ciscn复现笔记
 每天复现几道ciscn前几年的逆向题,总结一下
每天复现几道ciscn前几年的逆向题,总结一下
Day1
[CISCN 2022 东北]easycpp
知识点:读代码,常规逆向
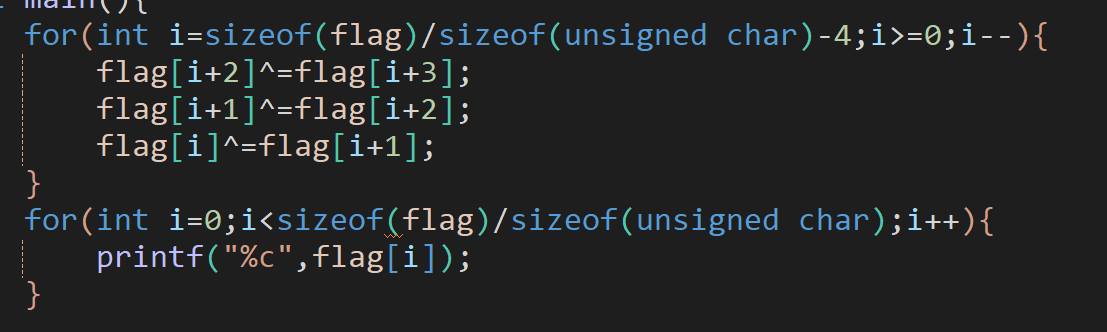
很简单的题,exe,无壳,关键在于读代码,关注注释部分对应的代码

还要注意逆向代码,
正向是从[0]到[len-3],逆向就要从[len-4]到[0]
[CISCN 2023 初赛]babyRE
知识点:.xml文件,Snap!可视化编程
参考
什么是 XML 文件?如何打开 XML 文件和最佳的 XML 浏览器?
以及AI对.xml文件的解释
.xml 文件是指扩展名为 .xml 的文件,代表“可扩展标记语言”(eXtensible Markup Language)。XML 是一种用于定义文档结构的标记语言,旨在存储和传输数据。它被设计为自我描述性的,意味着每个 XML 文件都包含有关其内容的信息,并且可以通过标签来描述数据的结构。
XML 文件的应用场景
- 配置文件:
- 许多应用程序使用 XML 文件作为配置文件,因为它们易于阅读和修改。
- 数据交换:
- XML 用于在不同系统之间传输数据,特别是在 Web 服务中。
- 文档格式:
- XML 可以用来定义复杂的文档格式,如 DocBook 或 MathML。
- Web 开发:
- 在 Web 应用程序中,XML 用于表示复杂的数据结构,尽管 JSON 更加流行。
- RSS 和 Atom:
- XML 是 RSS(简易信息聚合)和 Atom(另一种信息聚合格式)的基础
解压是.xml文件,打开,关注网址https://snap.berkeley.edu
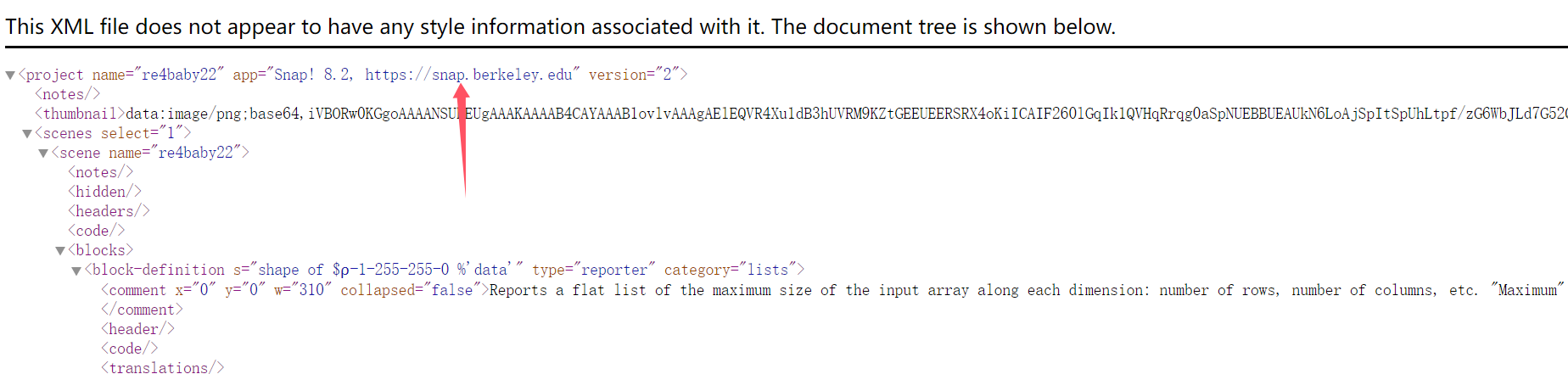
打开,是Snap!可视化编程网站
引用AI的解释:
Snap!(以前称为 "Build Your Own Blocks" 或 BYOB)是由伯克利大学开发的一款基于浏览器的可视化编程环境,主要用于教育目的。它继承了 Scratch 的设计理念,但提供了更多的高级功能和灵活性,允许用户创建更复杂的程序。
Snap! 的主要特点
- 基于浏览器:
- Snap! 是一个完全基于 Web 的应用程序,不需要安装任何软件,只需通过浏览器访问即可使用。
- 可视化编程:
- 用户通过拖拽图形化的积木块来构建程序逻辑,这种方式非常适合初学者学习编程概念。
- 高级特性:
- 除了基本的控制结构和数据类型外,Snap! 还支持自定义积木、第一类函数、列表操作等高级编程特性。
- 支持递归调用,使得编写复杂算法更加容易。
- 扩展性:
- 用户可以轻松地添加新的积木或修改现有积木的行为,极大地增强了系统的灵活性和可定制性。
- 提供插件机制,允许集成外部库和工具。
- 社区和支持:
- 拥有一个活跃的用户社区,提供教程、示例项目和技术支持。
- 适用于各个年龄段的学习者,特别是中小学生和编程初学者。
- 教育用途:
- 广泛应用于计算机科学教育中,帮助学生理解编程基础,如变量、循环、条件语句等。
- 也用于教授更高级的概念,如面向对象编程、事件驱动编程等。
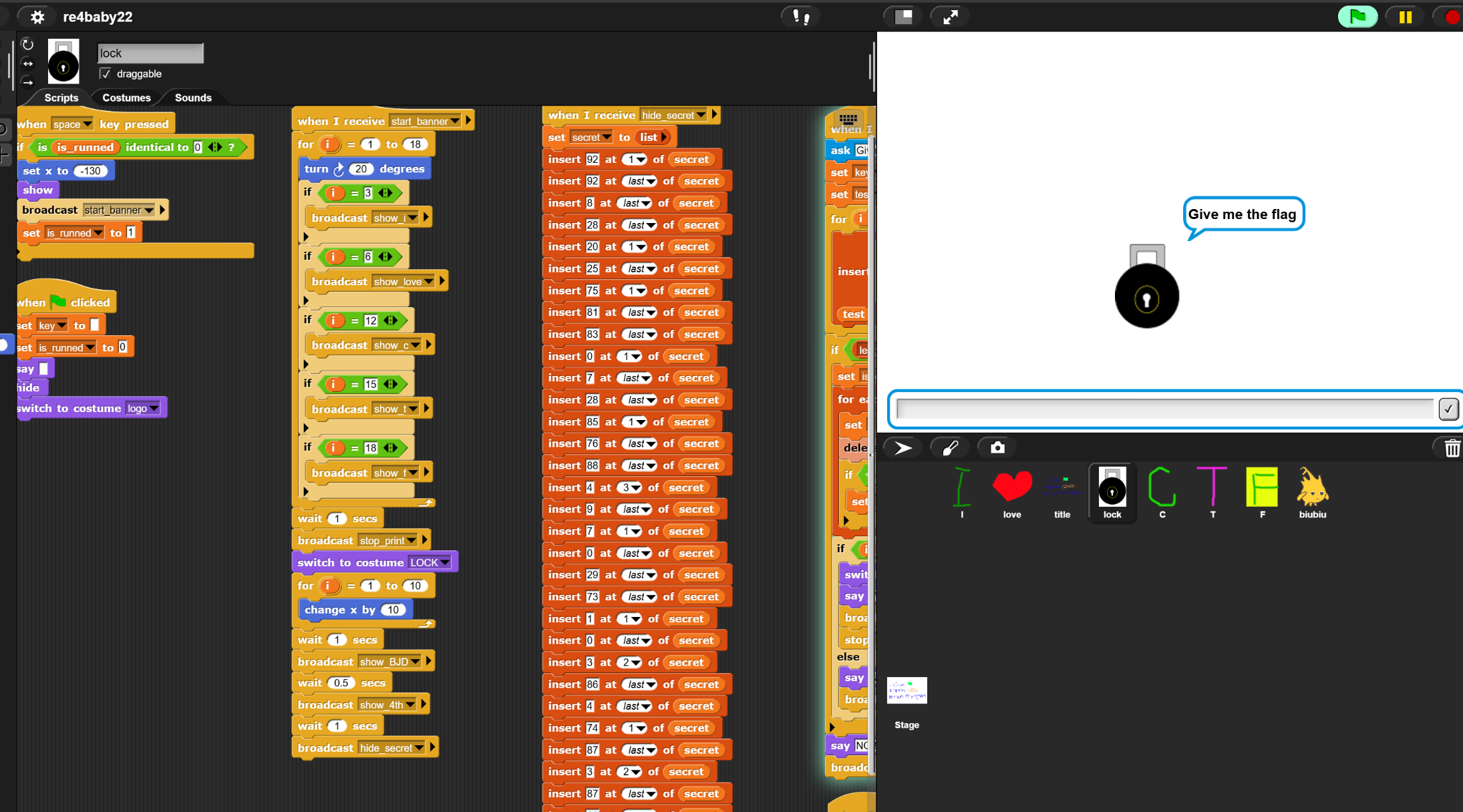
回到主题,看来这个.xml文件是由这个网站的一个项目导出的,拖进去

接下来就是定位到关键加密部分了,不是很难,就是上手操作要一点时间。
[CISCN 2021初赛]babybc
知识点:.bc文件,代码审计
首先解释一下.bc文件(具体结构不作介绍)
.bc文件是 LLVM 编译器基础设施中使用的一种二进制文件格式,它存储的是编译后的中间表示(Intermediate Representation, IR)。这种文件通常由前端编译器生成,并作为后端代码生成器的输入。.bc文件包含优化后的 LLVM IR 代码,以及相关的元数据和符号表信息。
什么是LLVM?
