
Django ORM 基本操作
本次sql大部分习题出自知乎以为网友,对原sql感兴趣的各位朋友,可以去参考知乎上的这位朋友:
https://www.zhihu.com/tardis/bd/art/38354000?source_id=1001
我们在他的基础上,进行sql改造,成为我们Django ORM机制下的ORM语法。本次教程的面向人群:我们默认你会使用Django,至少能够自己启动一个项目。
相关的Django基础,将不再赘述,如果你对Django本身的基础并不好,那么希望你可以先去学习Django基础,然后再来此处查看Django的ORM基本操作。
具体的表结构,我们参考知乎上面的,你们也可以自己看一下。
class Student(models.Model): class SexEnum: M = 1 F = 0 ChoicesSex = ( ("男性", 1), ("女性", 0), ) xuehao = models.IntegerField("学号", primary_key=True, default=1) name = models.CharField("姓名", max_length=255, default="0") brith = models.DateField("生日", default=datetime.now) gender = models.BooleanField("性别", choices=ChoicesSex, default=SexEnum.M) class Meta: db_table = "student"
class Teacher(models.Model): teacherid = models.IntegerField("教师号", primary_key=True, default=1) teachername = models.CharField("老师名字", max_length=255, null=True) class Meta: db_table = "teacher"
class Course(models.Model): kechengid = models.IntegerField("课程ID", primary_key=True, default=1) kechengname = models.CharField("课程名称", max_length=255) jiaoshiid = models.ForeignKey(Teacher, on_delete=models.CASCADE) class Meta: db_table = "course"
class Score(models.Model): xuehao = models.ForeignKey(Student, on_delete=models.CASCADE) kechengid = models.ForeignKey(Course, on_delete=models.CASCADE) chengji = models.IntegerField("成绩") class Meta: unique_together = (("xuehao", "kechengid"),) db_table = "score"
准备好上面的model后,我们使用makemigrations migrate 将数据迁移至数据库。
数据库迁移结束后,我们创建基本的数据链条。
由于编写时,记录缺失了一部分,大家自己将student、teacher表中的数据补全,我这里提供出course和score的表创建语句。
Course.objects.create(kechengid=1,kechengname="语文",jiaoshiid=Teacher.objects.filter(teacherid=1).first()) Course.objects.create(kechengid=2,kechengname="数学",jiaoshiid=Teacher.objects.filter(teacherid=2).first()) Course.objects.create(kechengid=3,kechengname="英语",jiaoshiid=Teacher.objects.filter(teacherid=3).first()) Course.objects.create(kechengid=2,kechengname="数学",jiaoshiid=1) Course.objects.create(kechengid=3,kechengname="英语",jiaoshiid=3) Score.objects.create(xuehao=Student.objects.filter(xuehao=1).first(),kechengid=Course.objects.filter(kechengid=1).first(), chengji=80) Score.objects.create(xuehao=Student.objects.filter(xuehao=1).first(),kechengid=Course.objects.filter(kechengid=2).first(), chengji=90) Score.objects.create(xuehao=Student.objects.filter(xuehao=1).first(),kechengid=Course.objects.filter(kechengid=3).first(), chengji=99) Score.objects.create(xuehao=Student.objects.filter(xuehao=2).first(),kechengid=Course.objects.filter(kechengid=2).first(), chengji=60) Score.objects.create(xuehao=Student.objects.filter(xuehao=2).first(),kechengid=Course.objects.filter(kechengid=3).first(), chengji=80) Score.objects.create(xuehao=Student.objects.filter(xuehao=3).first(),kechengid=Course.objects.filter(kechengid=1).first(), chengji=80) Score.objects.create(xuehao=Student.objects.filter(xuehao=3).first(),kechengid=Course.objects.filter(kechengid=2).first(), chengji=80) Score.objects.create(xuehao=Student.objects.filter(xuehao=3).first(),kechengid=Course.objects.filter(kechengid=3).first(), chengji=80)
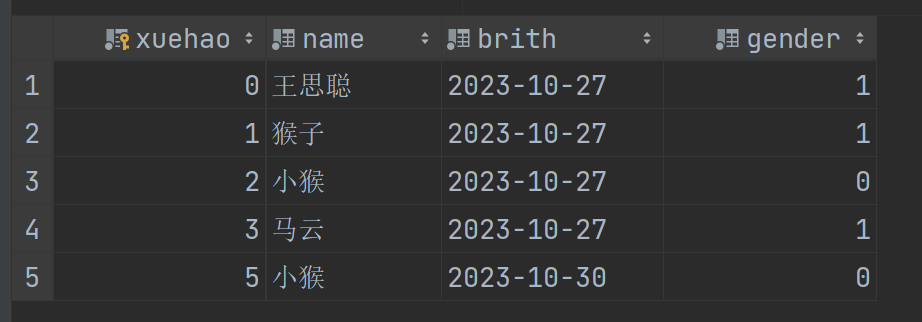
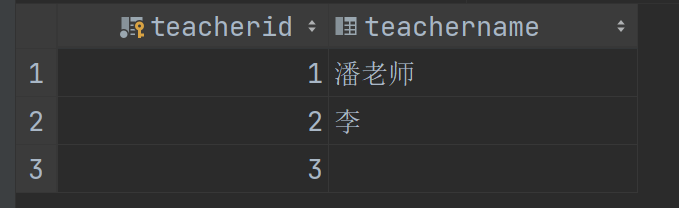
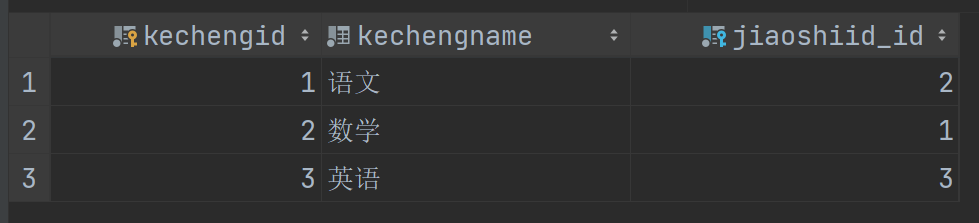
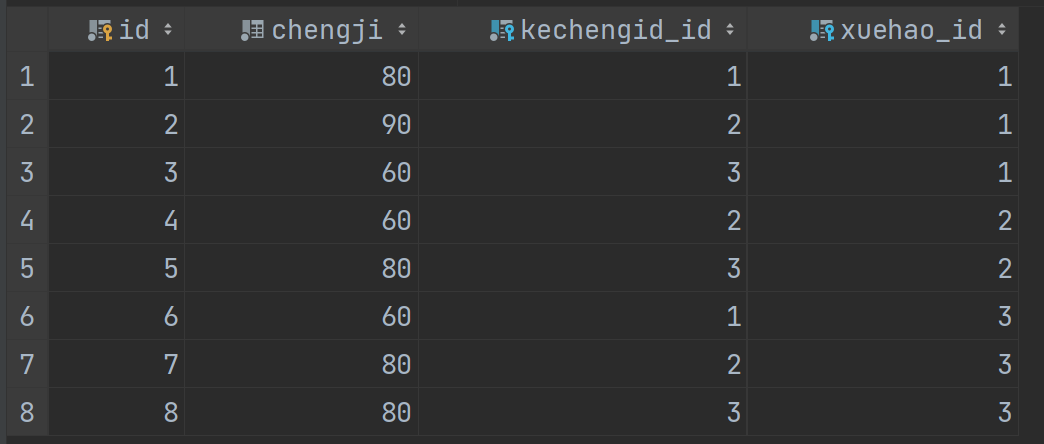
我们将数据库里面的数据贴出来供大家参考。
准备好数据后,我们开始今天的ORM基本操作。
-
查询姓 “猴” 的学生名单
Student.objects.filter(name__startswith="猴")
# <QuerySet [<Student: Student object (1)>]> -
查询姓氏中,最后一个是“猴”的学生的名单
Student.objects.filter(name__endswith="猴") # <QuerySet [<Student: Student object (2)>]>
-
查询名字中 带有 “猴” 的名单
Student.objects.filter(name__contains="猴") # <QuerySet [<Student: Student object (1)>, <Student: Student object (2)>]>
-
查询姓 “孟” 老师的个数
Teacher.objects.filter(teachername__contains="孟").count() # 1
以上是有关模糊查询的相关操作。在orm中,__有很神奇的用法,我们一一进行讲解:
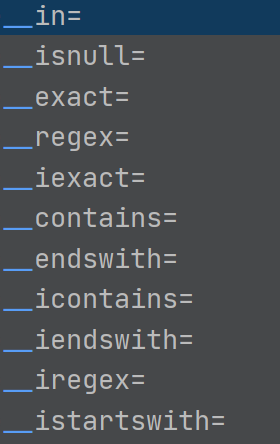
in : 后面接一个范围 --》 我们可以是 id__in = [1,2,3,4], 也可以是后面跟一个queryset对象集。
举例说明:
Score.objects.filter(xuehao_id__in=Student.objects.filter(xuehao__in=[1, 2])).query """ SELECT `score`.`id`, `score`.`xuehao_id`, `score`.`kechengid_id`, `score`.`chengji` FROM `score` WHERE `score`.`xuehao_id` IN (SELECT U0.`xuehao` FROM `student` U0 WHERE U0.`xuehao` IN (1, 2)) """
exact: 精确匹配 --》 你输入的东西,进行精确匹配
iexact: 精确,但不区分大小写, 精确匹配
regex: 正则匹配,调用数据库正则匹配方法,mysql:REGEXP_LIKE
ranger: 在 .... .... 范围内: __ranger = [10, 1000] 范围规定在十到一千之内
contains : 模糊匹配,但不忽略大小写。
