go学习笔记
包
go 由包组织(即一个文件夹,文件夹的名字对应包的名字,文件夹可以包含一个多个 go 源文件),每个源文件用packge 包名在开头声明
main 包:定义一个独立可执行程序,总是程序开始的地方
包的导入
通过import 包名或import (多个包名)*导入包
包名重复需要指定别名避免重复import 指定名 包名
空导入import _ 包名,主要想使用包中的func init(){}函数
包导入时是搜索到包的源码,将其编译为.a文件,放在临时目录里,然后链接在一起
注意:其实import 后跟的并不是包名,而是包导入路径,但是一般约定路径最后一段(目录名)和包名一致,如果不一致也最好在导入时显示表示
包的初始化
可以声明 func init(){}函数,不能被调用和引用,程序启动时自动执行
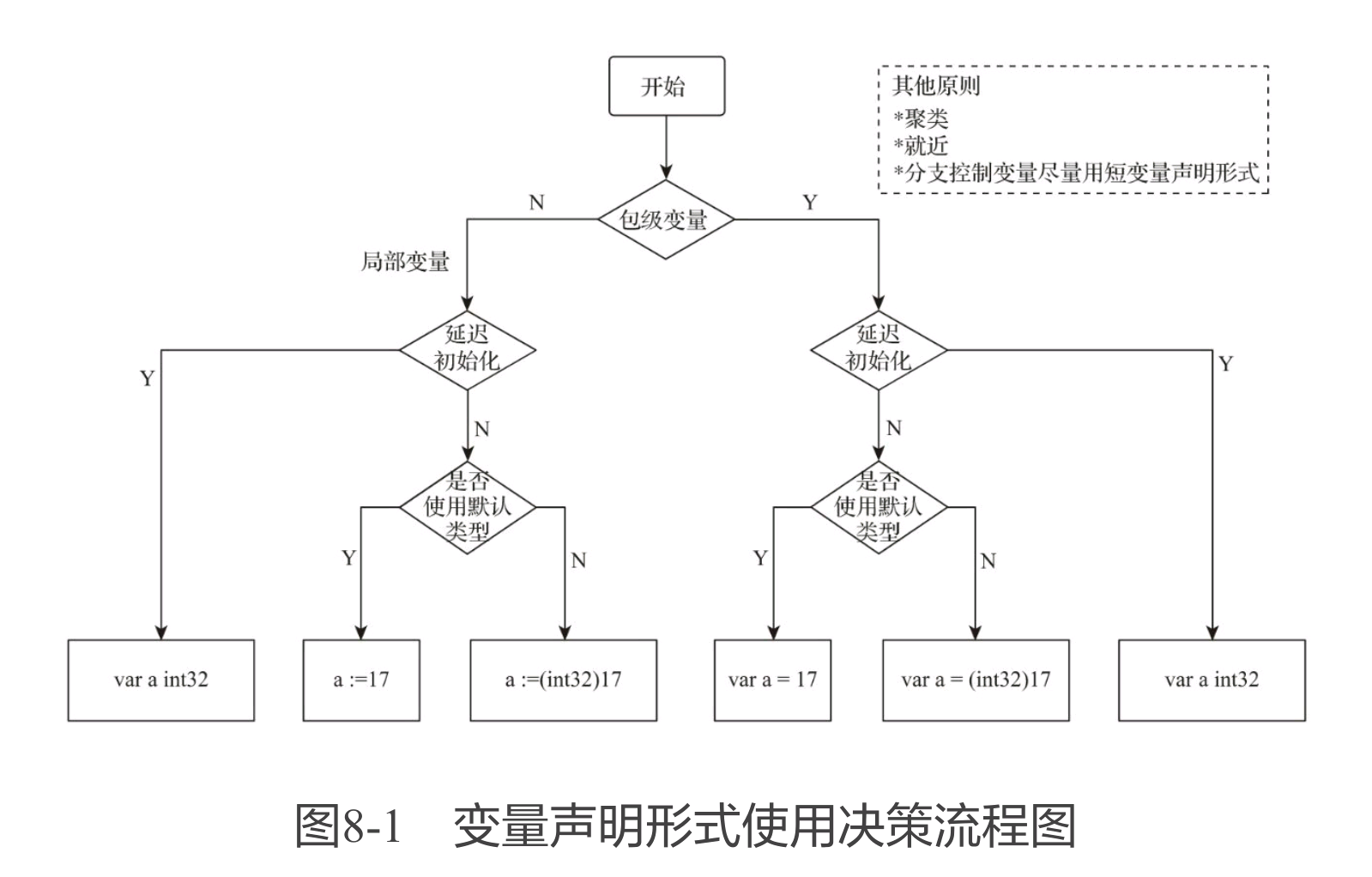
声明
命名采用驼峰,包名总是小写,名字大写意味着包外可以访问
var 变量
var 名字 类型=表达式
类型和表达式只能省略一个,省略类型,则由表达式推断得,省略表达式,则赋予对应类型的初始值(接口引用等初始值为 nil)
短变量声明(一般用于局部变量中不重要的变量)名字:=表达式
命名规则
赋值
可以多重赋值
i,j=1,2
i,j=j,i//交换i与j的值
控制逻辑
尽量遵循:出现错误就返回。成功逻辑不要放到if else中
循环
for initialization;condition;post{
}
//其中三个部分都可以省略
for range的坑
- i是重用的,不是每次迭代都重新创建,range遍历的是a的副本,除非使用&a或切片a[:]
- break 跳出的是所在的for select switch层,go中break continue可以后接标签
for i := range a{
// a是数组
}
switch
不像c等是顺序执行,default可以在任意顺序,switch可以有无标签的形式
func r() int{
return 0
}
func main() {
switch r(){
case 2:
fmt.Println(2)
default:
fmt.Println(1)
case 0:
fmt.Println(0)
}
a:=10
switch {
case a<10:
fmt.Println("小于")
case a>10:
fmt.Println("大于")
default:
fmt.Println("等于")
}
}
输入输出
抽象数据实例的读写gob包,另外还有xml包,json包等
文本字符串读写fmt.Fsacn fmt.Fprint
定长表示抽象数据的二进制读写binary.Read binary.Write
带缓冲区的读写bufio
带压缩数据的读写compress/gzip包
JSON
json.Marshal与json.Unmarshal负责转为json格式和转回,json.MarshalIndent可以输出格式化的json,第二个参数为自定义的前缀,第三个为自定义的缩进
能转为 json 的必须首字母大写,如下例的secert首字母小写,转化的data就不包含他
可以定义一些标签,用原生字符串表示,表示转化为json时,对应的key值替换为指定的,如data中的name被替换为nickname,其中omitempty 表示如果原始数据没指定这个值,用零值表示,如小王中没指定Age为多少,在data中被指定为为0
在转回时,定义的数据的变量名首字母需要大写,他会自动匹配数据中的首字母小写的,如data中为nickname,nameLIst为Nickname,两者会匹配
在转化时json.Unmarshal会自动丢弃不需要的数据
type people struct{
Name string `json:"nickname"`
Age int `json:"Age,omitempty"`
Hobby []string
secret string
}
var peoples=[]people{
{Name:"小明",Age:12,Hobby:[]string{"画画","唱歌"},secret:"哈哈"},
{Name:"小王",Hobby:[]string{"学习"},secret:"爱吃……"},
{Name:"小白",Age:12,Hobby:[]string{"打篮球"}},
}
//转为json
//data,err:=json.Marshal(peoples)
data,err:=json.MarshalIndent(peoples,""," ")
if err!=nil{
fmt.Printf("转换json失败%s",err)
}else{
fmt.Printf("%s\n",data)
}
//转回,只取nickname
var nameList []struct{Nickname string}
if err:=json.Unmarshal(data,&nameList);err!=nil{
fmt.Printf("转换json失败%s",err)
}else{
fmt.Printf("%s",nameList)
}
[
// {
// "nickname": "小明",
// "Age": 12,
// "Hobby": [
// "画画",
// "唱歌"
// ]
// },
// {
// "nickname": "小王",
// "Hobby": [
// "学习"
// ]
// },
// {
// "nickname": "小白",
// "Age": 12,
// "Hobby": [
// "打篮球"
// ]
// }
//]
//[{小明} {小王} {小白}]
模板
以"text/template"为例
type Pet struct{
Nickname string
Kind string
}
type people struct{
Name string `json:"nickname"`
Age int `json:"Age,omitempty"`
Pets []Pet
}
p:=people{Name:"小明",Age:12,Pets:[]Pet{Pet{"小花","猫"},Pet{"小黄","狗"}}}
//通过原生字符串定义一个模板,模板中Age后的|表示将数据交给year2Month处理,其中range .Pets表示循环展开.Pets
const temp=`-------分割线----------------------------
我叫{{.Name}},今年{{.Age| year2Month}}个月了
我养的宠物有:
{{range .Pets}}
{{.Nickname}},它是个{{.Kind}}
{{end}}`
//创建模板,然后添加其中要处理的函数
