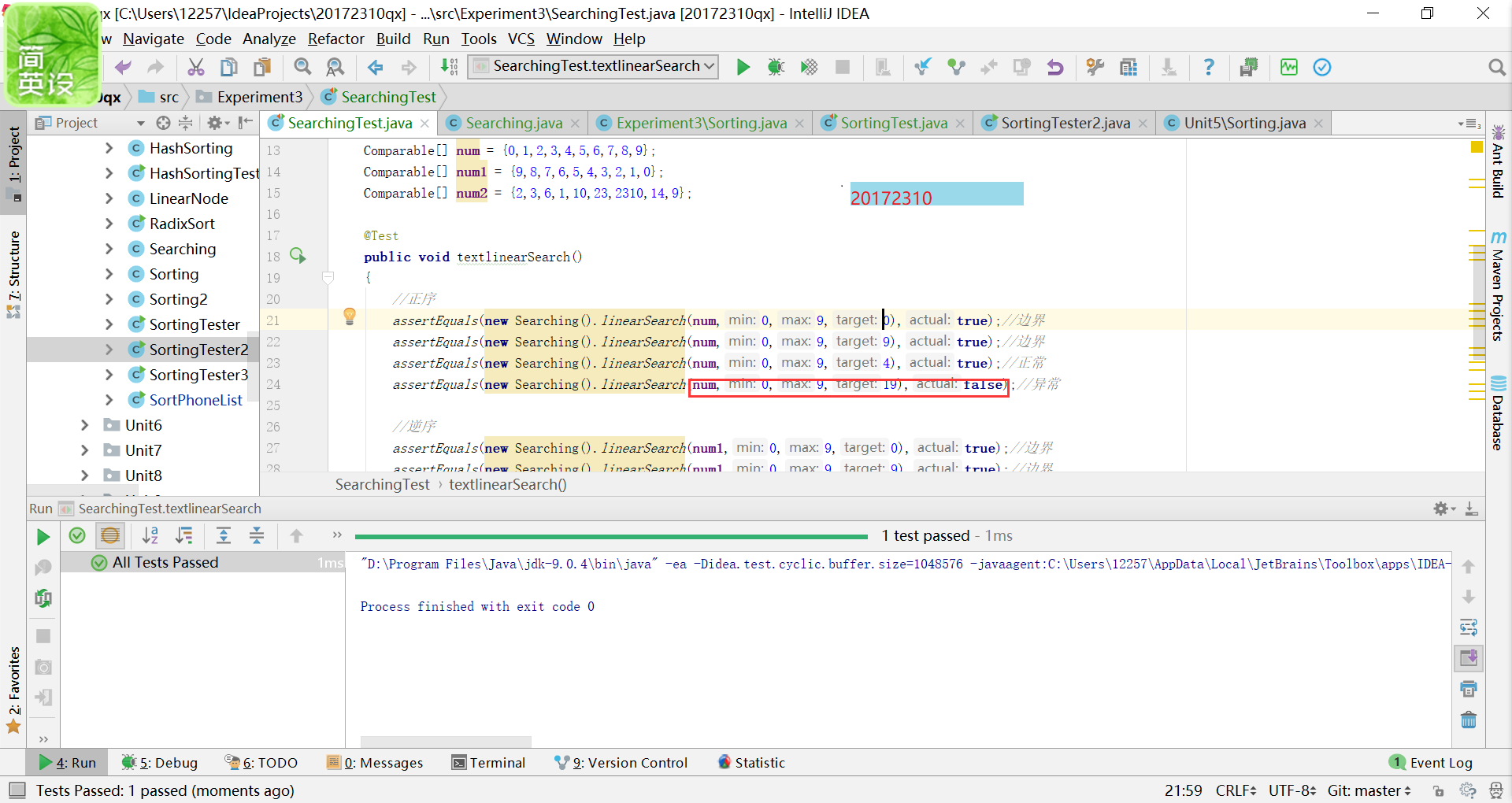
在查找中出现的异常我写了两种,一种是不相匹配,得出的结果不正确,第二种是越界问题,输入的索引值已经超出给定数组的容量;
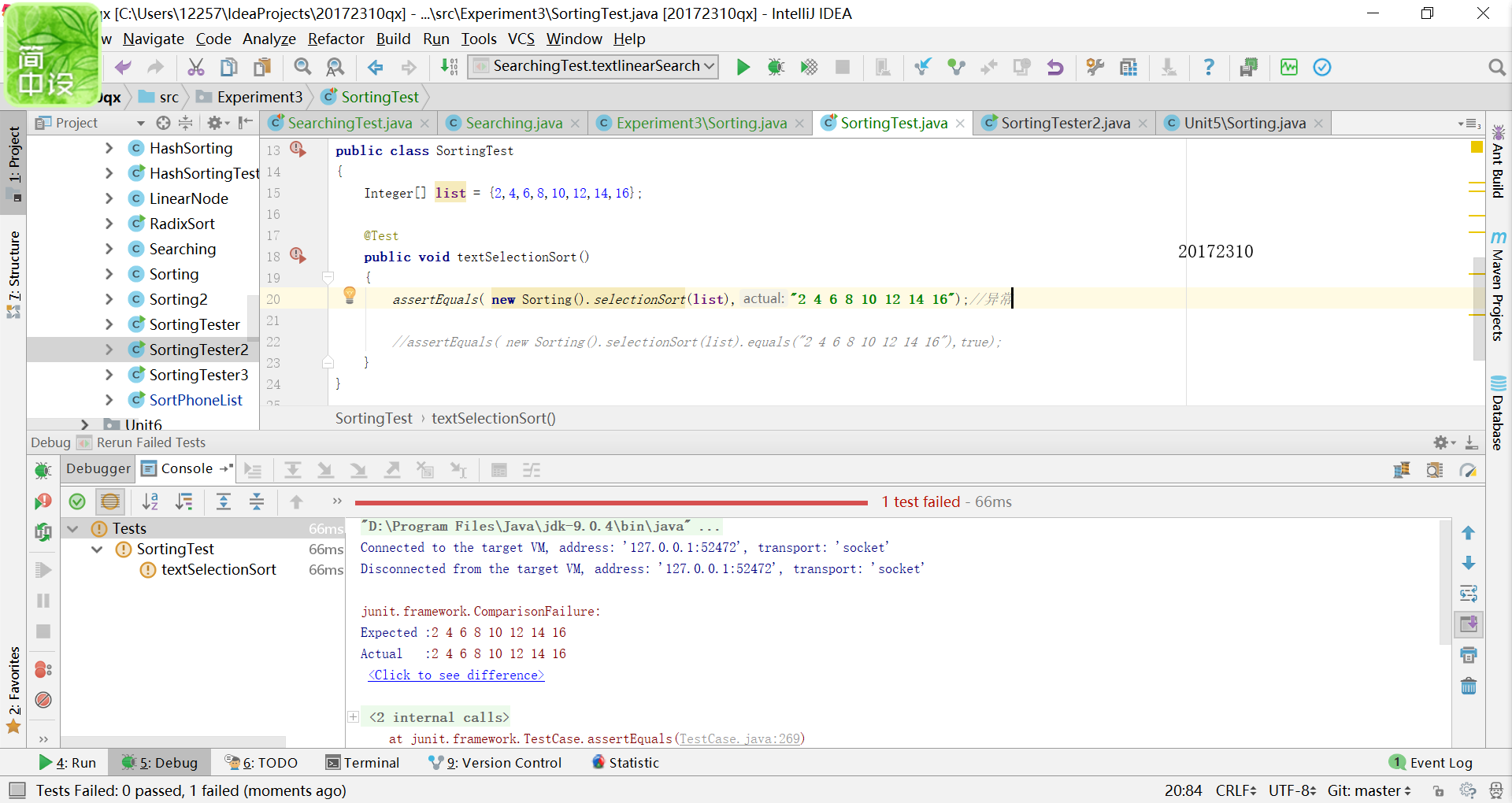
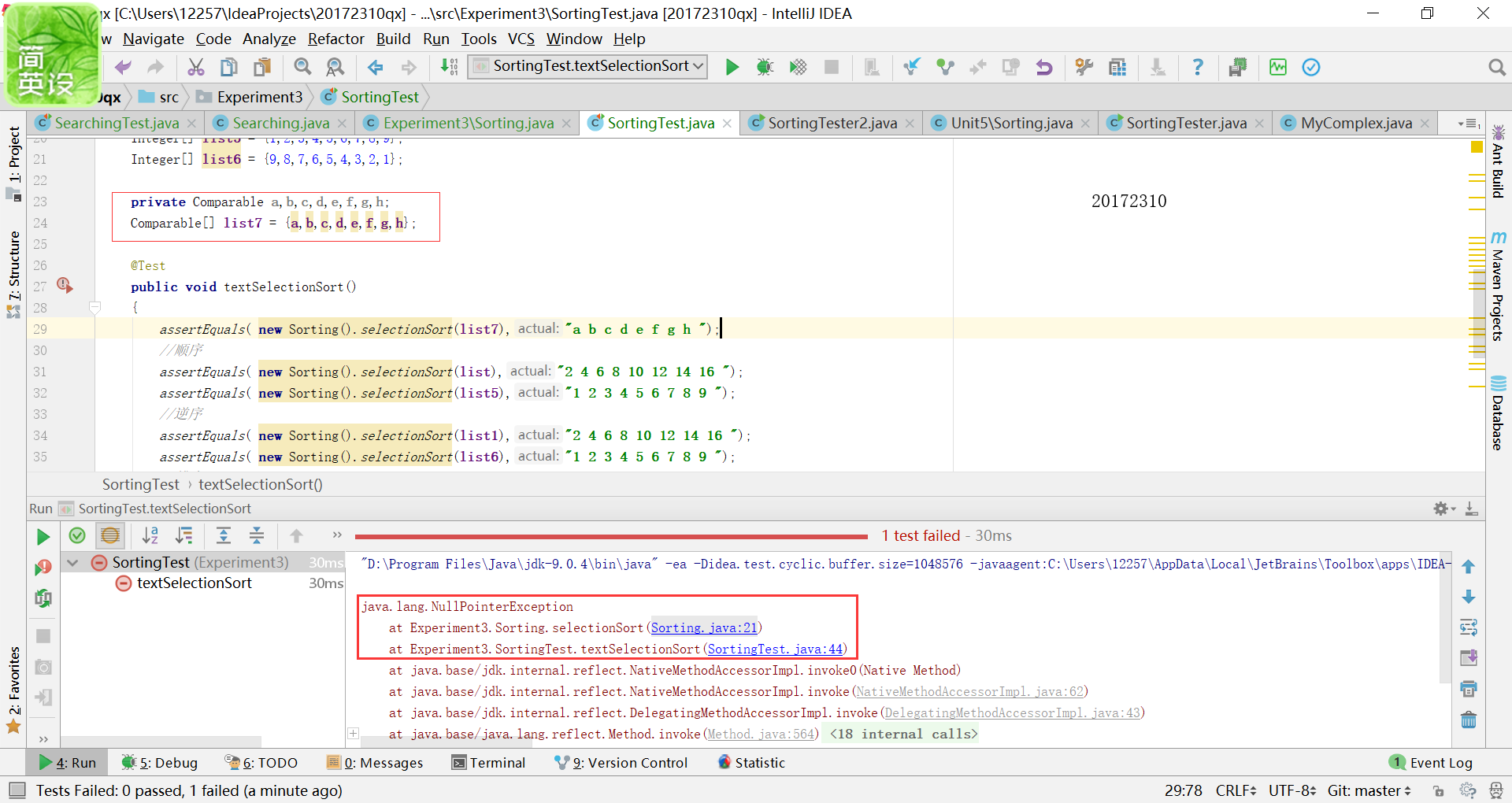
在排序中出现的错误有不相匹配,之前我其实看着两个基本一样的数组很是疑惑,为什么这是false,

经过仔细地观察,最后发现是因为末尾最后少了一个空格(掩面)。另一种错误是数组的类型是Comparable型的,进行不了排序。

实验三-查找与排序-2
实验要求内容
重构你的代码
把Sorting.java Searching.java放入 cn.edu.besti.cs1723.(姓名首字母+四位学号) 包中(例如:cn.edu.besti.cs1723.G2301)
把测试代码放test包中
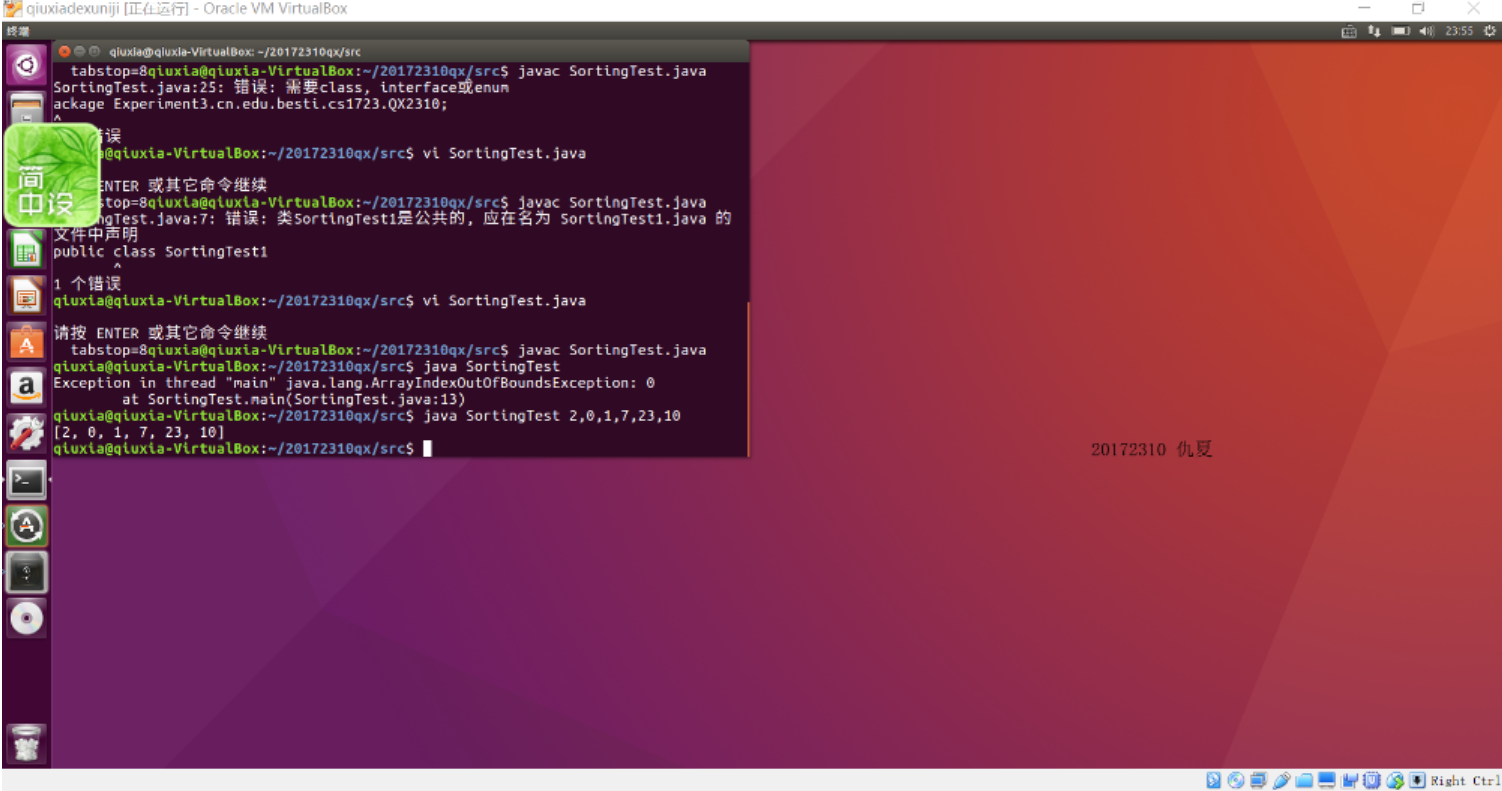
重新编译,运行代码,提交编译,运行的截图(IDEA,命令行两种)
实验过程及结果
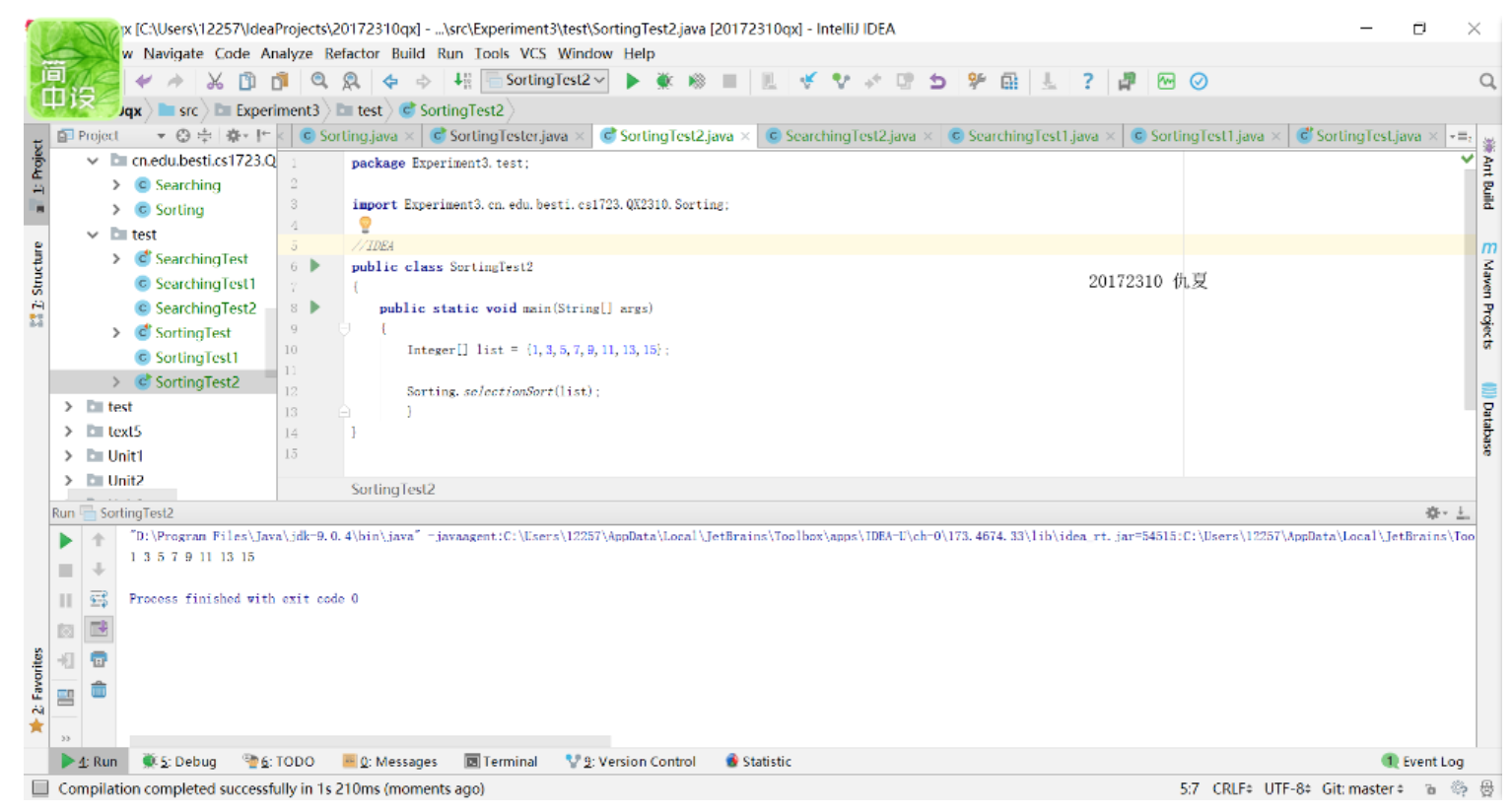
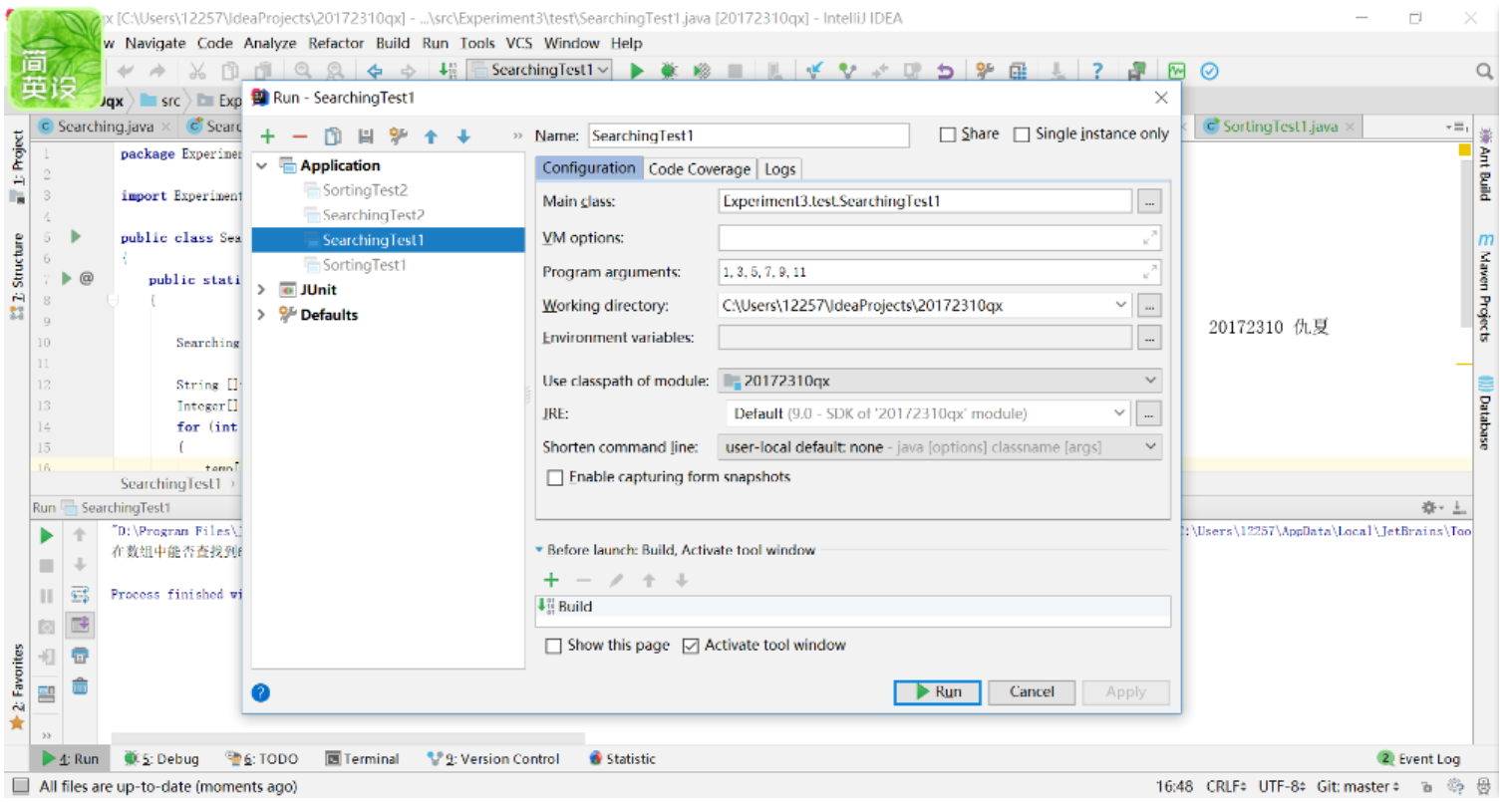