endswith: 以 ....... 为结尾的匹配,但不忽略大小写。
startswith: 以 ...... 为开头的匹配,但不忽略大小写。
icontains: 模糊匹配,但是忽略大小写。
iendswith: 以 ....... 为结尾的匹配,但忽略大小写。
istartswith: 以 ...... 为开头的匹配,但忽略大小写。
lt:小于 对应英文:less than
gt:大于 对应英文: geater than
lte:不大于(小于等于) less than or equal
gte:不小于 (大于等于) geater than or equal
ORM的双下滑查询还有很多,感兴趣的可以自己找找看,对日期啊,字符串,数字这类的都不一样,这里仅列出常用的。
5、查询课程编号为 “2” 的总成绩
Score.objects.filter(kechengid__kechengid=2).aggregate(chengji_sum=models.Sum("chengji")) # {'chengji_sum': 230}
思路:我们要查成绩,我们从表结构可知,成绩表与课程表是具有外键关联的,所以我们先把id为2的数据都查出来,以“__外键名”的形式,就可以获取到kechengid是2的全部成绩,然后在使用aggregate函数进行聚合。
aggregate函数基本使用法则:queryset对象支持聚合操作,ORM的聚合操作放在queryset的aggregate方法里面,使用models.xxxx的形式进行聚合。
本题中:我们需要对kechengid取出来之后的数据进行sum求和处理,我们就可以在aggregate函数里面入参是你自己想的名字+modles.Sum('chengji')的
形式进行sum操作。
6、查询选择了课程的学生数
Student.objects.distinct().annotate(scoreid=models.Count("score")).values("xuehao","scoreid").filter(scoreid__gt=0) # <QuerySet [{'xuehao': 1, 'scoreid': 3}, {'xuehao': 2, 'scoreid': 2}, {'xuehao': 3, 'scoreid': 3}]>
思路:查出 student 表中 score 的个数聚合,然后找到学号和刚才查完的数据,把聚合后的个数里面的小于零的过滤掉。
annotate函数基本使用法则:它不像aggregate一样,agg返回返回你需要的字段,ann将你后面生成的字段动态添加到查询集里面去,使得我们可以对其进行其他操作。
7、查询各科成绩的最高值和最低值
qs = Course.objects.annotate(maxs=models.Max("score__chengji"), mins=models.Min("score__chengji")) for i in qs: print(i.kechengname,i.maxs,i.mins)
"""
语文 80 60
数学 90 60
英语 80 60
"""
思路:从课程表里面,查出score表中chengji的外字段的最大值与最小值,然后聚合出来
在有外键的表中,我们可以使用表明小写来查询,这是Django ORM的反、正向查询手段。具体的反、正向查询你可以自行百度,很简单的。
主要你需要知道与记住的是:不论外键在哪张表里面,查什么就用什么,比如你想查询各科成绩,我们的查询主体是各科,也可以是成绩,不同的查询,使用不同的正或反向查询。
8、查询每科课程被选择的学生数
思路:因为课程表与学生表是没有关系的,所以我们使用成绩表进行查,先拿出课程表的课程id号,然后计算学号个数,进行聚合。
Score.objects.values("kechengid").annotate(xuesum=models.Count("xuehao"))
# <QuerySet [{'kechengid': 1, 'xuesum': 2}, {'kechengid': 2, 'xuesum': 3}, {'kechengid': 3, 'xuesum': 3}]>
9、查询男女人数
思路:先把student里面需要的分组字段拿出来,然后再聚合计算
Student.objects.values("gender").annotate(ren=models.Count("gender"))
# <QuerySet [{'gender': True, 'ren': 3}, {'gender': False, 'ren': 2}]>
10、查询平均成绩大于75分的学生的学号和平均成绩
思路:计算每一个学生的平均成绩,然后将大于75分的取出来