out,err:=template.New("temp").
Funcs(template.FuncMap{"year2Month": year2Month}).
Parse(temp)
if err!=nil{
fmt.Println("出错了1")
}
//执行这个模板,格式化数据
if err:=out.Execute(os.Stdout,p);err!=nil{
fmt.Println("出错了")
}
//-------分割线----------------------------
//我叫小明,今年144个月了
//我养的宠物有:
//
//小花,它是个猫
//
//小黄,它是个狗
文件读取和写入
func main() {
//从窗口标准输入读到要写入的文件名
outfilename:=""
fmt.Scan(&outfilename)
ioutil.WriteFile(outfilename,[]byte("***"),7777)
//读取文件中内容
data,err:=os.ReadFile(outfilename)
if err==nil{
fmt.Printf("%s",data)
}
//从命令行参数读取文件名,并统计每句话次数,最后输出
counts:=make(map[string]int)//键值对,键为string,值为int
infilename:=os.Args[1]//读取命令行参数
f,err:=os.Open(infilename)//打开文件
if err==nil{//如果没有错误err为nil
input:=bufio.NewScanner(f)
for input.Scan(){
counts[input.Text()]++
}
}
f.Close()
for line,n:=range counts{
fmt.Println("%f\t%s\n",n,line)
}
}
数据类型
基础类型:数字,字符串,布尔
聚合类型:数组,结构体
引用类型:指针,slice,map,函数,通道
接口类型
整数
有符号:int8 int16 int32 int64
无符号:uint8 uint16 uint32 uint64
另外有 int 和 uint,虽然其一般看做 int32,但是两者还是不同的类型
另外有 rune,其等于 int32,只是强调为 unicode 码点
另外有 byte8,其等于 int8,只是强调值为原始数据
另外有 unitptr,其为无符号整数,但大小不明确,用于底层
无符号整数一般只用于位运算和特定算术运算,极少用*表示非负值
进制:0开头 8进制,0x开头 16 进制
a:=07777
fmt.Printf("%d %o %x %X %#o %#x %#X",a,a,a,a,a,a,a)//#为输出前缀
//输出4095 7777 fff FFF 07777 0xfff 0XFFF
文字字符用单引号
a:='a'
b:='啊'
fmt.Printf("%c %c %q",a,b,b)
//a 啊 '啊'
浮点数
float32 float64
a:=2340.45678
fmt.Printf("%g %e %f %8.4f",a,a,a,a)
//2340.45678 2.340457e+03 2340.456780 2340.4568
布尔值
布尔值不能直接与 0,1 相互转换
字符串
string也相当于一个“描述符”,是指向字符串的指针
len()得到字符串的字节数,不是长度
字符串不可变,所以 b 和 c 实际指向的是在同一地方的字符串"abandon"
a:="学习"
fmt.Println(len(a))
b:="abandon"
fmt.Println(b[0])
c:=b[:2]
fmt.Println(c)
fmt.Println(c+a+b)
//6
//97
//ab
//ab学习abandon
go 源文件总以 utf-8 编码,每个字符占 1-4 个字节,可以用码点值*表示 Unicode 字符,所以字符串就是码点序列
Unicode仅仅只是一个字符集,规定了符号对应的二进制代码,至于这个二进制代码如何存储则没有任何规定,utf-8等实现了这个规定
可以通过[]rune 将字符串转换为其对应的码点序列,并且转换回字符串
a:="abandon世界"
b:=[]rune(a)
fmt.Printf("%x\n",b)
fmt.Println(string(b))
//[61 62 61 6e 64 6f 6e 4e16 754c]
//abandon世界
通过 range 对字符串遍历,它隐式对字符串进行了解码
for i,r :=range a{
fmt.Printf("%d %c %x\n",i,r,r)
}
//0 a 61
//1 b 62
//2 a 61
//3 n 6e
//4 d 64
//5 o 6f
//6 n 6e
//7 世 4e16
//10 界 754c
string可以与slice与byte相互转换,操作字符串的四个包
strings:字符串的搜索切割等
bytes:操作字符串 slice,及字符串增量构建
strconv:字符串与数字间的转换
unicode:判断字符串是数字及大小写转换等
原生字符串:用``反引号包裹,将完全输出字符串原*的格式
常量
go 中的常量一般无类型的,便于保存高精度的值,可以隐式或显示转换为其它类型
常量定义
const a=0
const(
e=2.71
pi=3.14
)
常量生成器
const(
b=iota
c
d
)
fmt.Println(b,c,d)
//0 1 2
数组
数组长度固定,slice 可长可短,一般不用数组
如果不同数组间元素可比较,且数组长度相同,那么数组可以直接比较
var a [2]int
b:=[2]int{1,2}
c:=[...]int{1,2}
fmt.Println(a[0],b[0],c[0])
fmt.Println("%t",b==c)
slice切片
切片是数组的“描述符”,切片的底层是数组,切片保存它指向的数组中元素的指针,长度和容量。长度是切片本身的长度,容量为指向元素到数组末尾的长度。
创建切片s := make([]int, 5)
数组的切片化u[low:high](u为一个数组)
go中数组变量表示整个数组,不是c中那样为指向数组的第一个元素。所以函数传递数组一般使用切片
切片是动态扩容的,但是使用append直到达到底层数组的容量界限,该切片就会与原数组解绑
使用append时,如果要扩容时会重新分配底层数组,并将原*元素复制
如下图所示,Q2与summer是months数组上的两个slice,其中len,cap的概念如图所示

slice 在初始化时可以不指定大小,也可以通过 make 生成,第一个参数是 slice 的 len 长度,第三个参数是 cap 容量
