20172310《程序设计与数据结构》(下)实验二:二叉树实验报告
20172310《程序设计与数据结构》(下)实验二:二叉树实验报告
报告封面
- 课程:《软件结构与数据结构》
- 班级: 1723
- 姓名: 仇夏
- 学号:20172310
- 实验教师:王志强老师
- 实验日期:2018年11月7日-2018年11月日
- 必修选修: 必修
实验二-1-实现二叉树
实验要求内容
参考教材p212,完成链树LinkedBinaryTree的实现(getRight,contains,toString,preorder,postorder)
用JUnit或自己编写驱动类对自己实现的LinkedBinaryTree进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息
课下把代码推送到代码托管平台
实验过程及结果
链树LinkedBinaryTree其实课本上已经有基本的框架代码了,要自己编写的就是getRight,contains,toString,preorder,postorder这些代码。
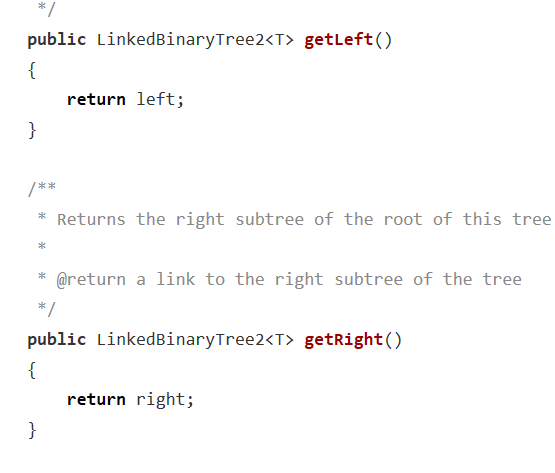
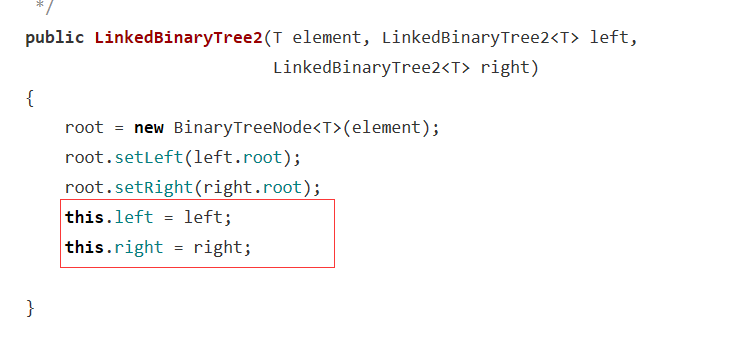
getRight和getLeft编写的时候其实时遇到了一些问题,最后换了上述的写法。

实验二树-2-中序先序序列构造二叉树
实验要求内容
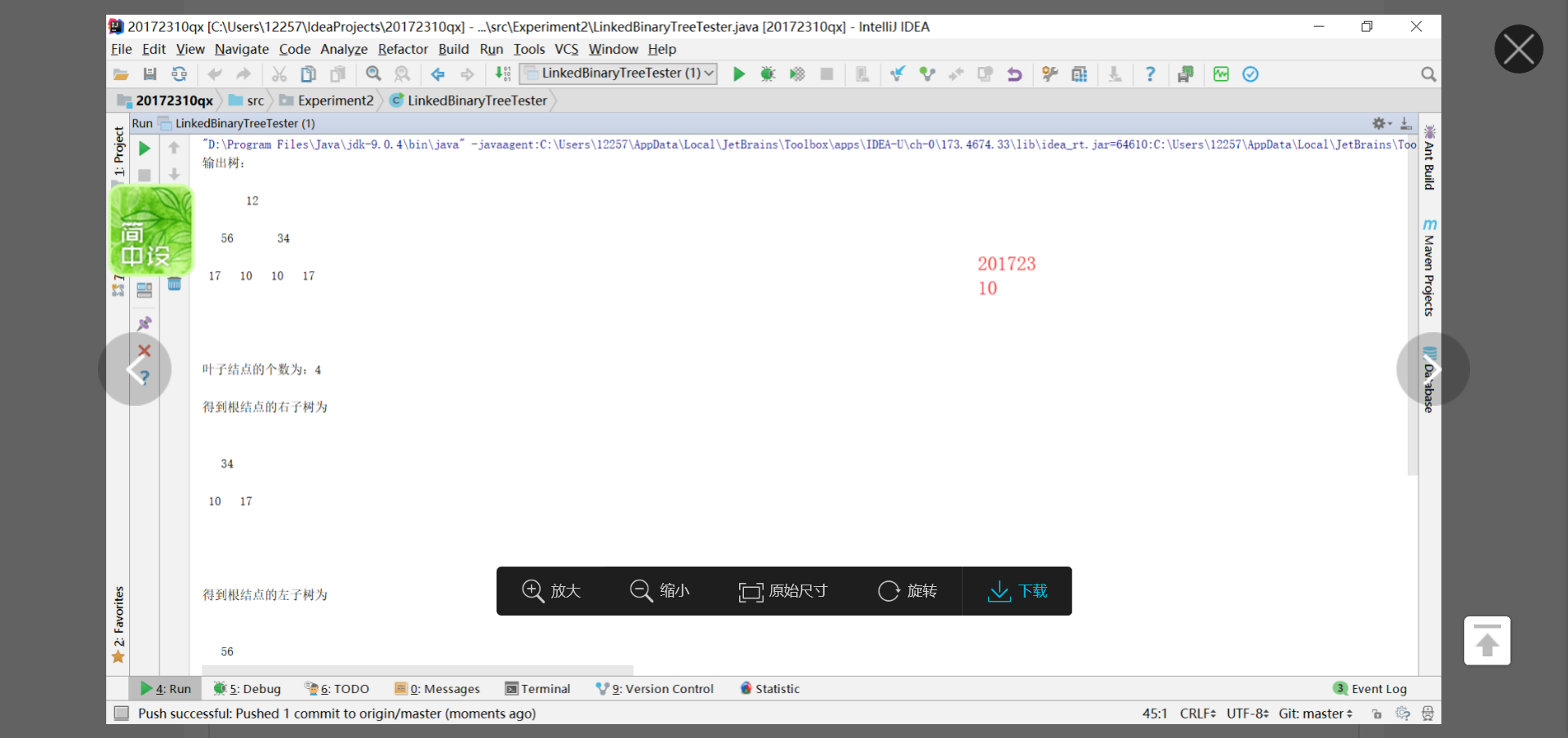
基于LinkedBinaryTree,实现基于(中序,先序)序列构造唯一一棵二㕚树的功能,比如给出中序HDIBEMJNAFCKGL和后序ABDHIEJMNCFGKL,构造出附图中的树
用JUnit或自己编写驱动类对自己实现的功能进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息
课下把代码推送到代码托管平台
实验过程及结果
(我现在觉得自己的脑子快要气死了,现在是11月19号,我在写实验三的博客时,以实验二的博客作为模板,结果直接在上面对实验1和2进行了更改,还没有发现什么不对,直接保存了,而且还没有备份。我的人生,一片灰暗,啊啊啊啊啊ε=ε=ε=(#>д<)ノ,只好重写了一遍,但是当时的有些图片已经找不到了了,所以接下来的图是蓝墨云中找回来的)。
- 先来看中序和后序遍历构造出一棵树的思路。

- 结果:

实验二 树-3-决策树
实验要求内容
自己设计并实现一颗决策树
提交测试代码运行截图,要全屏,包含自己的学号信息
课下把代码推送到代码托管平台
实验过程及结果
- 实验三是仿照背部疼痛诊断器来写的,只要看懂了背部疼痛诊断器就很好写

实验二 树-4-表达式树
实验要求内容
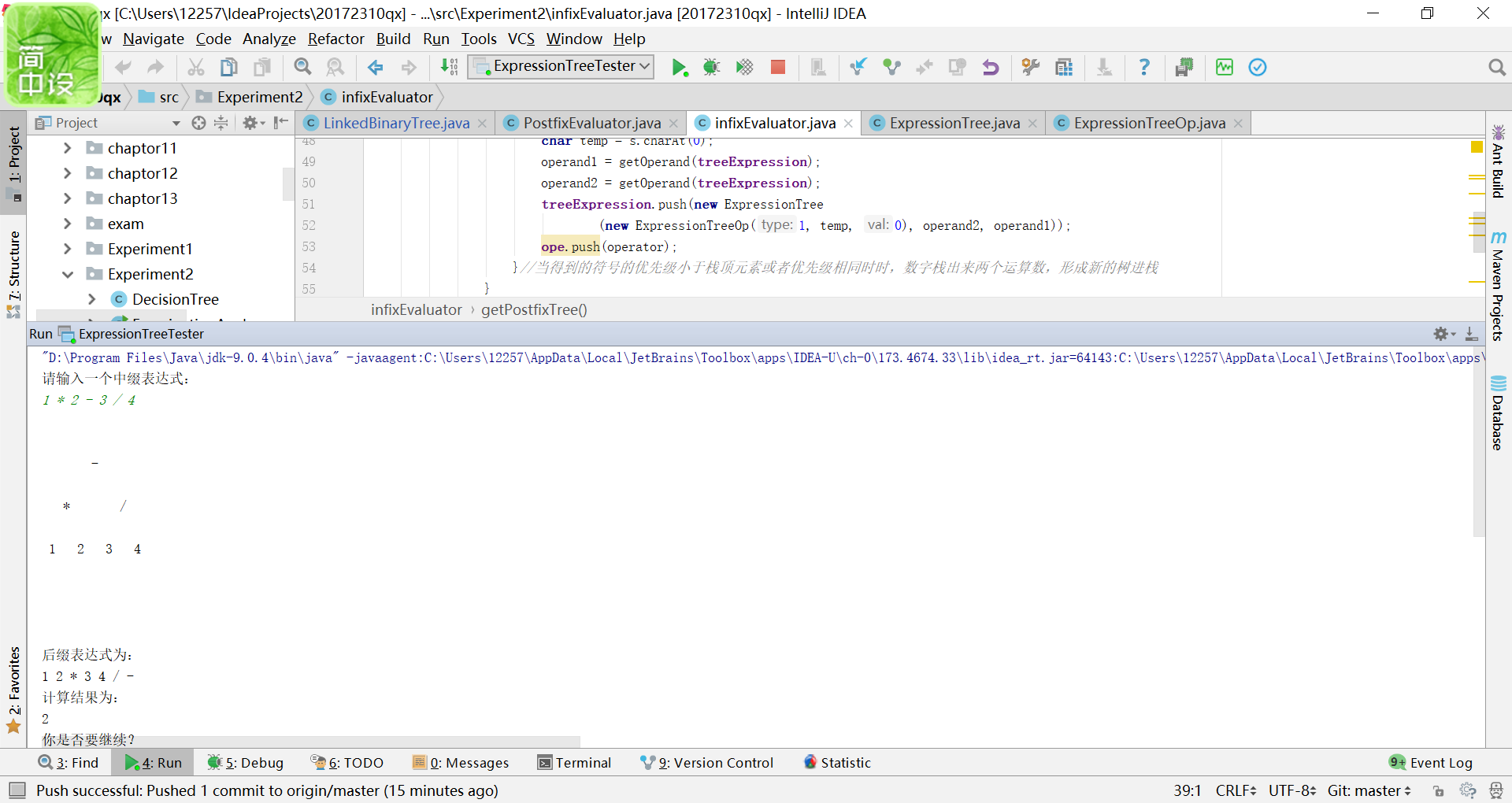
输入中缀表达式,使用树将中缀表达式转换为后缀表达式,并输出后缀表达式和计算结果(如果没有用树,则为0分)