- 命令行怎么写来着?看来自己的知识记得不牢呀。
- 自己重新找资料学习了一下——main函数命令行参数的使用
public static void main(String...args)是自己在IDEA中写的main命令行的代码。

实验三-查找与排序-3
实验要求内容
参考http://www.cnblogs.com/maybe2030/p/4715035.html 在Searching中补充查找算法并测试
提交运行结果截图
实验过程及结果
- 自己补充了一下斐波那契查找算法、分块查找、二叉树查找和哈希查找等查找算法
- 相关代码

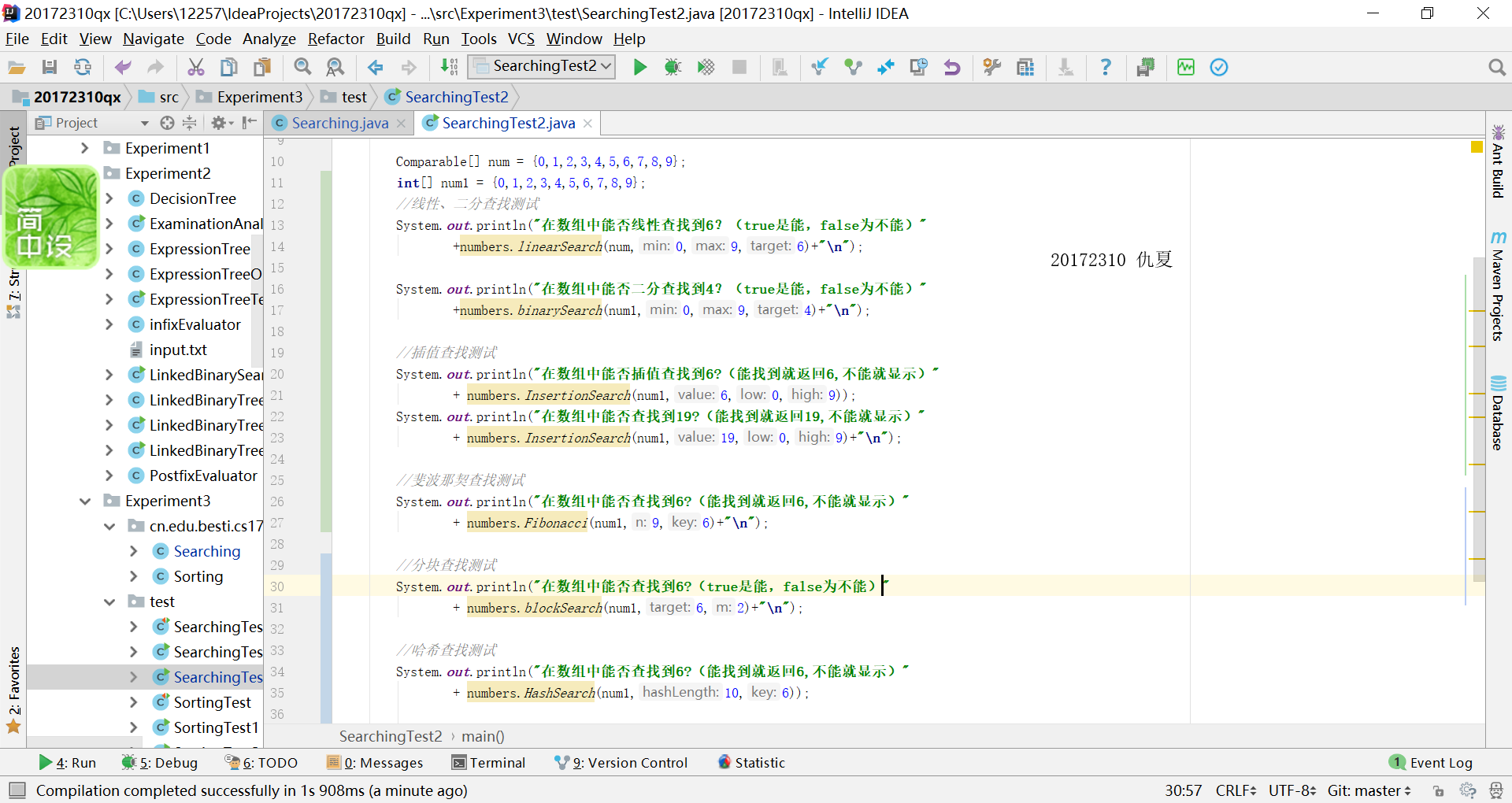
这个实验中我遇到了一些问题,遇到的相关问题会在下面详写。
实验三-查找与排序-4
实验要求内容
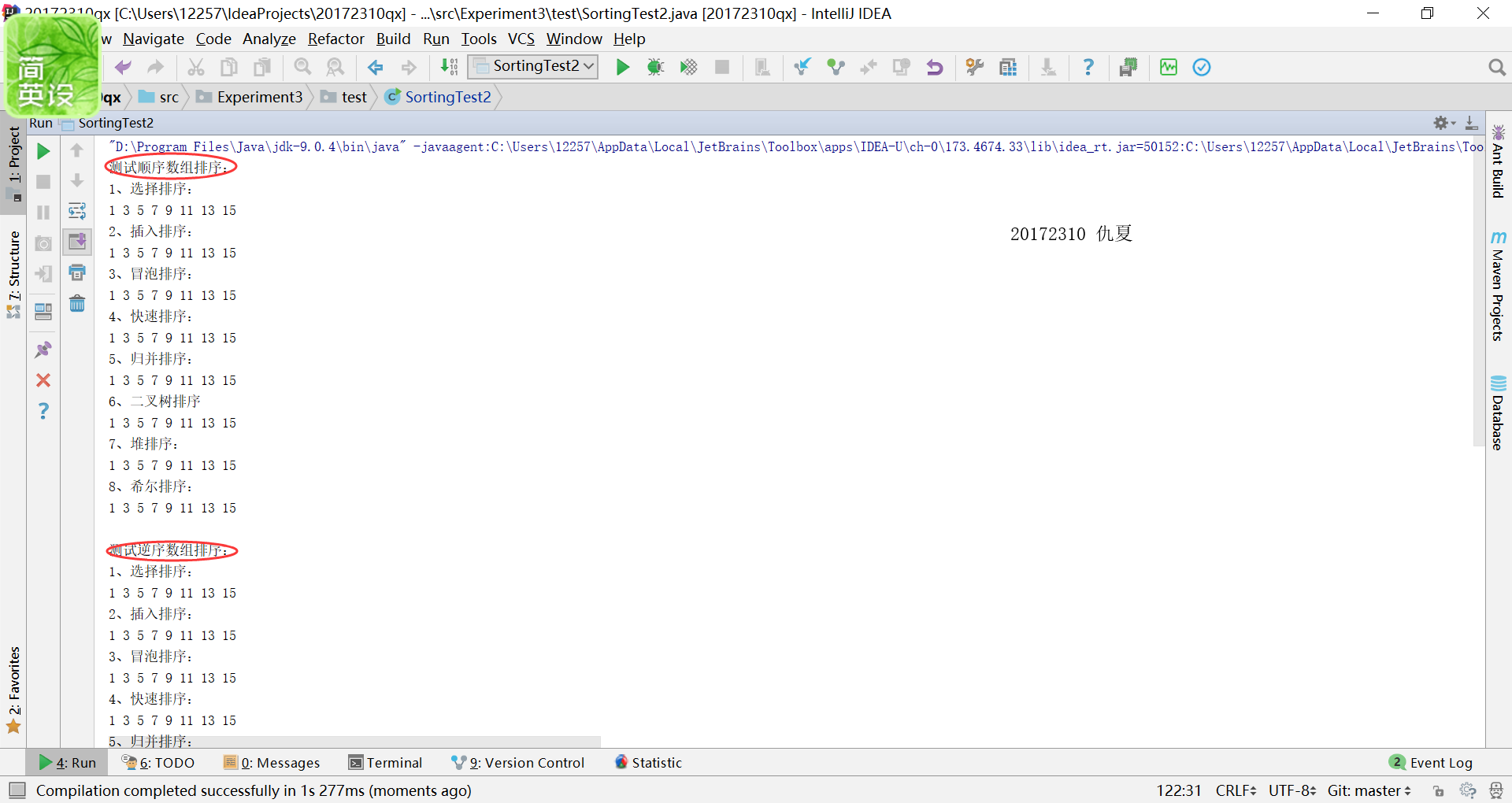
补充实现课上讲过的排序方法:希尔排序,堆排序,二叉树排序等(至少3个)
测试实现的算法(正常,异常,边界)
提交运行结果截图
(3分,如果编写多个排序算法,即使其中三个排序程序有瑕疵,也可以酌情得满分)
实验过程及结果
- 部分的排序算法之前的课本学习中已经完成过
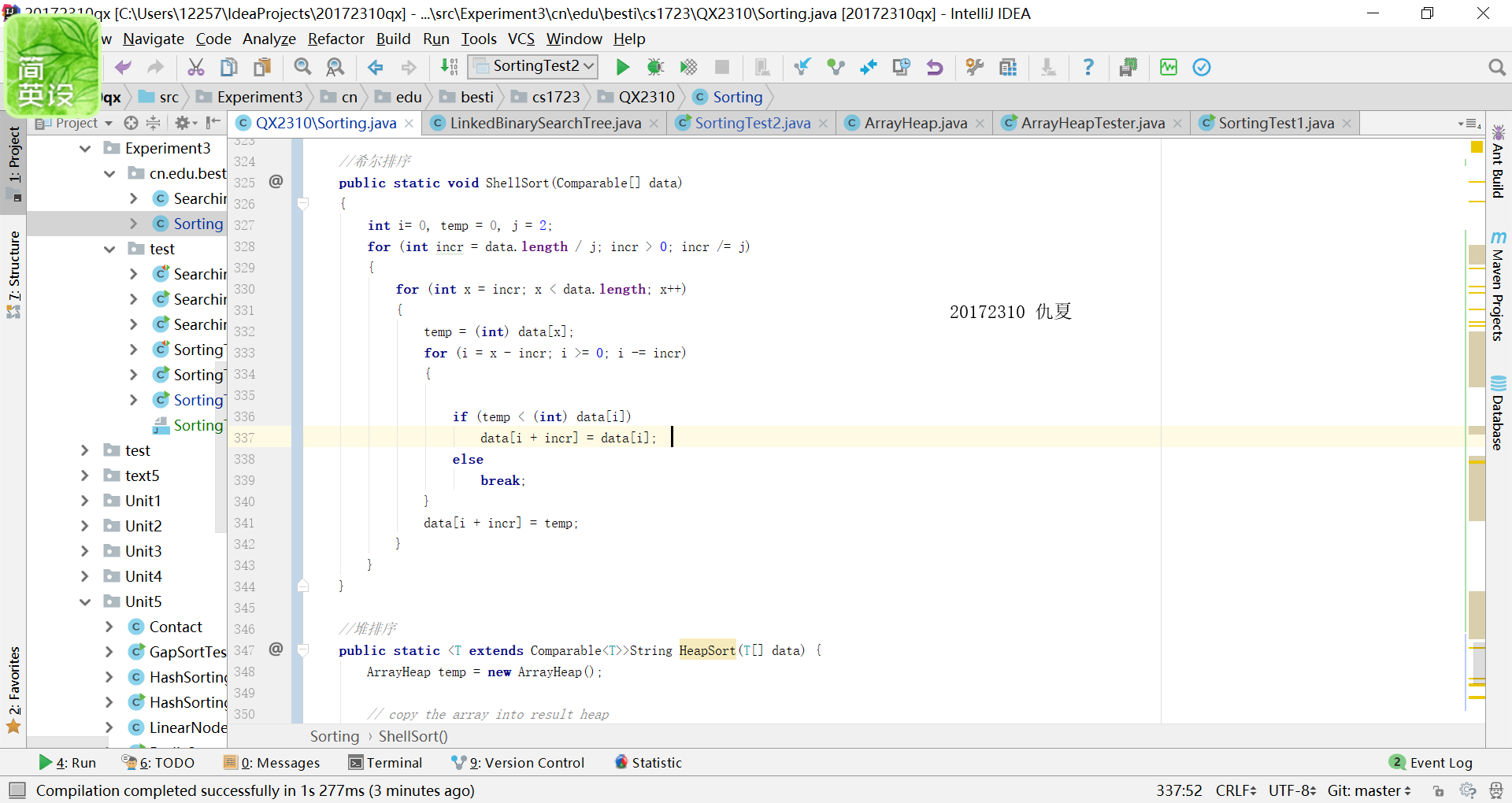
- 希尔排序
