20172310 2017-2018《程序设计与数据结构》(下)第五周学习总结
20172310 2017-2018《程序设计与数据结构》(下)第五周学习总结
教材学习内容总结
第九章_排序与查找
学习几种排序算法,并讨论这些算法的复杂度
9.1查找(线性查找与二分查找算法)
-
查找(searching) 是在某个项目组中寻找某一指定目标元素, 或者确定该组中并不存在该目标元素的一个过程。对其进行查找的项目组有时
也称为查找池( search pool)。 -
我们的目标就是尽可能高效地完成查找。从算法分析的角度而言,高效的查找会使该过程所做的比较操作次数最小化。同时该查找池中项目的数目定义了该问题的大小。
-
查找某一对象,必须能够将其跟另一个对象进行比较。我们对这些算法的实现就是对某个Comparable对象的数组进行查找。
如:public class Searching<T extends Comparable<T>>这个泛型声明的实际结果就是以用任何实现Comparable接口的类来实例化Searching类。
以Comparable接口的方式定义的Searching要求我们在使用查找或排序方法时必须实例化于是引出了泛型静态方法。
- 静态方法(static method),又称为类方法(class mehod),可以通过类名来激话。通过使用static 修饰符就可以把它声明为静态的。
例如,Math类的所有方法都是静志的可以如下通过Math类来调用sqrt方法:
System. out.printinl("squace root of 27: ”+ Math.sqrt(27));
- 静态方法不是作用于具体的对象中,因此不能引用实例变量(实例变量只存在类的一个实例中)。如果某个静态方法试图使用一个非静态的变量,编译器将发出一个错误。但是,静态方法可以引用静态变量,因为静态变量的存在与具体的对象无关。
- 泛型方法:与创建泛型类相似,我们也可以创建泛型方法。即,不是创建一个引用泛 型参数的类,而是创建一个引用泛型的方法。泛型参数只应用于该方法。
要创建个泛型方法, 只需在方法头的返回类型前插入一个泛型声明即可:
public static<T extends Comparable< T> > boolean
lineatsearch (T[] data, int min, int max, T target)
泛型声明必须位于返回类型之前,这样泛型才可作为返回类型的部分。
- 不一定非要指定用于替代泛型的数据类型。编译器可以从所提供的参数中推导出该数据类型。
- 线性查找法
如果该查找池组织成一个某类型的列表,那么完成该查找的一个简单方式就是从该列表头开始依次比较每一个值, 直至找到该目标元素。最后,我们要么找到该目标,要么到达列表尾并得出该组中不存在该目标的结论。这种方式之所以称为线性查找(linear search),是因为它是从一端开始并以线性方式搜索该查找池的
