
IO阻塞模型 非阻塞模型
IO阻塞模型(blocking IO)
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
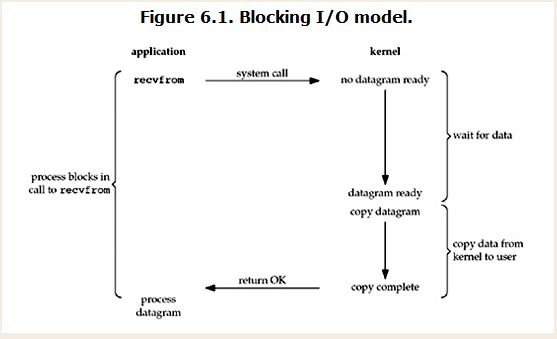
所以,blocking IO的特点就是在IO执行的两个阶段(等待数据和拷贝数据两个阶段)都被block了。


from socket import *
server = socket(AF_INET,SOCK_STREAM)
server.bind(('127.0.0.1',8080))
server.listen(5)
while True:
conn,addr = server.accept()
print(addr)
while True:
try:
data = conn.recv(1024)
if not data:break
conn.send(data.upper())
except ConnectionResetError:
break
conn.close()
from socket import *
client = socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',8080))
while True:
msg = input('>>:').strip()
if not msg:continue
client.send(msg.encode('utf-8'))
data = client.recv(1024)
print(data.decode('utf-8'))
client.close()
非阻塞IO模型
Linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:
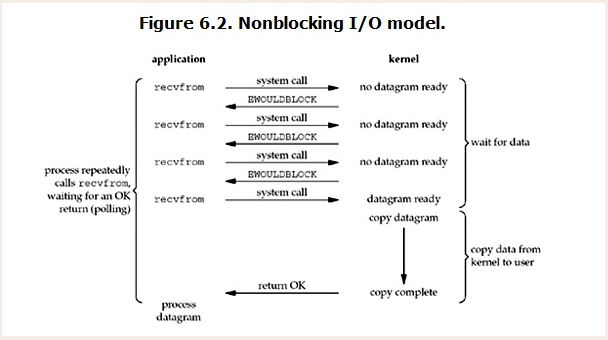
所以,在非阻塞式IO中,用户进程其实是需要不断的主动询问kernel数据准备好了没有。
# 1.对cpu的占用率过多,但是是无用的占用
# 2.在链接数过多的情况下不能及时响应客户端的消息
from socket import *
server = socket(AF_INET,SOCK_STREAM)
server.bind(('127.0.0.1',8080))
server.listen(5)
server.setblocking(False) # 非阻塞型,默认为阻塞型True
conn_l = []
while True:
try:
conn,addr = server.accept()
conn_l.append(conn)
print(addr)
except BlockingIOError:
# print('干其它活去了')
# time.sleep(2)
del_l = []
for conn in conn_l:
try:
data = conn.recv(1024)
if not data: # 针对linux系统
conn.close()
del_l.append(conn)
continue
conn.send(data.upper())
except BlockingIOError:
pass
except ConnectionResetError:
conn.close()
del_l.append(conn)
for conn in del_l:
conn_l.remove(conn)
from socket import *
client = socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',8081))
while True:
msg = input('>>:').strip()
if not msg:continue
client.send(msg.encode('utf-8'))
data = client.recv(1024)
print(data.decode('utf-8'))
client.close()
IO多路复用
IO multiplexing这个词可能有点陌生,但是如果我说select/epoll,大概就都能明白了。有些地方也称这种IO方式为事件驱动IO(event driven IO)。我们都知道,select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。它的流程如图:
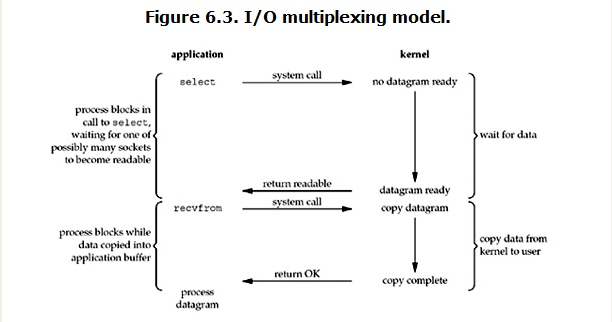
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
这个图和blocking IO的图其实并没有太大的不同,事实上还更差一些。因为这里需要使用两个系统调用(select和recvfrom),而blocking IO只调用了一个系统调用(recvfrom)。但是,用select的优势在于它可以同时处理多个connection。
强调:
1. 如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。
2. 在多路复用模型中,对于每一个socket,一般都设置成为non-blocking,但是,如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。
结论: select的优势在于可以处理多个连接,不适用于单个连接
from socket import *
import select
server = socket(AF_INET,SOCK_STREAM)
server.bind(('127.0.0.1',8080))
server.listen(5)
server.setblocking(False) # 非阻塞型,默认为阻塞型True
read_l = [server,]
print('strating....')
