
Python编程笔记二进制、字符编码、数据类型
bin()
在python中可以用bin()内置函数获取一个十进制的数的二进制
计算机容量单位
8bit = 1 bytes 字节,最小的存储单位,1bytes缩写为1B
1KB = 1024B
1MB = 1024KB
1GB = 1024MB
1TB = 1024 GB
1PB = 1024 TB
1EB = 1024 PB
1ZB = 1024 EB
1YB = 1024 ZB
1BB = 1024 YB
二、字符编码
Unicode编码:国际标准字符集,它将世界的各种语言的每个字符定义个唯一的编码,以满足跨平台、跨语言的文本信息转换。Unicode(统一码、万国码)规定所有的字符和符号最少由16位来表示(2个字节),即2**16 = 65536.
UTF-8 ,是对Unicode编码的压缩优化,它不在使用最少2个字节,而是将所有的字符和符号分类,ascii码中的内容用1个字节来保存,欧洲的字符用2个字节来保存,东亚的字符用3个字节保存。
windows 系统中文版默认编码是GBK
MAC \Linux 系统默认编码是UTF-8
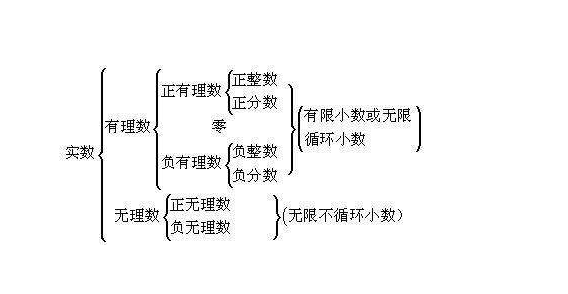
三、浮点数
浮点数是属于有理数中某特定子集的数的数字表示,在计算机中用以近似表示任意某个实数。包括整数和分数,包含有限小数和无线循环小数。
无限不循环的小数不是浮点数
整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的,而浮点数运算则可能有四舍五入的误差。
python默认的是小数点后16位的精度。但是这个精度越往后越不准,这个问题在其他语言中也存在。
四、列表
列表是一个数据的集合,集合里可以放任何的数据类型,可以对集合进行方便的增删查改
列表的功能
创建
直接用[]
用list方法
例子
li = ["nicholas",1]
li = list()
查询
通过索引值来取值
li = [1,2,a,4,5]
li[0]取第一个元素1
从右边开始取
li[-1]取出的是从右边的第一个5
index()返回从左到右数的遇到的第一个元素的索引值
count()统计某个元素在列表中的个数
切片
取出其中部分的元素
通过索引值来取
li = [1,2,3,4,5]
li[0:3] = [1,2,3]
取出从第0个元素到第二个元素,这里是前闭后开的区间
增加、修改
li = [1,2,3,4,5]
li.append("a")
在列表的最后追加一个元素“a”
li.insert(0,"b")
在列表的索引第0个位置插入元素“b”
insert的第一个参数规定了要插入的指定位置,第二个参数是插入的内容。
li[0] = 'a'
通过索引直接赋值修改
删除
li = [1,2,3,4,5]
li.pop()
删除某个值,并可以获取当前删除的值没有指定索引,默认删除最后一个元素
li.remove("3")
直接删除指定的元素
del li[0]
del li[1:3]
通过索引删除
例子
现有商品列表如下
products = [["iphone8",6888],["MacPro",14800],["小米6",2499],["Coffee",31],["Book",80],["Nike Shoes",799]]
要打印成如下格式
------------------------商品列表-----------------------
-
iphone8 6888
-
MacPro 14800
-
小米6 2499
-
Coffee 31
-
Book 80
-
Nike Shoes 799
参考答案
products = [["iphone8",6888],["MacPro",14800],["小米6",2499],
["Coffee",31],["Book",80],["Nike Shoes",799]]
for i,j in enumerate(products,0):
print("%s.%s %s"%(i,j[0],j[1]))
分析:这里用了enumerate()函数,列举了列表中的元素,这里的i代表的是下标,j代表的是元素。
