

《effective Go》读后记录:GO基础
一个在线的Go编译器
如果还没来得及安装Go环境,想体验一下Go语言,可以在Go在线编译器 上运行Go程序。
格式化
让所有人都遵循一样的编码风格是一种理想,现在Go语言通过gofmt程序,让机器来处理大部分的格式化问题。gofmt程序是go标准库提供的一段程序,可以尝试运行它,它会按照标准风格缩进,对齐,保留注释,它默认使用制表符进行缩进。Go标准库的所有代码都经过gofmt程序格式化的。
注释
Go注释支持C风格的块注释/* */和C++风格的行注释//。块注释主要用作包的注释。Go官方提倡每个包都应包含一段包注释,即放置在包子句前的一个块注释。对于有多个文件的包,包注释只需要出现在其中一个文件即可。
godoc 既是一个程序,又是一个 Web 服务器,它对 Go 的源码进行处理,并提取包中的文档内容。 出现在顶级声明之前,且与该声明之间没有空行的注释,将与该声明一起被提取出来,作为该条目的说明文档。
命名
- Go语言的命名会影响语义:某个名称在包外是否可见,取决于其首个字符是否为大写字母。
- 包:应当以小写的单个单词来命名,且不应使用下划线或驼峰记法。
- 包名:应为其源码目录的基本名称,例如在 src/pkg/encoding/base64 中的包应作为"encoding/base64" 导入,其包名应为 base64
- 获取器:若有个名为 owner (小写,未导出) 的字段,其获取器应当名为 Owner(大写,可导出) 而非 GetOwner。若要提供设置器方法,可以选择SetOwner。
- 接口:只包含一个方法的接口应当以该方法的名称加上 - er 后缀来命名
- 驼峰记法:Go 中约定使用驼峰记法 MixedCaps 或 mixedCaps
分号
- Go的词法分析器会用简单的规则来自动插入分号
- 如果在一行中写多个语句,需要用分号隔开
- 控制结构的左大括号不能放在下一行,因为根据词法分析器的规则,会在大括号前加入一个分号,造成错误
初始化
常量必须在定义的时候就进行初始化。常量只能是数字、字符、字符串、布尔值等基本类型,定义它们的表达式必须是在编译期就可以求值的类型。使用const来定义一个常量:
const LENGTH int = 10
const WIDTH int = 5
在Go中,枚举常量使用iota来创建,iota是一个自增长的值:
type AudioOutput int
const (
OutMute AudioOutput = iota // 0
OutMono // 1
OutStereo // 2
_
_
OutSurround // 5
)
iota总是用于increment,但它也可以用于表达式,在《effective Go》展示了一个定义数量级的表示:
type ByteSize float64
const (
_ = iota // 使用_来忽略iota=0
KB ByteSize = 1 << (10 * iota) // 1 << (10*1)
MB // 1 << (10*2)
GB // 1 << (10*3)
TB // 1 << (10*4)
PB // 1 << (10*5)
EB // 1 << (10*6)
ZB // 1 << (10*7)
YB // 1 << (10*8)
)
源文件可以定义无参数init函数,该函数在真正执行函数逻辑之前被自动调用,下面的程序简单说明这一点:
package main
import "fmt"
func init() {
fmt.Print("执行init函数0\n")
}
func init() {
fmt.Print("执行init函数1\n")
}
func init() {
fmt.Print("执行init函数2\n")
}
func main() {
fmt.Print("执行main函数\n")
}
//output :
执行init函数0
执行init函数1
执行init函数2
执行main函数
可以看到,在执行main函数中的逻辑前,init函数会先被调用,而且同一个源文件中可以定义多个init函数。init函数通常被用在程序真正执行之前对变量、程序状态进行校验。它的执行机制是这样的:
- 该包中所有的变量都被初始化器求值后,init才会被调用
- 之后在所有已导入的包都被初始化之后,init才会被调用
控制结构
Go使用更加通用的for来代替do与while循环,for的三种形式为:
// Like a C for
for init ; condition;post { }
//Like a C while
for condition{ }
//Like a C for(;;)
for {}
对于数组、切片、字符串、map,或者从信道读取消息,可以使用range子句:
for key ,value := range oldMap {
newMap[key] = value
}
Go的switch要更加灵活通用,当switch后面没有表达式的时候,它将匹配ture,这也意味着if-else-if-else链可以使用switch来实现:
func unhex(c byte) byte {
switch { //switch将匹配true
case '0' <= c && c <= '9':
return c - '0'
case 'a' <= c && c <= 'f':
return c - 'a' + 10
case 'A' <= c && c <= 'F':
return c - 'A' + 10
}
return 0
}
函数
Go的函数可以进行多值返回。在C语言中经常有这种笨拙的用法:函数通过返回值来告知函数的执行情况,例如返回0代表无异常,返回-1表示EOF等,而通过指针实参来传递数据给外部。现在使用Go函数的多值返回可以解决解决这个问题。下面是Go标准库中打开文件的File.Write 的签名:
func (file *File) Write(b []byte) (n int, err error)
Write函数返回写入的字节数以及一个错误。如果正确写入了,则err为nil,否则,err为一个非nil的error错误值,这在Go中是一种常见的编码风格。
Go函数的返回值可以被命名。Go的返回值在函数体内可以作为常规的变量来使用,称为结果“形参”,结果“形参”在函数开始执行时被初始化与其类型相应的零值。如果函数执行了不带参数的return,则把结果形参的当前值返回:
func abs(i int) (result int){
if i < 0{
result = -i //返回值result可以直接当成常规变量使用
}
return
}
这样做的好处是函数的签名即为文档,返回值的含义也写到了函数签名中,提高了代码的可读性。
Go提供defer语句用于延迟执行函数。defer语句修饰的函数,在外层函数结束之前被调用。可以这样来使用defer语句:
func printStr (a string){
fmt.Print(a);
}
func main() {
defer printStr("one\n")
defer printStr("two\n")
defer printStr("three\n")
fmt.Print("main()\n")
}
//output :
main()
three
two
one
关于defer语句:
- 适用于关闭打开的文件,避免多个返回路径都需要去关闭文件。
- 被推迟执行的函数的实参,才推迟执行时就会求值,而不是在调用执行时才求值。
- 被推迟的函数按照后进先出(LIFO)的顺序执行。
- defer语句是在函数级别的,即使把它写在大括号(块)中,也只会在调用函数结束时才调用被推迟执行的函数。
使用defer语句时还有一些细节需要注意。下面这段代码:
func main() {
fmt.Print(test())
}
func test() (r int) {
defer func() {
r = 1
return
}()
r = 2
return 3
}
//output:
1
输出并不是3,而是1.原因是return的操作实际包括了:
r = 0 //结果“形参”在函数开始执行时被初始化为零值
r = 2
r = 1 //defer语句执行
return r
内存分配
Go提供了两种分配原语new与make:
func new(Type) *Type
func make(t Type, size ...IntegerType) Type
new(T)用于分配内存,它返回一个指针,指向新分配的,类型为T的零值,通过new来申请的内存都会被置零。这意味着如果设计了某种数据结构,那么每种类型的零值就不必进一步初始化了。
make(T,args)的目的不同于new(T),它只用于创建切片(slice)、映射(map)、信道(channel),这三种类型本质上与引用数据类型,它们在使用前必须初始化。make返回类型为一个类型为T的已初始化的值,而非*T。
下面是new与make的对比:
var p *[]int = new([]int) // 分配切片结构;*p == nil;基本没用
var v []int = make([]int, 100) // 切片 v 现在引用了一个具有 100 个 int 元素的新数组
// 没必要的复杂:
var p *[]int = new([]int)
*p = make([]int, 100, 100)
// 习惯用法:
v := make([]int, 100)
数组
Go的数组与C语言的数组有很大的区别:
- 数组是值,把数组传递给函数,函数会得到该数组的一个副本,而不是指针。
- 数组的大小是类型的一部分。
[10]int与[20]int是两种类型。
如果想要像C语言那样传递数组指针,需要这样做:
func Sum(a *[3]float64) (sum float64) {
for _, v := range *a {
sum += v
} r
eturn
} a
rray := [...]float64{7.0, 8.5, 9.1}
x := Sum(&array) // 注意显式的取址操作
但在Go中通常不会这样做,而是通过切片来实现引用的传递。切片保存了对底层数组的引用,若你将某个切片赋予另一个切片,它们会引用同一个数组。
切片
切片是一个很小的对象,它对底层数组进行了抽象,并提供相应的操作方法,切片包含3个字段,其的内部实现为:
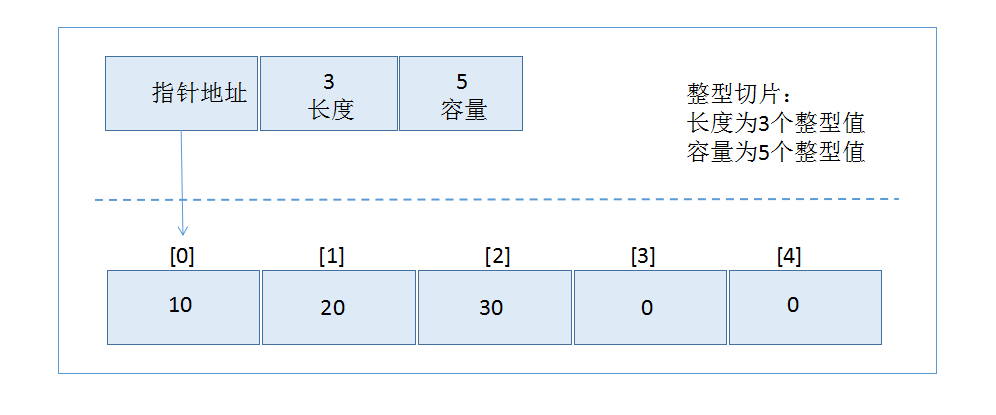
可以通过一些方式来定义切片:
var slice0 []type //通过声明一个未指定大小的数组来定义切片
var slice1 []type = make([]type, len) //通过make来创建切片,长度与容量都是5个元素
make([]T, length, capacity) //可以通过make来指定它的容量
声明的时候,只要在[]运算符里指定了一个值,那么创建的就是数组而不是切片,只有不指定值的时候,才会创建切片。
切片之所以称为切片,是因为创建一个新的切片就是把底层数组切出一部分,例如代码:
slice := [] int {10,20,30,40,50} //创建一个切片,长度与容量都是5
newSlice := slice[1:3] //创建一个新切片,其长度为5,容量为4
对底层数组容量是k的新切片slice[i,j]来说,长度是j-i,容量是k-i,创建的新切片内部实现为:
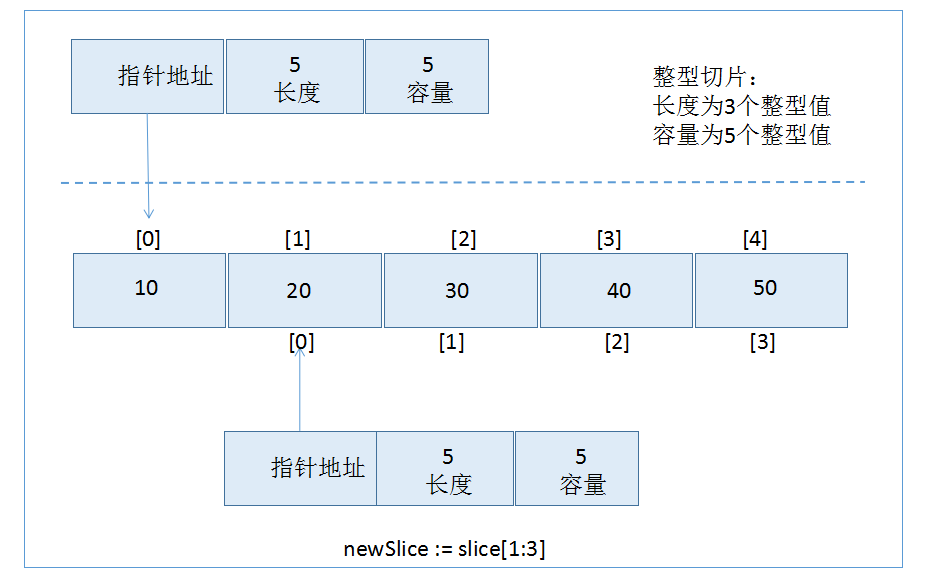
由于两个切片共享一部分的底层数组,所以修改newSlice的第2个元素,也将同样修改了slice的第三个元素。
可以使用append来增长切片的长度,这有两种情况:
- 当切片的可用容量足够时,append函数会增加切片的长度,而不会改变容量
- 当切片的可用容量不足时,append函数会增加切片的容量,增加的策略是:切片容量小于1000时,总是成倍地增加容量;一旦元素个数超过1000个,容量增加因子为1.25,也就是每次会增加25%。
当append函数造成切片容量拓展时,该切片将拥有一个全新的底层数组。
映射
映射与切片一样,也是引用类型。如果通过一个不存在的key来获取value,将返回与该映射中项的类型对应的零值:
var map1 map[string] int
map1 = make(map[string]int ,10)
map1["one"]=1
map1["two"]=2
