20172310 2017-2018《程序设计与数据结构》(下)第二周学习总结
20172310 2017-2018《程序设计与数据结构》(下)第二周学习总结
教材学习内容总结
第三章 集合概述——栈
-
集合是一种聚集,组织了其他对象的对象。集合中的元素通常是按照它们添加到
集合的顺序,或者是按元素之间的某种内在关系来组织的,并以此划分为线性集合和非线性集合。 -
集合是一种隐藏了实现细节的抽象
-
数据类型:是一组值及作用于这些数值上的各种操作
-
数据结构:是一种用于实现集合的基本编程结构
-
数据结构一般是说计算机存储和组织数据的方式,还有就是相互之间存在一种或多种特定关系的数据元素的集
合,简单来说就是数据的逻辑或物理存储方式。而数据类型就是对数据的抽象描述,包括整型、浮点型 -
抽象:标准的解释是从具体事物抽出、概括出它们共同的方面、本质属性与关系等,而将个别的、非本质的方面、属性与
关系舍弃,这种思维过程,称为抽象。在Java的学习中,也可以这样理解,就是从具体的多个数据找到他们的共性,隐藏各自的细节。 -
抽象数据类型(ADT):是一种在程序设计语言中尚未定义其值和操作的数据结构类型。ADT的抽象性体现在,ADT必
须对实现细节进行定义,且这些对用户是不可见的。 -
栈的元素是按后进先出的方法进行处理的,最后进入栈中的元素最先被移出(LIFO)
-
Java集合API是一个类集,表示了一些特定类型的集合,这些类的实现方式各不相同。
-
异常就是一个对象,它定义了一种非正常或错误的情况。异常由程序或运行时环境抛出,可以按预期的被捕获或被正
确处理。错误与异常类似,只不过错误往往表示一种无法恢复的情况,且不必去捕获它。错误和异常表示不正常或不合法的处理。
第四章 链式结构——栈
-
对象引用变量可以用来创建链式结构。
-
链表由一些对象构成,其中每个对象指向了链表中的下一个对象。
-
链表会按需求动态增长,因此在本质上,它没有容量限制。
-
在链表中存储的对象通常泛称为链表的结点。
-
通常需要一个单独的引用变量(next)来表示链表的首节点,终止于next引用为空的结点。
-
插入结点
- 改变引用顺序是维护链表的关键。
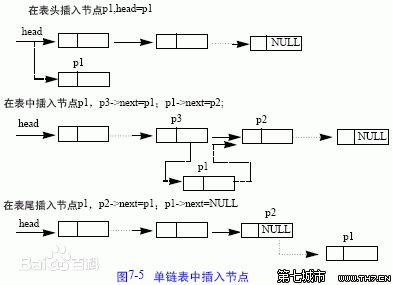
-
删除结点:

-
无链接的元素
- 存储在集合中的对象不应该含有基本数据结构的任何实现细节。
- 它只含有两个重要的引用:一个指向链表中的下一个节点,一个纸箱将存储进链表的元素。
-
双向链表
- 需要维护两个引用:一个引用指向链表的首结点;另一个引用指向链表的末端点。链表的每个结点都存在两个引用:一个指向下一个元素,另一个指向上一个元素。
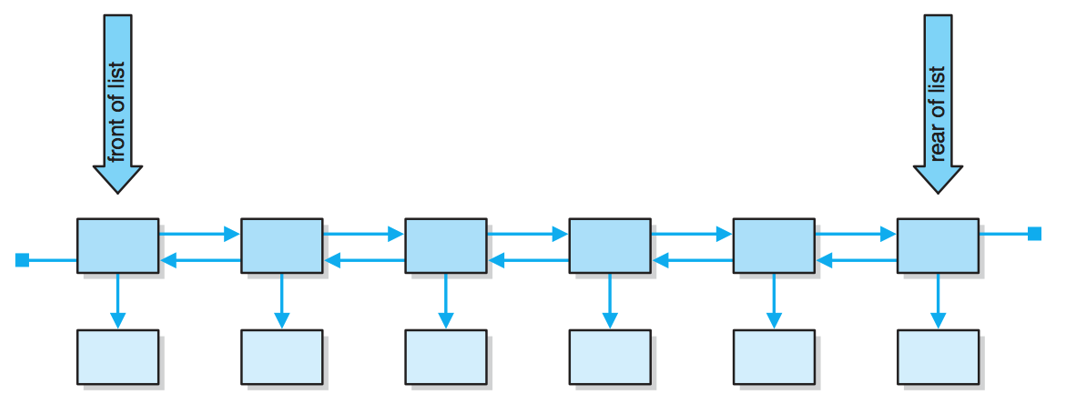
-
可以使用栈来模拟递归处理,以跟踪恰当的数据
-
只要有效地实现了恰当的操作,集合的任何实现都可以用来求解问题
-
栈的链表实现是从链表的一端添加和删除元素
教材学习中的问题和解决过程
- 问题1:泛型是什么?