提交测试代码运行截图,要全屏,包含自己的学号信息
课下把代码推送到代码托管平台
实验过程及结果
在课本第十章编写了一个表达式树的类,其中的思路就是操作数一个栈,操作符一个栈来构造一棵二叉树。这个实验的思路就是一样利用表达式树的原理,
将输入的中缀表达式读取构建一棵二叉树,想要变成后缀表达式,其实就是将这颗二叉树后序遍历输出。
关键代码为:
ExpressionTree operand1,operand2;
char operator;
String tempToken;
Scanner parser = new Scanner(expression);
while(parser.hasNext()){
tempToken = parser.next();
operator=tempToken.charAt(0);
if ((operator == '+') || (operator == '-') || (operator=='*') ||
(operator == '/')){
if (ope.empty())
ope.push(tempToken);//当储存符号的栈为空时,直接进栈
else{
String a =ope.peek()+"";
if (((a.equals("+"))||(a.equals("-")))&&((operator=='*')||(operator=='/')))
ope.push(tempToken);//当得到的符号的优先级大于栈顶元素时,直接进栈
else {
String s = String.valueOf(ope.pop());
char temp = s.charAt(0);
operand1 = getOperand(treeExpression);
operand2 = getOperand(treeExpression);
treeExpression.push(new ExpressionTree
(new ExpressionTreeOp(1, temp, 0), operand2, operand1));
ope.push(operator);
}//当得到的符号的优先级小于栈顶元素或者优先级相同时时,数字栈出来两个运算数,形成新的树进栈
}
}
else
treeExpression.push(new ExpressionTree(new ExpressionTreeOp
(2,' ',Integer.parseInt(tempToken)), null, null));
}
while(!ope.empty()){
String a = String.valueOf(ope.pop());
operator = a.charAt(0);
operand1 = getOperand(treeExpression);
operand2 = getOperand(treeExpression);
treeExpression.push(new ExpressionTree
(new ExpressionTreeOp(1, operator, 0), operand2, operand1));
