
数据库锁
MySQL中获取当前事件
now() 获取当前日期加事件 获得当前日期(date)函数:curdate() 获得当前时间(time)函数:curtime()
union
合并两次查找的结果,但是两次查找的字段数必须相同
union :表示去重复合并表
union ALL :表示不去重复合并表
数据库锁
当并发事务同时访问一个资源时,有可能导致数据不一致,因此需要一种机制来将数据访问顺序化,以保证数据库数据的一致性
数据库上的操作可以归纳为两种:读和写。
多个事务同时读取一个对象的时候,是不会有冲突的。同时读和写,或者同时写才会产生冲突。
开发中常见的两种锁
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block(阻塞)直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制.
注:要使用悲观锁,我们必须关闭mysql数据库的自动提交属性,因为MySQL默认使用autocommit模式,也就是说,当你执行一个更新操作后,MySQL会立刻将结果进行提交。关闭自动提交命令为:set autocommit=0;
设置完autocommit后,我们就可以执行我们的正常业务了。具体如下:

//0.开始事务 start transaction; //1.查询出数据信息 select * from ren where p_id='p001' for update; //2.修改当前人员信息 update ren set p_name='张1丰' where p_id='p001'; //3. 提交事务 commit;
在另外的查询页面执行:
select * from ren where p_id='p001' for update;
会发现当前查询会进入到等待状态,不会显示出数据,当上面的sql执行完毕提交事物后,当前sql才会显示结果.
上面的第一步我们执行了一次查询操作:select * from ren where p_id='p001' for update;
与普通查询不一样的是,我们使用了select…for update的方式,这样就通过数据库实现了悲观锁。此时在ren表中,id为p001的 那条数据就被我们锁定了,其它的事务必须等本注:需要注意的是,在事务中,只有SELECT ... FOR UPDATE 或LOCK IN SHARE MODE(共享锁) 同一笔数据时会等待其它事务结束后才执行,一般SELECT ... 则不受此影响。拿上面的实例来说,当我执行select * from ren where p_id='p001' for update;后。我在另外的事务中如果再次执行select * from ren where p_id='p001' for update;则第二个事务会一直等待第一个事务的提交,此时第二个查询处于阻塞的状态,但是如果我是在第二个事务中执行select * from ren where p_id='p001';则能正常查询出数据,不会受第一个事务的影响
注意: 悲观锁的确保了数据的安全性,在数据被操作的时候锁定数据不被访问,但是这样会带来很大的性能问题。因此悲观锁在实际开发中使用是相对比较少的
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁
使用乐观锁的两种方式:
1.使用数据版本(Version)记录机制实现,这是乐观锁最常用的一种实现 方式。何谓数据版本?即为数据增加一个版本标识,一般是通过为数据库表增加一个数字类型的 “version” 字段来实现。当读取数据时,将version字段的值一同读出,数据每更新一次,对此version值加一。当我们提交更新的时候,判断数据库表对应记录 的当前版本信息与第一次取出来的version值进行比对,如果数据库表当前版本号与第一次取出来的version值相等,则予以更新,否则认为是过期数 据。
2.乐观锁定的第二种实现方式和第一种差不多,同样是在需要乐观锁控制的table中增加一个字段,名称无所谓,字段类型使用时间戳 (datatime), 和上面的version类似,也是在更新提交的时候检查当前数据库中数据的时间戳和自己更新前取到的时间戳进行对比,如果一致则OK,否则就是版本冲突。
MySQL练习题
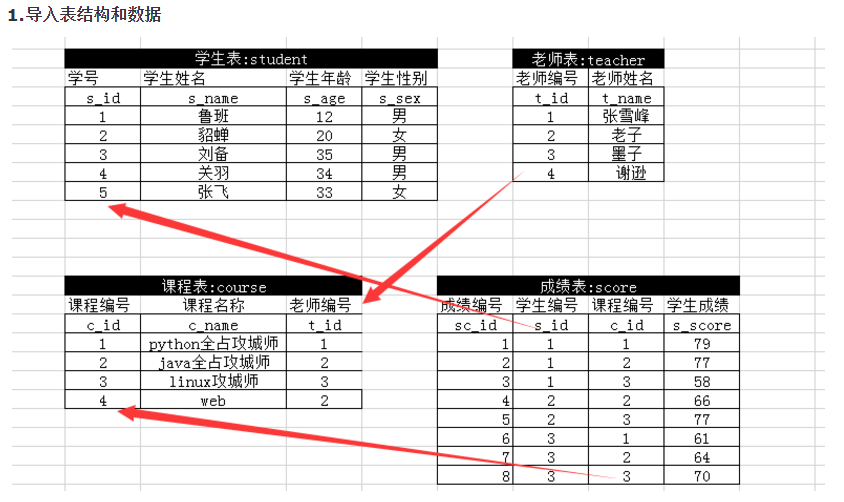
建表与插入数据
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for course
-- ----------------------------
DROP TABLE IF EXISTS `course`;
CREATE TABLE `course` (
`c_id` int(10) NOT NULL,
`c_name` varchar(255) DEFAULT NULL,
`t_id` int(11) DEFAULT NULL,
PRIMARY KEY (`c_id`),
KEY `t_id` (`t_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of course
-- ----------------------------
INSERT INTO `course` VALUES ('1', 'python', '1');
INSERT INTO `course` VALUES ('2', 'java', '1');
INSERT INTO `course` VALUES ('3', 'linux', '3');
INSERT INTO `course` VALUES ('4', 'web', '2');
-- ----------------------------
-- Table structure for score
-- ----------------------------
DROP TABLE IF EXISTS `score`;
CREATE TABLE `score` (
`sc_id` int(11) NOT NULL AUTO_INCREMENT,
`s_id` int(10) DEFAULT NULL,
`c_id` int(11) DEFAULT NULL,
`s_score` double DEFAULT NULL,
PRIMARY KEY (`sc_id`)
) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of score
-- ----------------------------
INSERT INTO `score` VALUES ('1', '1', '1', '79');
INSERT INTO `score` VALUES ('2', '1', '2', '78');
INSERT INTO `score` VALUES ('3', '1', '3', '35');
INSERT INTO `score` VALUES ('4', '2', '2', '32');
