【周报】模块
- 上周回顾
- 本周回顾
- 常见内置函数
- abs() 求绝对值
- all() 与 any()
- bin() oct() hex() 十进制转其他进制
- int() 其他进制转10进制
- bytes() 与 str() 编码转换
- callable() 判断数据是否可以调用
- chr() ord() 基于ASCII码 进行数字与字符的转换
- dir() 获取对象内可以用句点符取出的数据与方法
- divmod() 获取除法运算后的整数与余数 用于分页
- enumera() 枚举
- eval() exec() 识别字符串中的python代码
- hash() 返回一串随机的数字(哈希值)
- help() 查看帮助信息
- isinstance() 判断某个数据是否属于某个数据类型
- pow() 幂指函数
- round() 四舍五入 有偏差 可以查百度看看详细说明 但我懒
- 迭代
- 异常捕获
- 生成器
- 迭代取值与索引取值的差异
- 模块
- 编程思想
- 软件开发目录规范
- 内置模块
- 常见内置函数
上周回顾
函数进阶
*和**在实参中的作用
*可以将容器类型的参数内部的数据依次取出 以元组的形式传给形参
def func(*args): print(args)
l1 = [1, 2, 3, 4, 5]
func(l1) # ([1, 2, 3, 4, 5], ) # 将整个列表当做一个参数传入
func(*l1) # (1, 2, 3, 4, 5) # 将列表中的数据依次取出
def func(*args): print(args)
d1 = {'name': 'jason', 'age': 123}
func(*d1) # ('name', 'age')
# 字典也同理
# 注:字典被循环取值时 默认取的是key
**可以将字典中的键值对以关键字参数的形式传入形参中
注:只能使用字典
def func(*args, **kwargs): print(args, kwargs)
l1 = [1, 2, 3, 4, 5]
d1 = {'name': 'jason', 'age': 123, 'hobby': 'read'}
func(d1) # ({'name': 'jason', 'age': 123, 'hobby': 'read'},) {}
func(*d1) # ('name', 'age', 'hobby') {}
func(**d1) # () {'name': 'jason', 'age': 123, 'hobby': 'read'}
func(name='jason', age=123, hobby='read') # () {'name': 'jason', 'age': 123, 'hobby': 'read'}
命名关键字参数
有时候需要指定某个形参必须使用关键字传参的方式传入数据
def func(a, b, c, *args, d, **kwargs): print(a, b, c, args, d, kwargs)
func(1, 2, 3, 4, 5, 6, d=7, e=8, k=9) # 1 2 3 (4, 5, 6) 7 {'e': 8, 'k': 9}
# 可以看到d被赋值为7 只有通过关键字传参才能获取数据
名称空间
名称空间的定义
用于存储变量名与数据的绑定关系
名称空间的分类
内置名称空间
python解释器打开时立即创建的空间
用于存放内置方法与内置变量
无法直接修改或删除该空间的内容
全局名称空间
py文件运行时立即创建的空间
用于存储程序运行后产生的名字
程序结束 立即关闭
局部名称空间
函数调用时产生的空间
用于存储函数调用阶段产生的名字
函数运行结束 立即关闭
名称查找顺序
名称的查找顺序要以当前所在空间为基准
当前空间为局部空间:局部>全局>内置
当前空间为全局空间:全局>内置
名称空间作用域
内置名称空间
在全局任意位置都可以调用(全局有效)
全局名称空间
在全局任意位置都可以调用(全局有效)
内部名称空间
在当前局部空间内可以调用(局部有效)
global和nonlocal关键字
global关键字
global可以在局部名称空间中修改全局名称空间的变量
主要针对不可变类型
s = 'jason'
def func1():
global s # 获取到全局空间的s并对其进行修改
s = 'tony'
def func2():
s = 'jerry' # 只是在内部名称空间中定义了一个s
print(s) # jason
func2()
print(s) # jason
func1()
print(s) # tony
nonlocal关键字可以在局部空间中获取上一层局部空间并对其进行修改
主要针对不可变类型
def outer():
s = 'jason'
def inner1():
s = 'tony' # 这里是在inner1名称空间中定义了一个新的s变量
def inner2():
nonlocal s # 这里是将outer空间中的s获取并获得对其修改的能力
s = 'jerry'
print(s) # jason
inner1()
print(s) # jason
inner2()
print(s) # jerry
outer()
函数名的多钟使用方式
函数名可以用作赋值
函数名也算是一种变量名
内部存储的是代码块对应的地址
def func(): print('from func')
res = func # 将func函数名绑定的代码块传给res
res() # res也可以加括号调用了
# 运行结果
# from func
函数名可以用作实参
def func(func_name):
func_name()
def func1():
print('from func1')
func(func1) # from func1
函数名可以用作返回值
def func():
def func1():
print('from func1')
return func1
res = func() # 注意和 res = func 的区别
res()
函数名可以作为容器类型的数据值
def func1(): print('from func1')
def func2(): print('from func2')
l1 = [func1, func2]
l1[0]() # from func1
l1[1]() # from func2
总结:函数名其实就类似变量名 在使用的时候可以当做可以加括号的变量名来执行一些操作
装饰器
闭包函数
闭包函数给函数体提供了一种新的传参方式
闭包函数特点
1.定义在函数内部的函数
2.内部函数使用的外部名称空间中的变量名
装饰器简介
装饰器就是在不改变原函数调用方式和内部代码的情况下
给原函数添加新的功能
对修改封闭 对扩展开放
装饰器推导