}
return treeExpression.peek();
}
public String getTree()
{
return (treeExpression.peek()).printTree();
}
public int getResult(){
return treeExpression.peek().evaluateTree();
}
public String PostOrder(){
Iterator iterator = treeExpression.peek().iteratorPostOrder();
String result="";
for (;iterator.hasNext();)
result +=iterator.next()+" ";
return result;
}
实验二 树-5-二叉查找树
实验要求内容
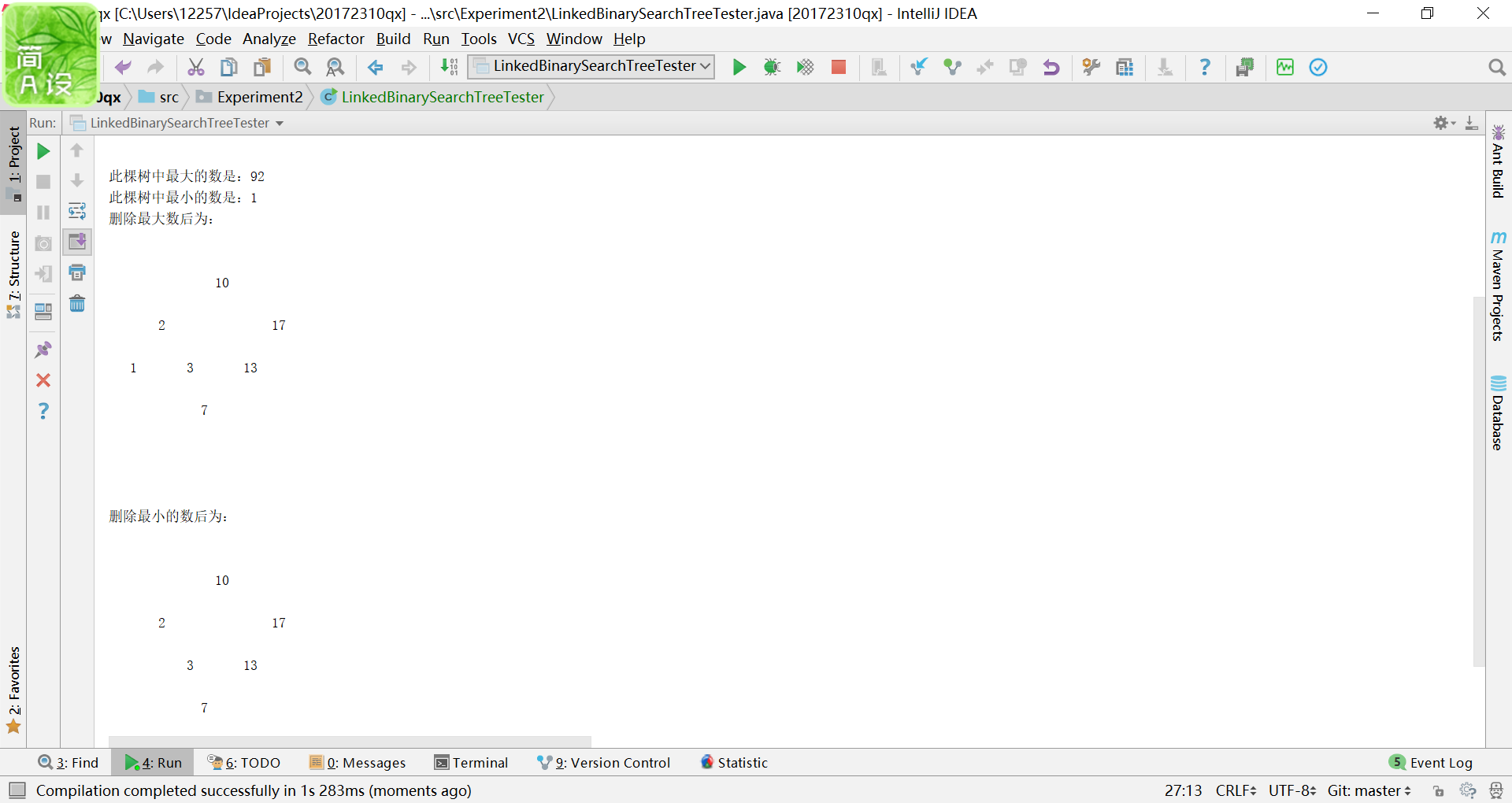
完成PP11.3,对于二叉查找树的链表实现,请实现removeMax、findMin和findMax等操作。
提交测试代码运行截图,要全屏,包含自己的学号信息
课下把代码推送到代码托管平台
实验过程及结果
public T removeMin() throws EmptyCollectionException
{
T result = null;
if (isEmpty())
throw new EmptyCollectionException("LinkedBinarySearchTree");
else
{
//如果根元素没有左孩子,根就是最小的元素,根元素变为原根元素的右孩子
if (root.left == null)
{
result = root.element;
root = root.right;
}
//如果根有左孩子
else
{
BinaryTreeNode<T> parent = root;
BinaryTreeNode<T> current = root.left;
while (current.left != null)
{
parent = current;
current = current.left;
}
result = current.element;
parent.left = current.right;
}
modCount--;
}
return result;
}
public T removeMax() throws EmptyCollectionException
{
T result = null;
if (isEmpty())
throw new EmptyCollectionException("LinkedBinarySearchTree");
else
{
//如果没有右孩子
if (root.right == null)
{
result = root.element;
root = root.left;
}
//如果有右孩子
