jmeter正则表达式提取器
正则表达式提取器:
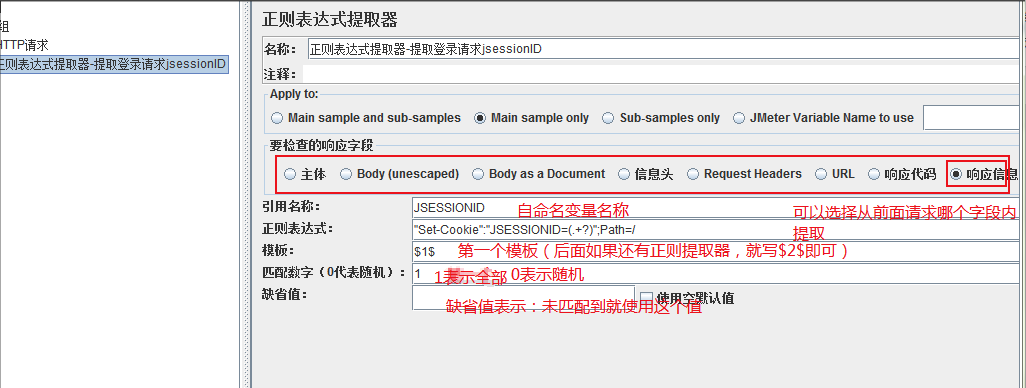
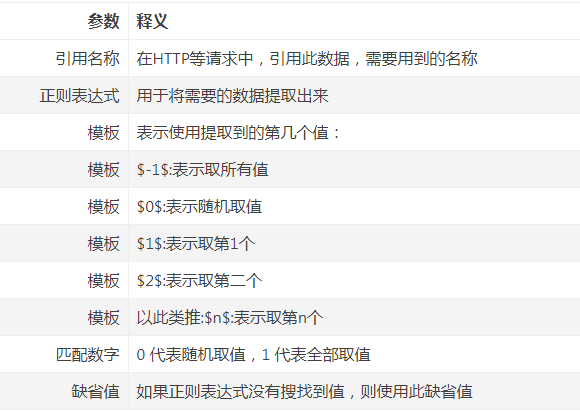
允许用户从服务器的响应中通过使用perl的正则表达式提取值。
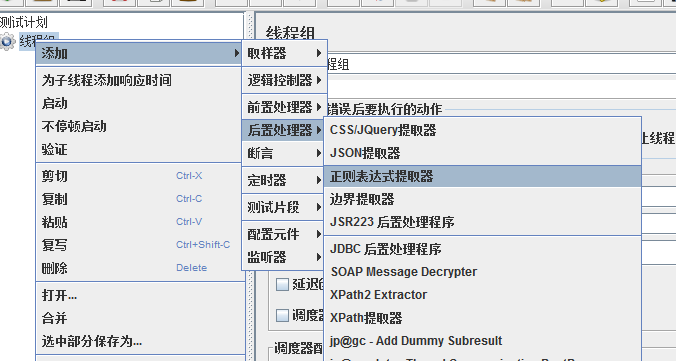
该元素会作用在指定范围取样器,
用正则表达式提取所需值,生成模板字符串,并将结果存储到给定的变量名中
操作如下:-------------
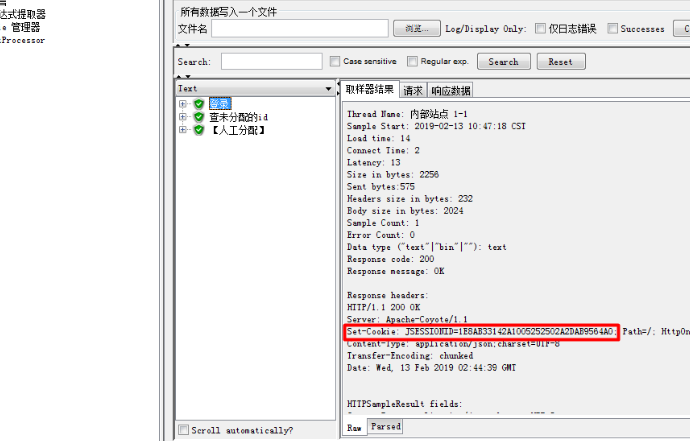
登录请求响应信息内 set-cookie:xxxxxxxxxx,这一串会应用到后面登录后的每个请求的头里去(那么就需要提取出来,通过变量的形式传递使用)
正则的简单使用模板介绍:
1\bhi\b : 匹配只有hi的字符,\b代表的位置,第一个\b代表单词开始的位置,第二个\b代表单词结束的位置 2\bhi\b.*\bthis\b : 匹配hi的字符后,中间有任意个字符后,后面是this的字符 3 . : 表示任意字符的元字符,例如Perl正则表达式,r.t匹配这些字符串:rat、rut、rt,但是不匹配root 4 *:表示任意数量的元字符,代表的不是字符,也不是位置,而是数量。匹配0或多个正好在它之前的那个字符。例如Perl正则表达式.*意味着能够匹配任意数量的任何字符 5 \d : 表示任意一个数字[0-9] 6 \d+ : 匹配一个或更多连续的数字。这里的+是和*类似的元字符,不同的是*匹配重复任意次(可能是0次),而+则匹配重复1次或更多次。 7 \D : 匹配任意非数字的字符 [^0-9] \w: 8 \d{2}: 表示任意一个数字出现两次,相当于\d\d 9 \s : 匹配任意的空白符,包括空格,换行符,制表符(tab),中文全角空格。即空白 [ \r\t\n\f] 10 \S : 匹配任意不是空白符的字符。即非空白 [^ \r\t\n\f] 11 \w : 匹配字母,数字,下划线或汉字。即任意单词字符 [_0-9a-zA-Z] 12 \W : 匹配任意不是字母,数字,下划线,汉字的字符。即任意非单词字符 [^_0-9a-zA-Z] 13 \b\w{2}\b : 匹配刚好有两个字符的单词 14 \b : 匹配单词的开始和结束 15 ^ : 匹配字符串的开始。例如Perl正则表达式^Whenin能够匹配字符串"Wheninthecourseofhumanevents"的开始,但是不能匹配"WhatandWheninthe" 16 $ : 匹配字符串的结束, 例: ^\d{2,5}$ 表示输入的数字必须是2位(包含)到5位(包含)之间; 例如Perl正则表达式weasel$能够匹配字符串"He'saweasel"的末尾,但是不能匹配字符串"Theyareabunchofweasels." 17 \ : 转义字符,如果要查找元字符就需要用转义字符来完成,比如: deerchao\.net 实际上是deerchao.net。 用来将这里列出的这些元字符当作普通的字符来进行匹配。例如Perl正则表达式\$被用来匹配美元符号,而不是行尾,类似的,Perl正则表达式\.用来匹配点字符,而不是任何字符的通配符 18 重复次数说明: *是重复0次或多次,+是重复1次或多次,?是重复零次或一次,{n} 是重复n次,{n,}是重复n次到多次,{n,m}是重复n次到m次 19 []、[c1-c2]、[^c1-c2]: 括号里的字符会被匹配,比如[ab]匹配a或b字符,[,?]匹配逗号或问号 例如Perl正则表达式r[aou]t匹配rat、rot和rut,但是不匹配ret。 可以在括号中使用连字符-来指定字符的区间,例如Perl正则表达式[0-9]可以匹配任何数字字符; 还可以制定多个区间,例如Perl正则表达式[A-Za-z]可以匹配任何大小写字母。 