public static void ShellSort(Comparable[] data)
{
int i= 0, temp = 0, j = 2;
for (int incr = data.length / j; incr > 0; incr /= j)
{
for (int x = incr; x < data.length; x++)
{
temp = (int) data[x];
for (i = x - incr; i >= 0; i -= incr)
{
if (temp < (int) data[i])
data[i + incr] = data[i];
else
break;
}
data[i + incr] = temp;
}
}
}
- 堆排序,其中调用了之前学习堆时完成的ArrayHeap类
public static <T extends Comparable<T>>String HeapSort(T[] data) {
ArrayHeap temp = new ArrayHeap();
// copy the array into result heap
for (int i = 0; i < data.length; i++)
temp.addElement(data[i]);
// place the sorted elements back into the array
int count = 0;
String result = "";
while (!(temp.isEmpty()))
{
data[count] = (T) temp.removeMin();
result += data[count] + " ";
count++;
}
return result;
}
-
关于二叉树排序,我并没有重新写一个方法,而是直接在tester程序中直接实例化一个linkedBinarySearchTree类中,用找到最小元素来实现
-


实验三-查找与排序-5
实验要求内容
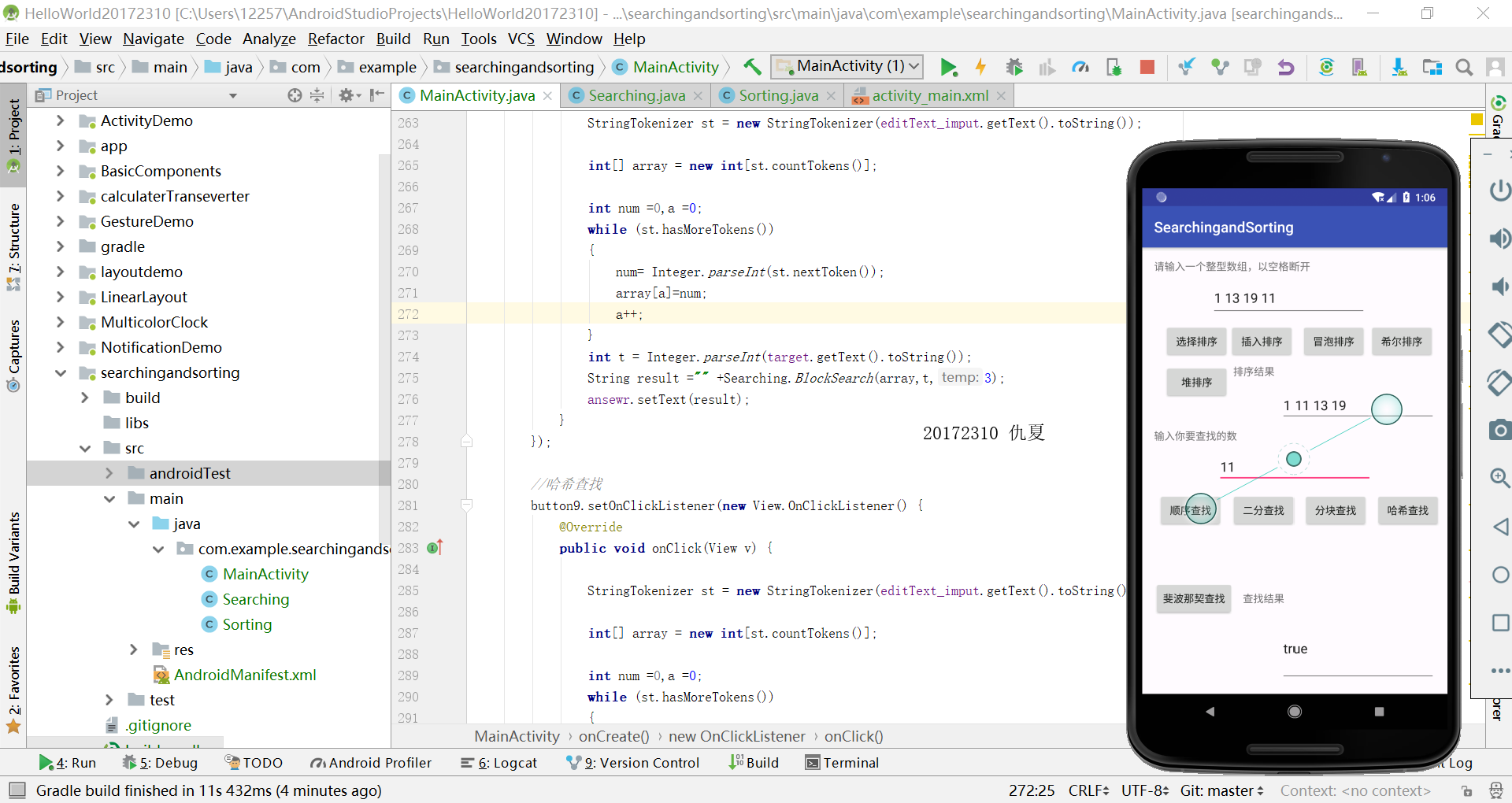
编写Android程序对各种查找与排序算法进行测试
提交运行结果截图
推送代码到码云
(加分3,加到实验中)
实验过程及结果
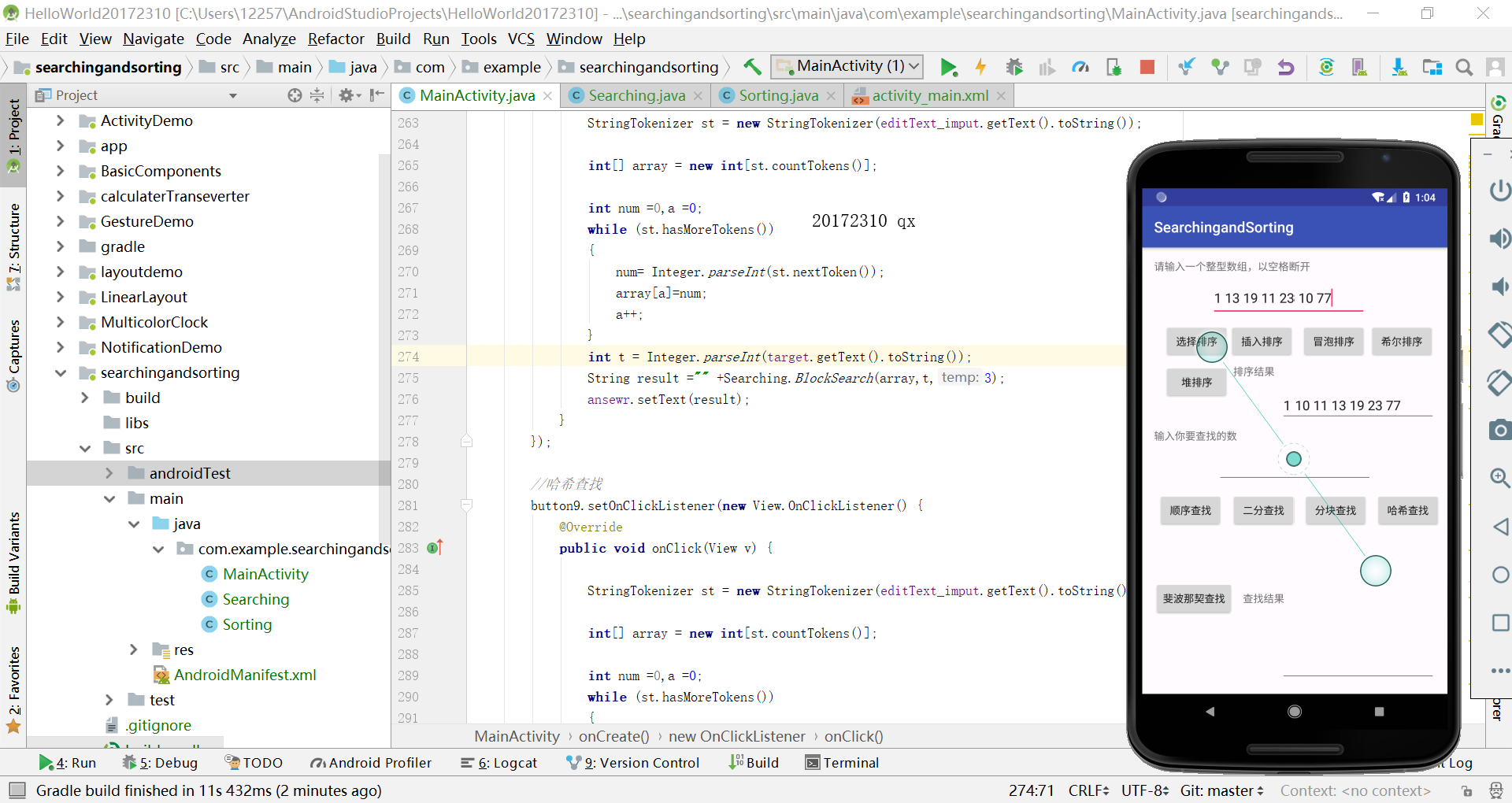
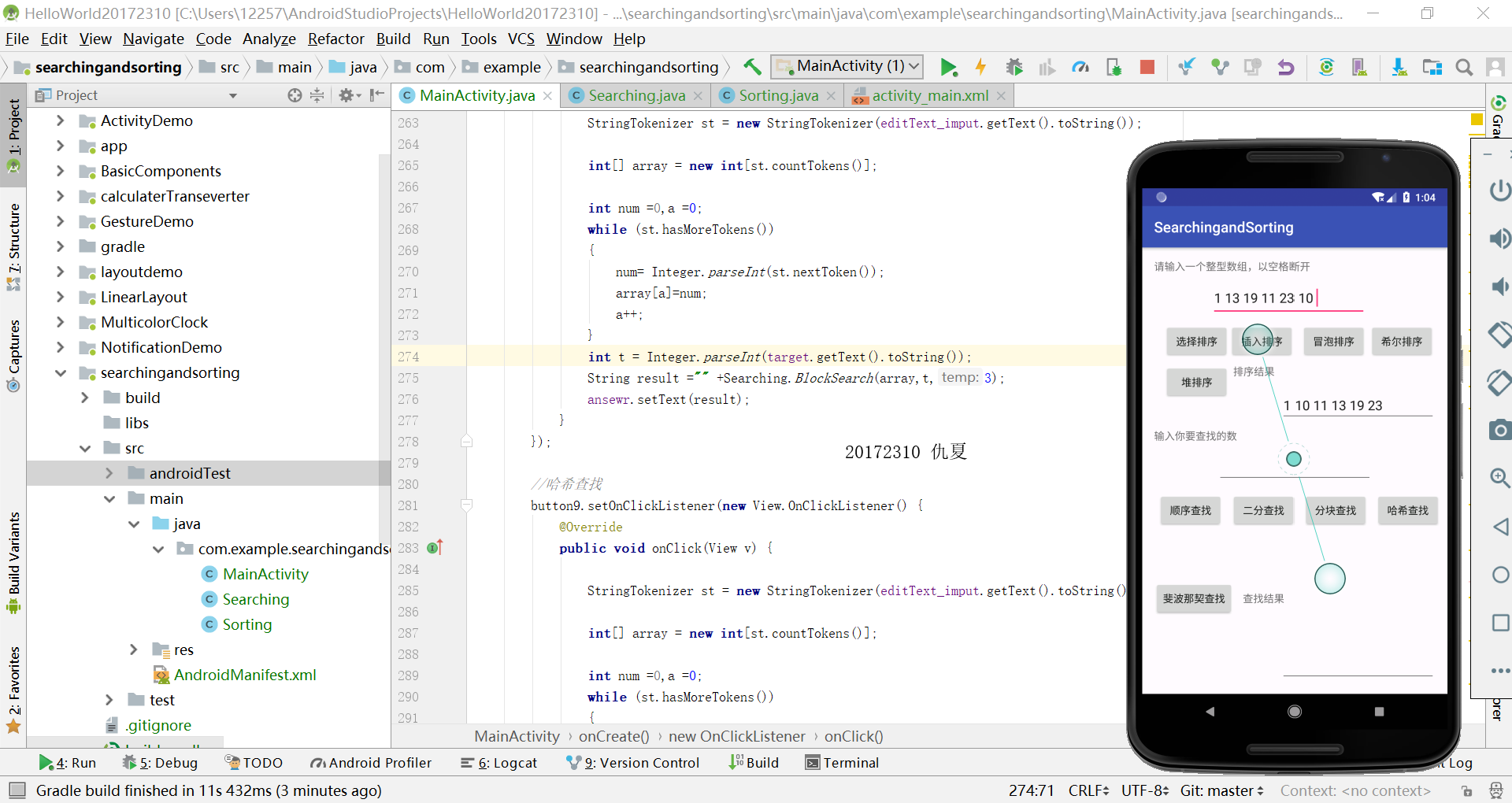
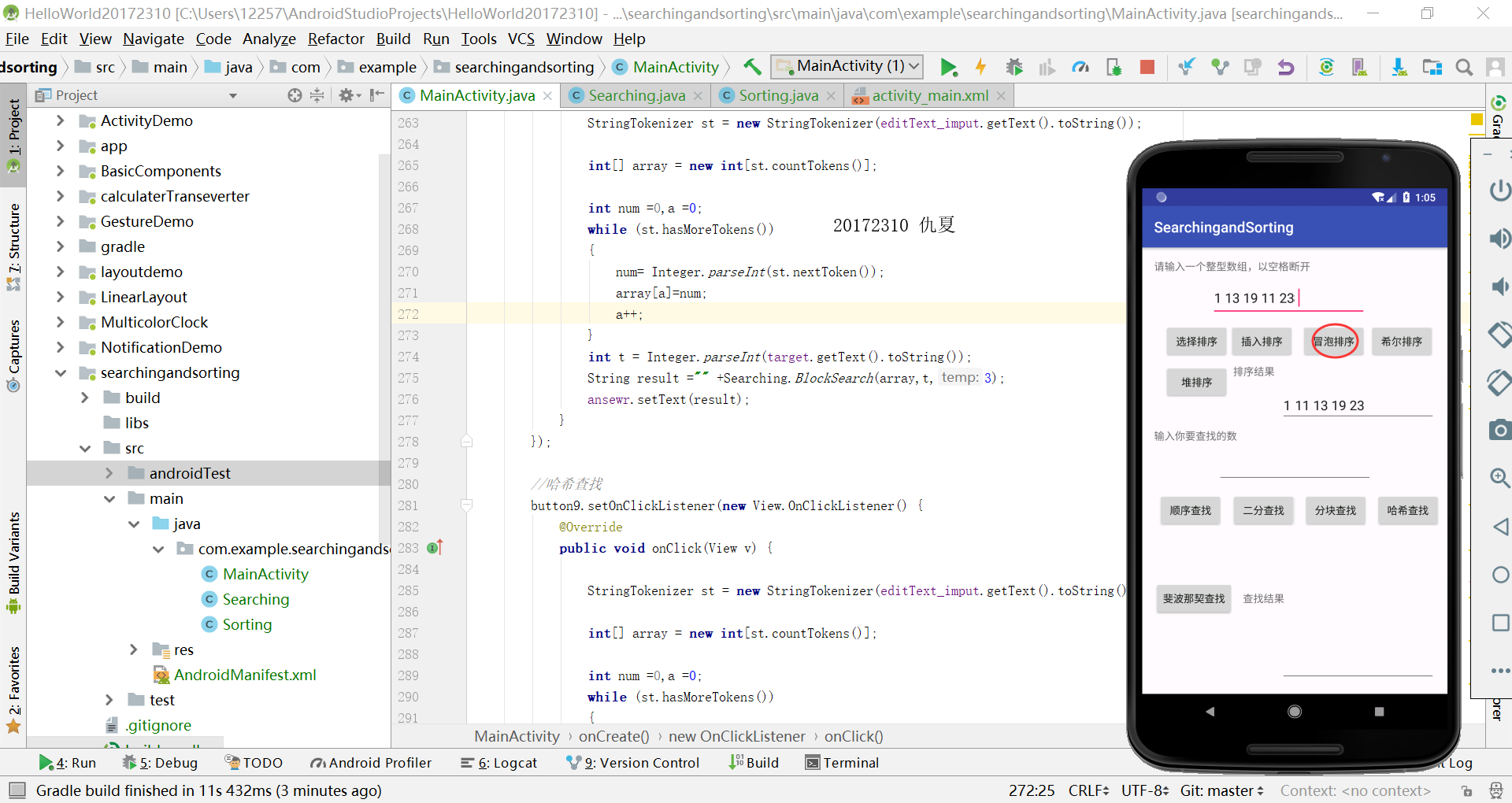
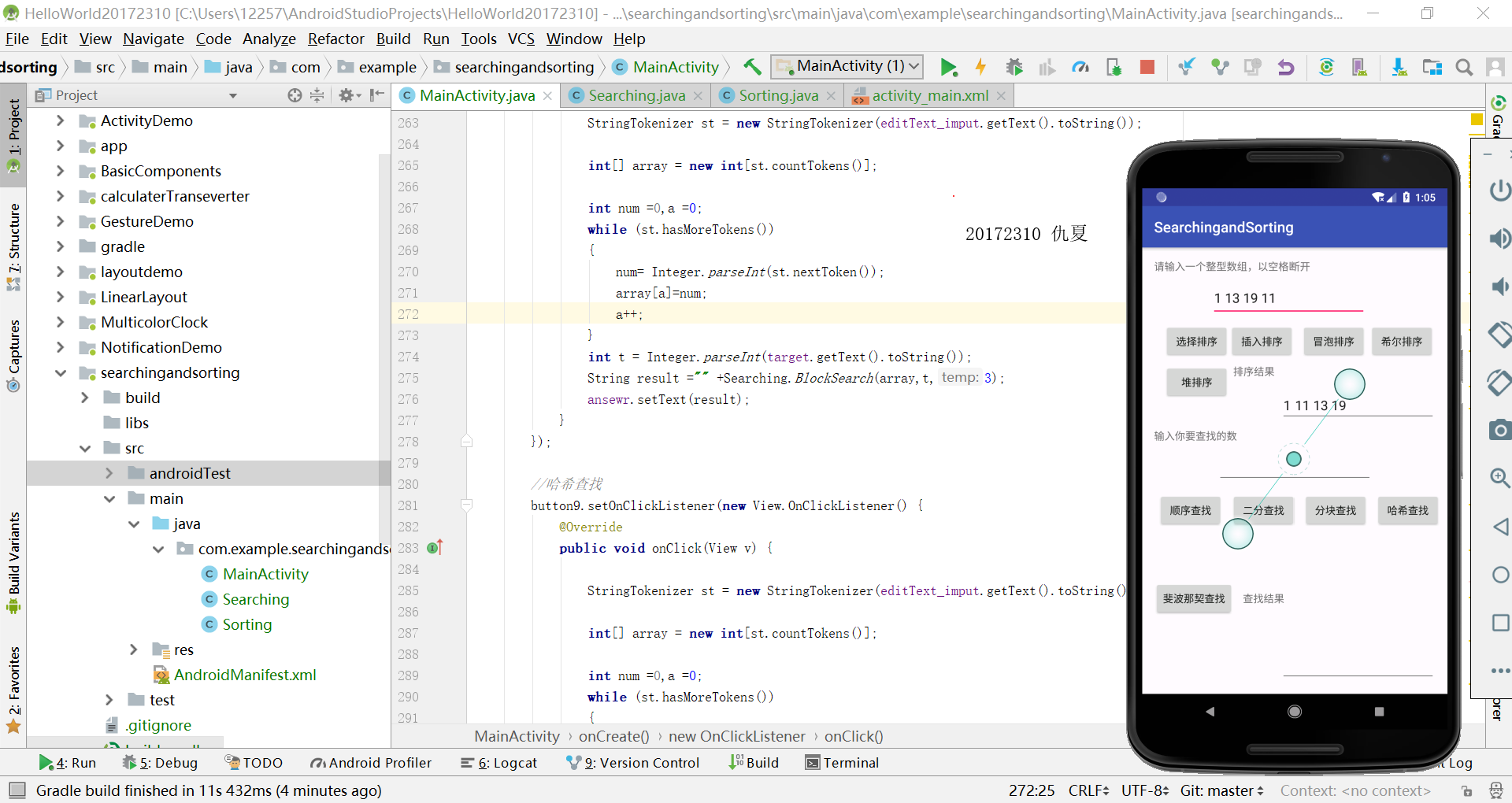
实验过程中遇到的问题及解决方案
-
问题1:对“斐波那契查找算法”难以理解。
-
问题1的解决方案:
在介绍斐波那契查找算法之前,我们先介绍一下很它紧密相连并且大家都熟知的一个概念——黄金分割。