else
{
BinaryTreeNode<T> parent = root;
BinaryTreeNode<T> current = root.right;
while (current.right != null)
{
parent = current;
current = current.right;
}
result = current.element;
parent.right = current.left;
}
modCount--;
}
return result;
}
public T findMin() throws EmptyCollectionException
{
T result = null;
if (isEmpty())
throw new EmptyCollectionException("LinkedBinarySearchTree");
else
{
if (root.left == null)
{
result = root.element;
}
else
{
BinaryTreeNode<T> parent = root;
BinaryTreeNode<T> current = root.left;
while (current.left != null)
{
parent = current;
current = current.left;
}
result = current.element;
}
}
return result;
}
public T findMax() throws EmptyCollectionException
{
T result = null;
if (isEmpty())
throw new EmptyCollectionException("LinkedBinarySearchTree");
else {
if (root.right == null)
{
result = root.element;
}
else
{
BinaryTreeNode<T> parent = root;
BinaryTreeNode<T> current = root.right;
while (current.right != null)
{
parent = current;
current = current.right;
}
result = current.element;
}
}
return result;
}
实验二 树-6-红黑树分析
实验要求内容
参考http://www.cnblogs.com/rocedu/p/7483915.html对Java中的红黑树(TreeMap,HashMap)进行源码分析,并在实验报告中体现分析结果。
(C:\Program Files\Java\jdk-11.0.1\lib\src\java.base\java\util)
实验过程及结果
-
学习的资料:Java Collections API源码分析
-
Java中红黑树的分析:
-
TreeMap 是什么?