五、hash
Hash,一般翻译为“散列”,也有直接音译为“哈希”,就是吧任意长度的输入,通过散列算法,变成固定长度的输出,该输出的就是散列值,这种转换就是一种压缩映射,也就是散列值的空间通常小于输入的空间,不同的输入可能会散列成相同的输出,这就是哈希冲突,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定的长度的消息摘要的函数。
特征:
hash值的计算过程是依据这个值的一些特征计算的,这就要求被hash值必须固定,因此被hash的值必须是不可变的
用途:
文件签名
md5加密
密码验证
六、字典
字典的for循环
例子
打印字典的key和value
第一种方式
dic = {"k1":"v1","k2":"v2","k3":"v3"}
for i in dic:
print(i,dic[i])
第二种方式
dic = {"k1":"v1","k2":"v2","k3":"v3"}
for i,v in dic.items():
print(i,v)
分析:这里的第一种方式更为高效,只用循环一次即可找到key和value的值
删除字典某个值的两种方式
例子
dic = {"k1":"v1","k2":"v2","k3":"v3"}
删除“k1":"v1"
第一种方式
dic = {"k1":"v1","k2":"v2","k3":"v3"}
dic.pop("k1")
print(dic)
第二种方式
dic = {"k1":"v1","k2":"v2","k3":"v3"}
del dic["k1"]
print(dic)
pop()方法
pop()方法可以指定返回值
如删除的键值对不存在,则可以指定返回值,与get()方法类似
例子
dic = {"k1":"v1","k2":"v2","k3":"v3"}
v = dic.pop("k5","no")
print(dic)
print(v)
输出结果
{'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}no
分析:这里用pop()方法删除一个不存在的键值对,如果直接写
pop("k5")会直接报错,但是指定返回值后可以执行。
增加键值对的方式
1、dic['new_key'] = 'new_value';
2、dic.setdefault(key, None) ,如果字典中不存在Key键,由 dic[key] = default 为它赋值;_
七、集合
集合是一个无序的,不重复的数据组合
集合的功能
a、去重、把一个列表变成集合,就自动去重
b、关系测试,测试两组数据之间的交集、差集、并集、交叉补集等关系
八、十六进制和二进制
十六进制和十进制的对应关系
十进制: 0--1 --2--3--4--5--6--7--8--9--10--11--12--13--14--15
十六进制:0--1 --2--3--4--5--6--7--8--9-- A-- B-- C-- D-- E-- F
十六进制和二进制的对应关系:

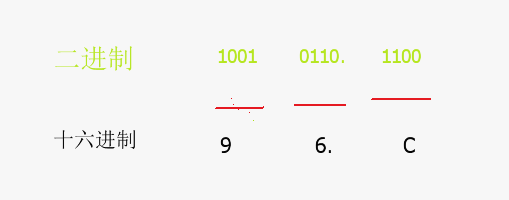
二进制转十六进制
二进制转换成十六进制的方法是,取四合一法,即从二进制的小数点为分界点,向左(或向右)每四位取成一位,
组分好以后,对照二进制与十六进制数的对应表,将四位二进制按权相加,得到的数就是一位十六进制数,然后按顺序排列,小数点的位置不变,最后得到的就是十六进制数
十六进制数的前缀是“0x”,后缀是“BH”
例子
二进制数 10010110.1100转换为十六进制数
将二进制数分为4个一组,从小数点开始向左向右分别开始取,每4个数一组,即
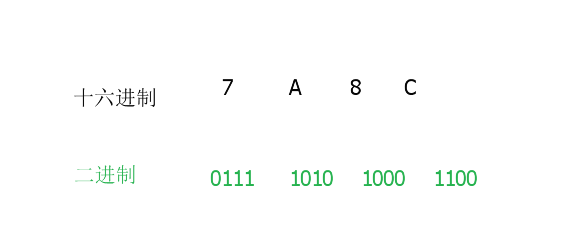
十六进制转二进制
十六进制转二进制方法就是一分四,即一个十六进制数分成四个二进制数,用四位二进制按权相加,最后得到二进制,小数点依旧就可以
例子
将十六进制数7a8c转为二进制数


 浙公网安备 33010602011771号
浙公网安备 33010602011771号