黄金比例又称黄金分割,是指事物各部分间一定的数学比例关系,即将整体一分为二,较大部分与较小部分之比等于整体与较大部分之比,其比值约为1:0.618或1.618:1。
0.618被公认为最具有审美意义的比例数字,这个数值的作用不仅仅体现在诸如绘画、雕塑、音乐、建筑等艺术领域,而且在管理、工程设计等方面也有着不可忽视的作用。因此被称为黄金分割。
大家记不记得斐波那契数列:1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89…….(从第三个数开始,后边每一个数都是前两个数的和)。然后我们会发现,随着斐波那契数列的递增,前后两个数的比值会越来越接近0.618,利用这个特性,我们就可以将黄金比例运用到查找技术中。
我知道斐波那契数列的一些特性,但是我都难以理解怎么来运用它,它又有什么优势呢?
- 理解查找原理:“斐波那契查找与折半查找很相似。比较的key值与第mid=(low+high)/2位置的元素比较”
- 基本思想:
- 1.假设有待查找数组array[n]和斐波那契数组F[k],并且n满足n>=F[k]-1&&n < F[k+1]-1,则它的第一个拆分点middle=F[k]-1
- 2.开始表中记录的个数为某个斐波那契数小1,即m=F(k)-1(就是指表中的初始数在满足第一条的情况下,去斐波那契数列中找到这个m,并记录);