- 问题1解决方案:
泛型是程序设计语言的一种特性。允许程序员在强类型程序设计语言中编写代码时定义一些可变部分
,那些部分在使用前必须作出指明。各种程序设计语言和其编译器、运行环境对泛型的支持均不一样。将类型参数化以达
到代码复用提高软件开发工作效率的一种数据类型。泛型类是引用类型,是堆对象,主要是引入了类型参数这个概念。
可以在集合框架(Collection framework)中看到泛型的动机。
泛型只在编译阶段有效。
- 泛型的好处:ava语言引入泛型的好处是安全简单。泛型的好处是在编译的时候检查类型安全,并且所有的强制转换都是自动和隐式的,提高代码的重用率。
- 问题2:三四章就是学习了用数组和链表两种方式实现栈的功能,那这两种方式各有什么优缺点呢?
- 问题2解决方案:看了半天的资料,才发现其实这个问题可以说成是数组和链表的区别。
数组,在内存上给出了连续的空间.链表,内存地址上可以是不连续的,每个链表的节点包括原来的内存和下一个节点的信息
数组:
优点:使用方便 ,查询效率 比链表高,内存为一连续的区域
缺点:大小固定,不适合动态存储,不方便动态添加
链表:
优点:可动态添加删除 大小可变
缺点:只能通过顺次指针访问,查询效率低
顺序表的优点:查找方便,适合随机查找
顺序表的缺点:插入、删除操作不方便,因为插入、删除操作会导致大量元素的移动
链接表的优点:插入、删除操作方便,不会导致元素的移动,因为元素增减,只需要调整指针。
顺序表的缺点:查找方便,不适合随机查找
代码调试中的问题和解决过程
- 问题1:在蓝墨云班课的作业上,突然出现了冒泡排序法这种排序方式,这是啥?(꒪Д꒪)ノ
- 问题1解决方案:
1.冒泡排序法:它重复地走访过要排序的元素列,依次比较两个相邻的元素,如果他们的顺序(如从大到小、首字母从A到Z)