a:=make([]string,2,4)
b:=[]int{1,2}
c:=[5]int{1,2,3,4,5}//一个数组
d:=c[:3]//数组上的slice
fmt.Println(b)
fmt.Println(a)
fmt.Println(d)
增加,复制与删除
func remove(slice []int ,i int)[] int{
copy(slice[i:],slice[i+1:])//将i之后的元素复制到i处
return slice[:len(slice)-1]
}
func main() {
a:=[]int{1,2,3,4,5,6,7,8,9}
a=append(a,10)
fmt.Println(a)
//删除第3个元素
a=remove(a,2)
fmt.Println(a)
}
//[1 2 3 4 5 6 7 8 9 10]
//[1 2 4 5 6 7 8 9 10]
map
map 是对散列表的引用,map 的键必须是相同类型,值必须是相同类型
创建初始化,添加和删除
a:=map[int]string{1:"hello",2:"hi",3:"dog",4:"cat"}
fmt.Println(a)
b:=make(map[int]string)
b[2]="2"
b[1]="1"
fmt.Println(b)
delete(b,2)
fmt.Println(b)
排序
按键值排序,需要使用 sort
a:=map[int]string{5:"mouse",1:"hello",2:"hi",3:"dog",4:"cat"}
var keyInSort []int
for key:=range a{
keyInSort=append(keyInSort,key)
}
sort.Ints(keyInSort)
for _,key:=range keyInSort{
fmt.Println(a[key])
}
查找
查找 map 中是否有键,如果存在,value 为键值,ok 为 true,如果不存在 value 为类型对应的零值,ok 为 false
a := map[int]string{5: "mouse", 1: "hello", 2: "hi", 3: "dog", 4: "cat"}
if value, ok := a[5]; !ok {
fmt.Println("没有这个值")
}else{
fmt.Println(value)
}
结构体
结构体定义和初始化
type people struct{
name string
age int
next *people
}
p:=people{name:"小明",age:10}
fmt.Println(p.name)
结构体嵌套
结构体不能包含自己类型的结构体,但可以使用如上所示,使用指针
在嵌套其它类型是,可以使用匿名成员,这样直接通过.号就能访问嵌套的结构体的值,但是在初始化时会麻烦点
type point struct{
x int
y int
}
type circle struct{
point
radius int
}
c:=circle{point:point{x:2,y:3},radius:4}
fmt.Println(c.x)
函数
声明
func name(parameter-list)(result-list){
body
}
形参收到的是每个实参的副本,所以修改形参不会影响调用者提供的实参,但是如果传入的是引用类型:指针,slice,map,函数,通道就会影响
返回值
返回值可以不指定变量名,但是如果指定了,在返回时只用写return
func year2Month(age int) (month int, day int){
month=age*12
day=age*356
return
}
函数变量
函数变量可以赋给变量,或者从其它函数返回
注意作用域规则陷阱:在循环里创建的函数变量共享相同的变量
func add1(v int) int{return v+1}
func eachAdd1(f func(v int)int,s []int){
for p,i:= range s{
s[p]=f(i)
}
}
func main() {
var f func(int) int//定义了函数变量f
f=add1//用函数add1为f赋值
a:=[]int{1,2,3,4,5}
eachAdd1(f,a)//函数变量作为参数传递到函数中
fmt.Println(a)
}
匿名函数
匿名函数可以使用外层函数的变量(go支持的闭包特性)
func add1() func()int{
var x int
return func()int{
x++
return x
}
}
func main() {
f:=add1()
fmt.Println(f())//1
fmt.Println(f())//2
fmt.Println(f())//3
fmt.Println(f())//4
f=add1()
fmt.Println(f())//1
fmt.Println(f())//2
}
延迟函数
在调用函数前加defer使得函数在return之后才才执行
func timeNow() {
fmt.Println(time.Now())
}
func main() {
fmt.Println("程序开始")
defer timeNow()
fmt.Println("程序结束")
}
//程序开始
//程序结束
//2022-08-27 14:18:58.4305243 +0800 CST m=+0.001673801
在函数开始和结束时分别调用
可以用于输出调试信息,保存旧值并恢复等作用
func timeNow() func(){
start:=time.Now()
fmt.Println("函数开始")
return func(){
fmt.Println(time.Since(start))
fmt.Println("函数结束")
}
}
func main() {
defer timeNow()()
time.Sleep(time.Second*10)
}
//函数开始
//10.0110625s
//函数结束
变长参数函数
func s(in ...int) {
}
在函数内in就相当于一个[]int类型
应用:在功能选项模式中使用
type Computer struct {
CPU int
GPU int
Memory int
}
type Option func(*Computer)
func NewComputer(option ...Option) *Computer {
// 默认值
c:=&Computer{
CPU:0,
GPU:0,
Memory:0
}
// 根据传入的操作修改配置
