大数据
#大数据关键技术
hdfs MapReduce spark hbase flink
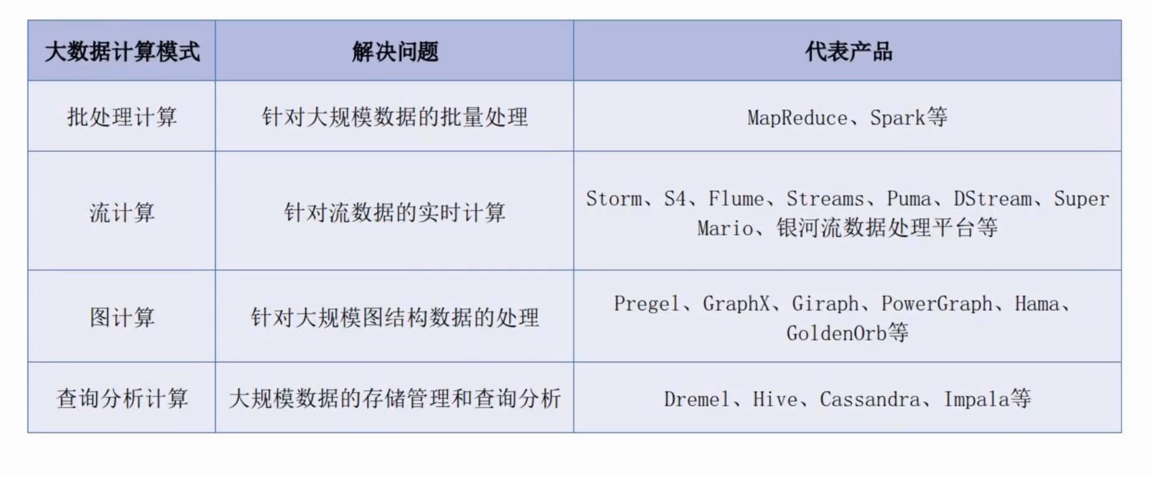
#大数据计算模式
批处理 : 针对大规模数据的批量处理 (MapReduce、spark)
流计算 : 针对流数据的实时计算 (flume、storm、s4、streams、puma、pstream、super mario、银河流数据处理平台等)
图计算 : 针对大规模图结构数据的处理 (pregel、graphx,giraph等)
查询分析计算 : 大规模数据的存储管理和查询分析 (Hive、dremel、Cassandra、Impala等)
spark sql
Map
Reduce
groupby
join
filter
spark和hadoop的区别
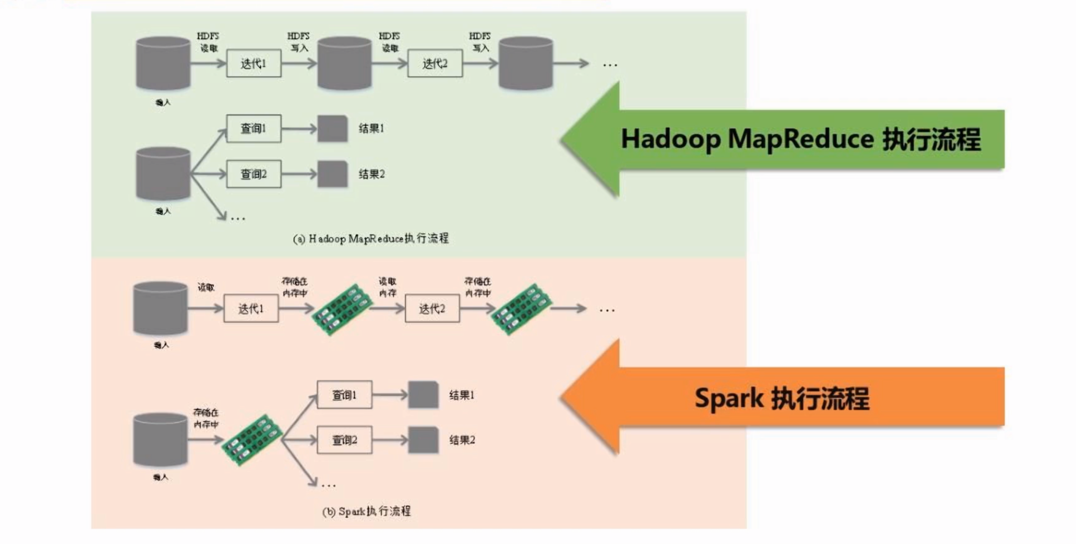
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)