封装成函数 > 闭包传参 > 函数名返回 > 形参 > 函数体返回值
装饰器固定模板
# 定义装饰器
def outer(func_name):
def inner(*args, **kwargs):
"""这里执行函数执行前的功能"""
res = func_name(*args, **kwargs)
"""这里执行函数执行后的功能"""
return res
return inner
# 使用装饰器(不使用语法糖的情况)
def index(): pass
index = outer(index)
index()
装饰器语法糖
# 定义装饰器
def outer(func_name):
def inner(*args, **kwargs):
"""这里执行函数执行前的功能"""
res = func_name(*args, **kwargs)
"""这里执行函数执行后的功能"""
return res
return inner
# 语法糖使用装饰器
@outer # 可以看错 index = outer(index)
def index(): pass
index()
装饰器修复技术
将装饰器隐藏的更深
from functools import wraps
# 定义装饰器
def outer(func_name):
@warps('func_name') # 加上这句
def inner(*args, **kwargs):
"""这里执行函数执行前的功能"""
res = func_name(*args, **kwargs)
"""这里执行函数执行后的功能"""
return res
return inner
# 目前不知道有什么实际作用 比较鸡肋
装饰器进阶
多层装饰器
# 定义装饰器
def outer1(func_name):
print('加载了 outer1')
def inner(*args, **kwargs):
print('使用了 outer1')
res = func_name(*args, **kwargs)
return res
return inner
# 定义装饰器
def outer2(func_name):
print('加载了 outer2')
def inner(*args, **kwargs):
print('使用了 outer2')
res = func_name(*args, **kwargs)
return res
return inner
# 定义装饰器
def outer3(func_name):
print('加载了 outer3')
def inner(*args, **kwargs):
print('使用了 outer3')
res = func_name(*args, **kwargs)
return res
return inner
@outer3
@outer2
@outer1
def index(): pass
index()
# 运行结果
# 加载了 outer1
# 加载了 outer2
# 加载了 outer3
# 使用了 outer3
# 使用了 outer2
# 使用了 outer1
总结:就是套娃 从下往上加载 从上往下运行
有参装饰器
def outer1(data_type):
def outer(func_name):
def inner(*args, **kwargs):
print(data_type)
res = func_name(*args, **kwargs)
return res
return inner
return outer
@outer1('list')
def func(): print('from func')
func()
# 运行结果
# list
# from func
递归&二分法
递归函数
就是函数间接或直接的调用了自己
算法--二分法
局限性:数据有序排序,当数据在开头或结尾时,比顺序查找费时间
def get_num(num_list, left, right, target_num):
if left > right:
print('没找到')
return
mid_index = left + (right - left) // 2
mid_value = num_list[mid_index]
if mid_value < target_num:
get_num(num_list, mid_index + 1, right, target_num)
elif mid_value > target_num:
get_num(num_list, left, mid_index - 1, target_num)
else:
print(f'找到了 在索引{mid_index}')
常见算法
冒泡
快排
插入
堆排
桶排
三元表达式&各种生成式&匿名函数
三元表达式
# 语法结构
res = 1 if 1 == 0 else 0
pritn(res) # 0
# 结果1 if 条件 else 结果2
# 条件成立 结果1 条件不成立 结果2
各种生成式
列表生成式(主要)
# 例子
l1 = [1, 2, 3, 4, 5, 6]
l2 = [i for i in l1 if i != 4]
print(l2) # [1, 2, 3, 5, 6]
# 语法结构
# [变量名的相关处理 for 变量名 in 数据集]
# 先执行for循环 然后将一个个的数据值交给for循环前面处理
# [变量名的相关处理 for 变量名 in 数据集 if 条件]
# 先执行for循环 然后将一个个的数据值交给if判断 结果为True则最后交给for循环前面处理
字典生成式
# 例子
new_dict = {i: 'jason' for i in range(4)}
print(new_dict) # {0: 'jason', 1: 'jason', 2: 'jason', 3: 'jason'}
new_dict = {i: 'jason' for i in range(4) if i != 2}
print(new_dict) # {0: 'jason', 1: 'jason', 3: 'jason'}
# 语法结构
# [K: V for 变量名 in 数据集]
# 可以在外部定义V 或 K 然后在内部进行输入
# [K: V for 变量名 in 数据集 if 条件]
# 与列表生成式相似
集合生成式
# 与上面两个相似
匿名函数
语法结构
# 关键字 lambda
lambda 形参:返回值
# 可以看做
def xxx(形参): # xxx只是随便写的 不是说匿名函数的函数名为xxx
return 返回值
内置函数
max()
# 源码分析
# def max(*args, key=None):
"""
可以看到max输入的参数最终会变成一个元组 最后会对元组内的数据集进行判断 取出最大值