for _,op:=range option {
option(h)
}
return c
}
// 一些配置操作
func optCPU(cpu int) Option {
return func(c *Computer) {
c.CPU = cpu
}
}
//等等
方法
只需要在函数名前加入类型定义,任何定义都可,但是不能是指针和接口类型(相当于类的成员函数)
type Point struct{X,Y int}
func (p Point)show(){
fmt.Println(p.X,p.Y)
}
func main() {
var p=Point{1,2}
p.show()
}
不能指针,不能的是本身是指针的类型
//错误
type Point *struct{X,Y int}
func (i Point)show(){
}
//正确
type Point struct{X,Y int}
func (i *Point)show(){
}
方法本质是一个以方法所绑定的类型实例为第一个参数的函数
方法变量与方法表达式
type Point struct{X,Y int}
func (p Point)sub(q Point) float64{
return math.Pow(float64(p.X-q.X), 2) + math.Pow(float64(p.Y-q.Y), 2)
}
func main() {
var p=Point{1,1}
var q=Point{4,5}
//方法变量
f:=p.sub
result:=f(q)
fmt.Println(result)
//方法表达式
e:=Point.sub
result=e(p,q)
fmt.Println(result)
}
接口
如果某个类型的方法的集合是接口类型的方法的集合的超集,则该类型实现了该接口
如,fmt有控制输出的机制,各类型可以实现这个接口*控制自己的输出,接口为
type Stringer interface{
Sting() string
}
如Point类型如果输出的话,它默认输出{2 3}
type Point struct{X,Y int64}
func main() {
p:=Point{2,3}
fmt.Println(p)
}
我们自己为Point实现这个接口,控制它输出自己X+Y的和,这里输就会是5
type Point struct{X,Y int64}
func (p Point) String() string{
return strconv.FormatInt(p.X+p.Y,10)
}
func main() {
p:=Point{2,3}
fmt.Println(p)
}
接口可以组合形成新的接口,如Reader与Writer都是接口
type ReadWriter interface{
Reader
Writer
}
接口在运行时表示为eface(空接口)或iface(非空接口),两个类型都由指向实际数据的指针和类型信息结构组成
将值类型转为引用类型为装箱,将任意类型赋给接口也是装箱操作,该过程会复制一份原类型的数据
当函数处理未知类型数据时可以传入空接口,但尽量不要使用
嵌入
垂直组合:
接口嵌入接口
结构体嵌入接口
结构体嵌入结构体(继承的实现)
水平组合:
使用接口作为水平组合的连接
接受接口类型的函数和方法
包裹函数
适配器
可以通过已有类型定义新类型
基于接口类型定义的新类型与原接口类型的方法集合是一致的
基于非接口类型定义的新类型不会得到原类型的方法集合
一些内置接口
实现sort.Interface*排序,只要实现Len(返回序列长度),Less(定义比较方法),Swap(定义交换方法)三种方法
type Student struct{
name string
grade int
}
type byName []*Student
func (b byName)Len() int{
return len(b)
}
func(b byName)Less(i,j int)bool{
return b[i].name<b[j].name
}
func(b byName)Swap(i,j int){
b[i],b[j]=b[j],b[i]
}
type byGrade []*Student
func (b byGrade)Len() int{
return len(b)
}
func(b byGrade)Less(i,j int)bool{
return b[i].name>=b[j].name
}
func(b byGrade)Swap(i,j int){
b[i],b[j]=b[j],b[i]
}
func main() {
studentList:=[]*Student{
{"小明",23},
{"纳兰性德",70},
{"王子",63},
}
//安照姓名排
sort.Sort(byName(studentList))
for i,s:=range studentList{
fmt.Printf("%v\t%-8v\t%v\t\n",i,s.name,s.grade)
}
//按照成绩排
sort.Sort(byGrade(studentList))
for i,s:=range studentList{
fmt.Printf("%v\t%-8v\t%v\t\n",i,s.name,s.grade)
}
//按照程序反排
sort.Sort(sort.Reverse(byGrade(studentList)))
for i,s:=range studentList{
fmt.Printf("%v\t%-8v\t%v\t\n",i,s.name,s.grade)
}
}
类型断言
express.(type)
用*识别错误,识别特性
并发同步
goroutine
go的并发线程并不是由操作系统线程*管理的,而是原生实现了goroutine,由Go在运行时负责调度,调度采用G-P-M模型
程序只有一个主goroutine*调用main函数,新的goroutine通过go语句创建
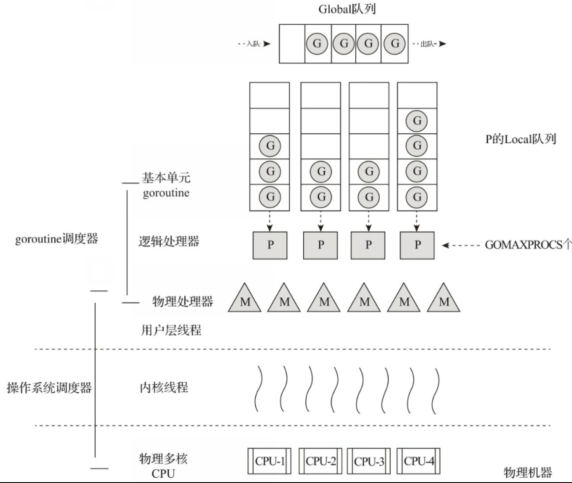
goroutine与操作系统线程区别:
- goroutine栈可以增大缩小
- 操作系统线程由时钟触发调度,需要上下文切换,goroutine由go语言结构触发调度,不需要切换到内核环境
服务端
func handleConn(c net.Conn){
defer c.Close()
for{
_,err:=io.WriteString(c,time.Now().Format("15:04:05\n"))
if err!=nil{
return
}
time.Sleep(1*time.Second)
}
}
func main() {