LLVM(Low Level Virtual Machine,底层虚拟机)最初是一个研究项目,旨在开发一种现代的、模块化的、可重用的编译器和工具链技术。随着时间的发展,LLVM 已经从一个单纯的虚拟机项目演变为一个广泛使用的编译器基础设施,支持多种编程语言和目标平台。它不仅包括编译器前端、优化中间表示(IR)、后端代码生成器,还包括调试信息生成、链接器等工具。
clang+llvm构成一个完整的编译器。clang是前端,llvm是后端,它们统称为LLVM。
再深入一点,编译器?
传统的编译器通常分为三个部分:
前端(frontEnd),优化器(Optimizer)和后端(backEnd)。
在编译过程中:
传统编译器工作的时候前端负责解析源代码,检查语法错误,并将其翻译为抽象的语法树(Abstract Syntax Tree)。
优化器对这一中间代码进行优化,试图使代码更高效。
后端则负责将优化器优化后的中间代码转换为目标机器的代码,这一过程后端会最大化的利用目标机器的特殊指令,以提高代码的性能。事实上,不光静态语言如此,动态语言也符合上面这个模型,例如 Java。JVM 也利用上面这个模型,将 Java 代码翻译为Java bytecode。这一模型的好处是,当我们要支持多种语言时,只需要添加多个前端就可以了。当需要支持多种目标机器时,只需要添加多个后端就可以了。对于中间的优化器,我们可以使用通用的中间代码。
现在主要的编译器有gcc,LLVM,Clang
什么是gcc?
GCC(英文全拼:GNU Compiler Collection)是 GNU 工具链的主要组成部分,是一套以 GPL 和 LGPL 许可证发布的程序语言编译器自由软件,由 Richard Stallman 于 1985 年开始开发。
GCC 原名为 GNU C语言编译器,因为它原本只能处理 C 语言,但如今的 GCC ,不仅可以编译 C、C++ 和 Objective-C,还可以通过不同的前端模块支持各种语言,包括 Java、Fortran、Ada、Pascal、Go 和 D 语言等等。
GCC支持多种硬件开发平台,还能进行跨平台交叉编译。此外,GCC是按模块化设计的,可以加入新语言和新CPU架构的支持。GCC、gcc、g++三者之间的关系
gcc(GUN C Compiler)是GCC中的c编译器,而g++(GUN C++ Compiler)是GCC中的c++编译器。
gcc和g++两者都可以编译c和cpp文件,但存在差异。gcc在编译cpp时语法按照c来编译但默认不能链接到c++的库(gcc默认链接c库,g++默认链接c++库)。g++编译.c和.cpp文件都统一按cpp的语法规则来编译。所以一般编译c用gcc,编译c++用g++。
什么是Clang?
LLVM2.0 - Clang
Apple 打算从零开始写 C、C++、Objective-C 语言的前端 Clang,完全替代掉 GCC。
Clang 是 LLVM 的前端,可以用来编译 C,C++,ObjectiveC 等语言。
Clang 则是以 LLVM 为后端的一款高效易用,并且与IDE 结合很好的编译前端。
Clang 只支持C,C++ 和 Objective-C 三种语言。2007 年开始开发,C 编译器最早完成,而由于 Objective-C 只是 C 语言的一个简单扩展,相对简单,很多情况下甚至可以等价地改写为 C 语言对 Objective-C 运行库的函数调用,因此在 2009 年时,已经完全可以用于生产环境。C++ 在后来也得到了支持。
OK,我们回到LLVM的bitcode(bc)
bitcode是LLVM IR的二进制形式。当拿到一个.bc文件,我能做什么?该怎么做?
1.查看
.bc文件的内容将
.bc文件转换为人类可读的.ll文件你可以使用
llvm-dis工具将.bc文件反汇编为文本形式的 LLVM IR 文件(.ll),这样可以直接阅读和分析代码。bash:
llvm-dis input.bc -o=output.ll
-o=output.ll: 指定输出文件名为output.ll。2.编译成可执行文件
clang program.bc -o my_program
program.bc: 输入的.bc文件。
-o my_program: 指定输出的可执行文件名为my_program。具体操作流程参考LLVM生成bc文件 - 逆向随笔|在逆向边缘反复横跳
好了,回到这道题,拿到一个.bc文件

先要把baby.bc文件编译成可执行文件

拿到了ELF文件,现在可以用ida分析了
int __fastcall main(int argc, const char **argv, const char **envp)
{
unsigned __int64 v4; // [rsp+8h] [rbp-20h]
size_t v5; // [rsp+10h] [rbp-18h]
unsigned __int64 i; // [rsp+18h] [rbp-10h]
__isoc99_scanf(&unk_402004, input, envp);
if ( (unsigned int)strlen(input) == 25 )
{
if ( input[0] )
{
if ( (unsigned __int8)(input[0] - '0') > 5u )
return 0;
v5 = strlen(input);
for ( i = 1LL; ; ++i )
{
v4 = i;
if ( i >= v5 )
break;
if ( (unsigned __int8)(input[v4] - '0') > 5u )
return 0;
}
}
if ( (fill_number(input) & 1) != 0 && (docheck() & 1) != 0 )
printf("CISCN{MD5(%s)}", input);
}
return 0;
}
__int64 __fastcall fill_number(__int64 a1)
{
_BYTE *v2; // [rsp+0h] [rbp-70h]
char v3; // [rsp+Fh] [rbp-61h]
_BYTE *v4; // [rsp+10h] [rbp-60h]
char v5; // [rsp+1Fh] [rbp-51h]
_BYTE *v6; // [rsp+20h] [rbp-50h]
char v7; // [rsp+2Fh] [rbp-41h]
_BYTE *v8; // [rsp+30h] [rbp-40h]
char v9; // [rsp+3Eh] [rbp-32h]
char v10; // [rsp+3Fh] [rbp-31h]
__int64 v11; // [rsp+40h] [rbp-30h]
__int64 v12; // [rsp+48h] [rbp-28h]
char v13; // [rsp+5Fh] [rbp-11h]
__int64 v14; // [rsp+68h] [rbp-8h]
v14 = 0LL;
do
{
v11 = v14;
v12 = 5 * v14;
v13 = *(_BYTE *)(a1 + 5 * v14);
if ( map[5 * v14] )
{
v10 = 0;
if ( v13 != '0' )
return v10 & 1;
}
else
{
map[5 * v14] = v13 - '0'; // a1[0+5*v14]
}
v8 = &map[5 * v14 + 1];
v9 = *(_BYTE *)(a1 + v12 + 1);
