理解CUDA中的网格(Grid),线程块(Block)和线程(thread)
从硬件层面说起:

上图是采纳了Turing架构的TU102 GPU,它的特点如下:
-
6 GPC(图形处理簇)
-
36 TPC(纹理处理簇)
-
72 SM(流多处理器)
-
每个GPC有6个TPC,每个TPC有2个SM
-
4,608 CUDA核
-
72 RT核
-
576 Tensor核
-
288 纹理单元
-
12x32位 GDDR6内存控制器 (共384位)
单个SM的结构图如下:
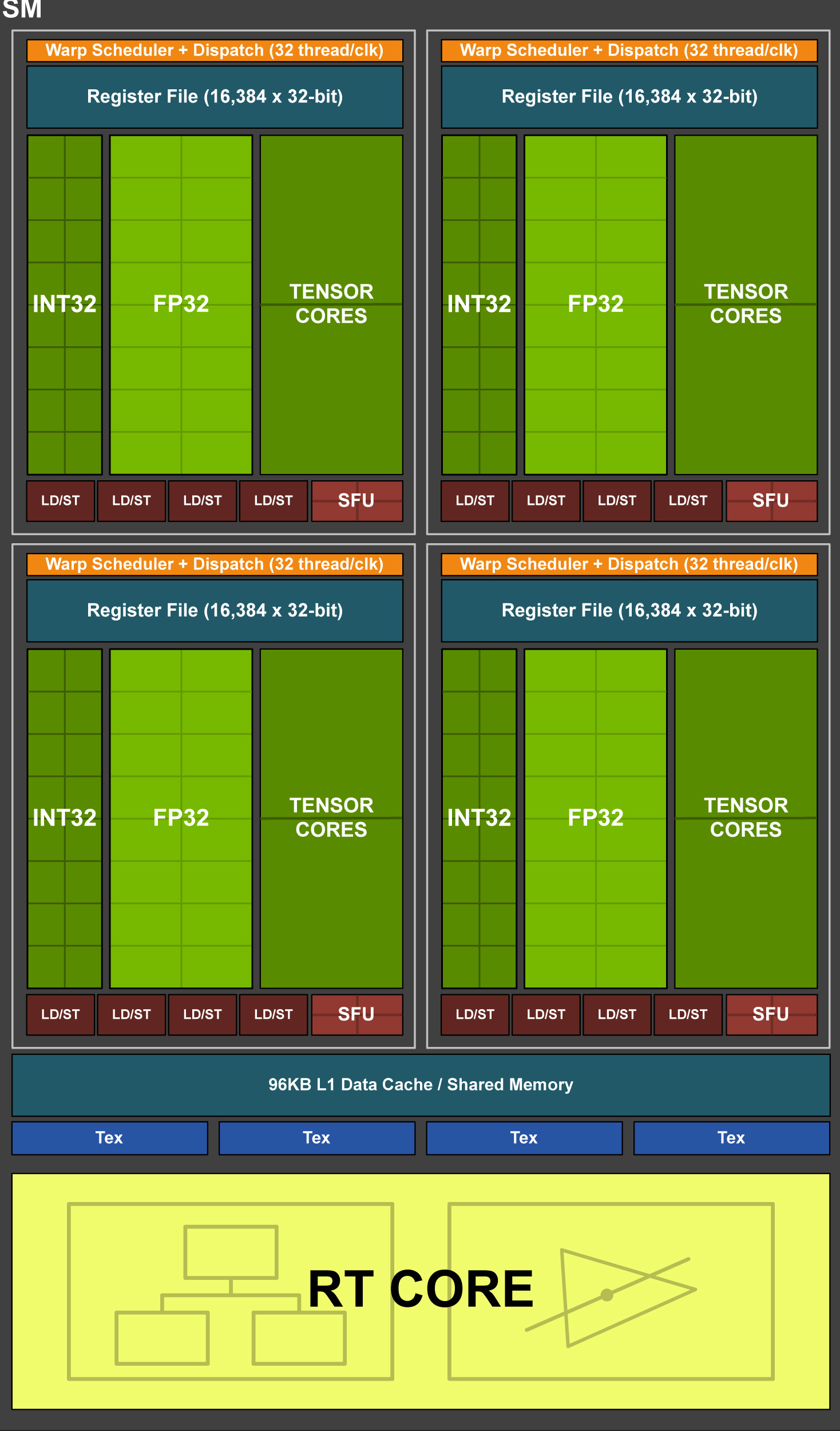
每个SM包含:
- 64 CUDA核
- 8 Tensor核
- 256 KB寄存器文件
重要概念:
Turing总体架构:TU102为例: 6个Graphics Processing Clusters(图形处理集群 -GPCs)(每个图形处理集群包含一个专用光栅引擎和6个TPC)> 36个Texture Processing Clusters(纹理处理集群-TPCs)(每个纹理处理集群包含2个SM)> 72个SM
SM(streaming multiprocessor):
1.Turing架构引入了新的SM体系架构。每个TPC包含2个SM,每个SM包含64个fp32核心和64个int32核心,这使得Turing可以并行执行fp32和int32运算。每个SM还包含8个混合精度的tensor core。
2.Turing的SM被划分为4个进程块,每个进程块包含16个fp32核心、16个int32核心、2个Tensor Cores、一个线程束调度器和一个调度单元,每个进程块还包含一个新的L0指令缓存和一个64KB寄存器。这4个进程块共享一个可自配置的96KB大小L1/共享内存区域。
3.Turing还改造了核心执行路径,相比之前的单一执行路径,Turing在执行混合fp算术指令如FADD、FMAD时为每个CUDA核心增加了另一个并行执行单元来并行执行整数运算和浮点数运算。
4.SM中的每个Tensor Core可以在每个时钟周期内执行高达64次fp16输入融合浮点乘加运算(FMA),8个Tensor Core这可以在每个时钟周期内执行总计512次fp16乘加运算,或1024次fp运算。Turing新引入的INT8精度模式在每个时钟周期内更是可以执行2048个整数运算。Tesla T4身为Turing第一个使用Turing架构的GPU,包含2560个CUDA核心和320个Tensor Cores,可实现130 TOPs(Tera Operations per second)的int8运算和高达260 TOPs的int4运算。
从软件层面说起:
对于CUDA的软件架构我们在逻辑上分为三个层次结构每个层次结构类型有三个维度(x,y,z),层次结构从小到大依次是Thread(线程),Block(线程块),Grid(网格)。
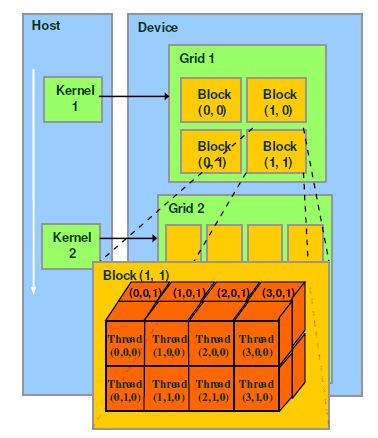