INSERT INTO `score` VALUES ('5', '3', '1', '66');
INSERT INTO `score` VALUES ('6', '4', '2', '77');
INSERT INTO `score` VALUES ('7', '4', '1', '68');
INSERT INTO `score` VALUES ('8', '5', '1', '66');
INSERT INTO `score` VALUES ('9', '2', '1', '69');
INSERT INTO `score` VALUES ('10', '4', '4', '75');
INSERT INTO `score` VALUES ('11', '5', '4', '75');
-- ----------------------------
-- Table structure for student
-- ----------------------------
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`s_id` varchar(20) NOT NULL,
`s_name` varchar(255) DEFAULT NULL,
`s_age` int(10) DEFAULT NULL,
`s_sex` char(1) DEFAULT NULL,
PRIMARY KEY (`s_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of student
-- ----------------------------
INSERT INTO `student` VALUES ('1', '鲁班', '12', '男');
INSERT INTO `student` VALUES ('2', '貂蝉', '20', '女');
INSERT INTO `student` VALUES ('3', '刘备', '35', '男');
INSERT INTO `student` VALUES ('4', '关羽', '34', '男');
INSERT INTO `student` VALUES ('5', '张飞', '33', '女');
-- ----------------------------
-- Table structure for teacher
-- ----------------------------
DROP TABLE IF EXISTS `teacher`;
CREATE TABLE `teacher` (
`t_id` int(10) NOT NULL,
`t_name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`t_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of teacher
-- ----------------------------
INSERT INTO `teacher` VALUES ('1', '张雪峰');
INSERT INTO `teacher` VALUES ('2', '老子');
INSERT INTO `teacher` VALUES ('3', '墨子');
典型题

-- 1、查询课程编号“001”比课程编号“002” 成绩高的所有学生的学号;
select s_score from score where c_id ='1';
select s_score from score where c_id ='2';
select A.s_id from (select s_score,s_id from score where c_id ='1') as A,
(select s_score,s_id from score where c_id ='2') B where A.s_id = B.s_id
and A.s_score > B.s_score;
-- 2、查询平均成绩大于60分的同学的学号和平均成绩;
select avg(s_score),s_id from score where s_id = 1 GROUP BY s_id having avg(s_score)>60
-- 3、查询所有同学的学号、姓名、选课数、总成绩;
select student.s_id,student.s_name,count(1) as'选课数',sum(s_score) from score,student where score.s_id = student.s_id GROUP BY s_id
-- 4查询含有"子"的老师的个数;
select count(t_id) from teacher where t_name like '%子%'
-- 5、查询没学过“老子”老师课的同学的学号、姓名;
select c.c_id from teacher t,course c where t.t_id = c.t_id and t.t_name ='老子';
select s_id from score s where s.c_id in
(select c.c_id from teacher t,course c where t.t_id = c.t_id and t.t_name ='老子');
select DISTINCT student.s_id,student.s_name from score,student where score.s_id not in (select s_id from score s where s.c_id in
(select c.c_id from teacher t,course c where t.t_id = c.t_id and t.t_name ='老子')
)
and student.s_id = score.s_id
-- 6、查询学过“001”并且也学过编号“002”课程的同学的学号、姓名;
select st.s_id,st.s_name from score s
inner join student st on s.s_id = st.s_id
where s.c_id = '1' or s.c_id ='2'
GROUP BY s.s_id HAVING count(s.s_id) = 2;
select st.s_id,st.s_name from (select * from score s where s.c_id = '1' union all select * from score s where s.c_id = '2' ) as lin
inner join student st on lin.s_id = st.s_id
GROUP BY lin.s_id HAVING count(lin.s_id) = 2
注意: union :表示去重复合并表
union ALL :表示不去重复合并表
-- 7、查询学过“老子”老师所教的所有课的同学的学号、姓名;