if ( *v8 )
{
v10 = 0;
if ( v9 != '0' )
return v10 & 1;
}
else
{
*v8 = v9 - '0'; // a1[1+5*v14]
}
v6 = &map[5 * v14 + 2];
v7 = *(_BYTE *)(a1 + v12 + 2);
if ( *v6 )
{
v10 = 0;
if ( v7 != '0' )
return v10 & 1;
}
else
{
*v6 = v7 - '0';
}
v4 = &map[5 * v14 + 3];
v5 = *(_BYTE *)(a1 + v12 + 3);
if ( *v4 )
{
v10 = 0;
if ( v5 != '0' )
return v10 & 1;
}
else
{
*v4 = v5 - '0';
}
v2 = &map[5 * v14 + 4];
v3 = *(_BYTE *)(a1 + v12 + 4);
if ( *v2 )
{
v10 = 0;
if ( v3 != '0' )
return v10 & 1;
}
else
{
*v2 = v3 - '0';
}
++v14;
v10 = 1;
}
while ( v11 + 1 < 5 );
return v10 & 1;
}
__int64 docheck()
{
char *v1; // [rsp+0h] [rbp-C8h]
char *v2; // [rsp+8h] [rbp-C0h]
char *v3; // [rsp+10h] [rbp-B8h]
char *v4; // [rsp+18h] [rbp-B0h]
char v5; // [rsp+21h] [rbp-A7h]
char v6; // [rsp+22h] [rbp-A6h]
char v7; // [rsp+23h] [rbp-A5h]
char v8; // [rsp+24h] [rbp-A4h]
char v9; // [rsp+25h] [rbp-A3h]
char v10; // [rsp+26h] [rbp-A2h]
char v11; // [rsp+27h] [rbp-A1h]
__int64 v12; // [rsp+28h] [rbp-A0h]
__int64 v13; // [rsp+38h] [rbp-90h]
char v14; // [rsp+46h] [rbp-82h]
char v15; // [rsp+47h] [rbp-81h]
__int64 v16; // [rsp+48h] [rbp-80h]
__int64 v17; // [rsp+50h] [rbp-78h]
char v18; // [rsp+5Fh] [rbp-69h]
char *v19; // [rsp+60h] [rbp-68h]
__int64 v20; // [rsp+68h] [rbp-60h]
char *v21; // [rsp+70h] [rbp-58h]
char v22; // [rsp+7Fh] [rbp-49h]
char *v23; // [rsp+80h] [rbp-48h]
__int64 v24; // [rsp+88h] [rbp-40h]
char *v25; // [rsp+90h] [rbp-38h]
__int64 v26; // [rsp+A0h] [rbp-28h]
__int64 v27; // [rsp+B0h] [rbp-18h]
char v28[6]; // [rsp+BCh] [rbp-Ch] BYREF
char v29[6]; // [rsp+C2h] [rbp-6h] BYREF
v27 = 0LL;
do
{
v24 = v27;
memset(v29, 0, sizeof(v29));
v25 = &v29[(unsigned __int8)map[5 * v27]];
if ( *v25
|| (*v25 = 1, v23 = &v29[(unsigned __int8)map[5 * v27 + 1]], *v23)
|| (*v23 = 1, v2 = &v29[(unsigned __int8)map[5 * v27 + 2]], *v2)
|| (*v2 = 1, v1 = &v29[(unsigned __int8)map[5 * v27 + 3]], *v1)
|| (*v1 = 1, v29[(unsigned __int8)map[5 * v27 + 4]]) )
{
v22 = 0;
return v22 & 1;
}
++v27;
}
while ( v24 + 1 < 5 );
v26 = 0LL;
while ( 1 )
{
v20 = v26;
memset(v28, 0, sizeof(v28));
v21 = &v28[(unsigned __int8)map[v26]];
if ( *v21 )
break;
*v21 = 1;
v19 = &v28[(unsigned __int8)map[v26 + 5]];
if ( *v19 )
break;
*v19 = 1;
v4 = &v28[(unsigned __int8)map[v26 + 10]];
if ( *v4 )
break;
*v4 = 1;
v3 = &v28[(unsigned __int8)map[v26 + 15]];
if ( *v3 )
break;
*v3 = 1;
if ( v28[(unsigned __int8)map[v26 + 20]] )
break;
++v26; // 为0则设置为1
if ( v20 + 1 >= 5 )
{
v16 = 0LL;
while ( 1 )
{
v17 = v16;
v18 = row[4 * v16];
if ( v18 == 1 )
{
if ( map[5 * v16] < map[5 * v16 + 1] )
goto LABEL_27;
}
else if ( v18 == 2 && map[5 * v16] > map[5 * v16 + 1] )
{
LABEL_27: // 不对
v22 = 0;
return v22 & 1;
}
v15 = row[4 * v16 + 1];
if ( v15 == 1 )
{
if ( map[5 * v16 + 1] < map[5 * v16 + 2] )
goto LABEL_27;
}
else if ( v15 == 2 && map[5 * v16 + 1] > map[5 * v16 + 2] )
{
goto LABEL_27;
}
v6 = row[4 * v16 + 2];
if ( v6 == 1 )
{
if ( map[5 * v16 + 2] < map[5 * v16 + 3] )
goto LABEL_27;
}
else if ( v6 == 2 && map[5 * v16 + 2] > map[5 * v16 + 3] )
{
goto LABEL_27;
}
v5 = row[4 * v16 + 3];
if ( v5 == 1 )
{
if ( map[5 * v16 + 3] < map[5 * v16 + 4] )
goto LABEL_27;
}
else if ( v5 == 2 && map[5 * v16 + 3] > map[5 * v16 + 4] )
{
goto LABEL_27;
}
++v16;
if ( v17 + 1 >= 5 )
{
v12 = 0LL;
while ( 1 )
{
v13 = v12 + 1;