如图所示:相当于把GPU上的计算单元分为若干(2~3)个网格,每个网格包含若干(65535)个线程块,每个线程块包含若干(512)个线程。对于thread往右x增加,往下y增加往里z增加。Thread,block,gird的设定是方便程序员进行软件设计,组织线程的,是CUDA编程上的概念。
Grid,Block,thread都是线程的组织形式,最小的逻辑单位是一个thread,最小的硬件执行单位是thread warp,若干个thread组成一个block,block被加载到SM上运行,多个block组成一个Grid。
总而言之,一个kernel对应一个Grid,该Grid又包含若干个Block,Block内包含若干个thread。Grid跑GPU的时候,可能是独占一个GPU,也可能是多个kernel并发占用一个GPU。
block是常驻在SM上的,一个SM可能有一个或者多个Block,具体根据资源占用分析。
thread以wrap为单位被SM的scheduler发射到计算单元或者其它单元,如SFU,LD/ST unit执行相关操作,需要等待的wrap会被切出(依然是resident状态)(上下文的切换),以空出执行单元给其它warps。
软硬件对应关系:
GPU硬件上的并行性是由SM决定的,GPU中每个SM都被设计成支持数以百计的线程并行计算,并且每个GPU都包含了很多SM,所以GPU支持成百上千的线程并行执行。当一个kernel启动时,thread会被分配到这些SM中去进行运算。大量的thread可能会被分配到不同的SM,同一个Block的thread必然是在同一个SM中并行(SIMT)执行的。NVIDIA把32个threads组成一个warp(如果1个block中有512个thread也就是说有512/32=16个warp),warp是调度和运行的基本单元,warp中所有thread并行执行相同的指令(其实由于SIMT的特性允许thread有自己的执行路径这样会导致各个thread的执行结束时间并不一致,所以CUDA提供了cudaThreadSynchronize()来同步同一个Block的thread以保证在下一步处理之前,所有的thread都到达某个时间点)。一个warp需要占用一个SM运行,多个warp(16个warp)需要轮流进入SM,有SM的硬件warp schedule负责调度。
SIMT和SIMD(单指令多数据):CUDA是一种典型的SIMT架构(单指令多线程),SIMT是NVIDIA提出的GPU概念。两者都是通过将同样的指令广播给多个执行单元来实现并行。一个主要的不同就是SIMD要求所有的数组元素在一个统一的同步组里面同步执行,而SIMT允许线程们(32个)在一个warp中各自独立执行。
SIMT有三个SIMD没有的主要特征:1.每个thread拥有自己的指令计数器和地址计数器 2.每个thread拥有自己的状态寄存器 3.每个thread可以有自己的独立执行路径(不同于SIMD32是全部一样的执行路径)。
开发过程中程序员老爷们可以通过设定block的属性来告诉GPU硬件,我有多少个线程,这些线程怎么组织。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号