while True:
rl,wl,xl = select.select(read_l,[],[]) # 整体的返回值是一个元组,rl为元组里的一个列表
# print('===>',rl) # rl里的值就是server对象或conn对象
for r in rl:
if r is server:
conn,addr = r.accept()
read_l.append(conn)
else:
try:
data = r.recv(1024)
if not data:
r.close()
read_l.remove(r)
r.send(data.upper())
except ConnectionResetError:
r.close()
read_l.remove(r)
from socket import *
client = socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',8081))
while True:
msg = input('>>:').strip()
if not msg:continue
client.send(msg.encode('utf-8'))
data = client.recv(1024)
print(data.decode('utf-8'))
client.close()
socketserver模块
TCP
import socketserver
class MyTCPHandler(socketserver.BaseRequestHandler):
def handle(self):
print('========?>',self.request) # self.request is conn
while True:
data = self.request.recv(1024)
self.request.send(data.upper())
if __name__ == '__main__':
# socketserver.ForkingTCPServer 这个模块的多进程只能在linux上用
server = socketserver.ThreadingTCPServer(('127.0.0.1',8080),MyTCPHandler)
server.serve_forever()
from socket import *
client = socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',8081))
while True:
msg = input('>>:').strip()
if not msg:continue
client.send(msg.encode('utf-8'))
data = client.recv(1024)
print(data.decode('utf-8'))
client.close()
UDP
import socketserver
class MyTCPHandler(socketserver.BaseRequestHandler):
def handle(self):
print('========?>',self.request) # self.request 是一个元组,第一个值是客户端发来的消息,第二个值是一个套接字对象
client_data=self.request[0]
self.request[1].sendto(client_data.upper(),self.client_address)
if __name__ == '__main__':
# socketserver.ForkingTCPServer 这个模块的多进程只能在linux上用
server = socketserver.ThreadingUDPServer(('127.0.0.1',8080),MyTCPHandler)
server.serve_forever()
from socket import *
client = socket(AF_INET,SOCK_DGRAM)
while True:
msg = input('>>:').strip()
if not msg:continue
client.sendto(msg.encode('utf-8'),('127.0.0.1',8080))
data,server_addr = client.recvfrom(1024)
print(data.decode('utf-8'))
client.close()
paramiko模块
paramiko是一个用于做远程控制的模块,使用该模块可以对远程服务器进行命令或文件操作,值得一说的是,fabric和ansible内部的远程管理就是使用的paramiko来现实
下载安装
pip3 install paramiko #在python3中
SSHClient
用于连接远程服务器并执行基本命令
基于用户名密码连接:
import paramiko
# 创建SSH对象
ssh = paramiko.SSHClient()
# 允许连接不在know_hosts文件中的主机
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 连接服务器
ssh.connect(hostname='120.92.84.249', port=22, username='root', password='xxx')
# 执行命令
stdin, stdout, stderr = ssh.exec_command('df')
# 获取命令结果
result = stdout.read()
print(result.decode('utf-8'))
# 关闭连接
ssh.close()
基于公钥密钥连接:
客户端文件名:id_rsa
服务端必须有文件名:authorized_keys(在用ssh-keygen时,必须制作一个authorized_keys,可以用ssh-copy-id来制作)
import paramiko
private_key = paramiko.RSAKey.from_private_key_file('/tmp/id_rsa')
# 创建SSH对象
ssh = paramiko.SSHClient()
# 允许连接不在know_hosts文件中的主机
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 连接服务器
ssh.connect(hostname='120.92.84.249', port=22, username='root', pkey=private_key)
# 执行命令
stdin, stdout, stderr = ssh.exec_command('df')
# 获取命令结果
result = stdout.read()
print(result.decode('utf-8'))
# 关闭连接
ssh.close()
SFTPClient
用于连接远程服务器并执行上传下载
基于用户名密码上传下载
import paramiko
transport = paramiko.Transport(('120.92.84.249',22))
transport.connect(username='root',password='xxx')
sftp = paramiko.SFTPClient.from_transport(transport)
# 将location.py 上传至服务器 /tmp/test.py
sftp.put('/tmp/id_rsa', '/etc/test.rsa')
# 将remove_path 下载到本地 local_path
sftp.get('remove_path', 'local_path')
transport.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号