listener,err:=net.Listen("tcp","localhost:8000")
if err!=nil{
log.Fatalln(err)
}
for{
conn,err:=listener.Accept()
if err!=nil{
log.Println(err)
continue
}
go handleConn(conn)
}
}
客户端
package main
import (
"io"
"log"
"net"
"os"
)
func main(){
conn,err:=net.Dial("tcp","localhost:8000")
if err!=nil{
log.Fatalln(err)
}
defer conn.Close()
mustCopy(os.Stdout,conn)
}
func mustCopy(dst io.Writer,src io.Reader){
if _,err:=io.Copy(dst,src);err!=nil{
log.Fatalln(err)
}
}
通道
传统的是基于共享内存的模型,go中还实现了基于CSP通信进程顺序模型的channel。CSP模型中,各个进程是独立运行的,它们通过发送和接收消息*进行通信。CSP模型的基本元素包括进程、通道和消息。共享内存的模型强调并发进程之间通过共享内存*进行通信和同步,需要采取合适的同步机制*保证数据的一致性和互斥访问,否则可能出现竞态条件
通道是两个goroutine之间的通信机制,每个通道有具体的类型,如chan intint 类型的通道
创建无缓冲通道(同步通道)ch:=make(chan int)//ch的类型为chan int
创建缓冲通道,容量为3ch:=make(chan int,3)
向通道发送数据xch<-x
从通道接收数据到x中x=<-ch
关闭通道close(ch)
获取通道容量cap(ch)
获取通道中元素个数len(ch)
只接收通道作为参数 <-chan
只发送通道作为参数 chan<-
ch1:=make(chan int)
ch2:=make(chan int)
go func(){
for x:=0;x<=100;x++ {
ch1 <- x
}
close(ch1)
}()
go func(){
for x:=range ch1{
ch2<-x*x
}
close(ch2)
}()
for x:=range ch2{
fmt.Println(x)
}
多路复用
使用select对多个通道进行操作,channel与select结合可以实现超时机制,心跳机制,利用default避免阻塞
abort:=make(chan struct{})
go func(){
os.Stdin.Read(make([]byte,1))
abort<- struct {}{}
}()
tick:=time.Tick(1*time.Second)
for{
select{
case<-tick:
fmt.Println(<-tick)
case<-abort:
fmt.Println("结束")
return
default:
//fmt.Println("等待中")
}
}
并发读取文件
var sema =make(chan struct{},20)
func dirents(dir string) []os.FileInfo{
sema<-struct{}{}
defer func(){<-sema}()
entries,err:=ioutil.ReadDir(dir)
if err!=nil{
return nil
}
return entries
}
func walkDir(dir string,n *sync.WaitGroup,filename chan string){
defer n.Done()
for _,entry:=range dirents(dir){
if entry.IsDir(){
n.Add(1)
go walkDir(filepath.Join(dir, entry.Name()),n,filename)
}else{
filename<-entry.Name()
}
}
}
func main() {
roots:=[]string{"D:\\"}
var n sync.WaitGroup
filename:=make(chan string)
for _,root:=range roots{
n.Add(1)
go walkDir(root,&n,filename)
}
go func() {
n.Wait()
close(filename)
}()
tick:=time.Tick(1*time.Second)
var nfiles int64
loop:
for {
select {
case <-tick:
fmt.Printf("已读取文件数%d", nfiles)
case name, ok := <-filename:
if !ok {
break loop
}
nfiles++
fmt.Println(name)
}
}
}
聊天
type client chan<-string
var(
entering=make(chan client)
leaving=make(chan client)
message=make(chan string)
)
func broadcaster() {
clients:=make(map[client]bool)
for{
select{
case msg:=<-message:
for cli:=range clients{
cli<-msg
}
case cli:=<-entering:
clients[cli]=true
case cli:=<-leaving:
delete(clients,cli)
close(cli)
}
}
}
func handleConn(conn net.Conn){
ch:=make(chan string)
go clientWriter(conn,ch)
who:=conn.RemoteAddr().String()
ch<-"你"+who+"已上线\n"
message<-who+"已上线\n"
entering<-ch
input:=bufio.NewScanner(conn)
for input.Scan(){
message<-who+": "+input.Text()
}
leaving<-ch
message<-who+"已下线\n"
conn.Close()
}
func clientWriter(conn net.Conn,ch<-chan string){
for msg:=range ch{
fmt.Fprintf(conn,msg)
}
}
func main() {
listener,err:=net.Listen("tcp","localhost:8000")