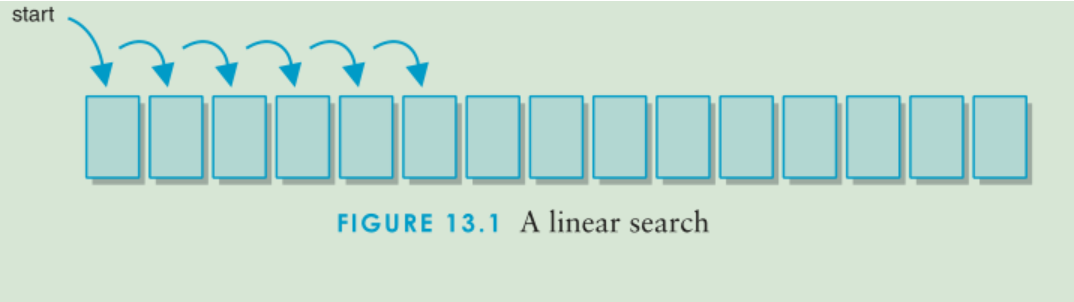
线性查找法代码:
public static<T extends Comparable<?super T> >
boolean lineatsearch (T[] data, int min, int max, T target)
int index = min;
boolean found = false;
while (!found && index <= max)
if (data [index]. compareToltarget) == 0
found=true;
index++;
return found;
该while循环将遍历数组元素,在找到元素或到达数组尾时其会终止
- 线性查找算法相当容易理解,但不是特别高效的。优点是线性查找并不要求查找池中的元素在数组中具有任何特定顺序。
-
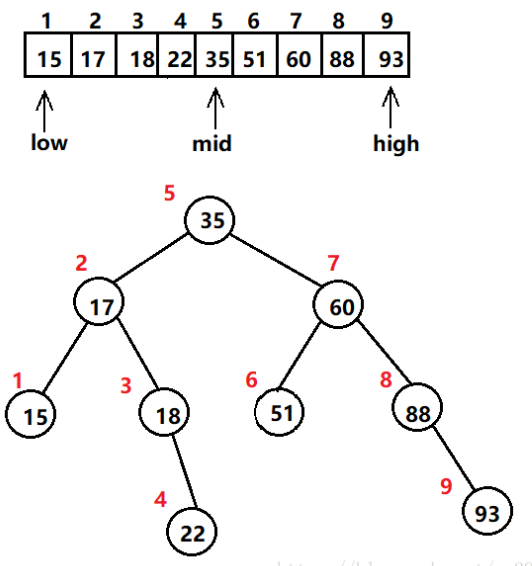
二分查找法
- 二分查找算法提升了查找过程的效率,但是查找池必须已排序。二分查找是从排序列表的中间开始查找。 二分查找都会将用于查找的剩余数据去掉大约一半(它同样会去掉中间元素)。 通过比较操作,我们将消减半的查找池。 剩下的一半查找池将表示可行候选项(viable candidates),目格元素就有待于在它们中间数找到。
public static <T extends Comparable<T>>
boolean binarySearch(T[] data, int min, int max, T target)
{
boolean found = false;
int midpoint = (min + max) / 2; // determine the midpoint(定义了用于查找(可行候选项)的数组部分)
if (data[midpoint].compareTo(target) == 0)
found = true;
else if (data[midpoint].compareTo(target) > 0)
{
if (min <= midpoint - 1)
found = binarySearch(data, min, midpoint - 1, target);
}
else if (midpoint + 1 <= max)
found = binarySearch(data, midpoint + 1, max, target);
return found;
}
}
binarySearch方法是递归实现的。如果没有找到目标元素,且有更多待查找数据,则该方法将调用其自身,同时传递参数,这些参数缩减了数组内可行候选项的规模。min和max索引用于确定是否还具有更多待查找数据。这就是说,如果削减后的查找区域一个元素也不含有,则该方法将不会调用其自身且会返回一个false 值。
- 在该过程中的任何时刻, 我们可能会有偶数个待查找值,因此就有两个“中间”值,根据该算法,所采用的中点可以是这两个中间值的任何一个。在该分 查找实现中,确定中点索引的计算丢弃了任何分数部分,因此它选择的是两个中间值中的第一个。
-
查找算法的比较
-
如果查找池中有n个元素,平均而言,在我们找到所查找的那个元素之前我们将不得不考察n/2个元素。因此,线性直找算法具有线性时间复杂度O(n),因为是依次每回查找一个元素, 所以复杂度是线性的一直接与待查找元素数目成比例。
-
找到位于该查找地中某元素的预期情形是大约(log2n)/2次比较。因此,二分查找具有一个对数算法且具有时间复杂度O(log2n)。与线性查找相比,n值较大时,二分查找要快得多。
-
两种查找算法的优势
1.线性查找般比查找要简单,线性查找无需花费额外成本来排序该查找列表。
2.二分查找的复杂度是对教级的,这使得它对于大型查找池非常有效率。对于小型问题,这两种类型的算法之间几乎不存在实用差别。但是,随着n的变大,二分查找就会变得吸引人。
-
9.2排序
-
排序是基于某一标准,将某一组项目按照某个规定顺序排列的一个过程。
-
基于效率排序算法通常也分为两类:顺序排序,它通常使用一对嵌套循环对n个元素排序,需要大约n^2次比较;以及对数排序, 它对n个元素进行排序通常需要大约nlog2 n次比较。与查找算法中一样,在n较小时,这两类算法之间几乎不存在实际差别。
-
本章学习三种顺序排序选择排序、 插入排序以及冒泡排序,以及两种对数排序快速排序和归并排序。
-
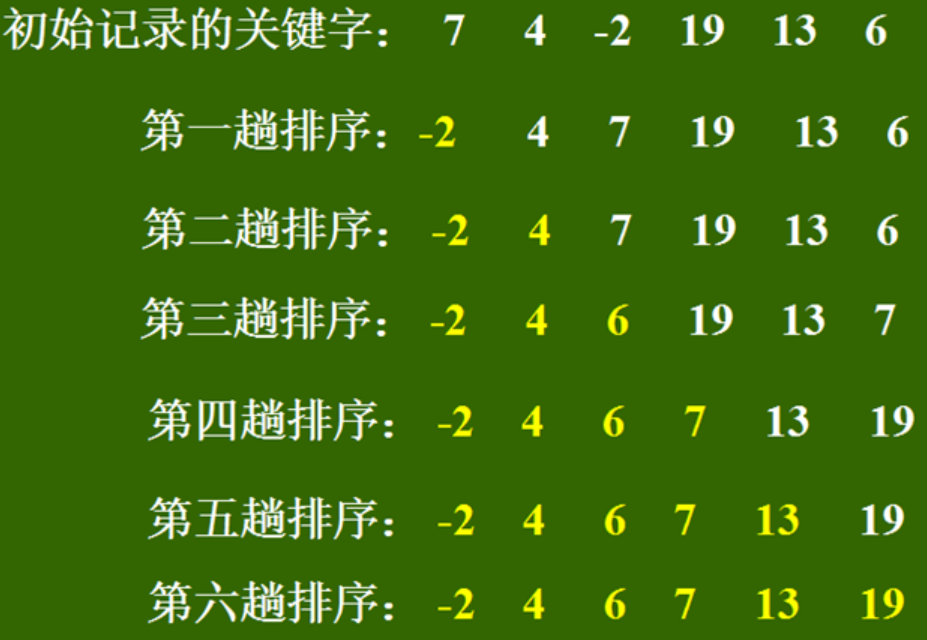
选择排序法
- 选择排序(selctionsomnd)算法通过反复地将某特定 值放到它在列表中的最终已排序位置,从面完成对某列值的排序。换句话说,对于列表中的每一位置,该算法都将选择由应该放进这位置的值并将其放在那里。
-选择持排字算法的一般策略:打描整个列表以找出最小值。将这个值与该列表第一个位置处的值交换。扫描(除了第一个值的)剩余部分列表并找出最小值,然后将它和该列表第二个位置处的值交换,扫描(除了前两个值的)剩余部分列表并找出最小值,然后将它和该列表第三个位置处的值交换,直到所有的数字排完。
-
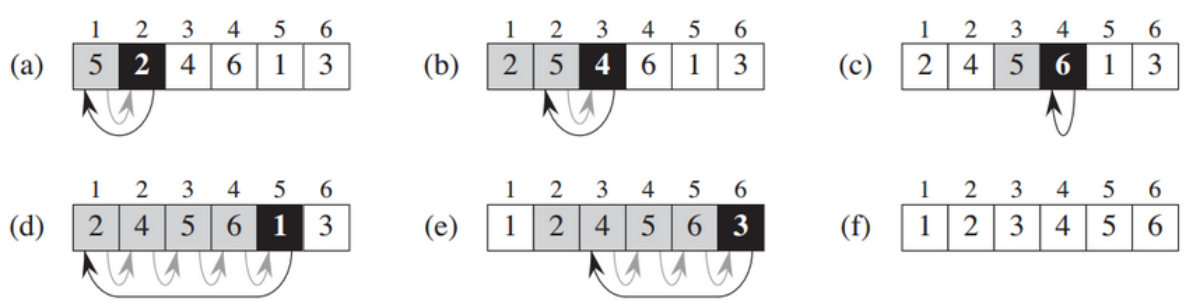
插入排序法
-
插入排序算法通过反复地将某一特定值插入到该列表某个已排序的子集中来完成对列表值的排序。
-