key是需要输入的函数名
一般搭配匿名函数使用
执行原理为 对第一个可变长参数做类似for循环处理 每次将其中的数传给后面的函数做判断
"""
# 例子1
l1 = [12, 123124, 12412312, 1412512512, 1231, 14124, 12315]
print(max(l1)) # 1412512512
# 例子2
dic = {
'jason': 100,
'kevin': 200,
'Baby': 500,
'zoy': 20
}
print(max(dic)) # zoy 为什么是zoy呢 明明数据只有20
"""
还记得吗 字典参与for循环只能获取K 所以这里也是这样
只是对名字进行了排序
而字符串之间比大小比的是ASCII码
A-Z为 65-90
a-z为 97-122
"""
# 那怎么对字典的值进行判断呢 可以用到key这个参数
res = max(dic, key=lambda k: dic.get(k))
print(res) # Baby
min()
与max相似
map()
l1 = [1, 2, 3, 4, 5, 6]
# 需求:将列表内所有数据自增10
res = map(lambda x: x+10, l1)
print(res) # <map object at 0x00000151CE92A0A0>
print(list(res)) # [11, 12, 13, 14, 15, 16]
filter()
l1 = [1, 2, 3, 4, 5, 6]
# 需求:将4移除
res = filter(lambda x: x!=4, l1)
print(res) # <filter object at 0x000002275135A100>
print(list(res)) # [1, 2, 3, 5, 6]
reduce()
l1 = [1, 2, 3, 4, 5, 6]
# 需求:求全部数据的和
from functools import reduce
res = reduce(lambda x, y: x + y, l1)
print(res) # 21
zip()
n1 = [1,2,3]
n2 = ['jason','kevin','oscar']
res = zip(n1,n2)
print(list(res)) # [(1, 'jason'), (2, 'kevin'), (3, 'oscar')]
'''
1.可以拼接多个值
2.拼接的值要支持for循环
3.如果存放的数据长短不一,那就按照最短的那个来连接
'''
本周回顾
常见内置函数
abs() 求绝对值
print(abs(-9)) # 9
print(abs(9)) # 9
all() 与 any()
# all() 判断容器类型中所有的数据是否都为True 可以看做全部数据进行and
l1 = [1, 2, 3, 4, 0]
l2 = [1, 2, 3, 4]
print(all(l1)) # False
print(all(l2)) # True
# any() 判断容器类型中是否存在数据为True 可以看做去全部数据进行or
print(any(l1)) # True
print(any(l2)) # True
l3 = [0, 0, 0, 0, None, False]
print(any(l3)) # False
bin() oct() hex() 十进制转其他进制
print(bin(10)) # 0b1010
print(oct(10)) # 0o12
print(hex(10)) # 0xa
int() 其他进制转10进制
# 注意要填写进制相关的符号
# 二进制 0b 八进制0o 十六进制0x
print(int(0b1010))
print(int(0o12))
print(int(0xa))
bytes() 与 str() 编码转换
s = '你好啊'
res = bytes(s, 'utf8') # 等价于 res = s.encode('ustf')
res1 = str(res, 'utf8') # 等价于 res1 = res.decode('utf8')
callable() 判断数据是否可以调用
call 在IT专业名词翻译成 调用 >>>:加括号
name = 'jason'
def index(): pass
print(callable(name)) # False
print(callable(index)) # True
chr() ord() 基于ASCII码 进行数字与字符的转换
print(chr(65)) # A
print(char(97)) # a
print(ord('A')) # 65
print(ord('a')) # 97
# ASCII码下 a-z 为 97-122 A-Z 为 65-90
dir() 获取对象内可以用句点符取出的数据与方法
s = '123'
print(dir(s)) # 结果有点多 自己试 嘻嘻
divmod() 获取除法运算后的整数与余数 用于分页
res = divmod(99, 10)
print(res) # (9, 9)
# 用于分页
real_num, more = divmod(898, 10)
if more:
real_num += 1
print(f'总页数为:{real_num}')
enumera() 枚举
name_list = ['jason', 'tony', 'kevin', 'jerry']
# 需求:循环打印出列表中的数据以及对应的索引值
count = 0
for i in name_list:
print(count, i)
count += 1
# 运行结果
# 0 jason
# 1 kevin
# 2 oscar
# 3 jerry
# 使用enumerate()
for i, j in enumerate(name_list):
print(i, j)
# 运行结果
# 0 jason
# 1 kevin
# 2 oscar
# 3 jerry
# 可以指认起始数字
for i, j in enumerate(name_list, start=1):
print(i, j)
# 运行结果
# 1 jason
# 2 kevin
# 3 oscar
# 4 jerry
eval() exec() 识别字符串中的python代码
s = 'print(123)'
eval(s) # 123
s = 'for i in range(10):print(i, end=" ")'
exec(s) # 0 1 2 3 4 5 6 7 8 9
hash() 返回一串随机的数字(哈希值)
print(hash('jason')) # -3519093933572877535
help() 查看帮助信息
help(len)