if err!=nil{
fmt.Println(err)
}
go broadcaster()
for{
conn,err:=listener.Accept()
if err!=nil{
fmt.Println(err)
continue
}
go handleConn(conn)
}
}
func main(){
conn,err:=net.Dial("tcp","localhost:8000")
if err!=nil{
log.Fatalln(err)
}
go func() {
io.Copy(os.Stdout, conn)
log.Println("done")
}()
mustCopy(conn, os.Stdin)
conn.Close()
}
func mustCopy(dst io.Writer,src io.Reader){
if _,err:=io.Copy(dst,src);err!=nil{
log.Fatalln(err)
}
}
互斥锁
除了通道,go也有传统的锁,在sync包中实现
sync.Mutex,相当于一个容量为1的通道,通过获取令牌和释放令牌保证同一时间最多只有一个goroutine访问共享变量
var mu sync.Mutex
mu.Lock()
mu.RUnlock()
多读单写锁
var mu sync.RWMutex
mu.RLock()
mu.RUnlock()
一次性初始化锁
它不仅是一个互斥锁,还定义了一个布尔值,开始布尔值为假,第一次调用会将其设置为真,并且进行初始化操作
var loadIconsOnce sync.Once
loadIconsOnce.Do(初始化函数)
条件变量 sync.Cond
sync.Once实现单例模式
并发的重复抑制的非阻塞缓存例子
pow是一个要记忆的函数,通过Memo可以保存每次函数f(这里也就是pow)的结果值,当之后有相同调用时不用运行函数,就可以直接从保存的结果中取出值
func pow(x int)(result int){
time.Sleep(time.Second*1)
return x*x
}
type entry struct{
res int
ready chan struct{}
}
type Func func(key int)int
type Memo struct {
f Func
cache map[int] *entry
mu sync.Mutex
}
func New(f Func) *Memo{
return &Memo{f:f,cache: make(map[int]*entry)}
}
func(memo *Memo) Get(key int)*entry{
memo.mu.Lock()
e:=memo.cache[key]
if e==nil{
e=&entry{ready:make(chan struct{})}
memo.cache[key]=e
memo.mu.Unlock()
e.res=memo.f(key)
close(e.ready)
}else{
memo.mu.Unlock()
<-e.ready
}
return memo.cache[key]
}
func main() {
m:=New(pow)
value:=[12]int{1,2,3,4,5,6,1,3,5,7,9,9}
var n sync.WaitGroup
for _,i:=range value{
n.Add(1)
go func(j int){
start:=time.Now()
res:=m.Get(j)
fmt.Printf("%d %s %d\n",j,time.Since(start),res.res)
n.Done()
}(i)
}
n.Wait()
}
在New时,相当于新建了一个Memo实例,并运行了server这个监管goroutine
在server中,对每个请求查询缓存,如果缓存命中,通过deliver中ready通道广播,如果没有命中,通过call得到结果,放入缓存,再通过deliver中ready通道广播
每一次执行函数,通过Get构造请求,等待server处理,最后得到server处理的结果
func pow(x int)(result int){
time.Sleep(time.Second*1)
return x*x
}
type entry struct{
res int
ready chan struct{}
}
type request struct{
key int
response chan<- entry
}
type Func func(key int)int
type Memo struct {requests chan request}
func New(f Func) *Memo{
memo:=&Memo{requests: make(chan request)}
go memo.server(f)
return memo
}
func(memo *Memo) Get(key int)*entry{
response:=make(chan entry)
memo.requests<-request{key,response}
res:=<-response
return &res
}
func(memo *Memo)server(f Func){
cache:=make(map[int]*entry)
for req:=range memo.requests{
e:=cache[req.key]
if e==nil{
e=&entry{ready:make(chan struct{})}
cache[req.key]=e
go e.call(f,req.key)
}
go e.deliver(req.response)
}
}
func(e *entry)call(f Func,key int){
e.res=f(key)
close(e.ready)
}
func(e *entry)deliver(response chan<-entry){
<-e.ready
response<-*e
}
func main() {
m:=New(pow)
defer close(m.requests)
value:=[12]int{1,2,3,4,5,6,1,3,5,7,9,9}
var n sync.WaitGroup
for _,i:=range value{
n.Add(1)
go func(j int){
start:=time.Now()
res:=m.Get(j)
fmt.Printf("%d %s %d\n",j,time.Since(start),res.res)
n.Done()
}(i)
}
n.Wait()
}
原子操作
