数据结构学习笔记(C)--半期复习
第一章---第四章(哈夫曼树)之前
1.0绪论

1.1 数据结构三要素:
-
逻辑结构
a.线性
线性结构--一对一
b.非线性
集合结构--属于同一集合”
树结构--一对多
图结构或网状结构--多对多
-
存储结构
顺序
链式
-
数据的运算
1.2 数据类型和抽象数据类型
抽象数据类型
ADT 抽象数据类型名
{
数据对象:<定义>
数据关系:<定义>//采用数学符号和自然语言描述
基本操作:<定义>
}ADT 抽象数据类型名
基本操作名(参数表)
//赋值参数只为操作提供输入值,以“&”开头,除此之外还将返回操作结果
初始条件:<描述>//操作执行之前数据结构和参数应满足的条件,为空则省略
操作结果:<描述>//操作完成后,数据结构的变化状况和应返回的结果
1.3 算法和算法分析
a.时间复杂度
描述的是算法执行时间开销和问题规模n之间的关系。包含最好、平均和最坏时间复杂度。时间复杂度通常包括:常量阶、线性阶、平方阶、对数阶等。
b.空间复杂度
程序执行时,除了需要寄存本身所有指令、常数、变量和输入的数据外(取决于问题本身),还需要一些对数据进行操作的辅助存储空间。空间复杂度考虑的就是在算法实现中考虑的辅助空间大小。
1.4 小结
1.算法有五个特性:有穷性、确定性、可行性、输入和输出。一个算法的优劣应从正确性、可读性、健壮性和高效性四个方面来评价。
2.数据的逻辑结构和存储结构是密不可分的,算法的设计取决于所选定的逻辑结构,而算法的实现依赖于采用的存储结构
3.链式存储设计时,各个不同结点的存储空间可以不连续,但结点内的存储单元地址必须连续
2.0 线性表
知识框架

2.1 线性表的定义
零个或多个数据元素的有限序列。
2.2 线性标的顺序存储结构---顺序表
概念:用一组地址连续的存储单元依次存储线性表的数据元素,这种存储结构的线性表称为顺序表。----数组
特点:逻辑上相邻的数据元素,物理次序也是相邻的。
存储结构:
typedef int ElemType; //ElemType的类型根据实际情况而定,这里假定为int
//顺序表数据结构
typedef struct
{
ElemType *elem;
int length;
}SqList;
对顺序表的操作:
初始化、插入、删除,查值,读取顺序表所有元素
初始化:
Status InitList(SqList* L){
//构造一个空的线性表L
L -> elem = (ElemType *)malloc(MAXSIZE*sizeof(ElemType));
if(!L -> elem){
return ERROR;
}
L -> length = 0;
return OK;
}
2.3 线性表的链式存储结构--单链表、静态链表
一、单链表
概念:在链式结构中,除了要存储数据元素的信息外,还要存储它的后继元素的存储地址。因此,为了表示每个数据元素ai与其直接后继元素ai+1之间的逻辑关系,对数据ai来说,除了存储其本身的信息之外,还需要存储一个指示其直接后继的信息(即直接后继的存储位置)。我们把存储数据元素信息的域称为数据域,把存储直接后继位置的域称为指针域。指针域中存储的信息称做指针或链。这两部分信息组成数据元素ai的存储映像,称为结点(Node)。n个结点(ai的存储映像)链结成一个链表,即为线性表(a1, a2, …, an)的链式存储结构,因为此链表的每个结点中只包含一个指针域,所以叫做单链表。

链表中第一个结点的存储位置叫头指针

有时为了方便对链表进行操作,会在单链表的第一个结点前附设一个节点,称为头结点,此时头指针指向的结点就是头结点。

空链表,头结点的直接后继为空。


存储结构
typedef struct Node
{
ElemType data;
struct Node *next;
} Node;
//构造LinkList
typedef struct {
int lenght;
Node *next;
}*LinkList;
操作:
初始化
/*构造一个带头结点的单链表*/
Status InitList(LinkList *L){
//生成一个空的LinkList和一个新结点
LinkList p = (LinkList)malloc(sizeof(LinkList));
Node *q = (Node *)malloc(sizeof(Node)); //头结点
q->next = NULL; //头结点的后继指向null
p->next = q; //头指针指向头结点
p->lenght = 0; //初始长度为0
(*L) = p;
return OK;
}
插入:
s->next=p->next;
p->next=s;
删除

清空、销毁
//核心
Node *p = (*L)->next->next, *q;
while(p != NULL){
q = p;
p = p->next;
free(q);
}
头插法
只需要将新的节点插在头结点和首元结点之间。(带头结点)