b = Score.objects.values("xuehao").annotate(avg=models.Avg("chengji")) b.filter(avg__gt=60) """ <QuerySet [{'xuehao': 1, 'avg': 76.6667}, {'xuehao': 2, 'avg': 70.0}, {'xuehao': 3, 'avg': 73.3333}]> <QuerySet [{'xuehao': 1, 'avg': 76.6667}]> """
11、查询至少选两门课程的学生的学号
思路:查出学号,然后根据课程id计数分类,最后将大于等于二的全部拿出来
Score.objects.values("xuehao__xuehao").annotate(count=models.Count("kechengid")).filter(count__gte=2)
# <QuerySet [{'xuehao__xuehao': 1, 'count': 3}, {'xuehao__xuehao': 2, 'count': 2}, {'xuehao__xuehao': 3, 'count': 3}]>
12、查询同名同性的学生名单并统计同名人数
思路:首先是同名\同性的取出来,然后根据姓名统计人数,最后将统计聚合之后的结果,大于1的取出来。
Student.objects.values("name", "gender").annotate(name_count=models.Count("name")).filter(name_count__gt=1) # <QuerySet [{'name': '小猴', 'gender': False, 'name_count': 2}]>
13、查询不及格的课程并按课程号从大到小排列
思路:将成绩小于八十的都查出来,然后按照课程id进行倒叙。
Score.objects.filter(chengji__lt=80).order_by("-kechengid__kechengid")
倒叙排序:在order_by里面的字段加上 - 号即可。
14、查询每门课程的平均成绩,结果按平均成绩升序排序,平均成绩相同时,按课程号降序排列
思路:查出课程ID,然后给成绩取平均值,然后按照平均成绩升序,课程号降序的形式排序
Score.objects.values("kechengid").annotate(avg=models.Avg("chengji")).order_by("-avg", "kechengid") # <QuerySet [{'kechengid': 2, 'avg': 76.6667}, {'kechengid': 3, 'avg': 73.3333}, {'kechengid': 1, 'avg': 70.0}]>
15、检索课程编号为“2”且分数小于81的学生学号,结果按分数降序排列
思路:首先,主语是查询学号,条件是课程编号为2并且分数小于81的学生号。正向查询成绩、和成绩号
Student.objects.filter(score__chengji__lt=81, score__kechengid=2).order_by("-score__chengji")
16、统计每门课程的学生选修人数(超过2人的课程才统计)、要求输出课程号和选修人数,查询结果按人数降序排序,若人数相同,按课程号升序排序
思路:首先是你需要谁,就查出来谁,你需要课程号,和选修人数,查出课程号,我们方便查看,顺便查出对应的课程名,然后按照课程ID计数,然后将大于2的全部都拿出来
Score.objects.values("kechengid","kechengid__kechengname").annotate(renshu=models.Count("kechengid")).filter(renshu__gt=2).order_by("-kechengid","renshu")
17、查询两门以上不及格课程的同学的学号及其平均成绩
思路:目的:同学的学号 and 平均成绩 无论是成绩表还是学生表,两个表之间存在内外键,所以用两个表哪个表查都可以。无非就是正反向查询问题。
Student.objects.filter(score__chengji__lt=81).annotate(ave=models.Avg("score__chengji"))
18、查询学生的总成绩并将其排名
Student.objects.values("name").annotate(sum=models.Sum("score__chengji")).filter(sum__isnull=False).order_by("-sum")
19、查询平均成绩大于73分的学生的学号和平均成绩
s = Student.objects.annotate(avg=models.Avg("score__chengji")).filter(avg__isnull=False) sf = s.filter(avg__gte=73)
本次就像分享这么多吧,看完这些,我相信你对Django ORM的基本操作已经有了一些理解,使用在实战上是没问题的了,好好学习,天天向上!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号