fmt.Print(map1["three"])
//output:
0
如果map1["three"]的value刚好是0,该怎么区分呢?可以采用多重赋值的形式来分辨这种情况:
i, ret := map1["three"]
if ret == true{
fmt.Print("map1[\"three\"]存在,值为:", i)
} else {
fmt.Print("map1[\"three\"] 不存在\n")
}
或者这样写更好一些,《effective Go》称为the “comma ok” idiom ,逗号OK惯用法
if i, ret := map1["three"] ;ret {
fmt.Print("map1[\"three\"]存在,值为:", i)
} else {
fmt.Print("map1[\"three\"] 不存在\n")
}
如果仅是需要判断某个key是否存在,可以用空白标识符_来代替value:
if _, ret := map1["three"] ;ret {
fmt.Print("map1[\"three\"]存在\n")
} else {
fmt.Print("map1[\"three\"]不存在,值为:")
}
使用内建函数delete函数来删除键值对,即使对应的键不在该映射中,delete操作也是安全的
方法
在函数的一节中,我们已经看到了write函数的声明为:
func (file *File) Write(b []byte) (n int, err error)
我们可以抽象出Go中函数的结构为:
func [(p mytype)] funcname([pram type]) [(parm type)] {//body}
其中,函数的(p mytype)为可选部分,具备此部分的函数称为方法(method),这部分称为接收者(receiver)。我们可以为任何已命名的类型,包括自己定义的结构体类型,定义方法。通过receiver,把方法绑定到类型上。下面是一个示例:
package main
import "fmt"
//定义一个矩形类型
type rect struct {
width ,height int
}
//这个方法扩大矩形边长为multiple倍
//这个方法的reciever为*rect
//表示这是定义在rect结构体上的方法
func (r *rect) bigger(multiple int){
r.height *=multiple
r.height *=multiple
}
//方法的reciever可以为结构体类型
//也可以为结构体指针类型
//区别在于当reciever为类型指针时
//可以在该方法内部修改结构体成员
func (r rect) area() int{
return r.width*r.height
}
func main(){
r := rect{width:10,height:5}
fmt.Print("r 's area:",r.area(),"\n")
r.bigger(10)
fmt.Print("r's area:",r.area())
}
//output:
r 's area:50
r's area:5000
以指针或值作为reciever的区别在于::
- 指针可以修改接收者
- 值方法可通过指针和值调用,而指针方法只能通过指针来调用
值方法可以通过指针和值调用,所以下面语句是合法的:
func main(){
r := rect{width:10,height:5}
//通过指针调用
fmt.Print("r 's area:",(&r).area(),"\n")
//通过值调用
fmt.Print("r 's area:",r.area(),"\n")
}
//output:
r 's area:50
r 's area:50
而对于指针方法只能通过指针来调用,你可能会感到疑惑,因为下面的语句也是合法的:
func main(){
r := rect{width:10,height:5}
fmt.Print("r 's area:",r.area(),"\n")
//通过值来调用指针方法(为什么合法?)