# 运行结果
# Help on built-in function len in module builtins:
#
# len(obj, /)
# Return the number of items in a container.
isinstance() 判断某个数据是否属于某个数据类型
s = 'jason'
print(isinstance(s, str)) # True
print(isinstance(s, int)) # False
pow() 幂指函数
print(pow(2, 10)) # 1024 既 2的10次方
round() 四舍五入 有偏差 可以查百度看看详细说明 但我懒
print(round(98.3)) # 98
print(round(98.5)) # 98
print(round(98.6)) # 99
print(round(5.5)) # 6
迭代
如何理解迭代
既更新换代 每次迭代都基于上次的结果
可迭代对象
如何判断可迭代对象
可迭代对象可以使用句点符调用__iter__方法
已知的可迭代对象有:
字符串 列表 字典 元组 集合 文件
已知的不可迭代对象有:
整型 浮点型 布尔值 函数名
迭代器对象
迭代器对象作用
迭代器对象给我们提供了一种不依赖于索引值的取值方式
正是有迭代器对象的存在 我们才可以从字典、集合这些无序排序的容器类型中获取数据
如何判断迭代器对象
迭代器对象通过句点符调用__iter__和__next__方法
可迭代对象与迭代器对象的关系
可迭代对象调用__iter__就会变成迭代器对象
迭代器对象无论调用多少次__iter__都还是本身
迭代器对象取值
l1 = [1, 2, 3, 4, 5]
# l1 并没有 __next__ 方法 因为它是可迭代对象
res = l1.__iter__() # 使用__iter__将可迭代对象转化为迭代器对象 并赋值给res
print(res.__next__()) # 1 使用__next__就可以取出下一个数据
# 不使用for循环 依次打印列表中所有数据
l1 = [1, 2, 3, 4, 5]
res = l1.__iter__()
n = 0
while n < len(l1):
print(res.__next__())
n += 1
# 运行结果
# 1
# 2
# 3
# 4
# 5
双下方法的另一种方法
res = l.__iter__() # 可以简写 res = iter(l)
res.__next__() # 可以简写 next(res)
# 不推荐
迭代器对象的特殊性
迭代器对象 通过打印操作无法直接看出内部的情况
这个时候能帮你节省空间
相当于一个工厂 需要数据时 一个个取出
异常捕获
如何理解异常
异常在程序运行中出现则会是程序直接结束
既程序员口中的BUG
异常的结构

关键字line
精准标记出异常的出现位置 一般来说看最后的超链接
最后一行冒号的左边
错误类型
最后一行冒号右边
错误的具体原因(关键)
异常类型
| 异常名称 | 描述 |
|---|---|
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| Exception | 常规错误的基类 |
| StopIteration | 迭代器没有更多的值 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| SystemExit | Python 解释器请求退出 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
| FloatingPointError | 浮点计算错误 |
| OverflowError | 数值运算超出最大限制 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| AssertionError | 断言语句失败 |
| EOFError | 没有内建输入,到达EOF 标记 |
| EnvironmentError | 操作系统错误的基类 |
| IOError | 输入/输出操作失败 |
| OSError | 操作系统错误 |
| WindowsError | 系统调用失败 |
| ImportError | 导入模块/对象失败 |
| LookupError | 无效数据查询的基类 |
| IndexError | 序列中没有没有此索引(index) |
| KeyError | 映射中没有这个键 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
| UnboundLocalError | 访问未初始化的本地变量 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| SyntaxError | Python 语法错误 |
| IndentationError | 缩进错误 |
| TabError | Tab 和空格混用 |
| SystemError | 一般的解释器系统错误 |
| ValueError | 传入无效的参数 |
| UnicodeError | Unicode 相关的错误 |
| UnicodeDecodeError | Unicode 解码时的错误 |
| UnicodeEncodeError | Unicode 编码时错误 |
| Warning | 警告的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| SyntaxWarning | 可疑的语法的警告 |
| UserWarning | 用户代码生成的警告 |
| FileNotFoundError | 文件未找到错误 |
异常分类
语法错误
不允许出现!出现就立马修改!
逻辑错误
允许出现 运行之后修改错误即可
什么时候需要异常捕获
不确定因素导致报错的情况下,如前后端数据交互时,断网导致的数据传输失败无法处理数据的问题
异常捕获原理
提前预知了报错的可能 提前给出相应处理措施
异常捕获语法结构
# 基本语法结构
try:
可能出现错误的代码(被try监控)
except 错误类型1 as e: # e就是具体错误信息
对应错误类型1的解决方法
except 错误类型2 as e:
对应错误类型2的解决方法
except 错误类型3 as e:
对应错误类型3的解决方法
except 错误类型4 as e:
对应错误类型4的解决方法
except 错误类型5 as e:
对应错误类型5的解决方法
# 摆烂语法
try:
可能出现错误的代码
except Exception: # Exception 接收所有异常 但不包括语法错误
解决方法
异常捕获其他操作补充
# else与finally
try:
n = 1
except Exception:
print('这都能错?我就知道你做不好')
else: # 代码未报错 执行else
print('哈哈哈哈哈 我就知道你不会犯错')
finally: # 无论代码有没有报错 都会执行
print('无论做得好做得不好 做自己就好')
# 断言 assert
name = 'jason'
assert isinstance(name, list) # 断言name 属于 list类型 如果不对则报错 对则执行后面的代码 感觉和if作用差不多
print('哈哈哈哈哈') # 显然name不是list类型 所以这步不会执行
# 主动抛出异常 raise
name = 'jason'
if name == 'jason':
raise Exception('鸡你太美')
else:
raise Exception('你干嘛~')

for循环本质
l1 = [11, 22, 33, 44, 55, 66]
res = l1.__iter__()
while True:
try:
print(res.__next__())
except StopIteration:
break
生成器
生成器对象的性质
本质就是迭代器对象
不过迭代器对象是编译器提供给我们的
而生成器对象时我们根据迭代器 自己手搓的
主要依赖yield关键字
生成器对象的作用
优化代码 提供一种不依赖于索引的取值方式 并在需要数据时一个一个取出 节省了占用空间
代码实现
# yield关键字
def func():
print(123)
yield
func() # 运行后发现 啥也没有
# 原来 当函数体内有yield关键字 第一次运行时并不会执行函数体代码 而是产生一个迭代器对象 既生成器 可以由一个变量名接收
res = func()
res.__next__() # 123 通过调用__next__方法就可以调用yield上面的代码
# 当然 函数体内可以不止有一个yield
def func():
print(1)
yield
print(2)
yield
print(3)
yield
print(4)
yield
res = func()
res.__next__() # 1
res.__next__() # 2
res.__next__() # 3
res.__next__() # 4
# yield 后面可以添加返回值 和return用法相似
def func():
print(1)
yield 111
print(2)
yield 222
print(3)
yield 333
res = func()
res1 = res.__next__() # 1
res2 = res.__next__() # 2
res3 = res.__next__() # 3
print(res1) # 111
print(res2) # 222
print(res3) # 333
yield关键字其他用法
# yield可以在函数中充当一个参数
def func(name, s_name=None):
print(f'{name}要来检查博客辣!!!')