TreeMap 是一个有序的key-value集合,它是通过红黑树实现的。
TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。
TreeMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。
TreeMap 实现了Cloneable接口,意味着它能被克隆。
TreeMap 实现了java.io.Serializable接口,意味着它支持序列化。
TreeMap基于红黑树(Red-Black tree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。
另外,TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fastl的。
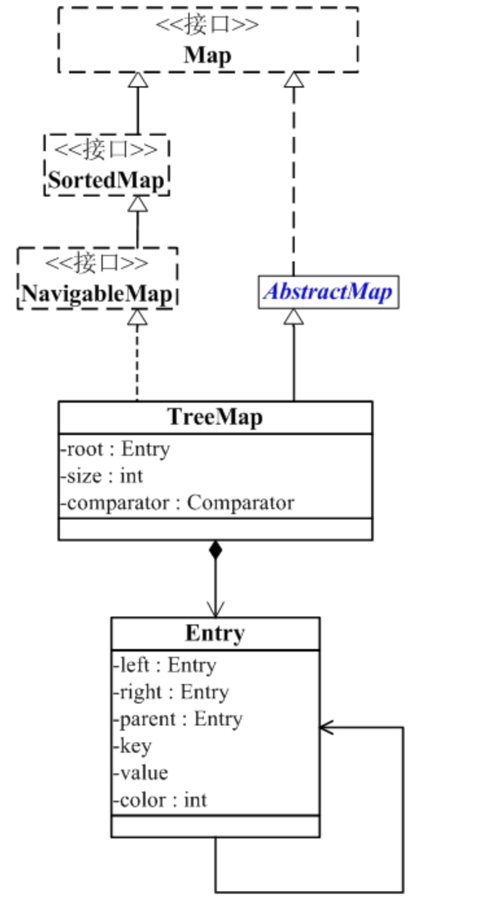