插入排序算法的一般策略:对列表中的头两个值依据其相对大小对其进行排序,如果有必要则将它们互换。将列表的第三个值插入到头两个(已排序的)值中的恰当位置。然后将第四个值插入到列表头三个值中的正确位置。每做出一次插入, 该排序子集中的值数目就会增加一个。继续这一过程, 直至列表中的所有元素都得到完全排序。该插入过程需要对数组中的其他元素移位,以给插入元素腾出空间。
-
-
冒泡排序法
-
冒泡排序算法通过重复地比较相邻元素且在必要时将它们互换,从而完成对某个列表的排序。
-
冒泡排序算法的一般策略:扫描该列表且比较邻接元素,如果它们不是按相对顺序排列则将其互换。这就像把最大值“冒泡”到列表的最后位置,这是它在最终已排序列表中的恰当位置。然后再次扫描该列表,冒泡出倒数第二个值。继续这一过程, 直至所有元素都被冒泡到它们正确的位置。
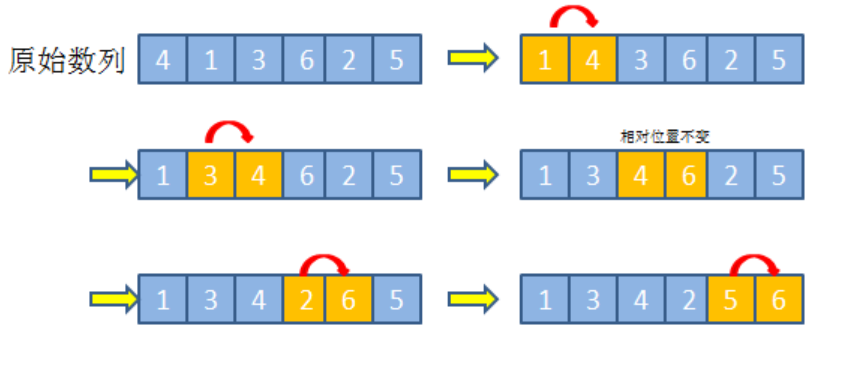
-
-
快速排序法
- 快速排序(quick sort)算法是这样对列表进行排序的:通过使用个任意选定的分区元素(partition clement)将该列表分区,然后对分区元素的任边的子列表进行递归排序。
- 快速排序算法的般策略:首先, 选择一个列表元素作为分区元素。下步,分割该列表,使得小于该分区无素的所有元素位于该元素的左边,所有大于该分区元素的元素位于右边。最后,将该快速接序策略(递归式)应用于两个分区。
- 归并排序法
-
归并排序(merge sort)算法是另一种递归排序算法, 通过将列表递归式分成两半直至每一子列表都只含有一个元素,然后将这些子列表按顺序重组,这样就完成了对列表的排序。
-
归并排序算法的 一般策:首先将该列表分成两个大约相等的部分,然后对每一部分列表递归调用其自身。继续该列表的递归分解,直至达到该递归的基本情形,这时活列表被分割成长度为1的列表,根据定义,它是已排序的了。然后,随着程序控制权传园率该通归调用结构,该算法将两个递归调用所产生的那两个排序子列表归并为个排序列表。
-
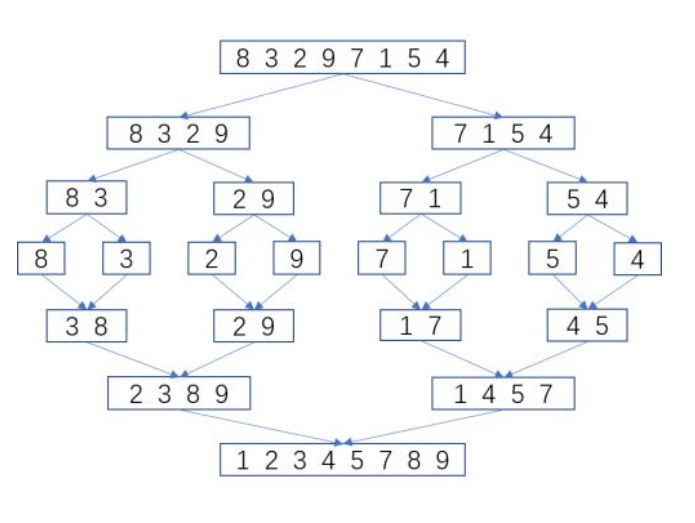
- 基数排序法
- 基数排序法可以无需进行元素之间的相互比较来排序,是种更高效的排序算法。
- 基数排序是基于队列处理的。排序要基于某个特定的值,这个值称为排序关键字(sort key)。对于排序关键字中每个数字/字符的每种可能取值,都会创建个单独的队列。队列的数目(或可能取值的种数)就称为基数(radix)。 例如,如果要排序十进制数,则基数应该是10, 0~9的每个数字都对应着一个队列。
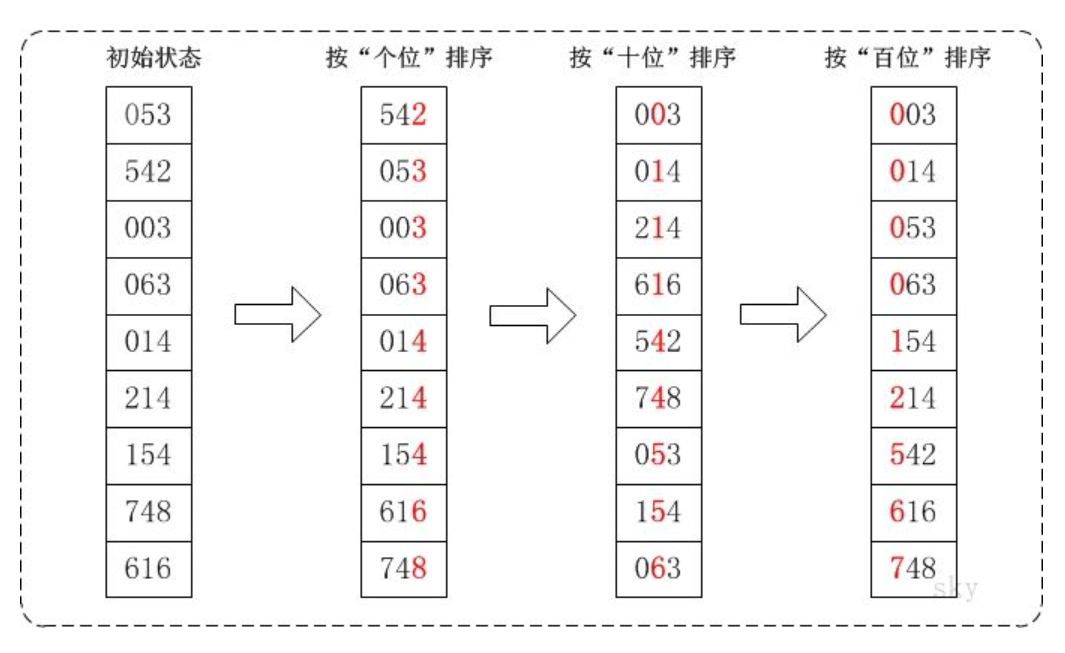
- 各种排序算法的比较

教材学习中的问题和解决过程
- 问题1:

但有时代码却是

- 问题1解决方案:这两种写法我都尝试了,没有体现出区别,那第一种代码是什么意思呢?