while True:
s_name = yield
print(f'哦吼!{s_name}博客没写 录音也没录')
res = func('jason') # 同样第一次调用不会执行函数体代码
res.__next__() # jason要来检查博客辣!!!
res.send('快男') # 哦吼!快男博客没写 录音也没录 send()用于传值给yield 并自动调用__next__方法
res.send('XXX') # 哦吼!XXX博客没写 录音也没录
生成器表达式
l1 = [i for i in range(10)]
print(l1) # [0, 1, 2, 3, 4, 5, 6, 7, 8 ,9]
n = 1
l1 = (i + n for i in range(10))
print(l1) # <generator object <genexpr> at 0x00000234BAD46B30> "元组生成式"生成了一个生成器对象
# 只有通过__next__或相关操作取出里面的数据 表达式才会生效
print(list(l1)) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
l2 = (i + n for i in range(10))
n = 2 # 修改了n = 2
print(list(l2)) # [2, 3, 4, 5, 6, 7, 8, 9, 10, 11] 执行了修改后的n
# 面试题
def add(n, i): # 普通函数 返回两个数的和 求和函数
return n + i
def test(): # 生成器
for i in range(4):
yield i
g = test() # 激活生成器
for n in [1, 10]:
g = (add(n, i) for i in g)
"""
第一次for循环
g = (add(1, i) for i in g) # 这里并没有调用 只是产生了一个迭代器(生成器)
第二次for循环
g = (add(10, i) for i in (add(10, i) for i in g)) # 这里的add()中的n变为了10 然后再产生了一个生成器
"""
res = list(g) # 这里才进行了调用 n为10 所以全部生成器中n都为10
"""
大致过程
先:g = (add(10, i) for i in (10, 11, 12, 13))
再 res = (20, 21, 22, 23)
"""
print(res)
#A. res=[10,11,12,13]
#B. res=[11,12,13,14]
#C. res=[20,21,22,23] # 正确答案
#D. res=[21,22,23,24]
迭代取值与索引取值的差异
迭代取值
优势:能够对无序的数据集进行取值
劣势:只能一个个获取数据 并且不能重复获取
索引取值
优势:能够随意重复获取任意位置的数据
劣势:无法对无序的数据集进行取值
模块
如何理解模块
模块就像一个工具箱 里面装有各种工具
导入了模块就能使用其中的名字和功能
模块分类
内置模块
解释器自带的能够直接使用的模块
import time
import sys
import os
自定义模块
自己写的模块
将想要的功能写在一个py文件上 然后在另一个py文件中导入该模块 就可以使用这些功能
第三方模块
别人写的模块 存在于网络上 使用之前要提前下载
其实在别人看来 你写的模块就是第三方模块
模块的表现形式
py文件
含有多个py文件的文件夹
模块的两种导入方式
# 方式1:import ...
import time
time.sleep()
# 方式2: from ... import ...
from time import sleep
sleep()
# import ...
# 优点 通过模块.的方式可以使用到模块内的全部名字 且不会冲突
# 缺点 暴露太多 有时候并不想所有东西都可以通过模块.的方式获取
# from ... import ...
# 优点 指名道姓的使用指定的名字 并且不需要加模块名前缀
# 缺点 名字容易于当前全局名称空间的名字产生冲突
补充说明
# 起别名
# 在多个模块名字相同 或 模块名较复杂的情况下 可以通过 as 别名 的方式取一个别名
# 再通过别名.的形式调用模块内的功能
import UserInfoGetTargetName as UIGT
UIGT.XXXXX
from a import d as a_d
from b import d as b_d
from c import d as c_d
# 导入多个名字
# 建议同一目录下的模块 或 功能相似的模块 采用统一导入
from a import b, c, d
import run, runfast, runslowly
判断文件类型
所有py文件都含有一个内置的名字__name__
当py文件为执行文件时__name__为__main__
当py文件为被导入文件时__name__为文件名(模块名)
循环导入问题
# 以下为a.py的内容
import b
name = 'from a'
print(b.name)
# 以下为b.py的内容
import a
name = 'from b'
print(a.name)
# 无论执行哪个文件都会报错
# 解决措施
# 在导入前先把东西准备好
# 以下为a.py的内容
name = 'from a'
import b
print(b.name)
# 以下为b.py的内容
name = 'from b'
import a
print(a.name)
模块查找顺序
先在内存中查找>>>再去内置中查找>>>在去环境变量中查找(sys.path)
所有的路径都是参照执行文件来的
可以通过 sys.path.append() 的方式添加文件的绝对路径
可以通过 from ... import ... 获取相对路径下的模块 起始位置一定是执行文件所在的位置
导入模块时发生的事情
import...