这是大多数参考资料上给出的关于TreeMap的简介,但是里面还涉及到了很多的其他的有关概念,所以不太好理解,我也翻看了一些资料,在上面点击就可以查看。关于代码的理解可以看一下Java 集合系列12之 TreeMap详细介绍(源码解析)和使用示例
- Hashmap是什么?Java 集合系列10之 HashMap详细介绍(源码解析)和使用示例
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。
HashMap 的实例有两个参数影响其性能:“初始容量” 和 “加载因子”。容量 是哈希表中桶的数量,初始容量 只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
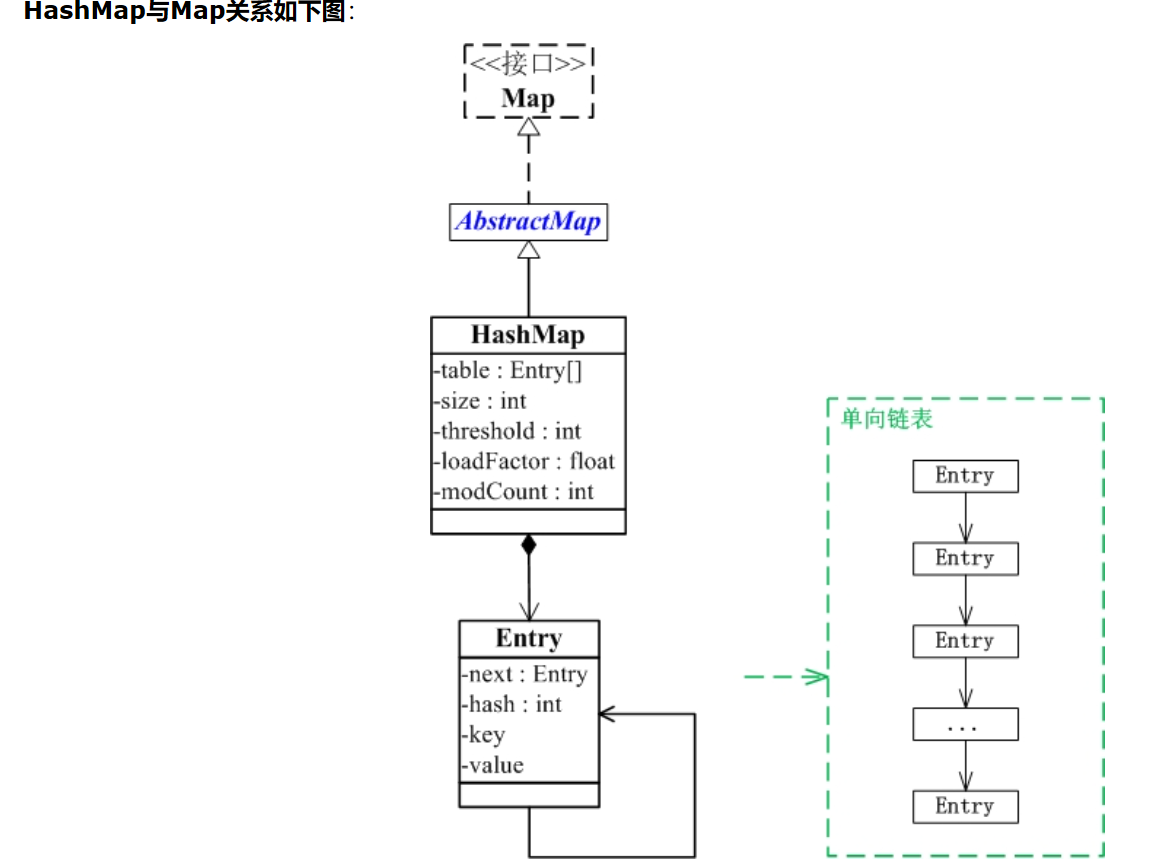

- HashMap和TreeMap最本质的区别:
HashMap通过hashcode方法对其内容进行快速查找,而 TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用TreeMap,因为HashMap中元素的排列顺序是不固定的。
实验过程中遇到的问题和解决过程
-
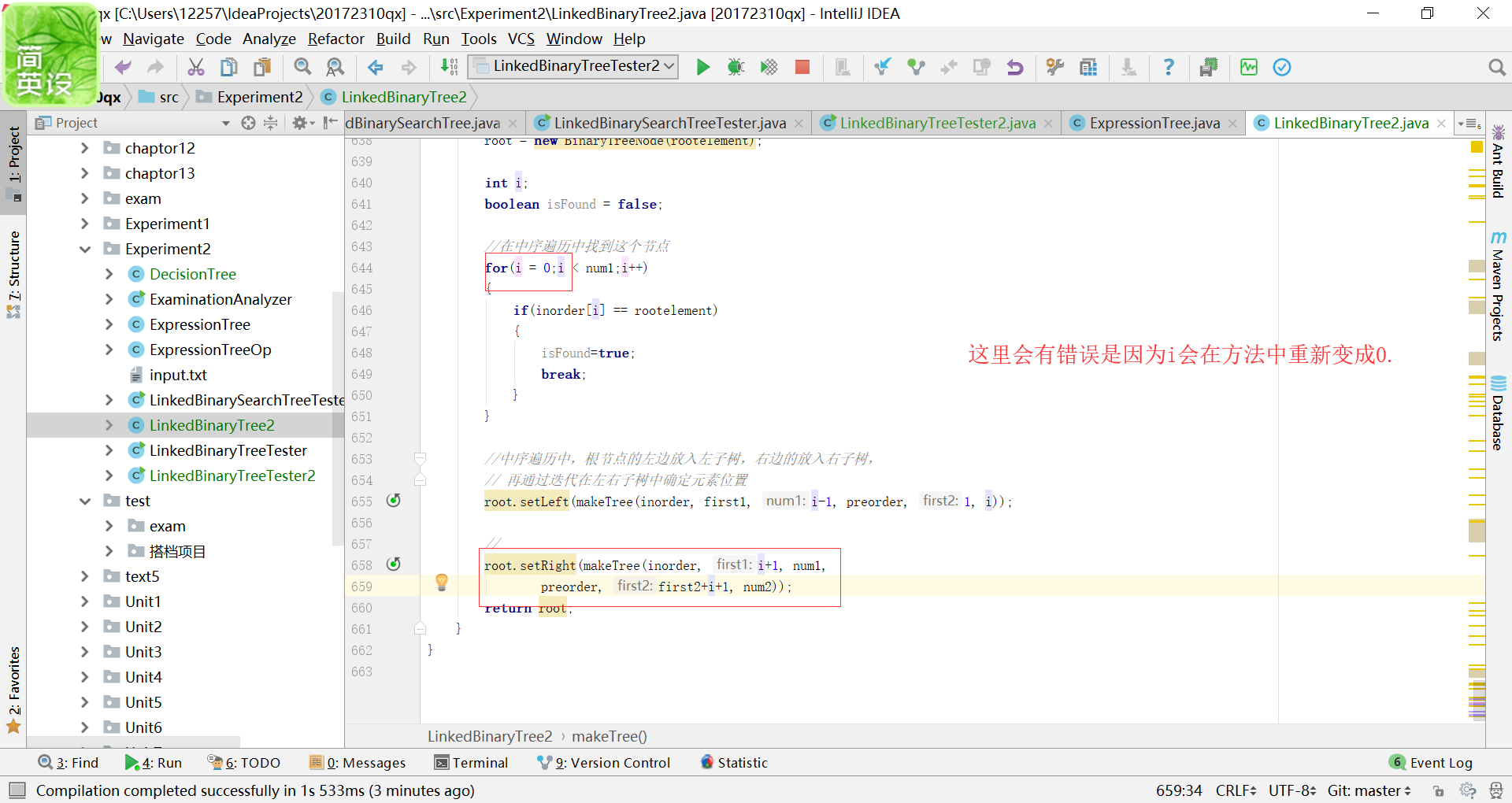
问题一:在实验二—2中,想要用迭代的方式继续处理左右子树,但是估计是参数写错了,于是出现了这样的错误。
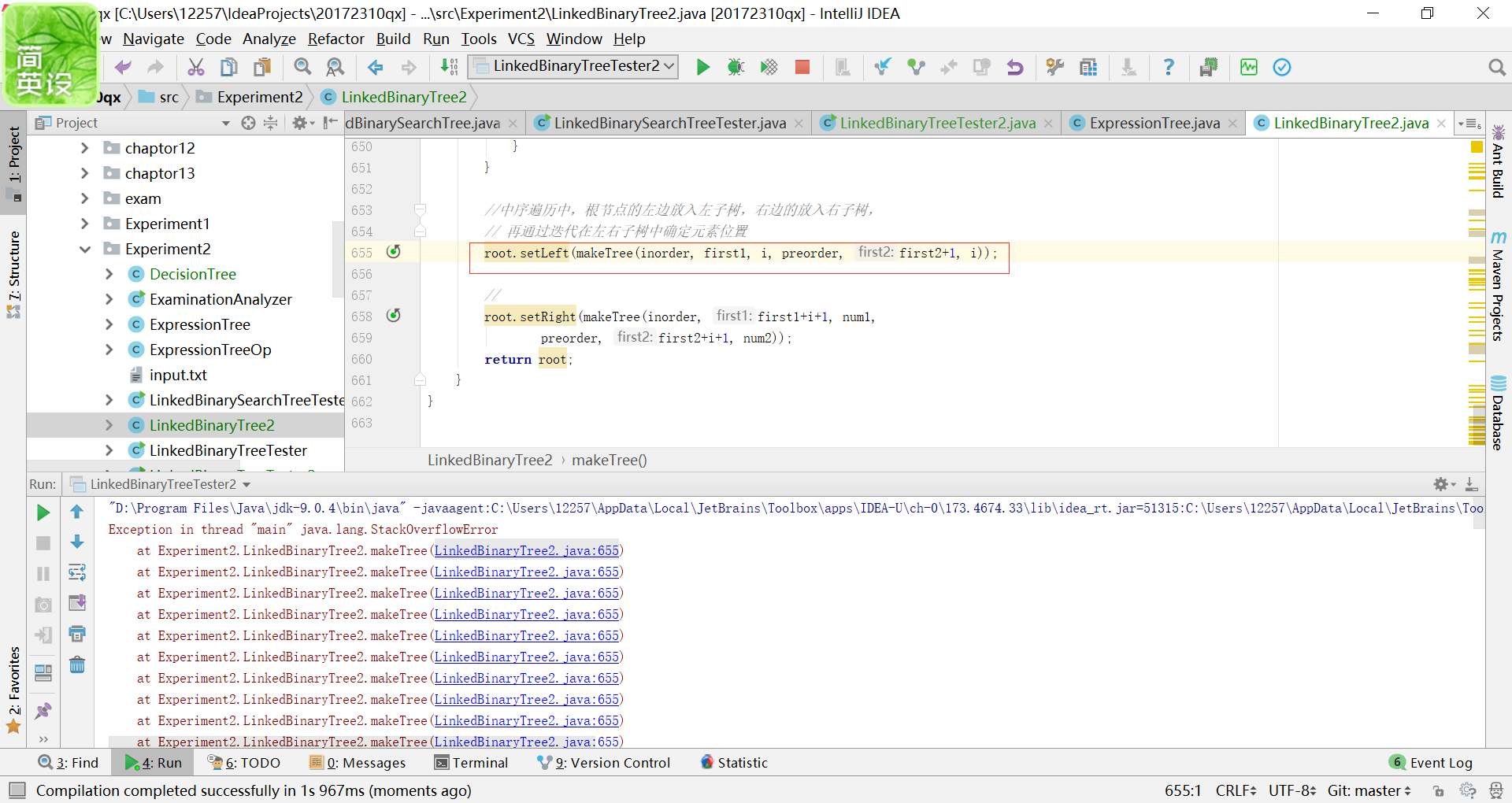
-
问题一的解决方案:形参的编写一定要仔细,不然就很可能得不到正确的结果。肉眼难以找出自己的思路错误,于是进行了代码调试。
-
问题二:在实验二 树-4-表达式树中写的方法最开始是对于“/”操作符的放入是有问题的,就像:
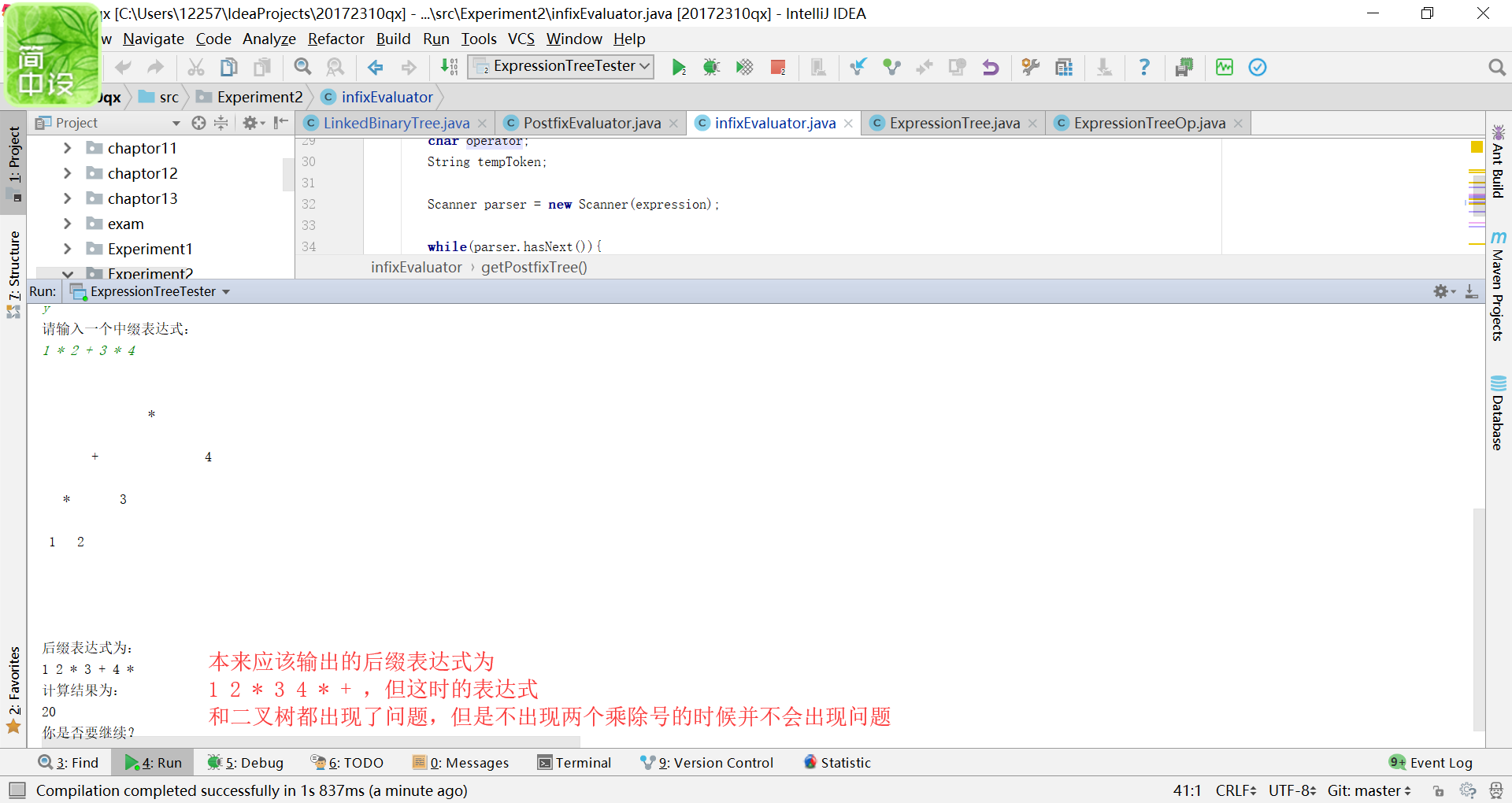
所以判断是下面这段代码放入操作符的时候出现了问题。