- 3.然后再将k值与第F(k-1)位置的记录;
- 进行比较(及mid=low+F(k-1)-1),比较结果也分为三种
- 相等,mid位置的元素即为所求
- 如果 >,low=mid+1,k-=2;(low=mid+1后待查找的元素在[mid+1,high]范围内,该范围内的元素个数为n-(F(k-1))= Fk - 1 - F(k-1)=Fk-F(k-1)-1=F(k-2)-1个,所以k-=2)
- 如果 <,high=mid-1,k-=1.(low=mid+1说明待查找的元素在[low,mid-1]范围内,k-=1 说明范围[low,mid-1]内的元素个数为F(k-1)-1个,所以k-=1)
- 基本思想:
// 假设有待查找数组array[n]和斐波那契数组F[k],并且n满足n>=F[k]-1&&n < F[k+1]-1,则它的第一个拆分点middle=F[k]-1
// 寻找k值,k值要求k值能使得F[k]-1恰好大于或等于n
int k = 0;
while (n > F[k] - 1)//计算n位于斐波那契数列的位置
k++;
int[] temp;//将数组data扩展到F[k]-1的长度
temp = new int[F[k] - 1];
for (int x = 0; x < data.length; x++) {
temp[x] = data[x];
}
for (int i = n; i < F[k] - 1; ++i)
temp[i] = data[n - 1];
while (low <= high) {
int mid = low + F[k - 1] - 1;
if (key < temp[mid]) {
high = mid - 1;
k -= 1;
} else if (key > temp[mid]) {
low = mid + 1;
k -= 2;
} else {
if (mid < n)
return mid; //若相等则说明mid即为查找到的位置
else
return n - 1; //若mid>=n则说明是扩展的数值,返回n-1
}
}
return -1;
-
斐波那契数列的优势:
- 复杂度分析:最坏情况下,时间复杂度为O(logn),且其期望复杂度也为O(logn),和对半查找法的时间复杂度相同;
- 且对半查找法我们从信息论的信息熵的相关知识能看出,对半查找法在执行步数上仍然比斐波那契二分查找法更少;
- 但是从代码算法来看,斐波那契二分查找法在核心算法上,只有赋值与减法运算,对半查找法却有除法运算。
关于二分法中,斐波那契查找算法对于对半查找法优势的理解
-
问题2:在写分块查找时,调用了之前写的顺序查找,然后往定义的最大元素组成的数组中添加元素是一直出现错误。之后发现自己定义的是