<T extends Comparable<T>>和<T extends Comparable<? super T>>有什么不同呢?
<T extends Comparable<T>>
类型 T 必须实现 Comparable 接口,并且这个接口的类型是 T。只有这样,T 的实例之间才能相互比较大小。例如,在实际调用时若使用的具体类是 Dog,那么 Dog 必须 implements Comparable<
<T extends Comparable<? super T>>
类型 T 必须实现 Comparable 接口,并且这个接口的类型是 T 或 T 的任一父类。这样声明后,T 的实例之间,T 的实例和它的父类的实例之间,可以相互比较大小。例如,在实际调用时若使用的具体类是 Dog (假设 Dog 有一个父类 Animal),Dog 可以从 Animal 那里继承 Comparable,或者自己 implements Comparable 。<
按我理解这样声明的好处就是,例如对 Animal/Dog 这两个有父子关系的类来说: <T extends Comparable<? super T>> 可以接受 List<Animal> ,也可以接收 List
所以,<T extends Comparable<? super T>> 这样的类型参数对所传入的参数限制更少,提高了 API 的灵活性。总的来说,在保证类型安全的前提下,要使用限制最少的类型参数。
可以参考一下这篇文章:
如何理解 Java 中的 <T extends Comparable<? super T>>
代码调试中的问题和解决过程
-
问题1:在完成蓝墨云线性表实践时,实现选择排序法的时候,排出来的结果是
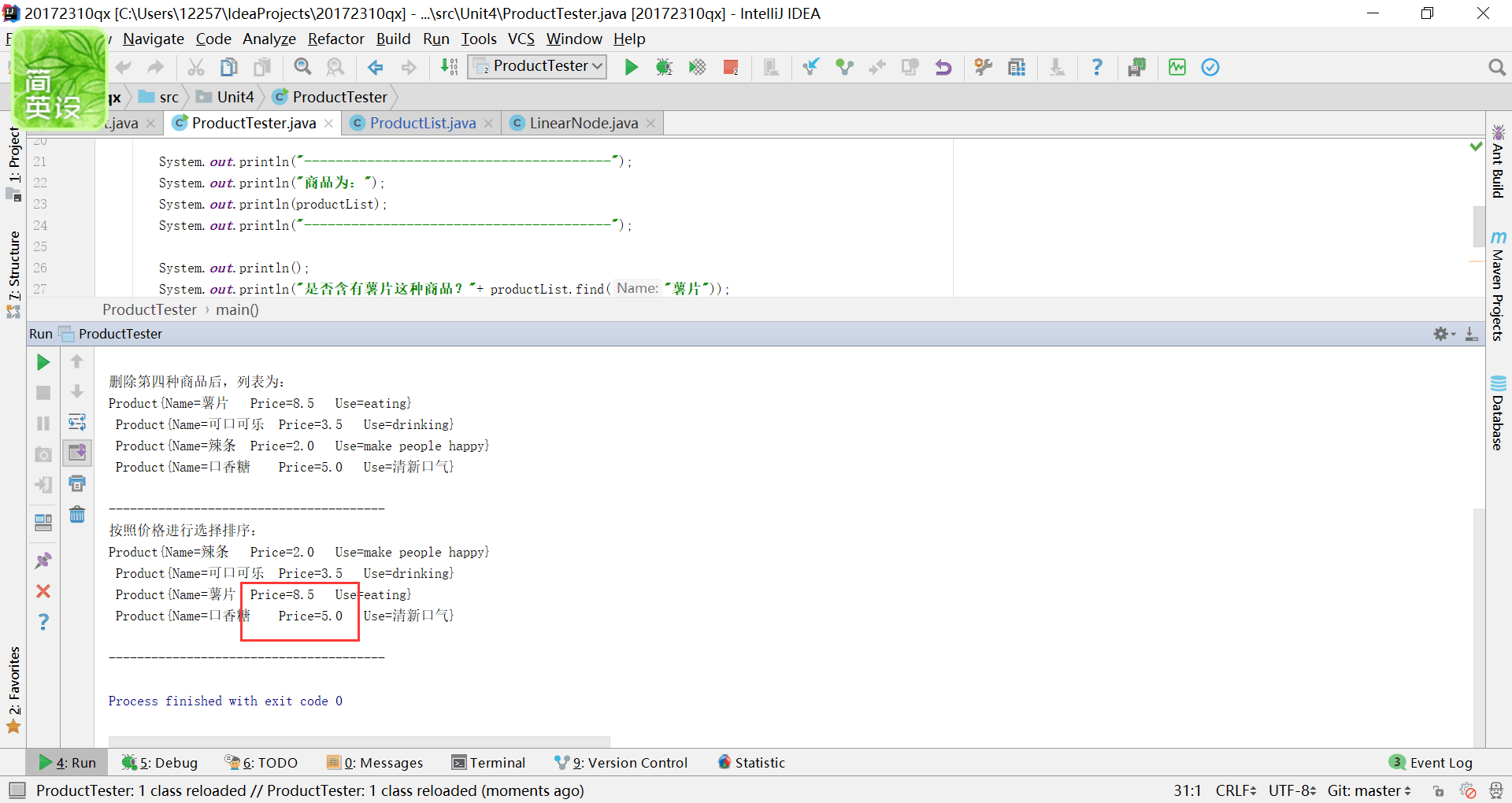
-
问题1解决方案:当时的代码是这样的
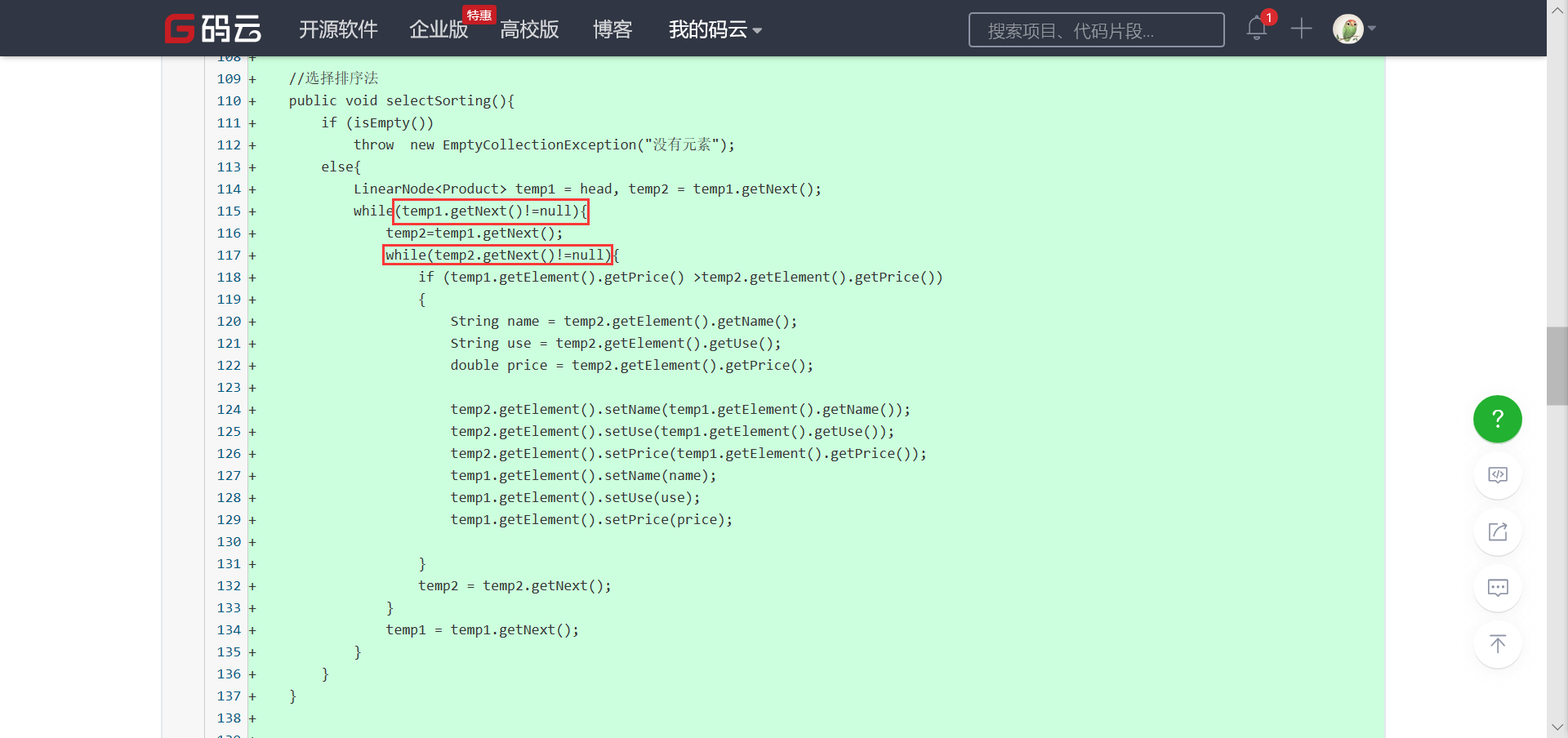
选择排序的逻辑确实是我的代码所体现的那样,但是为什么会出错呢?