核心代码:
s->next=L->next; ①
L->next=s; ②
尾插法

核心代码:
r->next=s; //①r的指针域指向S(让新结点插入到链表)
r=s; //②r指针指向s(保持r指针一直在链表尾端,方便插入新的结点)
二、静态链表
略
三、循环链表
概念:将单链表中终端节点的指针端由空指针改为指向头结点,就使整个单链表形成一个环,这种头尾相接的单链表称为单循环链表,简称循环链表。


上述仅设头指针的循环链表有一个弊端,我们可以用O(1)的时间访问第一个节点,但对于最后一个节点,却需要O(n)的时间,于是就有了仅设尾指针的循环链表。

操作:
四、双向链表
概念:双向链表(double linked list)是在单链表的每个结点中,再设置一个指向其前驱结点的指针域。所以在双向链表中的结点都有两个指针域,一个指向直接后继,另一个指向直接前驱。
存储结构:
/*双向链表存储结构*/
typedef struct DulNodse{
ElemType data;
struct DulNode *prior; //直接前驱指针
struct DulNode *next; //直接后继指针
} DulNode, *DuLinkList;
操作:
插入

//第一步:把p赋值给s的前驱
s->prior = p;
//第二步:把p->next赋值给s的后继
p->next = p->next
//第三步:把s赋值给p->next的前驱
p->next->prior = s;
//第四步:把s赋值给p的后继
p->next = s;
删除

//第一步
p->next = q->next;
//第二步
q->next->prior = p;
free(q);
2.4 小结
1.线性表:除第一个元素a1外,每一个元素有且只有一个直接前驱元素,除了最后一个元素an外,每一个元素有且只有一个直接后继元素。数据元素之间的关系是一对一的关系
2.在较复杂的线性表中,一个数据元素可以由若干个数据项组成。在这种情况下,常把数据元素称为记录,含有大量记录的线性表又称为文件
3.通常较稳定的线性表选择顺序存储,而频繁进行插入、删除操作的线性表(即动态性较强)宜选择链式存储。
4.对于按值查找,顺序表无序时,两者的时间复杂度均为O(n);
5.采用头插法建立单链表时,读入数据的顺序与生成的链表中的元素的顺序是相反的,每个结点插入时间为O(1)一共为O(n)
6.循环单链表中没有指针域为NULL的结点,故循环单链表的判空条件为它是否等于头指针
7.与单链表相比,双链表的优点之一是访问前后相邻结点更灵活
8.某线性表用带头结点的循环单链表存储,头指针为head,当head->next->next=head时,线性表长度可能是0或1
3.0 栈和队列

3.1栈
1.概念
栈(Stack):是只允许在一端进行插入或删除的线性表。首先栈是一种线性表,但限定这种线性表只能在某一端进行插入和删除操作。
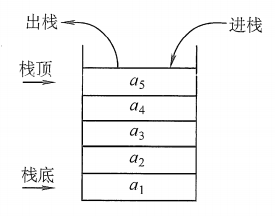
栈顶(Top):线性表允许进行插入删除的那一端。
栈底(Bottom):固定的,不允许进行插入和删除的另一端。
空栈:不含任何元素的空表。
栈又称为后进先出(Last In First Out)的线性表,简称LIFO结构
2. 顺序存储结构
常见操作
-
初始化
void InitStack(SqStack *S){ S->top = -1; //初始化栈顶指针 } -
判空
if(S.top == -1) -
入栈
S->top++; //栈顶指针增加一 S->data[S->top] = e; //将新插入元素赋值给栈顶空间 -
出栈
*e = S->data[S->top]; //将要删除的栈顶元素赋值给e S->top--; -
获取栈顶元素
*e = S->data[S->top];//记录栈顶元素
存储结构
#define MAXSIZE 50 //定义栈中元素的最大个数
typedef int ElemType; //ElemType的类型根据实际情况而定,这里假定为int
typedef struct{
ElemType data[MAXSIZE];
int top; //用于栈顶指针
}SqStack;
3. 链式存储结构
采用链式存储的栈称为链栈,链栈的优点是便于多个栈共享存储空间和提高其效率,且不存在栈满上溢的情况。通常采用单链表实现,并规定所有操作都是在单链表的表头进行的。这里规定链栈没有头节点,Lhead指向栈顶元素,