T[] maxlist,然后调用方法将元素变为Integer
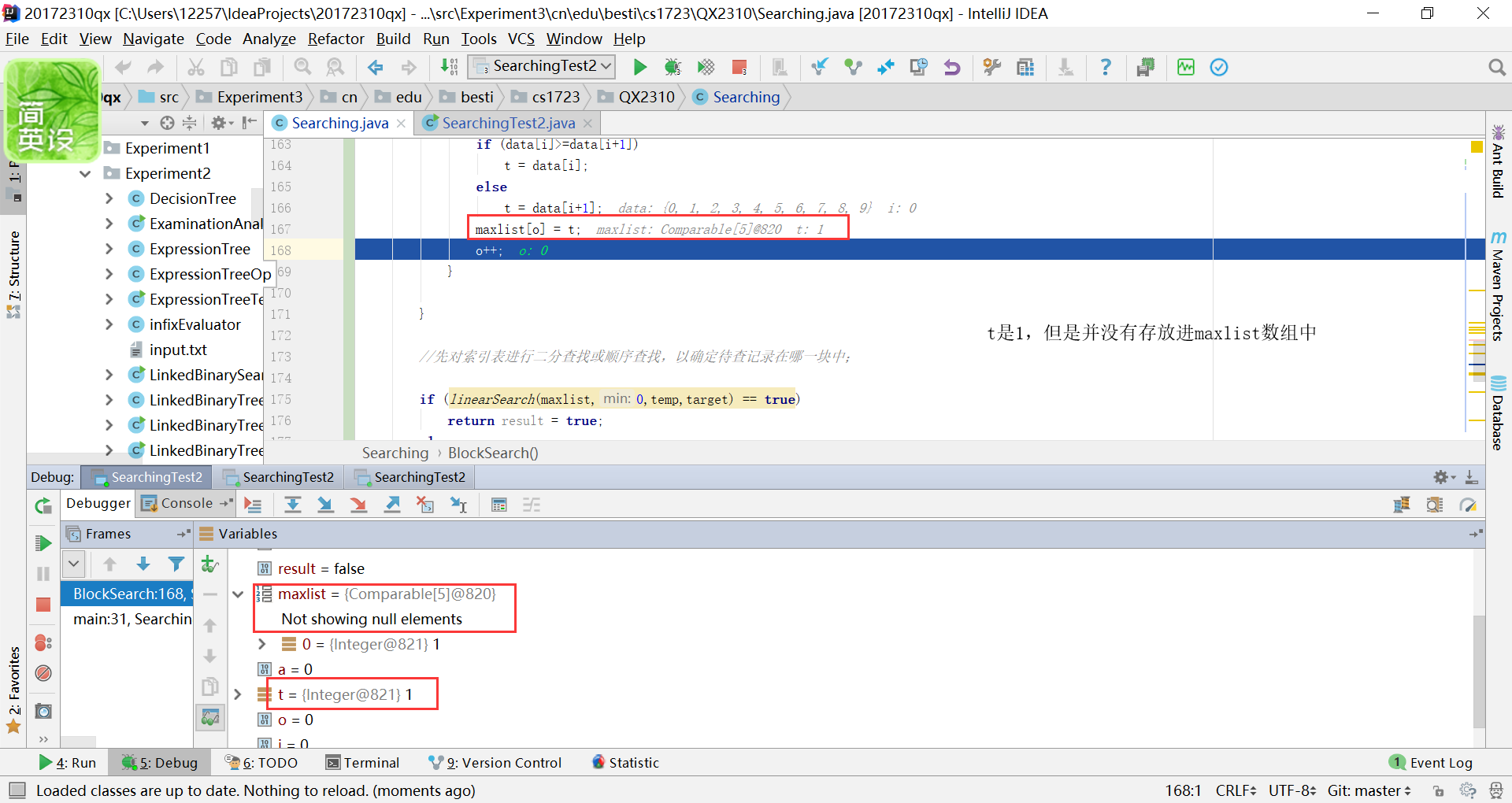
但是还是出现了
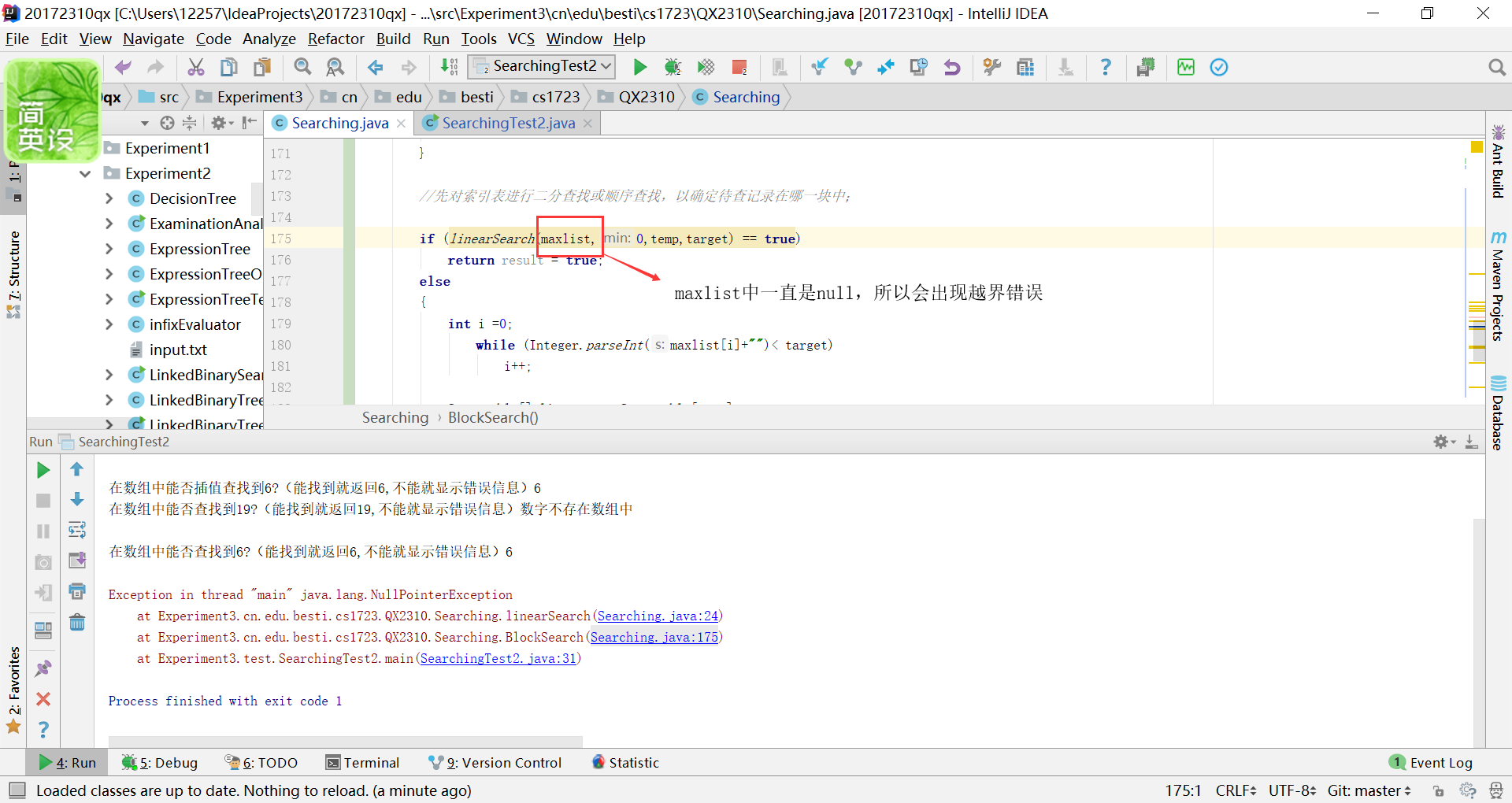
发现不会报错了,但是数组中却存储不进元素,一直是null。
- 问题2的解决方案:最后又只好重写一个顺序查找方法
public static <T> boolean linearSearch2(int[] data, int min, int max, int target)
{
int index = min;
boolean found = false;
while (!found && index <= max)
{
if ( data[index]==target)
found = true;
index++;
}
return found;
}
感想或其他
这篇博客是实验完成了一周之后才开始写的,但对这次实验我的印象还是很深刻的,主要是自己往常写代码的时候遇到的问题都向别人或多或少寻求了帮助,而这次写分块查找的算法时,我是按照 [Data Structure & Algorithm] 七大查找算法这篇博客里的思路写的,和别人的思路有些不一样。这是这个学期的最后一个实验了,(o)/~,不过接下来的小组作业挺难的。