if (((ope.peek().equals("+"))||(ope.peek().equals("-")))&&((operator=='*')||(operator=='/')))
ope.push(tempToken);
于是进行调试
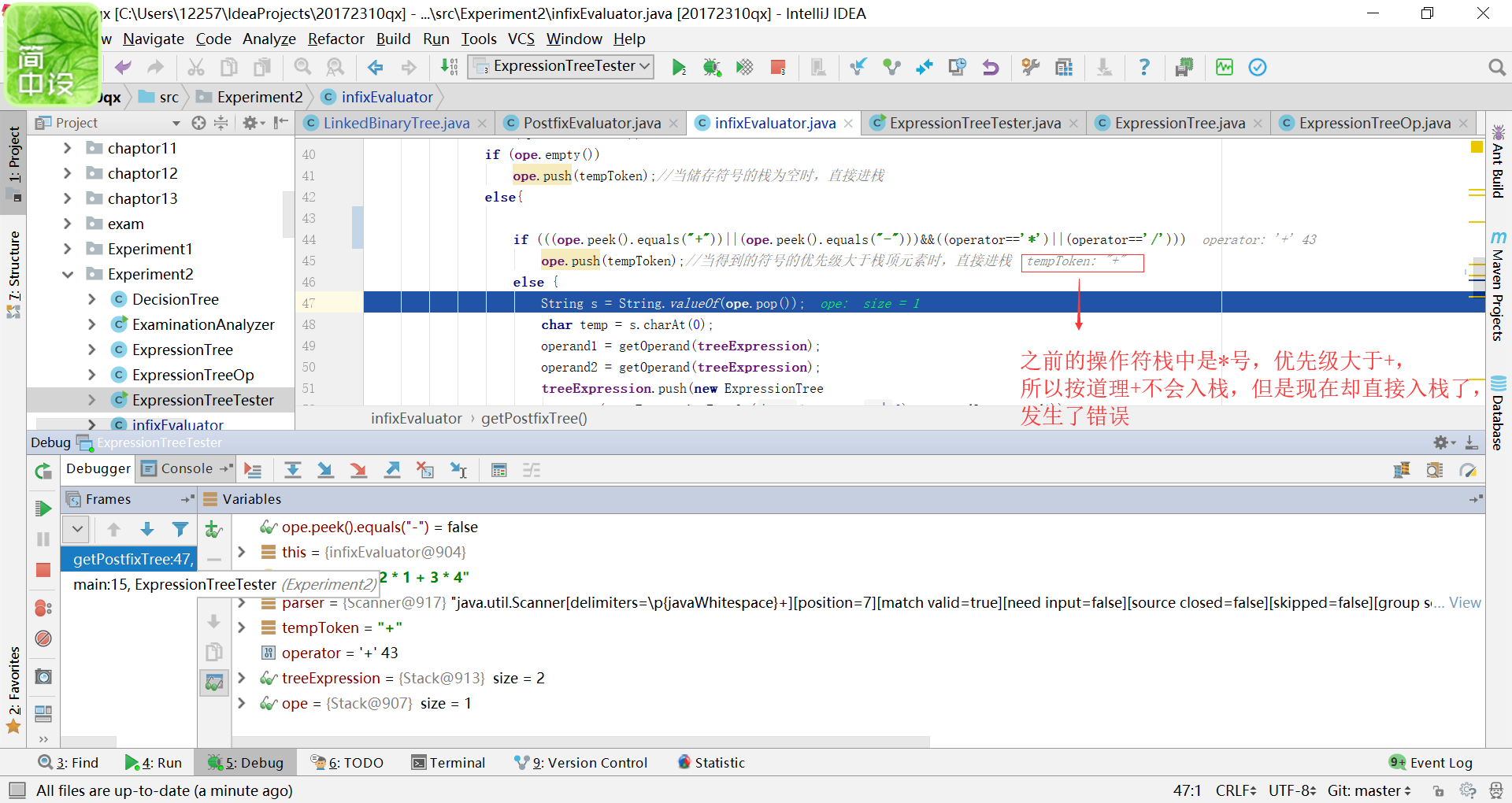
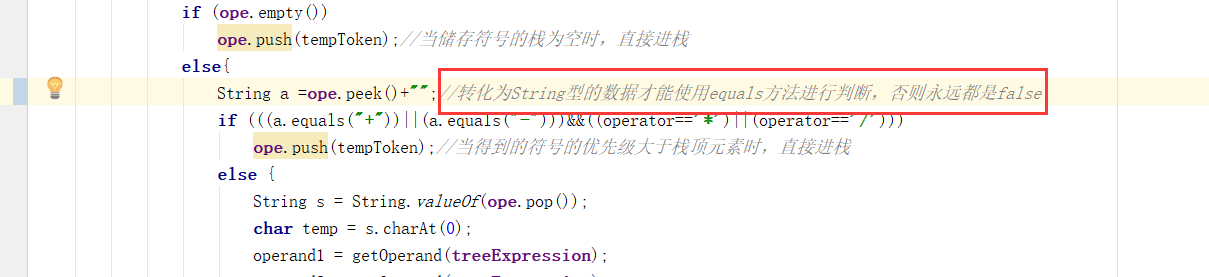
- 问题二的解决方法:其实这个问题我之前一直都没有想明白,多亏了我机智聪明的队友,他又对代码进行了思考和调试,在他的指导下,我才发现错误的地方是
其他(感悟、思考等)
这次的实验有简单的也有困难的,发现自己有时候的思路真的挺奇葩的。对于第六个那种纯看文字学习的实验我有些转不动脑子,平常自学其实都用的是纸质课本,可以在上面勾勾画画,但看电脑我的思维就很容易跑偏,所以看了好几遍第六个实验,看来以后还是要多克服克服这种思维不集中的问题,提高一下学习的效率。还有要感谢一下队友的帮助,不然问题都还解决不了。