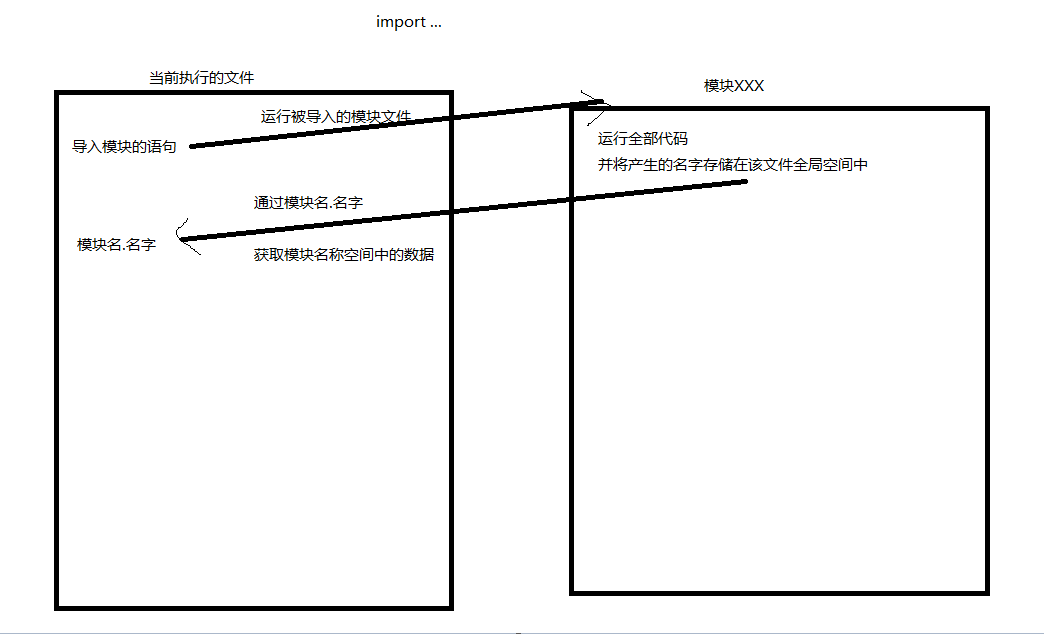
from ... import ...
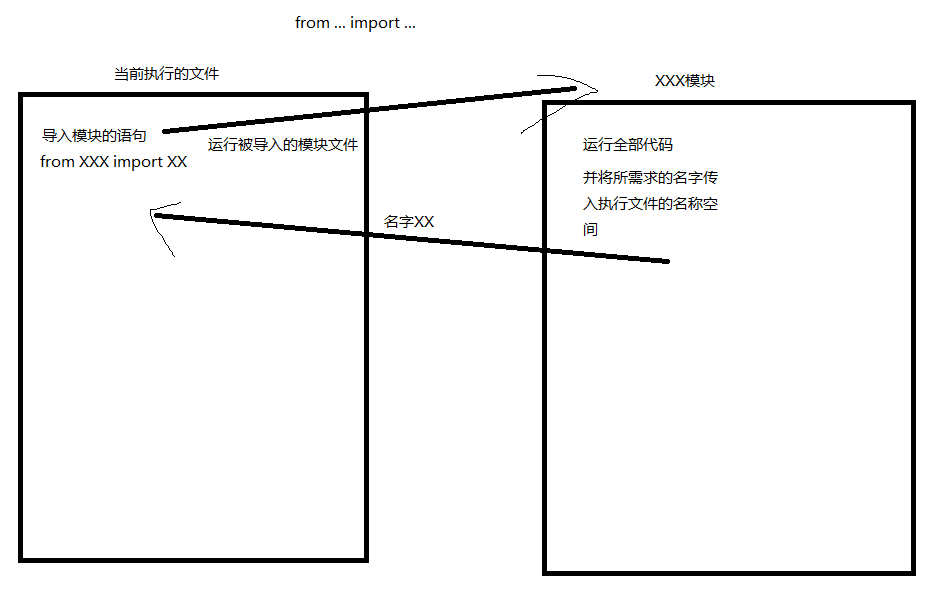
绝对导入与相对导入
只要提到模块的导入 那么sys.path永远以执行文件为基准
绝对导入
from ccc.ddd.eee impot a
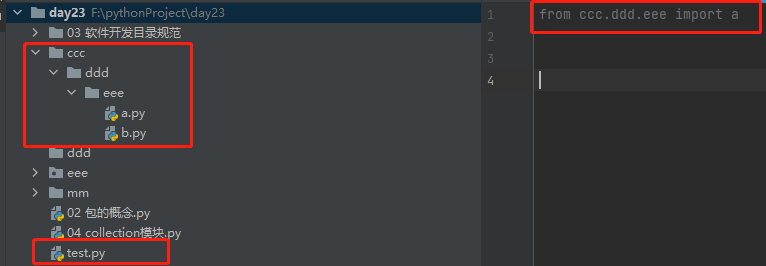
绝对导入会按照当前执行文件的sys.path一层层的往下查找
pycharm默认将项目根目录存放在sys.path中 所以从项目根目录一层层导入绝对不会出错

但若不是用pycharm运行 则需要将项目根目录路径添加到sys.path
所以还是养成手动将根目录添加到sys.path中的习惯
提高项目兼容性
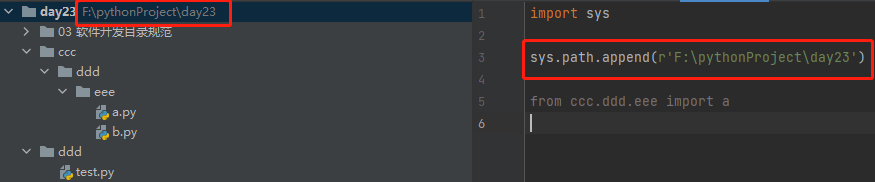
相对导入
模块文件之间的导入会使用到相对导入
但绝对导入更好
.在路径中的作用
| 标点 | 作用 |
|---|---|
| . | 当前文件路径 |
| .. | 上一级文件路径 |
| ../.. | 上上级文件路径 |
相对导入可以不参考执行文件所在的路径 直接以当前模块路径为准
但相对导入有些缺陷:
1.只能在模块文件中使用 不在执行文件中使用
2.相对导入在项目比较复杂的情况下 可能会出错
建议:多用绝对导入 少用相对导入
包的概念
如何理解包
专业角度:内部含有__init__.py的文件夹
直观角度:内部有模块文件的文件夹
作用:存放多个模块 仅仅是更加方便的管理模块文件
包的使用
import 包名
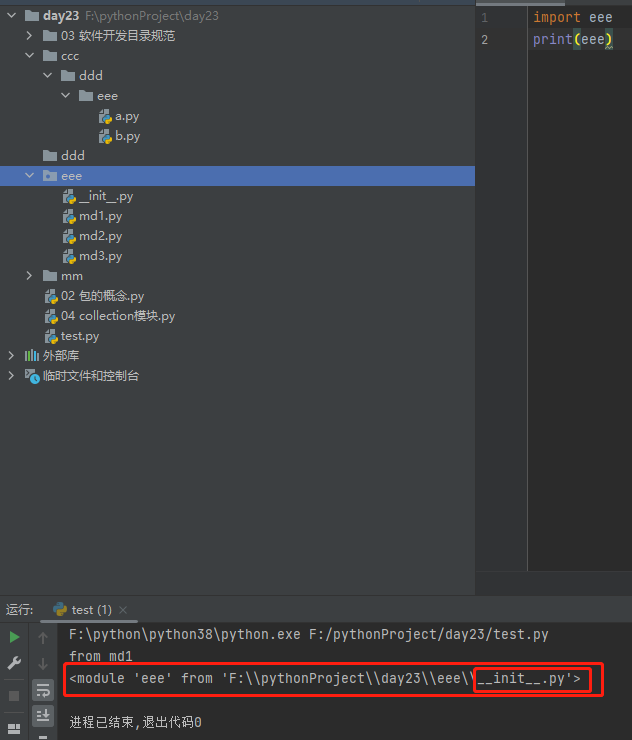
可以看到这里导入的是包内的__init__.py文件
但也可以通过from ... import ...的方式跳过__init__.py文件直接获取包内的模块文件
不同版本导入包的差异
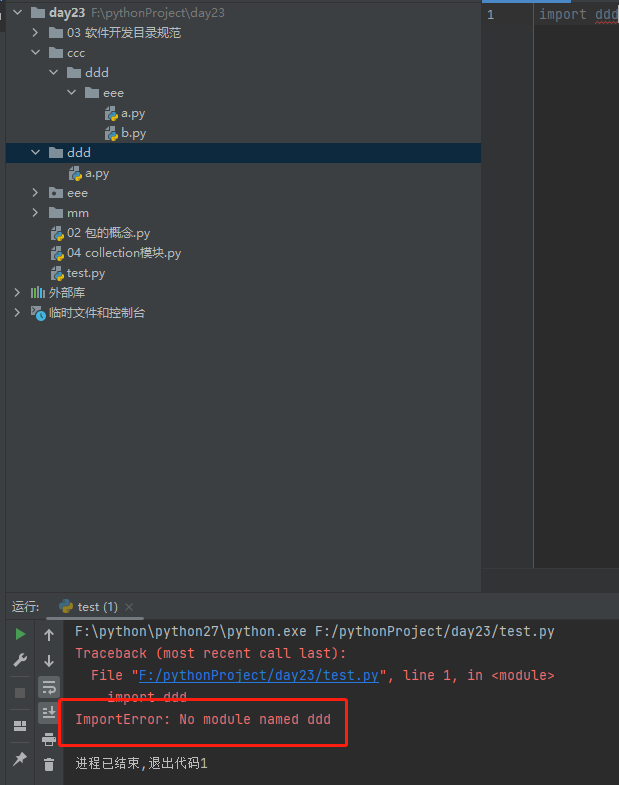
python3解释器中包内有没有__init__.py都无所谓了
而python2解释器中包内严格需求要有__init__.py
python2环境下
编程思想
小白阶段
按需求从上往下的编写代码(面条版)-----单文件
函数阶段
打破从上往下编写代码的空间限制 按功能将代码封装为不同函数-----单文件
模块阶段
把封装好的函数按功能分类并拆分到不同的模块中-----多文件
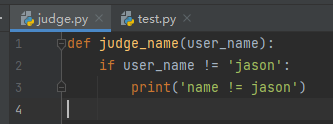
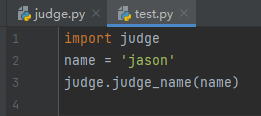
每个阶段都使代码变得更加规范
软件开发目录规范
目的
为了更加方便、高效、快捷的管理代码
| 文件夹 | 作用 | 内含文件 |
|---|---|---|
| conf | 存储程序的配置文件 | settins.py |
| core | 存储程序的核心功能 | src.py |
| bin | 存储程序的启动文件 | start.py |
| lib | 存储程序的公共功能 | common.py |
| db | 存储程序的数据文件 | userinfo.txt |
| log | 存储程序的日志文件 | log.log |
| interface | 存储程序的接口文件 | user.py、good.py |
| readme(单个文件) | 用于介绍程序的功能 | \ |
| requirements.txt(单个文件) | 记录了项目所需的第三方模块名称和版本信息 | \ |
内置模块
collections模块(了解)
作用
给我们提供了更多的数据类型
| 名字 | 类型 |
|---|---|
| namedtuple | 具名元组 |
| deque | 双端队列 |
| OrderedDict | 有序字典 |
| defaultdict | 默认值字典 |
| counter | 计数器 |
time模块
作用
提供了很多时间的操作