链栈的空其实就是top=NULL的时候
存储结构
/*栈的链式存储结构*/
/*构造节点*/
typedef struct StackNode{
ElemType data;
struct StackNode *next;
}StackNode, *LinkStackPrt;
/*构造链栈*/
typedef struct LinkStack{
LinkStackPrt top;
int count;
}LinkStack;
基本操作
Push
/*插入元素e为新的栈顶元素*/
Status Push(LinkStack *S, ElemType e){
LinkStackPrt p = (LinkStackPrt)malloc(sizeof(StackNode));
p->data = e;
p->next = S->top; //把当前的栈顶元素赋值给新节点的直接后继
S->top = p; //将新的结点S赋值给栈顶指针
S->count++;
return OK;
}
Pop(核心)
*e = S->top->data;
p = S->top; //将栈顶结点赋值给p
S->top = S->top->next; //使得栈顶指针下移一位,指向后一结点
free(p); //释放结点p
S->count--;
4. 应用
1.逆波兰表达式
2.括号配对
3.2 队列
概念:队列(queue)是只允许在一端进行插入操作,而在另一端进行删除操作的线性表。
队列是一种先进先出(First In First Out)的线性表,简称FIFO。允许插入的一端称为队尾(rear),允许删除的一端称为队头(front)。
1.顺序存储结构
#define MAXSIZE 50 //定义队列中元素的最大个数
typedef struct{
ElemType data[MAXSIZE]; //存放队列元素
int front,rear;
}SqQueue;
1.顺序队列
操作:
判空
Q->front == Q->rear == 0
入队
队不满时,先送值到队尾元素,再将队尾指针加1。

如图d,队列出现“上溢出”,然而却又不是真正的溢出,所以是一种“假溢出”。
出队
队不空时,先取队头元素值,再将队头指针加1。
2.循环存储结构--解决假溢出
typedef int ElemType; //ElemType的类型根据实际情况而定,这里假定为int
#define MAXSIZE 50 //定义元素的最大个数
/*循环队列的顺序存储结构*/
typedef struct{
ElemType data[MAXSIZE];
int front; //头指针
int rear; //尾指针,若队列不空,指向队列尾元素的下一个位置
}SqQueue;
队首指针Q->front = MAXSIZE-1后,再前进一个位置就自动到0
初始时:Q->front = Q->rear=0。
队首指针进1:Q->front = (Q->front + 1) % MAXSIZE。
队尾指针进1:Q->rear = (Q->rear + 1) % MAXSIZE。
队列长度:(Q->rear - Q->front + MAXSIZE) % MAXSIZE。
牺牲一个单元来区分队空和队满,入队时少用一个队列单元,这是种较为普遍的做法,约定以“队头指针在队尾指针的下一位置作为队满的标志”,
操作:
判空
Q->front == Q->rear
判满
(Q->rear + 1)%Maxsize == Q->front
元素个数
(Q->rear - Q ->front + Maxsize)% Maxsize
初始化
/*初始化一个空队列Q*/
Status InitQueue(SqQueue *Q){
Q->front = 0;
Q->rear = 0;
return OK;
}
入队
出队
3 链式存储结构
队列的链式存储结构表示为链队列,它实际上是一个同时带有队头指针和队尾指针的单链表,只不过它只能尾进头出而已。

空队列时,front和real都指向头结点。
存储结构:
/*链式队列结点*/
typedef struct {
ElemType data;
struct LinkNode *next;
}LinkNode;
/*链式队列*/
typedef struct{
LinkNode *front, *rear; //队列的队头和队尾指针
}LinkQueue;
当Q->front == NULL 并且 Q->rear == NULL 时,链队列为空。
4.双端队列
概念:双端队列是指允许两端都可以进行入队和出队操作的队列,如下图所示。其元素的逻辑结构仍是线性结构。将队列的两端分别称为前端和后端,两端都可以入队和出队。
3.3 小结
1.栈:后进先出
2. n个不同元素进栈,出栈元素不同排列的个数为
即卡特兰数
3.采用顺序存储的栈称为顺序栈;栈空:S.top = -1;栈满:S.top = MaxSize-1;栈长:S.top+1
4.循环队列队空:Q.front==Q.rear ; 队满(Q.rear+1)%MaxSize == Q.front;
4.0 串、数组、广义表
4.1 串
概念:串( string)是由零个或多个字符组成的有限序列,又名叫字符串。
知识框架