错误就把他们交换过来。走访元素的工作是重复地进行直到没有相邻元素需要交换,也就是说该元素已经排序完成。
这个算法的名字由来是因为越大的元素会经由交换慢慢“浮”到数列的顶端(升序或降序排列),就如同碳酸饮料中二氧化碳
的气泡最终会上浮到顶端一样,故名“冒泡排序”。
2.三种算法的区别:选择排序需要两层循环来实现,外层循环控制次数,内层循环控制找到最小的值。然后将内层循
环找到的最小值与外层循环本次索引对应元素进行交换,直至遍历完整个数组.插入排序有两层循环,外层循环逐个遍历
数组元素,内层循环把外层循环的元素与该元素在内层循环的下一个元素进行比较,如果外层循环选择的元素小于内层循
环选择的元素,那么数组元素都行右移动为内层循环元素留出位置。冒泡算法是最基础的一个排序算法,每次使用第一个
值和身后相邻的值进行比较,如果是升序将大数向左边交换,降序则向右边交换。最终将大数移动到一边,
最终排成一个序列。
结论:冒泡算法效率最低,插入算法效率最高 - 三种基础排序算法(选择排序、插入排序、冒泡排序)
- 三个基本排序算法执行效率比较(冒泡排序,选择排序和插入排序)
代码托管
(statistics.sh脚本的运行结果截图)
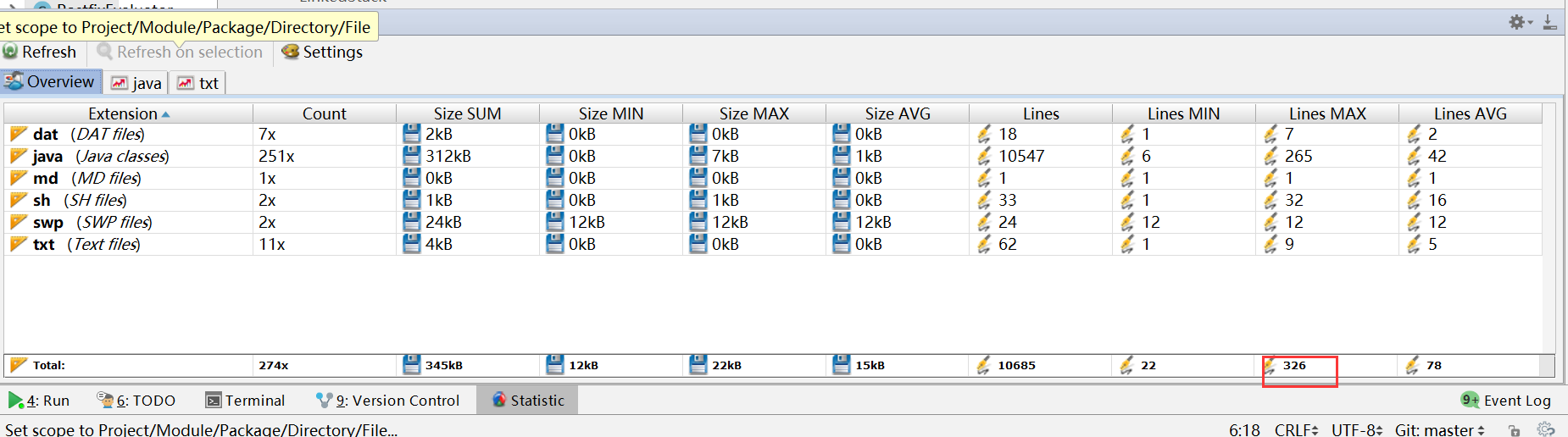
上周考试错题总结
- 错题1及原因,理解情况

一个高效的系统可以优雅地处理问题
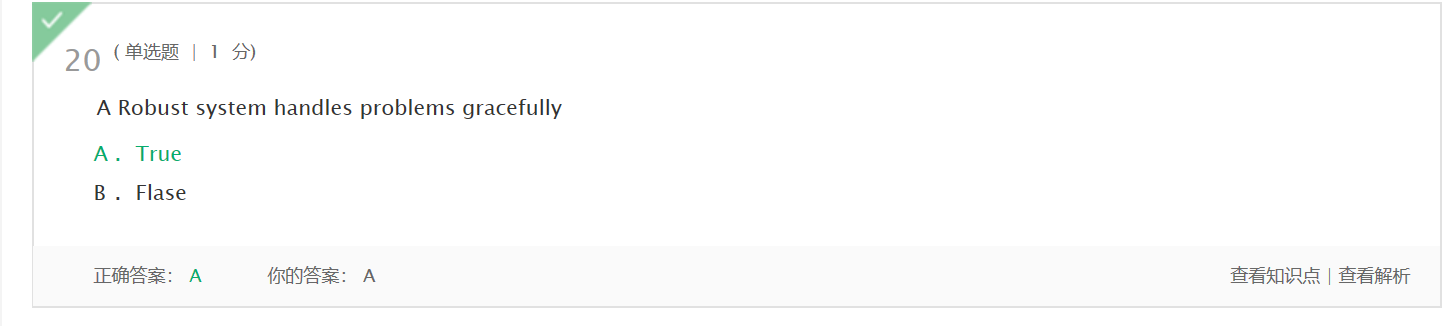
太粗心了。
- 错题2及原因,理解情况
可以使用堆栈来保存一组数据的顺序
解析:一组地址采用连续的存储单元来依次存储线性表的各个数据元素称之为线性表的顺序存储结构,顺序存储结构就是把