| 函数 | 作用 |
|---|---|
| time() | 获取时间戳 |
| localtime() | 获取结构化时间 |
| gmtime() | 获取英国伦敦的结构化时间 |
| strftime() | 根据某舟格式来格式化时间 |
| sleep() | 程序在原地等待自定义的时间 |
时间的格式
在striftime()中输入特定的格式可以获取特定的时间字符串
import time
res = time.strftime('%Y-%m-%d %H:%M:%S')
print(res) # 2022-07-15 17:11:02
res = time.strftime('%Y-%m-%d %X')
print(res) # 2022-07-15 17:11:02
| 格式 | 作用 |
|---|---|
| %Y | 获取年份 |
| %m | 获取月份 |
| %d | 获取天份 |
| %H | 获取小时 |
| %M | 获取分钟 |
| %S | 获取秒数 |
| %X | 获取时分秒 |
datetime模块
与time模块类似 都是时间相关操作的模块
使用
import datetime
res = datetime.datetime.today()
print(res) # 2022-07-15 17:18:49.814341
res1 = datetime.date.today()
print(res1) # 2022-07-15
"""
date 年月日
datetime 年月日 时分秒
"""
print(res.year) # 2022
print(res.month) # 7
print(res.day) # 15
print(res.hour) # 17
print(res.minute) # 22
print(res.second) # 16
print(res.weekday()) # 4
print(res.isoweekday()) # 5
"""
year 年
moth 月
day 日
hour 时
minute 分
second 秒
weekday() 周几 周一为0
isoweekday()周几 周一为1
"""
# timedelta 日期延期/提前
res = datetime.date.today()
tl = datetime.timedelta(days=3)
print(res) # 2022-07-15
print(res + tl) # 2022-07-18
print(res - tl) # 2022-07-12
"""
timedelta括号内有很多参数 没有的时间可以通过换算得来
"""
os模块
语句
# 导入
import os
import os
# 创建目录 mkdir() makedirs()
os.mkdir(r'aaa') # 创建单级文件 但不能创建多级文件 但mkdir该语句在很多系统都通用
os.makedirs(r'aaa\bbb\ccc') # 创建多级文件 也可以创建单级文件
import os
# 删除目录 rmdir() removedirs()
os.rmdir(r'aaa') # 删除单级文件 但文件内不能有数据 不能删除多级文件
os.removedirs(r'aaa\bbb\ccc') # 可以删除多级文件
# 但若文件内有数据则无法删除 从内到外依次删除空的文件夹 直到遇到有数据的文件夹
import os
# 列举指定文件下的文件名称 listdir() 结果返回的是列表
# aaa文件夹中有 a.py b.py c.py
res = os.listdir(r'aaa')
print(res) # ['a.py', 'b.py', 'c.py']
import os
# 重命名文件 rename() 删除文件 remove()
os.rename('a.txt', r'aaa.txt') # 将a.txt更改为aaa.txt
os.remove('aaa.txt') # 删除aaa.txt
import os