v14 = col[5 * v12];
if ( v14 == 1 )
{
v11 = 0;
if ( map[5 * v12] > map[5 * v13] )
goto LABEL_26;
}
else if ( v14 == 2 )
{
v11 = 0;
if ( map[5 * v12] < map[5 * v13] )
{
LABEL_26: // 不对
v22 = v11;
return v22 & 1;
}
}
v10 = col[5 * v12 + 1];
if ( v10 == 1 )
{
v11 = 0;
if ( map[5 * v12 + 1] > map[5 * v13 + 1] )
goto LABEL_26;
}
else if ( v10 == 2 )
{
v11 = 0;
if ( map[5 * v12 + 1] < map[5 * v13 + 1] )
goto LABEL_26;
}
v9 = col[5 * v12 + 2];
if ( v9 == 1 )
{
v11 = 0;
if ( map[5 * v12 + 2] > map[5 * v13 + 2] )
goto LABEL_26;
}
else if ( v9 == 2 )
{
v11 = 0;
if ( map[5 * v12 + 2] < map[5 * v13 + 2] )
goto LABEL_26;
}
v8 = col[5 * v12 + 3];
if ( v8 == 1 )
{
v11 = 0;
if ( map[5 * v12 + 3] > map[5 * v13 + 3] )
goto LABEL_26;
}
else if ( v8 == 2 )
{
v11 = 0;
if ( map[5 * v12 + 3] < map[5 * v13 + 3] )
goto LABEL_26;
}
v7 = col[5 * v12 + 4];
if ( v7 == 1 )
{
v11 = 0;
if ( map[5 * v12 + 4] > map[5 * v13 + 4] )
goto LABEL_26;
}
else if ( v7 == 2 )
{
v11 = 0;
if ( map[5 * v12 + 4] < map[5 * v13 + 4] )
goto LABEL_26;
}
++v12;
v11 = 1;
if ( v13 >= 4 )
goto LABEL_26;
}
}
}
}
}
v22 = 0;
return v22 & 1;
}
就是一个5x5的数独表格,填数字进去要满足几个条件:
每一行不重复
每一列不重复
数字范围:0~5
unsigned char map[] = { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 0, 3, 0, 0, 0, 0, 0, 0, }; //每一行每一列数字不同,map[2][2]=4;map[3][3]=3; //map[i]不为0时输入必须为0 unsigned char row[] = { 0, 0, 0, 1, 1, 0, 0, 0, 2, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, }; //row[i]==1:左边大于右边 //row[i]==2:右边大于左边unsigned char col[] =
{
0, 0, 2, 0, 2,
0, 0, 0, 0, 0,
0, 0, 0, 1, 0,
0, 1, 0, 0, 1
};
//col[i]2:上面大于下面
//col[i]1:上面小于下面
把这几个条件用z3表示就可以解出满足条件的map,最后得到输入的flag
exp如下:
from z3 import *
from hashlib import md5
map=[[0 for i in range(5)] for j in range(5)]
row=[[0,0,0,1],
[1,0,0,0],
[2,0,0,1],
[0,0,0,0],
[1,0,1,0]]
#row[i*4+j]==1,左边大于右边
#row[i*4+j]==2,右边大于左边
col=[[0,0,2,0,2],
[0,0,0,0,0],
[0,0,0,1,0],
[0,1,0,0,1]]
#col[i]==1:上面小于下面
#col[i]==2:上面大于下面
s=Solver()
for i in range(5):
for j in range(5):
map[i][j]=Int('x%d%d'%(i,j))#初始化变量
s.add(map[2][2]==4)
s.add(map[3][3]==3)
for i in range(5):
for j in range(5):
s.add(map[i][j]>=1)
s.add(map[i][j]<=5)#取值范围0~5
for i in range(5):
for j in range(4):
if row[i][j]==1:
s.add(map[i][j]>map[i][j+1])#row[i*4+j]==1,左边大于右边
elif row[i][j]==2:
s.add(map[i][j]<map[i][j+1])##row[i*4+j]==2,右边大于左边
for j in range(5):
for i in range(4):
if col[i][j]==1:
s.add(map[i][j]<map[i+1][j])#col[i]==1:上面小于下面
elif col[i][j]==2:
s.add(map[i][j]>map[i+1][j])#col[i]==2:上面大于下面
for i in range(5):
for j in range(5):
for k in range(j):
s.add(map[i][j]!=map[i][k])#每一行无相同数字
for j in range(5):
for i in range(5):
for k in range(i):
s.add(map[i][j]!=map[k][j])#每一列无相同数字
answer = s.check()
if answer == sat:
flag=[]
m = s.model()
for i in range(5):
for j in range(5):
flag.append(m[map[i][j]].as_long())
#print(flag)
for i in range(len(flag)):
flag[i]+=48
flag[12]=48
flag[18]=48
flag=bytes(flag)
print(flag)
print("CISCN{"+md5(flag).hexdigest()+"}")
参考资料:
详解三大编译器:gcc、llvm 和 clang_clang gcc llvm-CSDN博客
Linux环境下GCC基本使用详解(含实例)_linux gcc-CSDN博客
通义千问
[CISCN 2023 初赛]ezbyte
知识点:c++异常处理机制,DWARF Expression
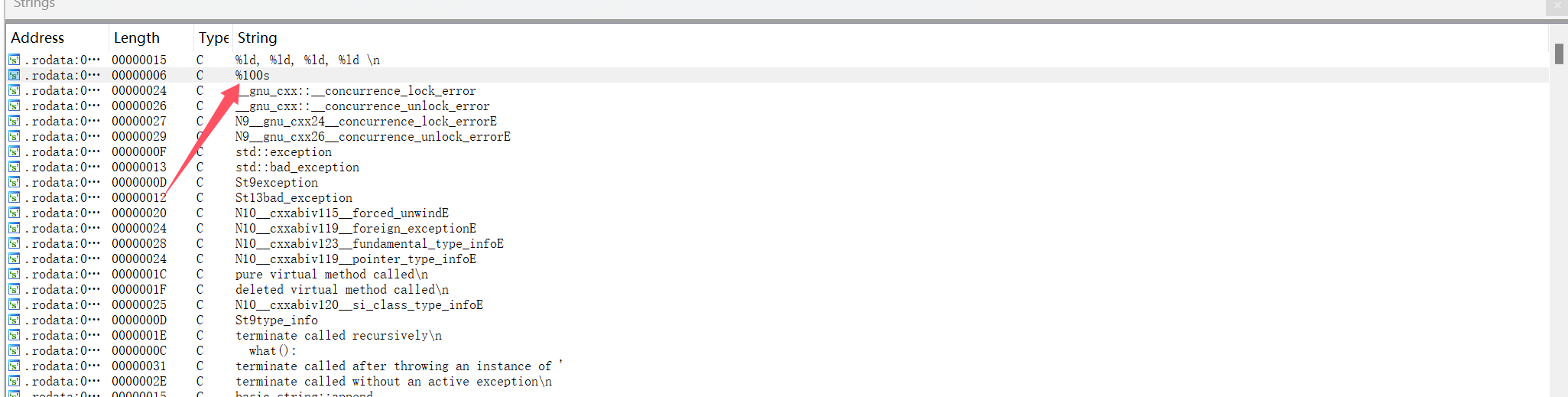
搜索字符串,定位到%100s
int __fastcall main(int argc, const char **argv, const char **envp)
{
_QWORD *v3; // rax
int result; // eax