#1.先查询"老子"老师教哪些课程
#2.再查询哪些学生学习了这些课程
#3.再根据学生编号分组,如果分组后的个数 ="老子"老师所教授课程的个数,
# 则表示学过该老师所有课程.
select c_id from course c ,teacher t where c.t_id = t.t_id and t.t_name='张雪峰';
select st.s_id,st.s_name from score,student st where score.s_id = st.s_id and c_id in(
select c_id from course c ,teacher t where c.t_id = t.t_id and t.t_name='张雪峰')
GROUP BY s_id having count(sc_id) =
(select count(1) from course c ,teacher t where c.t_id = t.t_id and t.t_name='张雪峰')
-- 8、查询课程编号“2”的成绩比课程编号“1”课程低的所有同学的学号、姓名;
select a.s_id from
(select * from score where c_id ='1') a,
(select * from score where c_id ='2') b
where a.s_id = b.s_id and a.s_score < b.s_score;
-- 9、查询有课程成绩小于60分的同学的学号、姓名;
select DISTINCT st.s_id,st.s_name from student st,score sc where st.s_id = sc.s_id and sc.s_score < 60
-- 10、查询没有学全所有课的同学;
select count(1) from course c
select * from student st where s_id in (
select s_id from score sc GROUP BY sc.s_id HAVING count(1)
<> (select count(1) from course c)
)
-- 11、查询至少有一门课与学号为“002”的同学所学相同的同学的学号和姓名;
select sc.c_id from score sc,student st where sc.s_id =st.s_id and sc.s_id ='2'
select DISTINCT st.s_id,st.s_name from score sc,student st where
st.s_id =sc.s_id and sc.c_id in(select sc.c_id from score sc where sc.s_id ='2')
-- 12、查询学过 学号为“002”同学全部课程 的其他同学的学号和姓名;
select sc.c_id from score sc where sc.s_id = '2'
select st.s_id,st.s_name from score sc,student st where sc.s_id =st.s_id and st.s_id !='2' and sc.c_id in
(select sc.c_id from score sc where sc.s_id = '2')
GROUP BY sc.s_id HAVING count(1) = (select count(1) from score sc where sc.s_id = '2')
-- 14、把“score”表中“老子”老师教的课的成绩都更改为此课程的平均成绩;
UPDATE score set s_score = (select * from (select avg(sc.s_score) from teacher t,course c,score sc where c.t_id = t.t_id
and sc.c_id = c.c_id and t.t_name='张雪峰' ) ss)
where score.sc_id in( select * from
(select sc_id from teacher t,course c,score sc where c.t_id = t.t_id
and sc.c_id = c.c_id and t.t_name='张雪峰') aaa )
-- 13、查询和“002”号的同学学习的课程完全相同的,其他同学学号和姓名;
#1.找出与002学生学习课程数相同的学生(你学两门,我也学两门)
#2.然后再找出学过'002'学生课程的学生,剩下的一定是至少学过一门002课程的学生
#3.再根据学生ID进行分组,剩下学生数count(1) = 002学生所学课程数
select st.s_id,st.s_name from score sc1,student st where sc1.s_id = st.s_id and sc1.s_id in(
select sc.s_id from score sc GROUP BY sc.s_id HAVING count(1) = (select count(1) from score where s_id = '2')
) and sc1.c_id in(select c_id from score where s_id = '2')
GROUP BY sc1.s_id HAVING count(1) = (select count(1) from score where s_id = '2')
and sc1.s_id != '2'
-- 16、按平均成绩从高到低显示所有学生的“python”、“java”、“linux”三门的课程成绩,
-- 按如下形式显示: 学生ID,
-- python,
-- java,
-- linux,
-- 有效课程数,
-- 有效平均分
select sc1.s_id,
(select sc.s_score from score sc,course c where sc.c_id = c.c_id and c.c_name = 'python'