另一个重要的用法是“排除”,要想匹配除了指定区间之外的字符——也就是所谓的补集——在左边的括号和第一个字符之间使用^字符,例如Perl正则表达式[^269A-Z]将匹配除了2、6、9和所有大写字母之外的任何字符 20 [a-z0-9A-Z] : 相当于匹配\w 21 | : 匹配或规则,将两个匹配条件进行逻辑“或”(Or)运算。比如: \(0\d{2}\)[- ]?\d{8}|\(0\d{3}\)[- ]\d{7}|0\d{2}[- ]?\d{8}|0\d{3}[- ]?\d{7} 这个就是匹配电话号码的,如:012-56236562, 0536-1234567,(0536)-1234567,01212345678 例如Perl正则表达式(him|her)匹配"itbelongstohim"和"itbelongstoher",但是不能匹配"itbelongstothem."。注意:这个元字符不是所有的软件都支持的 22 ():匹配分组,255.134.123.123 或 193.168.1.1 匹配表达式为:(([01]?\d\d?|25[0-5]|2[0-4]\d)\.){3}([01]?\d\d?|25[0-5]|2[0-4]\d) 23 \B : 匹配不是单词开头或结尾的位置 24 + :匹配1或多个正好在它之前的那个字符。例如Perl正则表达式9+匹配9、99、999、98、93dsf、9.....等。注意:这个元字符不是所有的软件都支持的 25 ? :匹配0或1个正好在它之前的那个字符。注意:这个元字符不是所有的软件都支持的 26 [^x] : 匹配除了x以外的任意字符 27 [^aeiou] : 匹配除了aeiou以外的任意字符 28 (?<word>\w+) 或(?'word'\w+) 后向引用,用于重复搜索前面某个分组已经匹配的文本,引用时就可以写成\k<word>。实际上分组0对应整个正则表达式;组号分配过程是从左到右分配两遍的,第一遍先扫描未命名的分组,第二遍扫描已命名的分组,所以命名分组的组号永远大于未命名分组的组号的; 可以用(?:exp)来剥夺组号分配的参与权 29 分组命名的几种语法: (exp) 匹配exp表达式并将文本匹配的内容自动分配到分组里; (?<name> exp)匹配exp表达式里的文本内容到name组名下,也可以写成(?'name'exp); (?:exp)匹配exp表达式里内容,但是不捕获匹配的文本也不给匹配的文本分配组号;(?=exp)匹配exp前面的位置; (?<=exp)匹配exp后面的位置 ; (?!exp)匹配后面不是exp的位置 ; (?<!exp) 匹配前面不是exp的位置; (?#comment)添加注释,对正则表达式没有任何影响; 30 (?=exp)与(?<=exp)为零宽断言,其中(?=exp)为零宽度正预测先行断言,(?<=exp)为零宽度正回顾后发断言。(?=exp)表示自exp断言表达式出现的位置开始匹配断言之前的内容,如\b\w+(?=er\b) 源文件为tester,则匹配结果为:test。(?<=exp)表示自exp断言表达式内容结束后的位置开始匹配后面的内容,如(?<=test)\w+\b 源文件为test, 则匹配结果为:er。 31 {i}、{i,}、{i,j}:匹配指定数目的字符,这些字符是在它之前的表达式定义的。例如Perl正则表达式A[0-9]\{3\}能够匹配字符"A"后面跟着正好3个数字字符的串,例如A123、A348等,但是不匹配A1234。Perl正则表达式[0-9]\{4,\}匹配连续的任意4个或4个以上数字字符。Perl正则表达式[0-9]\{4,6\}匹配连续的任意4个、5个或者6个数字字符。注意: 这个元字符不是所有的软件都支持的 32 \ba\w*\b:匹配以字母a开头的单词——先是某个单词开始处(\b),然后是字母a,然后是任意数量的字母或数字(\w*),最后是单词结束处(\b)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号