于是我就进行了单步调试,发现因为 while(temp2.getNext()!=null)这行代码是只有temp2之后还存在元素时才会进入循环体,这样就有一个问题,如果temp2就是最后一个元素了,就不会在进行比较,于是发生了上面的错误。现在的关键就是要解决最后两个数比较的位置在哪。
我先将

这段代码放在了第二个循环体的后面,结果陷入了无限死循环;我又把他放在了第一个循环的外面,这个if条件句不会成立。最后我修改为
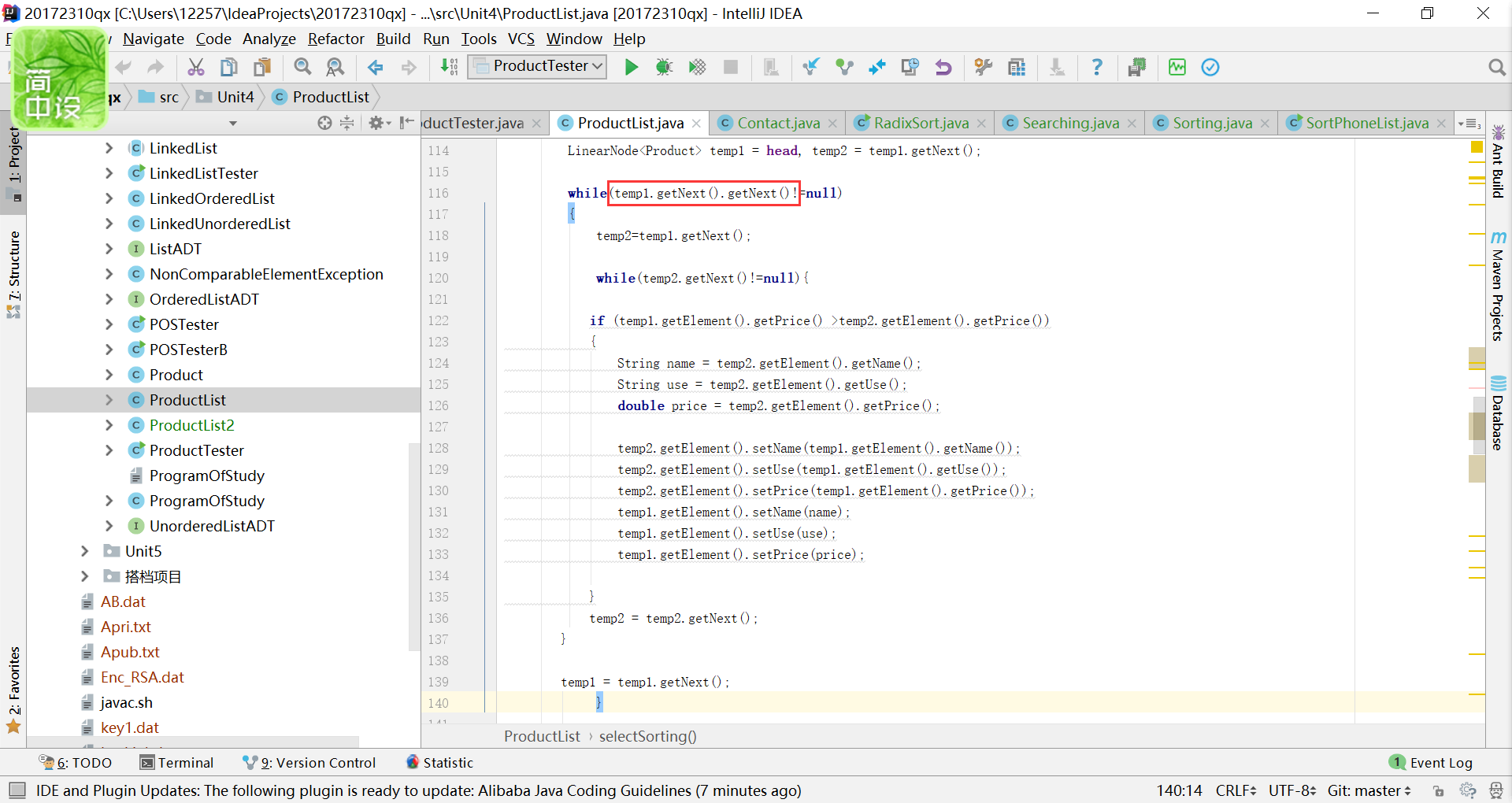
才解决了问题。
-
问题2:pp9.3中要求编写代码来计算每次代码执行时间,时间该如何计算呢?