一堆数据按照给定的地址连续存放。而链表是内存中随机存贮,只有数组这种静态的内存分配方式才是连续存贮的。
课后作业
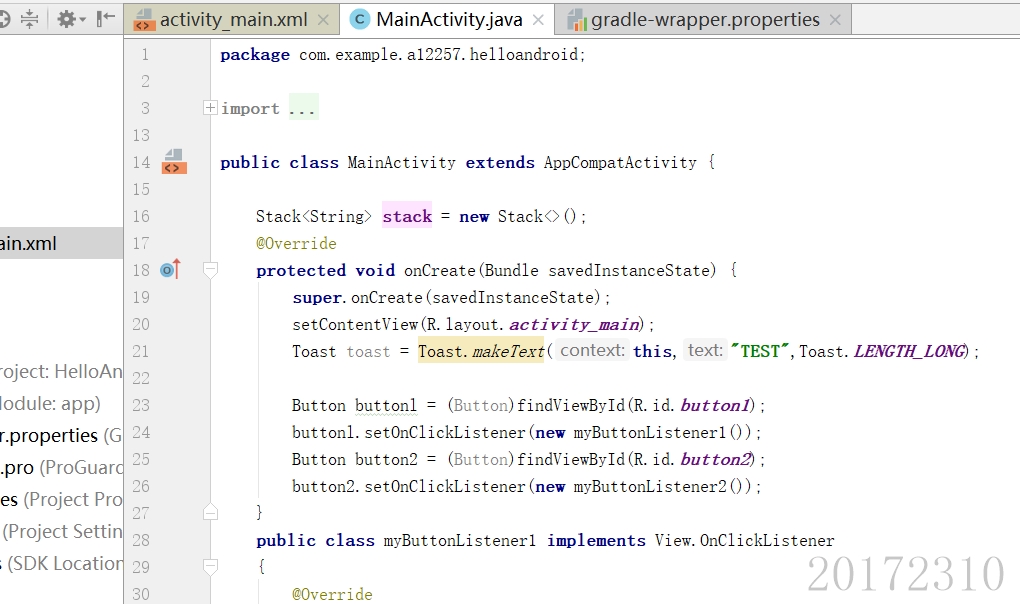
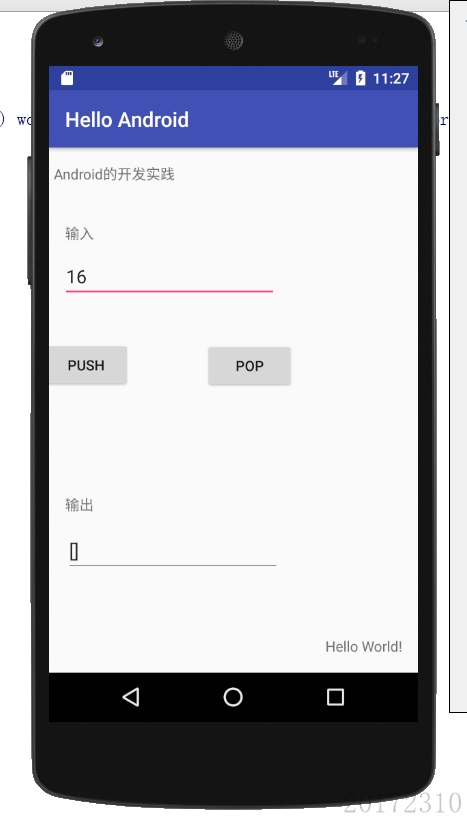
pp3.9是使用Android Studio没上传码云,现附上截图



结对及互评
点评:
-
博客中值得改正的问题:
- 教材内容总结很详细,利用代码详细讲解,但是没必要将教材中的代码大量的放入博客中,可以尝试用简洁的语言表述一下。
- 没有发现阅读教材的问题
-
代码中值得学习的问题:
- 代码量很大,花了很多时间自己编码。
- 没有放代码量的截图
点评的同学博客和代码
其他(感悟、思考等,可选)
这个星期又开始了敲代码之旅,数组,集合,栈这些内容其实上个学期都有学习到一些,但是经过这一个礼拜
的学习发现,这个学期的课程更加深入了(其实这是必然的),但是我也认识到上个学期的内容很多我都遗忘了,
所以有时间还是要去复习一下以前的课本了( • ̀ω•́ )✧
学习进度条
|| | 代码行数(新增/累积)| 博客量(新增/累积)|学习时间(新增/累积)|重要成长|
| -------- | :----------------😐:----------------😐:---------------: |:-----😐
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 1/1 | 10/10 | |
| 第二周 | 326/326 | 1/2 | 18/28 | 学习在一点点的深入 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号