__int64 flag[129]; // [rsp+10h] [rbp-420h] BYREF
unsigned __int64 v6; // [rsp+418h] [rbp-18h]
v6 = __readfsqword(0x28u);
memset(flag, 0, 1024);
scanf((__int64)"%100s", flag);
v3 = sub_46F4F0(qword_5D5520, (__int64)flag);
sub_46E060((__int64)v3, (__int64 (*)(void))sub_46EE20);
sub_404C21((unsigned __int8 *)flag);
result = 0;
if ( __readfsqword(0x28u) != v6 )
sub_535290();
return result;
}
能够判断这里就是main函数,重点关注 sub_404C21
__int64 __fastcall sub_404C21(unsigned __int8 *a1)
{
__int64 result; // rax
result = *a1;
if ( (_BYTE)result == 'f' )
{
result = a1[1];
if ( (_BYTE)result == 'l' )
{
result = a1[2];
if ( (_BYTE)result == 'a' )
{
result = a1[3];
if ( (_BYTE)result == 'g' )
{
result = a1[4];
if ( (_BYTE)result == '{' )
{
result = a1[41];
if ( (_BYTE)result == '}' )
{
result = a1[40];
if ( (_BYTE)result == '1' )
{
result = a1[39];
if ( (_BYTE)result == '6' )
{
result = a1[38];
if ( (_BYTE)result == '8' )
{
result = a1[37];
if ( (_BYTE)result == '3' )
sub_404BF5();
}
}
}
}
}
}
}
}
}
return result;
}
发现这个函数是对输入的flag作了前五位和后五位的判断
中间那部分呢?在汇编找找看
.text:0000000000404C21 ; __unwind {
.text:0000000000404C21 endbr64
.text:0000000000404C25 push rbp
.text:0000000000404C26 mov rbp, rsp
.text:0000000000404C29 sub rsp, 30h
.text:0000000000404C2D mov [rbp+var_28], rdi
.text:0000000000404C31 mov rax, [rbp+var_28]
.text:0000000000404C35 movzx eax, byte ptr [rax]
.text:0000000000404C38 cmp al, 66h ; 'f'
.text:0000000000404C3A jnz loc_404D22
.text:0000000000404C40 mov rax, [rbp+var_28]
.text:0000000000404C44 add rax, 1
.text:0000000000404C48 movzx eax, byte ptr [rax]
.text:0000000000404C4B cmp al, 6Ch ; 'l'
.text:0000000000404C4D jnz loc_404D22
.text:0000000000404C53 mov rax, [rbp+var_28]
.text:0000000000404C57 add rax, 2
.text:0000000000404C5B movzx eax, byte ptr [rax]
.text:0000000000404C5E cmp al, 61h ; 'a'
.text:0000000000404C60 jnz loc_404D22
.text:0000000000404C66 mov rax, [rbp+var_28]
.text:0000000000404C6A add rax, 3
.text:0000000000404C6E movzx eax, byte ptr [rax]
.text:0000000000404C71 cmp al, 67h ; 'g'
.text:0000000000404C73 jnz loc_404D22
.text:0000000000404C79 mov rax, [rbp+var_28]
.text:0000000000404C7D add rax, 4
.text:0000000000404C81 movzx eax, byte ptr [rax]
.text:0000000000404C84 cmp al, 7Bh ; '{'
.text:0000000000404C86 jnz loc_404D22
.text:0000000000404C8C mov rax, [rbp+var_28]
.text:0000000000404C90 add rax, 29h ; ')'
.text:0000000000404C94 movzx eax, byte ptr [rax]
.text:0000000000404C97 cmp al, 7Dh ; '}'
.text:0000000000404C99 jnz loc_404D22
.text:0000000000404C9F mov rax, [rbp+var_28]
.text:0000000000404CA3 add rax, 28h ; '('
.text:0000000000404CA7 movzx eax, byte ptr [rax]
.text:0000000000404CAA cmp al, 31h ; '1'
.text:0000000000404CAC jnz short loc_404D22
.text:0000000000404CAE mov rax, [rbp+var_28]
.text:0000000000404CB2 add rax, 27h ; '''
.text:0000000000404CB6 movzx eax, byte ptr [rax]
.text:0000000000404CB9 cmp al, 36h ; '6'
.text:0000000000404CBB jnz short loc_404D22
.text:0000000000404CBD mov rax, [rbp+var_28]
.text:0000000000404CC1 add rax, 26h ; '&'
.text:0000000000404CC5 movzx eax, byte ptr [rax]
.text:0000000000404CC8 cmp al, 38h ; '8'
.text:0000000000404CCA jnz short loc_404D22
.text:0000000000404CCC mov rax, [rbp+var_28]
.text:0000000000404CD0 add rax, 25h ; '%'
.text:0000000000404CD4 movzx eax, byte ptr [rax]
.text:0000000000404CD7 cmp al, 33h ; '3'