r.bigger(10)
fmt.Print("r's area:",r.area())
}
//output:
其实是这样的:如果值是可以寻址的,那么Go会自动插入取址操作符来对付一般的通过值调用的指针方法。在这个例子中,r是可寻址的,因此r.Bigger(10)将被编译器改写为(&r).Bigger。
另外,方法也可以"转换"为函数,这一点便不在这里详谈。
接口
通过方法与接口,Go语言定义了一种与java/C++等OOP语言截然不同的“继承”的形态。通过实现接口定义的方法,便可将reciever的类型变量赋值给接口类型变量,通过接口类型变量来调用到reciever类型的方法,用C++来类比,就是通过父类指针来调用到了派生类的成员函数(不过Go没有这些概念)。下面是一个示例:
package main
import (
"fmt"
"math"
)
//定义了一个接口geometry表示几何类型
type geometry interface {
area() float64
bigger(float64)
}
//矩形和圆形要实现这接口的两个方法
type rect struct {
width, height float64
}
type circle struct {
radius float64
}
//在Go中,实现接口,只需要实现该接口定义的所有方法即可
//矩形的接口方法实现
func (r *rect) bigger(multiple float64) {
r.height *= multiple
r.height *= multiple
}
func (r *rect) area() float64 {
return r.width * r.height
}
//圆形的接口方法实现
func (c *circle) bigger(multiple float64){
c.radius *= multiple
}
func (c *circle) area() float64 {
return math.Pi * c.radius * c.radius
}
//可以把rect和circle类型的变量作为实参
//传递给geometry接口类型的变量
func measure (g geometry){
fmt.Print("geometry 's area:",g.area(),"\n")
g.bigger(2)
fmt.Print("after bigger 2 multiple, area :",g.area(),"\n")
}
func main() {
r := rect{width: 10, height: 5}
c := circle{radius:3}
measure(&r)
measure(&c)
}
//output:
geometry 's area:50
after bigger 2 multiple, area :200
geometry 's area:28.274333882308138
after bigger 2 multiple, area :113.09733552923255
类型转换
- 字面量的值,Go编译器会进行隐式转换:
func main() {
var myInt int32 =5
var myFloat float64 = 6
fmt.Print(myInt,"\n")
fmt.Print(myFloat)
}
这里的6为整型类型的字面值常量 Integer literals.。它赋值给了float64类型变量,编译器进行了隐式类型转换。
- 底层类型不同的变量,需要显式类型转换:
func main() {
var myInt int32 =5
//var myFloat float64 = myInt //error
var myFloat float64 = float64(myInt) //需要显式转换
fmt.Print(myInt,"\n")
fmt.Print(myFloat)
}
这里还要区分静态类型与底层类型:
type IntA int32
type IntB int32
func main() {
var a IntA =1
//var b IntB = a //error
var b IntB = IntB(a)
fmt.Print(a,"\n")
fmt.Print(b)
}
这里IntA为变量a的静态类型,而int32为变量a的底层类型。即使两个类型的底层类型相同,在相互赋值时还是需要强制类型转换的。
接口类型变量的类型转换,有两种情况:
- 普通类型向接口类型的转换:隐式进行
- 接口类型向普通类型的转换:需要类型断言
根据Go 官方文档 所说,所有的类型,都实现了空接口interface{},所以普通类型都可以向interface{}进行类型转换:
func main() {
var x interface{} = "hello" // 字符串常量->interface{}
var y interface{} = []byte{'w','o','r','l','d'} //[]byte ->interface{}
fmt.Print(x," ")
fmt.Printf("%s",y)
}
而接口类型向普通类型的转换,则需要由Comma-ok断言或switch测试来进行了。
Comma-ok断言
语法: value,ok := element.(T)
element必须为ingerface类型,断言失败,ok为false,否则为true,下面是例程:
func main() {
var vars []interface{} = make([]interface{},5)
vars[0] = "one"
vars[1] = "two"
vars[2] = "three"
vars[3] = 10
vars[4] = []byte{'a', 'b', 'c'}
for index, element := range vars {
if value, ok := element.(int); ok {
fmt.Printf("vars[%d] type is int,value is %d \n",index,value)
}else if value,ok := element.(string);ok{
fmt.Printf("vars[%d] type is string,value is %s \n",index,value)
}else if value,ok := element.([]byte);ok{
fmt.Printf("vars[%d] type is []byte,value is %s \n",index,value)
}
}
}
//output:
vars[0] type is string,value is one
vars[1] type is string,value is two
vars[2] type is string,value is three
vars[3] type is int,value is 10
vars[4] type is []byte,value is abc
Comma-ok断言也可以这样使用:
value := element.(T)
但一旦断言失败将产生运行时错误,不推荐使用。
switch测试
switch测试只能在switch语句中使用。将上面的例程改为switch测试:
func main() {
var vars []interface{} = make([]interface{}, 5)
vars[0] = "one"
vars[1] = "two"
vars[2] = "three"
vars[3] = 10
vars[4] = []byte{'a', 'b', 'c'}
for index, element := range vars {
switch value := element.(type) {
case int:
fmt.Printf("vars[%d] type is int,value is %d \n", index, value)
case string:
fmt.Printf("vars[%d] type is string,value is %s \n", index, value)
case []byte:
fmt.Printf("vars[%d] type is []byte,value is %s \n", index, value)
}
}
}
(完)
作者:melonstreet
出处:https://www.cnblogs.com/QG-whz/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