# 获取当前工作路径 getcwd() 获取的是绝对路径
print(os.getcwd()) # F:\pythonProject\day24
os.chdir(r'..') # chdir() 类似 控制台中的cd
print(os.getcwd()) # F:\pythonProject
import os
# 与程序启动文件相关
print(os.path.abspath(__file__)) # 获取当前文件的绝对路径(可以不记)
print(os.path.dirname(__file__)) # 获取当前文件所在的目录路径(必须得记)
import os
# 判断路径是否存在(文件、目录) exists() isdir() isfile()
# exists() 就像 isdir() 和 isfile() 功能的结合版
# isdir() 只能判断路径是否是目录(既文件夹)
# isfile() 只能判断路径是否是文件
# exists() 可以判断路径是否存在
import os
# 拼接路径 join()
relative_path = 'a.txt'
absolute_path = r'D:\pythonProject\day24\ccc\ddd\eee'
res = os.path.join(absolute_path, relative_path) # 两个路径之间会根据当前系统自动添加\或/(不同系统之间路径的分隔符不同)
print(res) # D:\pythonProject\day24\ccc\ddd\eee\a.txt
import os
# 获取文件大小 getize()
# a.txt 的内容如下
# 你好aaaa
print(os.path.getsize(r'a.txt')) # 10 计算的是字节量 1个中文3字节 1个英文1个字节 所以是10字节
sys模块
语句
import sys
print(sys.path) # 结果是列表
print(sys.version) # 查看解释器版本信息
print(sys.platform) # 查看当前平台
res = sys.argv
"""需求 命令行执行当前文件必须提供用户名和密码 否则不准执行"""
if len(res) == 3:
username = res[1]
password = res[2]
if username == 'jason' and password == '123':
print('您可以正常执行该文件')
else:
print('用户名或密码错误')
else:
print('请填写用户名和密码')
# 上述校验也可以使用异常捕获实现(课下实现)
res = sys.argv
try:
username = res[1]
password = res[2]
if username == 'jason' and password == '123':
print('您可以正常执行该文件')
else:
print('用户名或密码错误')
except IndexError:
print('请输入用户名和密码')
json模块
语句
import json
res = json.dumps(d) # 序列化 将其他数据类型转换成json格式字符串
print(res, type(res)) # {"name": "jason", "pwd": 123} <class 'str'>
res1 = json.loads(res) # 反序列化 将json格式字符串转换成对应编程语言中的数据类型
print(res1, type(res1)) # {'name': 'jason', 'pwd': 123} <class 'dict'>
"""
dumps() 将其他数据类型转换为json格式字符串
loads() 将json格式字符串z换行成对应的数据类型
dump() 将其他数据类型直接以json格式字符串写入文件
load() 将文件中json格式字符串读取出来并转换成对应的数据类型
"""

 浙公网安备 33010602011771号
浙公网安备 33010602011771号