基础概念:
a. 空串:n = 0时的串称为空串。
b. 空格串:是只包含空格的串。注意它与空串的区别,空格串是有内容有长度的,而且可以不止一个空格。
c. 子串与主串:串中任意个数的连续字符组成的子序列称为该串的子串,相应地,包含子串的串称为主串。
d.子串在主串中的位置就是子串的第一个字符在主串中的序号。
4.1.1 存储结构
1.顺序存储表示
#define MAXLEN 255 //预定义最大串长为255
typedef struct{
char ch[MAXLEN]; //每个分量存储一个字符
int length; //串的实际长度
}SString;
2.堆分配存储表示
堆分配存储表示仍然以一组地址连续的存储单元存放串值的字符序列,但它们的存储空间是在程序执行过程中动态分配得到的。
typedef struct{
char *ch; //按串长分配存储区,ch指向串的基地址
int length; //串的长度
}HString;
4.1.2 KMP算法
如果已匹配相等的前缀序列中有某个后缀正好是模式的前缀,那么就可以将模式向后滑动到与这些相等字符对齐的位置,主串i指针无须回溯,并继续从该位置开始进行比较。而模式向后滑动位数的计算仅与模式本身的结构有关,与主串无关。
基本概念:
前缀是指以串第一个字符开头且不包含最后一个元素的连续的子串
后缀是指以串最后一个字符结尾且不包含第一个元素的连续的子串(可以为串自身)。
一个串的公共前后缀:如果前缀集合与后缀集合中存在一个相同的元素,即存在一个子串,它既可以是前缀也可以是后缀,则称这个子串为该串的公共前后缀。
最大公共前后缀长度:公共前后缀不一定只有一个,因此,需要我们寻找最长的公共前后缀,并得到它的长度,称为最大公共前后缀长度。
next[j]=最大公共前后缀长度+1
void get_next(String T, int *next){
int i = 1, j = 0;
next[1] = 0;
while (i < T.length){
if(j==0 || T.ch[i]==T.ch[j]){ //ch[i]表示后缀的单个字符,ch[j]表示前缀的单个字符
++i; ++j;
next[i] = j; //若pi = pj, 则next[j+1] = next[j] + 1
}else{
j = next[j]; //否则令j = next[j],j值回溯,循环继续
}
}
}
int Index_KMP(String S, String T){
int i=1, j=1;
int next[255]; //定义next数组
get_next(T, next); //得到next数组
while(i<=S.length && j<=T.length){
if(j==0 || S.ch[i] == T.ch[j]){ //字符相等则继续
++i; ++j;
}else{
j = next[j]; //模式串向右移动,i不变
}
}
if(j>T.length){
return i-T.length; //匹配成功
}else{
return 0;
}
}
4.2 数组
数组的顺序存储:行优先顺序;列优先顺序。数组中的任一元素可以在相同的时间内存取,即顺序存储的数组是一个随机存取结构。
关联数组(Associative Array),又称映射(Map)、字典( Dictionary)是一个抽象的数据结构,它包含着类似于(键,值)的有序对。 不是线性表。
矩阵的压缩:
对称矩阵、三角矩阵:直接存储矩阵的上三角或者下三角元素。注意区分i>=j和i
4.3 广义表
广义表(Lists,又称列表)是线性表的推广。广义表是n(n≥0)个元素a1,a2,a3,…,an的有限序列,其中ai或者是原子项,或者是一个广义表。若广义表LS(n>=1)非空,则a1是LS的表头,其余元素组成的表(a2,…an)称为LS的表尾。
#A=()——A是一个空表,其长度为零。
#B=(e)——表B只有一个原子e,B的长度为1。
#C=(a,(b,c,d))——表C的长度为2,两个元素分别为原子a和子表(b,c,d)。
#D=(A,B,C)——表D的长度为3,三个元素都是广义 表。显然,将子表的值代入后,则有D=(( ),(e),(a,(b,c,d)))。
#E=(a,E)——这是一个递归的表,它的长度为2,E相当于一个无限的广义表E=(a,(a,(a,(a,…)))).
1.广义表的元素可以是子表,而子表的元素还可以是子表。由此,广义表是一个多层次的结构,可以用图形象地表示
2.广义表可为其它表所共享。
3.广义表的递归性
4.4 小结
1.串的逻辑结构和线性表极为相似,区别仅在于串的数据对象限定为字符集。
2.在基本操作上,串和线性表有很大差别。线性表的基本操作主要以单个元素作为操作对象,如查找、插入或删除某个元素等;而串的基本操作通常以子串作为操作对象,如查找、插入或删除一个子串等。
3.子串的定位操作通常称为串的模式匹配,它求的是子串在主串中的位置。
4.广义表的元素也可以为空。表尾是指除去表头后剩下的元素组成的表,表头可以为表或单元素值。所以表尾不可以是单个元素值,一定是一个广义表。
5.在(非空)广义表中:(1)表头head可以是原子或者一个表. (2)表尾tail一定是一个表 (3)广义表难以用顺序存储结构.(4)广义表可以是一个多层次的结构
6.广义表()和(())不同,前者为空表,长度n=0。后者长度n=1,可分解得到表头、表尾且均为空表。
5.0 树与二叉树
略


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端