.text:0000000000404CD9 jnz short loc_404D22
.text:0000000000404CDB mov rax, [rbp+var_28]
.text:0000000000404CDF mov rax, [rax+5]
.text:0000000000404CE3 mov [rbp+var_20], rax
.text:0000000000404CE7 mov rax, [rbp+var_28]
.text:0000000000404CEB mov rax, [rax+0Dh]
.text:0000000000404CEF mov [rbp+var_18], rax
.text:0000000000404CF3 mov rax, [rbp+var_28]
.text:0000000000404CF7 mov rax, [rax+15h]
.text:0000000000404CFB mov [rbp+var_10], rax
.text:0000000000404CFF mov rax, [rbp+var_28]
.text:0000000000404D03 mov rax, [rax+1Dh]
.text:0000000000404D07 mov [rbp+var_8], rax
.text:0000000000404D0B mov r15, [rbp+var_8]
.text:0000000000404D0F mov r14, [rbp+var_10]
.text:0000000000404D13 mov r13, [rbp+var_18]
.text:0000000000404D17 mov r12, [rbp+var_20]
.text:0000000000404D1B call sub_404BF5
在最后那里找到中间被分为4个部分分别存入r12~r15(顺序是r15-r14-r13-r12)
前面定位%100s时还有一个字符串"yes"
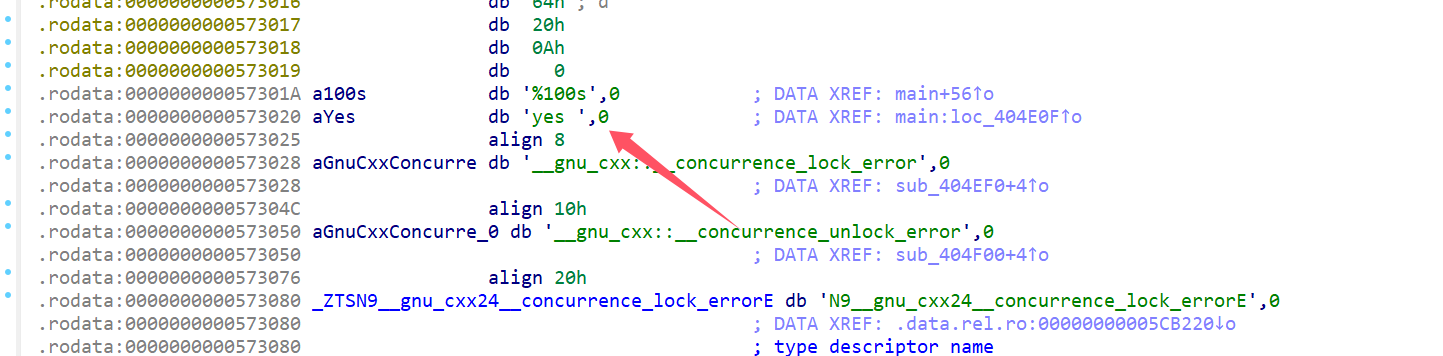
猜测它所在的位置就是判断输入正确的地方,查看汇编
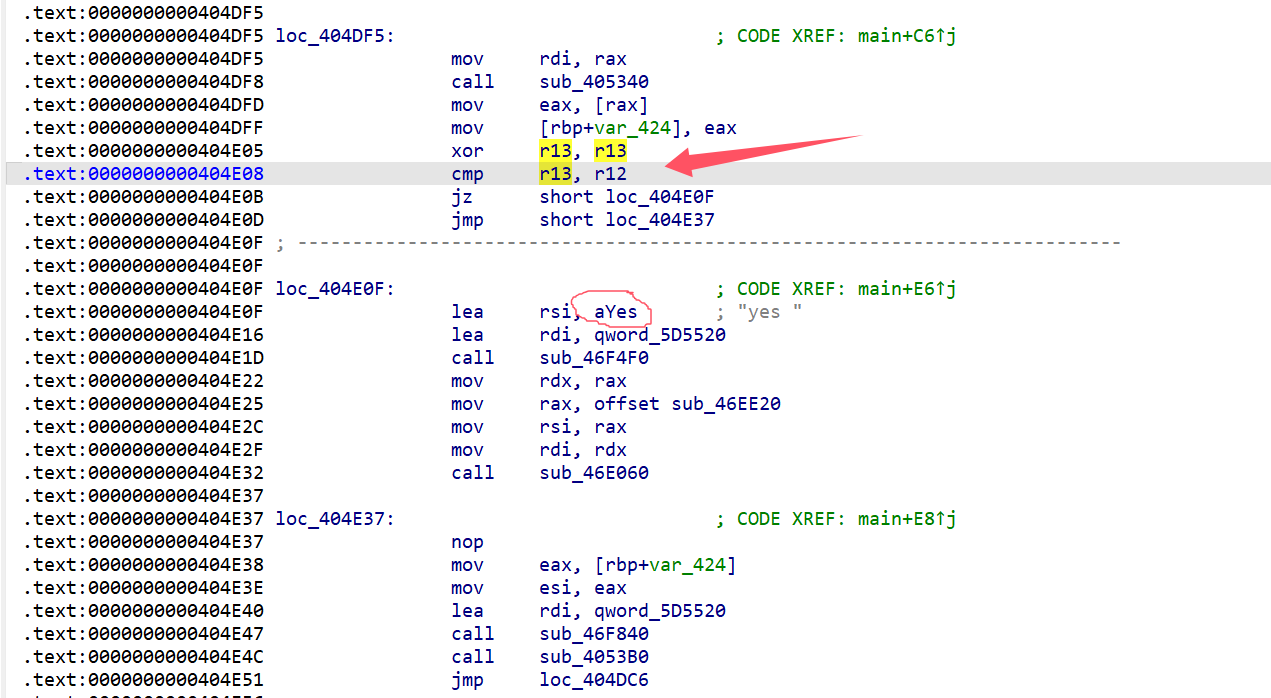
这里最后是判断r12是否与r13相等,前面有 xor r13, r13,那么r13=0后与r12比较,要跳转到yes,那r12应该为0,但是找不到对r12的操作码。
参考以下文章:
通过DWARF Expression将代码隐藏在栈展开过程中-软件逆向-看雪-安全社区|安全招聘|kanxue.com
C++异常处理机制(throw、try、catch、finally) - 知道了呀~ - 博客园
为此,我们可以大致猜测就是运行程序,触发一个异常,然后通过此条转到想要操作的地方,进行操作。
当触发一个异常时,程序会沿着调用链不断向上进行栈展开,直到寻找到能处理这个异常的catch块。栈展开的过程也是一个程序运行状态恢复的过程,考虑如下调用链:f1 -> f2 -> f3,在f3发生了一个异常,在f1中的catch块能处理这个异常。为了能正常执行f1中的catch块,有必要恢复一些基本的程序状态,比如RBP与RSP寄存器,否则f1中的catch块就不能正常访问局部变量,即无法正常执行。
当触发异常的时候,程序会沿着调用链不断向上进行栈展开,直到寻找到能处理这个异常的catch块。
然而在这个过程中DWARF调试信息完成这个恢复过程
在DWARF 3标准中引入了一个DWARF Expression,这个DWARF Expression变相就是一个虚拟机
使用readelf -wf ezbyte_patch >1.txt获取Dwarf调试信息
DW_CFA_val_expression: r12 (r12)
(DW_OP_constu: 2616514329260088143;
DW_OP_constu: 1237891274917891239;
DW_OP_constu: 1892739;
DW_OP_breg12 (r12): 0;
DW_OP_plus;
DW_OP_xor;
DW_OP_xor;
--------------------------------------
DW_OP_constu: 8502251781212277489;
DW_OP_constu: 1209847170981118947;
DW_OP_constu: 8971237;
DW_OP_breg13 (r13): 0;
DW_OP_plus;
DW_OP_xor;
DW_OP_xor;
DW_OP_or;
--------------------------------------
DW_OP_constu: 2451795628338718684;
DW_OP_constu: 1098791727398412397;
DW_OP_constu: 1512312;
DW_OP_breg14 (r14): 0;
DW_OP_plus;
DW_OP_xor;
DW_OP_xor;
DW_OP_or;
--------------------------------------
DW_OP_constu: 8722213363631027234;
DW_OP_constu: 1890878197237214971;
DW_OP_constu: 9123704;
DW_OP_breg15 (r15): 0;
DW_OP_plus;
DW_OP_xor;
DW_OP_xor;
DW_OP_or)
其中部分操作的具体解释如下:
DW_OP_constu: 8722213363631027234:将一个无符号整数压入堆栈。
DW_OP_constu: 1890878197237214971:将另一个无符号整数压入堆栈。
DW_OP_constu: 9123704:将第三个无符号整数压入堆栈。
DW_OP_breg15 (r15): 0:从 r15 这个寄存器中读取一个值,并将其加上偏移量 0。
DW_OP_plus:从堆栈中弹出两个值,相加后再将结果压入堆栈。
DW_OP_xor:从堆栈中弹出两个值,进行异或运算后再将结果压入堆栈。
DW_OP_xor:重复前面的操作,再进行一次异或运算。DW_OP_or;:从堆栈中弹出两个值,进行或运算后再将结果压入堆栈。
转换成python代码如下:
r12, r13, r14, r15 = 0, 0, 0, 0
r12 = (r12 + 1892739) ^ 1237891274917891239 ^ 2616514329260088143
r13 = (r13 + 8971237) ^ 1209847170981118947 ^ 8502251781212277489
r14 = (r14 + 1512312) ^ 1098791727398412397 ^ 2451795628338718684
r15 = (r15 + 9123704) ^ 1890878197237214971 ^ 8722213363631027234
r12 = r12 | r13 | r14 | r15
#最终r12的值应该为0
因此需要逆向倒推r12~r15的值
exp如下:
import binascii
def reverse_by_pairs(s):
# 两两分组
pairs = [s[i:i+2] for i in range(0, len(s), 2)]
# 将分组后的结果倒序
reversed_pairs = pairs[::-1]
# 将倒序的分组拼接回字符串
return ''.join(reversed_pairs)