atomic包:主要同步一个整型变量或自定义类型变量,对临界区数据同步还是使用sync
并发模式
创建模式
func f() chan T {
c:=make(chan T)
go func(){
}()
return c
}
int main() {
c := f()
}
//通过通道建立两个goroutine之间的联系
退出模式:分离模式,join模式,通知等待模式(可以通知goroutine退出,不是被动等待)
管道模式:扇出模式,扇入模式
超时取消模式:使用go context包,在超时或不需要时取消原有操作
错误处理
构造错误值
err:= errors.New("error string") // 返回errors.errorString类型
err1 = fmt.Errorf("%d", i)
errWrap = fmt.Errorf("%w", err) // 返回fmt.wrapError类型
透明错误处理策略:完全不关心错误的上下文,一有错误就立马进入唯一处理路径
哨兵模式:根据返回的错误信息,选择不同的路径(可以通过errors.Is判断错误值是否与一个error类型变量相同)
错误值类型检视策略:利用类型断言或类型选择判断错误值与自定义错误类型是否相同,或使用errors.As
错误行为特征检视策略:将错误类型共有行为抽象为接口,之后通过返回错误值是否为接口判断选择路径
网络编程
网络IO模型
- 阻塞
- 非阻塞(之后通过轮询查询数据是否就位)
- IO多路复用(也是非阻塞,只不过不轮询,而是采用事件通知的方式,基于select/poll)
- 异步IO(上述同步方式等数据准备好后需要自己复制数据自己调用函数处理,而异步在数据准备好后将数据复制到用户空间,再调用函数处理)
tcp编程
服务端客户端读写
func handleConn(c net.Conn) {
defer c.Close()
for {
buffer := make([]byte, 100)
n, err := c.Read(buffer)
if err != nil {
fmt.Println("accept err:", err)
return
}
fmt.Printf("read %d byte content is %s\n",n,string(buffer[:n]))
}
}
func main() {
l, err := net.Listen("tcp", ":9999")
if err != nil {
fmt.Println("listen err:", err)
return
}
defer l.Close()
for {
c, err:= l.Accept()
if err != nil {
fmt.Println("accept err:", err)
return
}
go handleConn(c)
}
}
func main() {
c, err := net.Dial("tcp", ":9999")
if err != nil {
fmt.Println("listen err:", err)
return
}
defer c.Close()
c.Write([]byte("hello world"))
}
http编程
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "hello world\n")
})
http.ListenAndServe(":8888", nil) // https使用ListenAndServeTLS
}
time包
time.Now返回当前时间,由一个结构体time.Time,结构体包含挂钟时间,单调时间和时区
时间比较采用Equal
使用Before After比较时间先后关系
并能通过Sub运算返回time.Duration类型的纳秒值(基于这个函数还有Since与Until)
格式化输出采用助记符而不是类似“%Y-%M”
一次性定时器的创建,三种方法
func main() {
_ = time.AfterFunc(1*time.Second, func() {
fmt.Println("afterfunc timer")
})
select {
case <-time.After(2 * time.Second):
fmt.Println("After timer")
}
Timer3 := time.NewTimer(3 * time.Second)
select {
case <-Timer3.C:
fmt.Println("NewTimer timer")
}
}
Stop停止定时器
Reset重置定时器
信号处理
收到信号三种处理方式:
- 忽略信号
- 执行系统默认处理
- 执行自定义处理
服务端进程一般以守护进程运行,需要系统信号执行退出操作,但是如果采用系统默认退出,可能有一些尚未保存的信息丢失,所以采用自定义处理
使用os/signal包
func Notify(c chan<- os.Signal, sig ...os.Signal)
sig为想要捕获的信号
c为捕获后放入的channel,用于通知用户
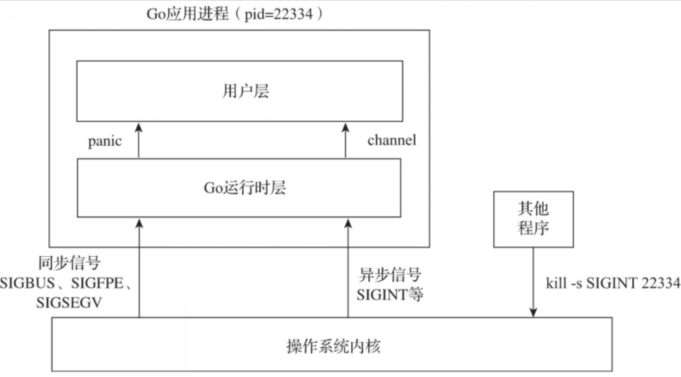
go捕获的信号
- 同步信号:一些bug引起的信号,需要转为panic立马处理
- 异步信号:捕获后放入channel等待用户处理
- 不能捕获的信号:由于操作系统限制不能捕获:SIGKILL SIGSTOP
http服务退出例子
func main() {
var wg sync.WaitGroup
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "hello world\n")
})
var srv = http.Server{
Addr:"localhost:8888",
}
wg.Add(2)
srv.RegisterOnShutdown(func() {
// 退出时清理资源
wg.Done()
})
go func(){
quit:=make(chan os.Signal, 1)
signal.Notify(quit, syscall.SIGINT, syscall.SIGTERM, syscall.SIGQUIT, syscall.SIGHUP)
<-quit
timeoutCtx, cf := context.WithTimeout(context.Background(), time.Second * 5)
defer cf()
var done = make(chan struct{}, 1)
go func(){
if err:= srv.Shutdown(timeoutCtx); err!=nil {
//Shutdown err
}
done<- struct{}{}
