Sliced Scroll
在实现日常需求中,经常有 用到 Sliced Scroll 记录下
max是切片数,是切片编号。最大值可以等于分片的数量,较低或更高。拆分首先在分片上完成,然后在每个分片上本地进行。这意味着,如果每个切片将是单个分片上的滚动。idmax == num_of_shards。 请注意,当切片数大于分片数时,将执行内存成本操作。您可以使用切片滚动进行并行重新索引、按查询更新和按查询删除。在此处阅读更多内容。
查询 2020-04-24 00:00:00 到 2020-04-26 12:59:59 所有条数,记录已经超过1万条,使用 Sliced Scroll,
注意: "max": 5 ,max 可以去掉,去掉的话 就是可以查询全量
GET xxxxindex/_search?scroll=1m
{
"query": {
"bool": {
"must": [
{
"range": {
"curTime": {
"gt": "2020-04-24 00:00:00",
"lt": "2020-04-26 12:59:59"
}
}
}
]
}
},
"from": 0,
"size": 1,
"slice": {
"id": 0,
"max": 5
}
}
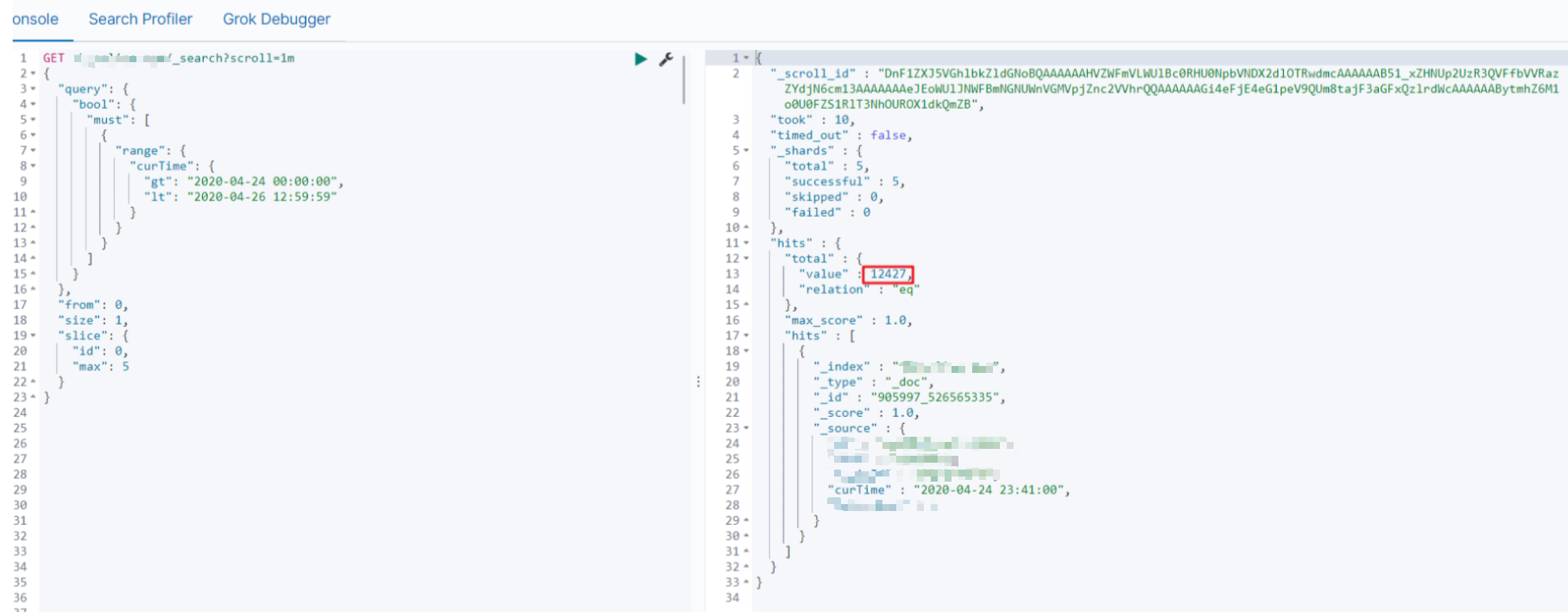
这样写,它会返回 符合条件的总条数
从视图中,可以看到 返回 “_scroll_id”
刚设置的 scroll=1m,分片在一分钟内有效
把返回 _scroll_id 内容复制到新的语句
GET /_search/scroll
{
"scroll":"1m",
"scroll_id":"DnF1ZXJ5VGhlbkZldGNoBQAAAAAAHU1dFmVLWUlBc0RHU0NpbVNDX2dlOTRwdmcAAAAAAB5srBZHNUp2UzR3QVFfbVVRazZYdjN6cm13AAAAAAAeGzcWUlJNWFBmNGNUWnVGMVpjZnc2VVhrQQAAAAAAGiY-FjE4eG1peV9QUm8tajF3aGFxQzlrdWcAAAAAABylIBZ6M1o0U0FZS1RlT3NhOUROX1dkQmZB"
}
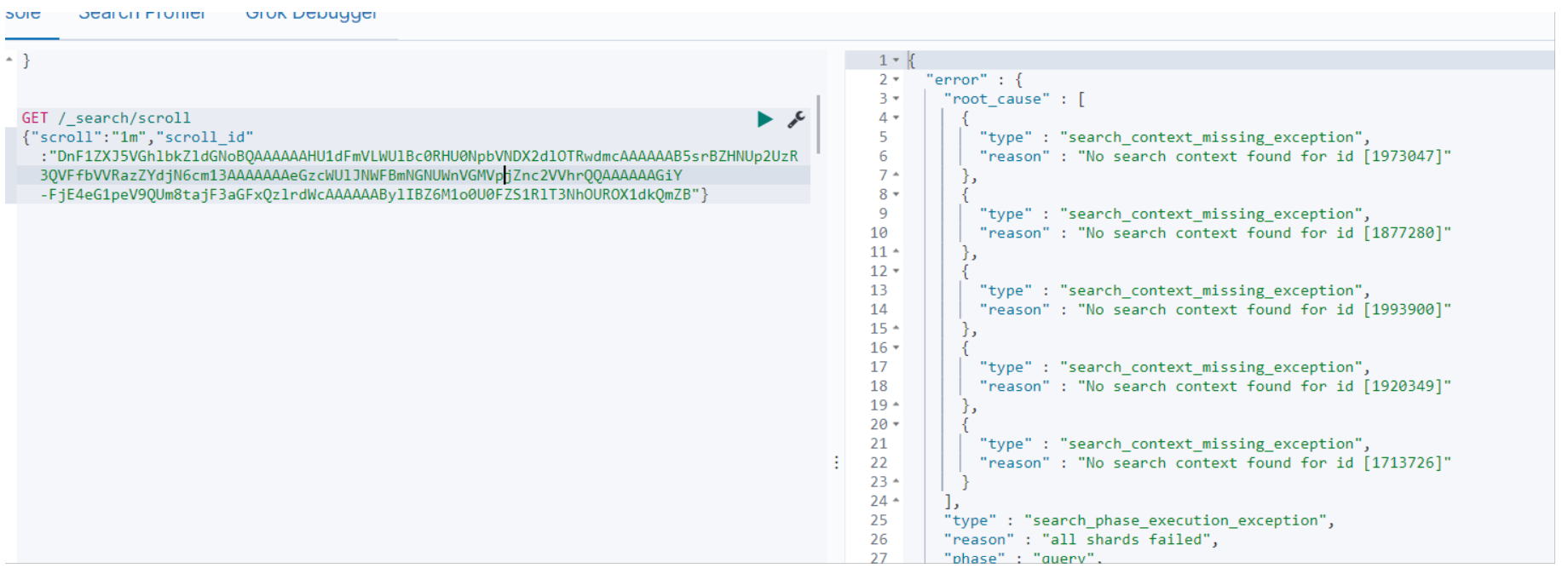
在1分钟以内,查询有效,返回下一批数据,超过1分钟,查询就会报错,报错图如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号