if __name__ == "__main__":
flag=[]
r12=(2616514329260088143^1237891274917891239)-1892739
r13=(8502251781212277489^1209847170981118947)-8971237
r14=(2451795628338718684^1098791727398412397)-1512312
r15=(8722213363631027234^1890878197237214971)-9123704
print("r15:"+hex(r15))
print("r14:"+hex(r14))
print("r13:"+hex(r13))
print("r12:"+hex(r12))
'''
r15:0x6336396431336361
r14:0x2d393663612d3439
r13:0x65342d653037652d
r12:0x3562666539303665
'''
'''
按顺序拼凑起来是(去掉0x:63363964313363612d393663612d343965342d653037652d3562666539303665
'''
flag="63363964313363612d393663612d343965342d653037652d3562666539303665"
flag=reverse_by_pairs(flag)
print("flag{"+binascii.unhexlify(flag).decode(encoding="utf-8")+"3861}")
#flag{e609efb5-e70e-4e94-ac69-ac31d96c3861}
另外在读大佬的博客时还发现了一种方法
先恢复一些符号然后调试找到DWARF Expression的''虚拟机'',然后逆出前面的操作。
收获
-
整道题复现下来发现自己还有很多东西没学(哭
-
找到了老大哥的blog,嘿嘿。
-
初识异常处理机制和DWARF Expression
不足
- 还是不会恢复符号
- 另外对异常处理机制的学习只能说算是开了个眼,深层次的还是搞不懂
逆向的路还很长很长~
参考资料:
[2023 CTF国赛初赛(CISCN) re- ez_byte_ciscn 2023 初赛]ezbyte-CSDN博客
[CISCN 2023 初赛]moveAside
知识点:ltrace指令,python实现linux交互,plt,mov混淆
ida分析,搜索字符串,找到一个可疑的字符串
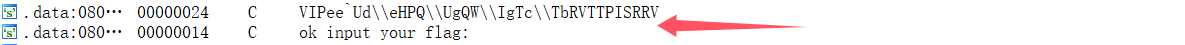
提取关键字符串
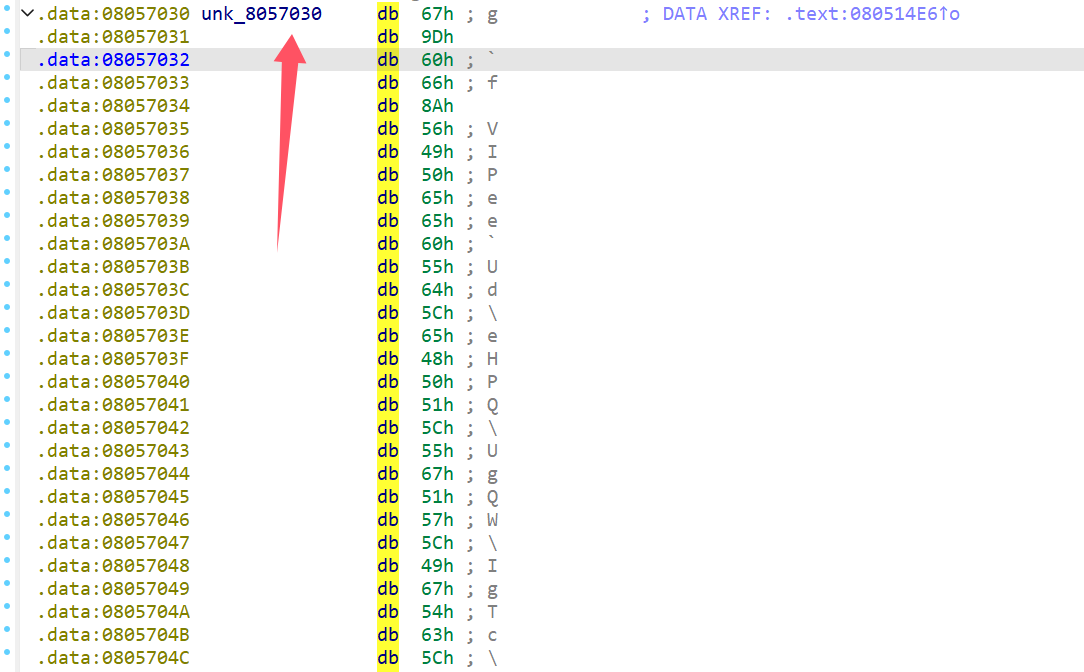
main被混淆了,具体混淆技术不清楚
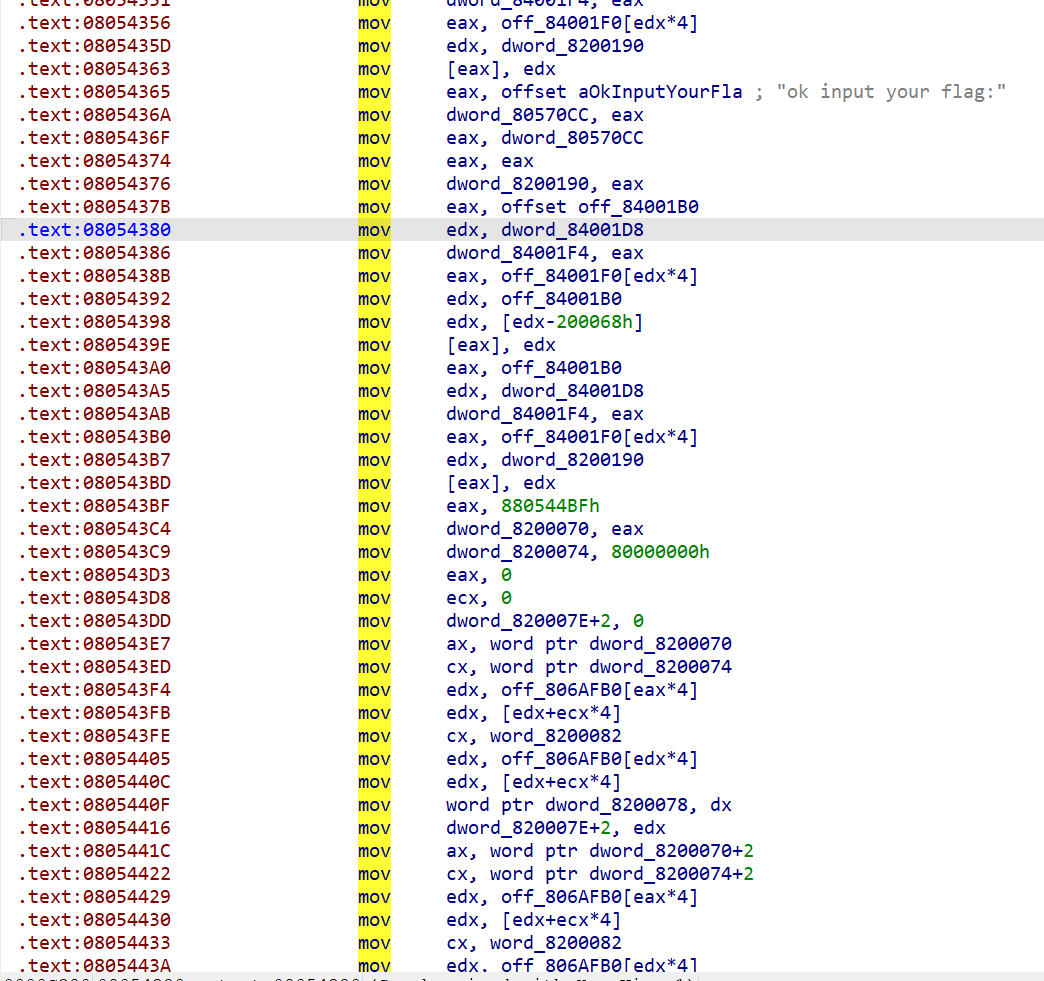
这时可以用ltrace跟踪调用的函数
ltrace是一个 Linux 下的命令行工具,用于跟踪程序运行过程中调用的 动态库函数 和 库函数内部调用的其他库函数。它对调试和分析程序的动态行为非常有帮助,尤其是研究程序如何与共享库交互。
跟踪后显示以下内容
sigaction(SIGSEGV, { 0x8049090, <>, 0, nil }, nil) = 0
sigaction(SIGILL, { 0x8049117, <>, 0, nil }, nil) = 0
--- SIGSEGV (Segmentation fault) ---
time(nil) = 1733742336
--- SIGSEGV (Segmentation fault) ---
srand(1733742336) = <void>
--- SIGILL (Illegal instruction) ---
--- SIGSEGV (Segmentation fault) ---
rand() = 598656811
--- SIGILL (Illegal instruction) ---
--- SIGILL (Illegal instruction) ---
--- SIGILL (Illegal instruction) ---
--- SIGILL (Illegal instruction) ---
--- SIGILL (Illegal instruction) ---
--- SIGILL (Illegal instruction) ---
--- SIGILL (Illegal instruction) ---
--- SIGILL (Illegal instruction) ---
--- SIGILL (Illegal instruction) ---
--- SIGILL (Illegal instruction) ---
--- SIGILL (Illegal instruction) ---
--- SIGILL (Illegal instruction) ---
--- SIGILL (Illegal instruction) ---
--- SIGILL (Illegal instruction) ---
--- SIGILL (Illegal instruction) ---
--- SIGILL (Illegal instruction) ---
--- SIGILL (Illegal instruction) ---
--- SIGILL (Illegal instruction) ---
--- SIGILL (Illegal instruction) ---
--- SIGILL (Illegal instruction) ---
--- SIGILL (Illegal instruction) ---
--- SIGILL (Illegal instruction) ---
--- SIGSEGV (Segmentation fault) ---
puts("ok input your flag:"ok input your flag:
) = 20
--- SIGSEGV (Segmentation fault) ---
__isoc99_scanf(0x805709b, 0x8600198, 263, 56
输入123456,结果如下
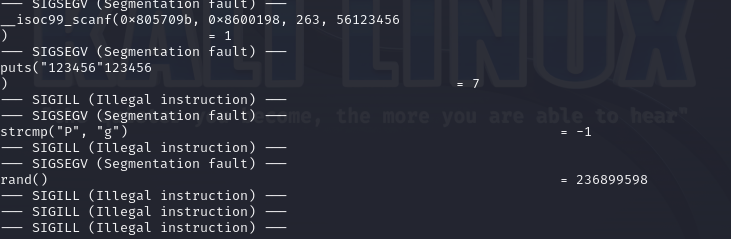
可以发现调用了strcmp函数并返回了-1,而且比较的两个值分别是'p'和'g'
再尝试flag{123456}
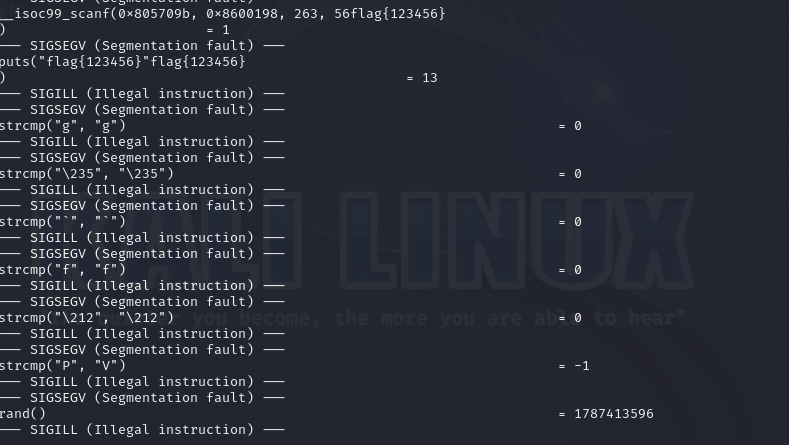
发现前5个strcmp都是返回的0(正确匹配),第六个返回的-1(错误匹配)
可以确定程序是对输入的每个字符进行加密后分别调用strcmp进行比较,那么可以确定是单表映射
猜测前面的可疑字符串就是密文
注意到strcmp时会把加密后的输入和密文进行对比,那可以获取每个字符加密后的结果然后依次比较爆破
获取加密结果的字符的方法是将strcmp直接改成puts

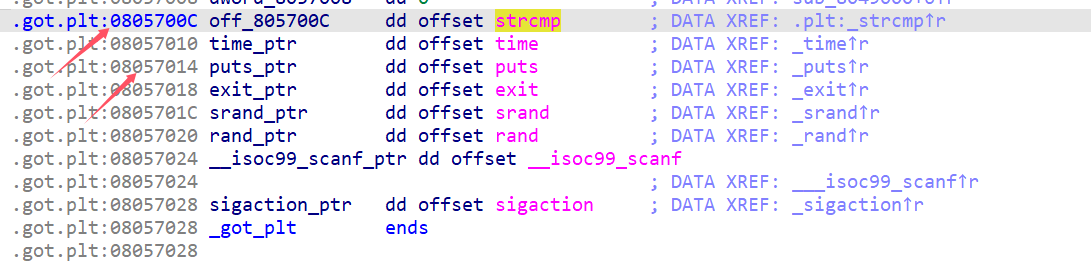
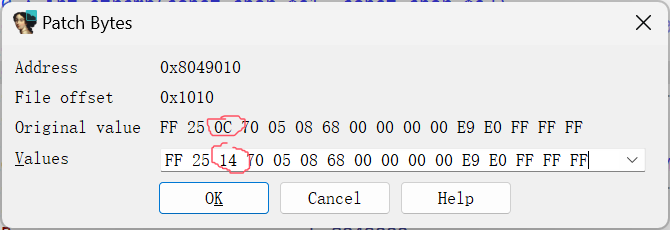
然后右键->Patching->Apply patches to->Apply patches保存为新的文件,再重新运行
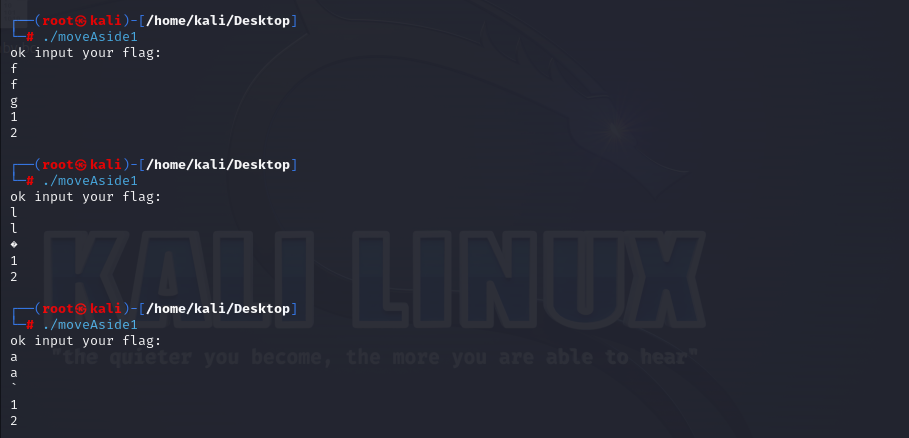
可见输入'f'后返回'g',输入'a'后返回'`',由此可以构造脚本
exp:
from pwn import *