wg.Done()
}()
select {
case <-timeoutCtx.Done():
// timout
case <- done:
}
}()
err := srv.ListenAndServe()
if err != nil {
}
wg.Wait()
}
unsafe
go是类型安全的,不支持隐式类型转换,不支持指针运算,但为了兼顾系统编程问题,使用unsafe
Sizeof获取类型大小
Alignof获取内存地址对齐系数
Offsetof获取结构体中字段的地址偏移量
安全使用模式
- *T1->unsafe.Pointer->*T2 需保证Alignof(T1)>=Alignof(T2)
例
f float64
*(*uint64)(unsafe.Pointer(&f))
reflect.SliceHeader与reflect.StringHeader必须以这种模式构建,否则sliceHeader.Data可能被GC
- unsafe.Pointer->uintptr
uintptr(unsafe.Pointer(&x))
- 模拟指针运算unsafe.Pointer(uintptr(unsafe.Pointer(&b)) + offset)
这个转化过程需要在一个表达式中完成,否则b可能因为GC而失效 - 调用syscall.Syscall系列函数时指针类型到uintptr类型参数的转换
- 将reflect.Value.Pointer或reflect.Value.UnsafeAddr转换为指针
反射
反射是程序在运行时访问检测和修改它本身状态或行为的能力,go的反射依赖于interface{}
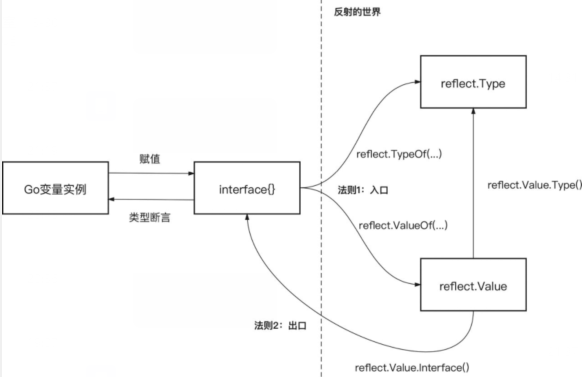
通过ValueOf得到Value对象,可以得到实例的值信息
通过TypeOf得到Type对象,可以得到实例的类型信息
通过函数类型或包含方法的类型实例反射的Value对象,可以使用Call调用函数或方法
Value.Interface是ValueOf的逆过程
如果反射对象以值形式传递给ValueOf后,再对反射对象信息进行修改是无意义的,被禁止
可以通过CanSet CanAddr CanInterface判断反射对象是否可设置,可寻址,可恢复为interface{}
与c的互操作
C代码直接以注释形式出现在go源码中
之后紧接着导入名为C的包
之后使用C包调用C代码中定义的函数
在go中链接外部C库
使用#cgo指示符
但是在go中使用c可能导致调用开销增加,线程量暴涨,失去跨平台交叉编译的能力
测试
go原生支持测试,利用go test命令和testing包
包内测试(白盒)
测试代码与源代码在同一个包内,以*_test.go命名
优点:较高的测试覆盖率(因为可以访问包未导出符号)
缺点:需要随着源代码改变而经常改变,循环引用的问题
包外测试(黑盒)
测试代码放在*_test包中
缺点:只能测试包暴露的“API”
可以在待测试包中使用export_test.go在其中暴露一些符号,以供包外测试
测试代码组织模式:
平铺
xUnit家族
测试固件
go测试代码编写逻辑:给定输入,比较被测函数返回与预期是否一样,不一样则使用testing包输出错误信息,使用Errorf不会中断当前执行,使用Fatalf会中断当前执行
测试的外部数据统一放在testdata文件夹下
将输出数据写入.golden文件可以方便的对比数据处理前后差异
当在测试中依赖外部组件或服务时,可以使用以下几种概念模拟
fake:用函数模拟假的组件或服务
stub
mock
模糊测试:自动或半自动为程序提供随机数据,*检测程序是否有bug
使用go-fuzz
通过创建fuzz.go文件并编写Fuzz函数
如果要测试很多功能,可以在fuzztest中建立多个测试单元,每个单元包含存放语料的目录corpus,包含Fuzz函数的fuzz.go,手工生成初始语料的目录gen和之下的代码main.go
性能测试
可以在*test.go中通过编写Benchamark*的函数测试
测试可以采用串行或并行执行的方式
性能比较工具 benchstat
对性能瓶颈剖析
使用pprof expvar
go 调试工具Delve
go 陷阱
短变量
同一个代码块中,使用多变量的短变量声明语句重新声明已经声明过的变量时,只会对其重新赋值
var a int = 5
a, b := 10, 20 //Yes
在不同代码块层次使用多变量的短声明会带*变量遮蔽问题
nil
零值可用,不需要初始化,声明后就可使用
sync.Mutex
bytes.Buffer
var strs []string = nil
strs = append(strs, "hello")
值为nil的接口类型不总是等于nil
因为接口包含两部分,一部分为类型信息,一部分为值信息
string的零值是"",判断字符串为空是将len(s) 与0比较
for range
对字符串遍历得到的是各字符的码点
对map遍历是随机的
是在副本上遍历
迭代变量是重用的
for v:= range a {
go func(){
//v是一样的
}()
}
//解决
for v:= range a {
go func(v){
//v是一样的
}(v)
}
切片
新切片与原切片共享底层存储,如果原切片占用较大内存,新切片的存在又使原切片内存无法释放
使用copy建立独立存储空间
切片支持自动扩容,一旦扩容,新切片与原切片不会共用同一个底层存储
goroutine
所有goroutine都会随着main goroutine退出而退出
如果任何goroutine出现panic,如果没有及时捕获,整个程序都退出,所以采用
defer func(){
if e := recover(); e != nil {
fmt.println(e)
}
}()
go中break会跳出最内层的switch select for代码块
net/http
需要手动关闭resp.Body
resp, err := http.Get(url)
defer resp.Body.Close()
这样http客户端才会重用带有keep-alive的http连接
go的垃圾回收机制
https://www.cnblogs.com/cxy2020/p/16321884.html
Golang v1.3之前采用传统采取标记-清除法,需要STW,暂停整个程序的运行。
在v1.5版本中,引入了三色标记法和插入写屏障机制,其中插入写屏障机制只在堆内存中生效。但在标记过程中,最后需要对栈进行STW。
在v1.8版本中结合删除写屏障机制,推出了混合屏障机制,屏障限制只在堆内存中生效。避免了最后节点对栈进行STW的问题,提升了GC效率

 浙公网安备 33010602011771号
浙公网安备 33010602011771号