-
问题2解决方案:
方案一:我们要计算程序,函数的执行之间,通常是在代码执行前后加入时间戳,两者的差值即为执行时间,
var count=1000;
var begin=new Date();
for(var i=0;i<count;i++){
document.createElement("div");
}
var end=new Date();
var time=end-begin;
console.log("time is="+time);
方案二:我们可以使用System类的currentTimeMillis()方法来返回当前的纳秒数,并保存到一个变量中,在方法执行完毕后再次调用 System的nanoTime()方法,并计算两次调用之间的差值,就是方法执行所消耗的纳秒数。因为队友建议ms为单位对于计算机来说时间有点长,所以得到的可能值会为0,所以使用ns为单位。
long startTime = System.nanoTime(); //获取开始时间
doSomething(); //测试的代码段
long endTime = System.nanoTime(); //获取结束时间
System.out.println("程序运行时间:" + (endTime - startTime) + "ns"); //输出程序运行时间
代码托管
(statistics.sh脚本的运行结果截图)
上周考试错题总结
- 错题1及原因,理解情况
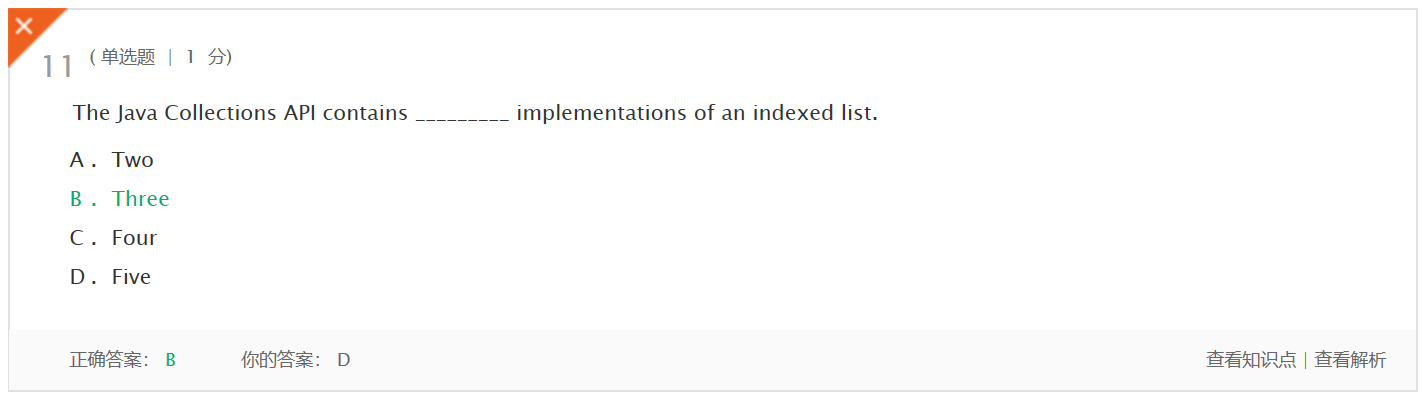
java集合API包含一个索引表__的实现。因为没有注意课本关键概念的总结,其实120面有答案,含有索引列表的三种实现。
结对及互评
点评:
-
博客中值得学习的或问题:
教材内容总结很精简,我觉得可以添加一下对方法的简单的解释。
教材问题2,其实可以写在教材内容总结里,有点缺少图示。但都是自己总结,进行了学习和简化。 -
本周结对学习情况
-
结对学习内容
- 学习第九章几种排序算法和查找算法,并讨论这些算法的复杂度。
- 探讨完成蓝墨云班课上线性表实践的作业,并相互帮助修改错误。
点评过的同学博客和代码
- 上周博客互评情况
其他(感悟、思考等,可选)
每天都要花好几个小时站在操场,还落了好多课,感觉少了好多时间学习,而且这周的任务量也不轻,自己还是要多抽出时间来学习。
学习进度条
|| | 代码行数(新增/累积)| 博客量(新增/累积)|学习时间(新增/累积)|重要成长|
| -------- | :----------------😐:----------------😐:---------------: |:-----😐
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 1/1 | 10/10 | |
| 第二周 | 326/326 | 1/2 | 18/28 | |
| 第三周 | 784/1110 | 1/3 | 25/53 | |
| 第四周 | 2529/3638 | 2/5 | 37/90 | |
| 第五周 | 1254/4892 | 2/7 | 20/110 | |
-
计划学习时间:28小时
-
实际学习时间:20小时
-
最近因为学校的活动少了一些时间来学习。