context(log_level='debug')
# 密文
flag = [0x67, 0x9D, 0x60, 0x66, 0x8A, 0x56, 0x49, 0x50, 0x65, 0x65,
0x60, 0x55, 0x64, 0x5C, 0x65, 0x48, 0x50, 0x51, 0x5C, 0x55,
0x67, 0x51, 0x57, 0x5C, 0x49, 0x67, 0x54, 0x63, 0x5C, 0x54,
0x62, 0x52, 0x56, 0x54, 0x54, 0x50, 0x49, 0x53, 0x52, 0x52,
0x56, 0x8C]
flag1 = ''
index = 0
while True:
for i in range(33, 127):
p = process("./moveAside1")
# input your 。。。回显
p.recvline()
# 输入
p.sendline(chr(i).encode())
# 题目中的原样输出
p.recvline()
# 修改的strcmpputs回显
a = p.recvline().decode('ISO-8859-1').strip('\n')
print(flag1)
# 回显可对应密文则加上输入
if index == len(flag):
break
if ord(a) == flag[index]:
index += 1
flag1 += chr(i)
p.close()
print(flag1)
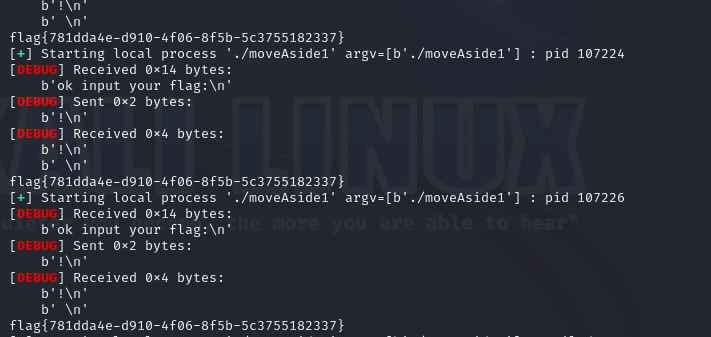
爆破出flag为
#flag{781dda4e-d910-4f06-8f5b-5c3755182337}
收获
ltrace指令
功能:
跟踪动态链接库函数调用:
例如
printf,malloc,strcpy,strcmp等标准库函数。显示函数的参数和返回值:
在函数调用时记录传入参数,在返回时显示返回值。
动态链接库交互分析:
可以观察程序与动态库(如 libc.so、libm.so)之间的具体交互。
调试与逆向工程辅助:
逆向分析程序的动态行为,比如某些加密或解密逻辑。
性能调试:
了解程序在某些动态库调用上的瓶颈。
使用
ltrace ./program ltrace -e malloc ./your_program #跟踪特定函数调用 ltrace -o output.txt ./your_program #输出内容保存到指定文件
python实现linux交互
之前一直不知道怎么在linux下和elf进行交互,通过这道题了解到了一些
第一句话
from pwn import* #使用from来导入pwntools模块设置基本信息
在打靶机前需要按照靶机的类型设置好基本信息,因为
pwntools中很多工具需要依靠contest来自动选择类型,比如shellcraft(用于生成shellcode代码的工具)等
os是靶机的系统类型一般就是linux系统
arch是指题目的架构,我们可以使用checksec工具来查看具体的架构,一般是AMD64或i386
log_level是指日志输出等级,可以设置为debug或者直接不设置删掉也行,设置为debug在脚本运行的时候会输出我们具体发送了什么信息,靶机反馈了什么信息。context(os='linux', arch='AMD64', log_level='debug') #或者 context.arch = 'amd64'#i386(视具体情况而定) context.os = 'linux' context.log_level = 'debug'通信通道 (pwnlib.tubes)
功能:统一接口处理远程连接、本地进程、监听器等。
常用方法:recvline(): #接收一行数据。 recvuntil(delimiter): #接收到指定的分隔符。 clean(): #清理缓冲区。 interactive(): #与应用进行交互。举例:
from pwn import * p = remote('example.com', 1234) p.recvuntil(b': ') p.sendline(b'password') p.interactive()汇编与反汇编(
pwnlib.asm)from pwn import * shellcode = asm(shellcraft.sh()) print(hexdump(shellcode))数据打包与解包 (
pwnlib.util.packing)
功能:提供
p32,u32,p64,u64等函数,简化字节序转换。from pwn import * addr = p32(0xdeadbeef) print(addr) # 输出: b'\xef\xbe\xad\xde'仅列举一些常见的,具体需要还是查文档PWN从入门到放弃(2)——Pwntools使用入门-腾讯云开发者社区-腾讯云
plt
got与plt表
- got(全局偏移表)
got表是Linux平台用来解决对全局数据,外部函数引用的表,当在程序中引用外部的数据,函数时,通过got表来实现对相关数据符号的解析。 - plt(过程链接表)
在动态链接过程中, 函数在加载共享库之后,会对got节中的函数地址进行填充,所以,调用的时候利用plt跳转到got表中项指定的地址即可。
动态链接器默认采用延迟链接方式时,动态链接器不会在程序加载时解析每一个函数,而是在调用时通过plt和got来对函数进行解析,然后会将解析获得函数地址存放在got中,下一次调用时会直接使用got中的函数地址对函数进行调用。在ELF将GOT拆分成两个表“.got”和".got.plt",前者用来保存全局变量引用的地址,后者用来保存函数引用的地址。也就是说,所有对于外部函数的引用被分离出来放到了“.got.plt”中
延迟重定位------GOT表和PLT表 - 简书
只有动态库函数在被调用时,才会进行地址解析和重定位工作,这时候动态库函数的地址才会被写入到GOT表项中
函数第一次被调用过程

第一步由函数调用跳入到PLT表中,然后第二步PLT表跳到GOT表中,可以看到第三步由GOT表回跳到PLT表中,这时候进行压栈,把代表函数的ID压栈,接着第四步跳转到公共的PLT表项中,第5步进入到GOT表中,然后_dl_runtime_resolve对动态函数进行地址解析和重定位,第七步把动态函数真实的地址写入到GOT表项中,然后执行函数并返回。
dynamic段:提供动态链接的信息,例如动态链接中各个表的位置
link_map:已加载库的链表,由动态库函数的地址构成的链表
_dl_runtime_resolve:在第一次运行时进行地址解析和重定位工作

可以看到,第一步还是由函数调用跳入到PLT表,但是第二步跳入到GOT表中时,由于这个时候该表项已经是动态函数的真实地址了,所以可以直接执行然后返回。
对于动态函数的调用,第一次要经过地址解析和回写到GOT表项中,第二次直接调用即可
mov混淆
参考资料:
PWN从入门到放弃(2)——Pwntools使用入门-腾讯云开发者社区-腾讯云
[pwntools 及其他pwn工具使用使用教程(1)]-CSDN博客
CTF常用python库PwnTools的使用学习 - Ox9A82 - 博客园
菜鸟笔记之pwn工具篇--pwntools库的基本使用 - XiDP - 博客园
理解elf文件的got和plt-软件逆向-看雪-安全社区|安全招聘|kanxue.com


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端