and sc1.s_id =sc.s_id ) as 'python',
(select sc.s_score from score sc,course c where sc.c_id = c.c_id and c.c_name = 'java'
and sc1.s_id =sc.s_id) as 'java',
(select sc.s_score from score sc,course c where sc.c_id = c.c_id and c.c_name = 'linux'
and sc1.s_id =sc.s_id) as 'linux',
count(1) as '课程数',
avg(sc1.s_score) as '平均分'
from score sc1 GROUP BY sc1.s_id
-- 18、查询"学生ID","各科平均成绩","及格率",并按各科平均成绩从低到高和及格率的百分数从高到低顺序
-- #3.计算及格率. 规则:及格课数/总科数 *100
-- case when .... then ...else ... end
select sc.s_id,avg(sc.s_score),
(sum(case when sc.s_score >= 60 then 1 else 0 end)/count(1) * 100 )AS aaa
from score sc GROUP BY sc.s_id order by avg(sc.s_score) asc, aaa desc
-- 20、统计列印各科成绩,各分数段人数,
-- 显示:课程ID,课程名称,[100-85],[85-70],[70-60],[ <60]
select sc.c_id,
c.c_name,
sum(CASE WHEN sc.s_score BETWEEN 85 and 100 then 1 else 0 end ) as '[100-85]',
sum(CASE WHEN sc.s_score BETWEEN 70 and 84 then 1 else 0 end ) as '[85-70]',
sum(CASE WHEN sc.s_score BETWEEN 60 and 69 then 1 else 0 end ) as '[70-60]',
sum(CASE WHEN sc.s_score <60 then 1 else 0 end ) as '[ <60] '
from score sc,course c where sc.c_id = c.c_id GROUP BY sc.c_id
-- 23、查询学生表中男生、女生人数
select
sum(case when s_sex ='男' then 1 else 0 end ) as '男',
sum(case when s_sex='女' then 1 else 0 end) as '女'
from student
-- 26、查询每门课程的平均成绩,结果按平均成绩升序排列,平均成绩相同时,按课程号降序排列
select c_id,avg(IFNULL(sc.s_score,0)) from score sc GROUP BY sc.c_id
order by avg(sc.s_score) asc , sc.c_id desc、
注意 ifnull(参数,默认值):表示如果指定参数为空则取第二个默认值
-- 30、查询任何一门课程成绩在60分以上的姓名、课程名称和分数;
select st.s_name,c.c_name,score.s_score from score,student st,course c
where score.s_id = st.s_id and
score.c_id = c.c_id and
score.s_score >60 GROUP BY score.s_id
-- 30、查询所有课程成绩在60分以上的姓名、课程名称和分数;
select sc.*,min(sc.s_score) from score sc GROUP BY sc.s_id HAVING min(sc.s_score) >60
-- 30、查询所有课程成绩在60分以上的姓名、课程名称和分数;
select st.s_name,c.c_name,sc.s_score from score sc,student st,course c
where sc.s_id = st.s_id and sc.c_id = c.c_id
GROUP BY sc.s_id HAVING min(sc.s_score) >60
case when then else end
-- 20、统计列印各科成绩,各分数段人数,
-- 显示:课程ID,课程名称,[100-85],[85-70],[70-60],[ <60]
select sc.c_id,
c.c_name,
sum(CASE WHEN sc.s_score BETWEEN 85 and 100 then 1 else 0 end ) as '[100-85]',
sum(CASE WHEN sc.s_score BETWEEN 70 and 84 then 1 else 0 end ) as '[85-70]',
sum(CASE WHEN sc.s_score BETWEEN 60 and 69 then 1 else 0 end ) as '[70-60]',
sum(CASE WHEN sc.s_score <60 then 1 else 0 end ) as '[ <60] '
from score sc,course c where sc.c_id = c.c_id GROUP BY sc.c_id
ifnull
-- 26、查询每门课程的平均成绩,结果按平均成绩升序排列,平均成绩相同时,按课程号降序排列
select c_id,avg(IFNULL(sc.s_score,0)) from score sc GROUP BY sc.c_id
order by avg(sc.s_score) asc , sc.c_id desc、
注意 ifnull(参数,默认值):表示如果指定参数为空则取第二个默认值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号