差别MapReduce:
hadoop: 读取-》写入-》读取-》写入
spark: 读取-》储存在内存中-》读取-》储存在内存中
内存中查询比磁盘中查询速度快
spark 可以替代hadoop中的MapReduce
hadoop 中的HDFS,HBase 还是无法替代
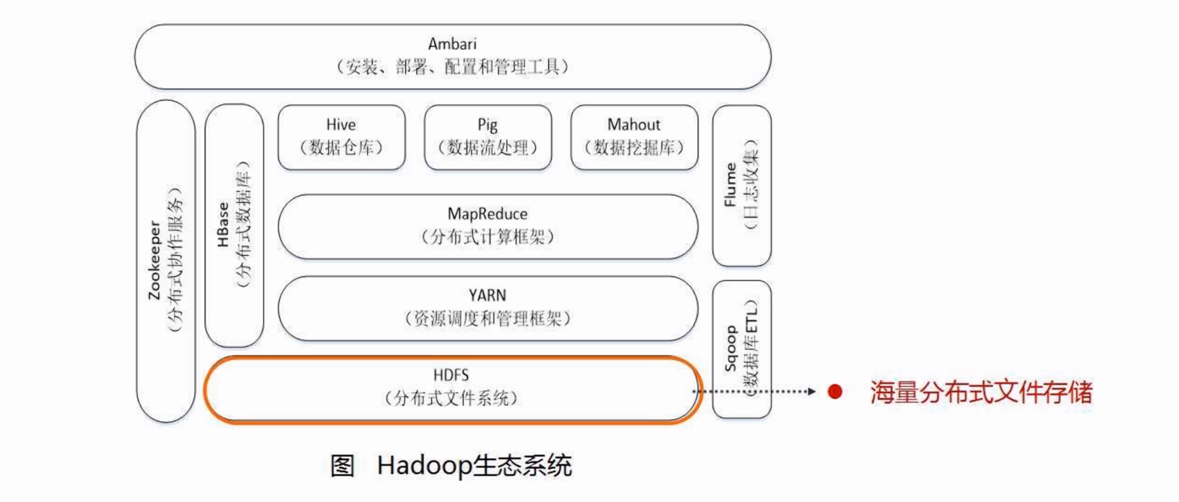
spark概括
运行模式多样化 可访问:
HDFS :分布式文件系统
Cassandra :NoSQL数据库系统
HBase :分布式的、面向列的开源数据库 分布式存储系统 (Hadoop Database)
HBase系统上运行批处理运算,最方便和实用的模型依然是MapReduce
使用Pig Latin流式编程语言来操作HBase中的数据
Hive :Hadoop的一个数据仓库工具
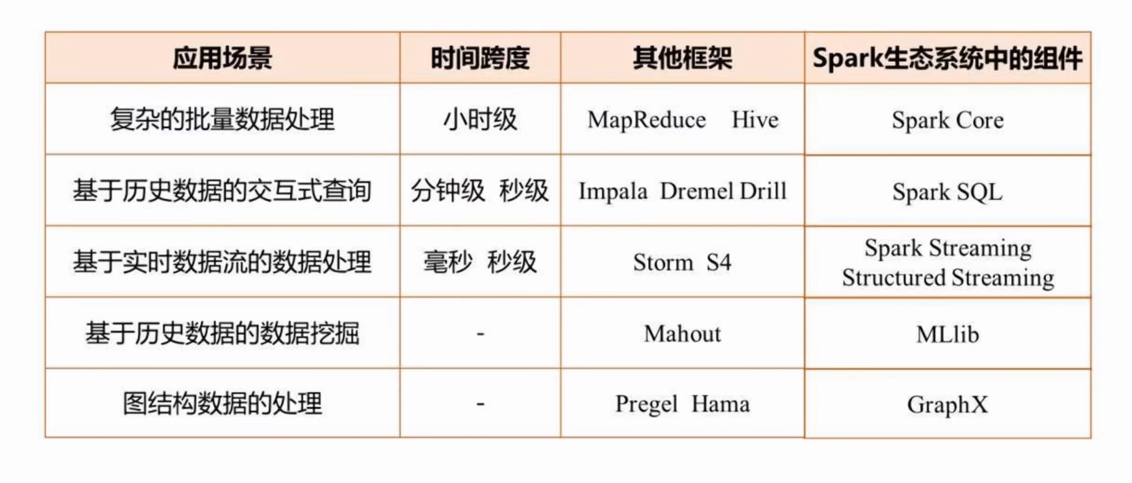
spark生态系统
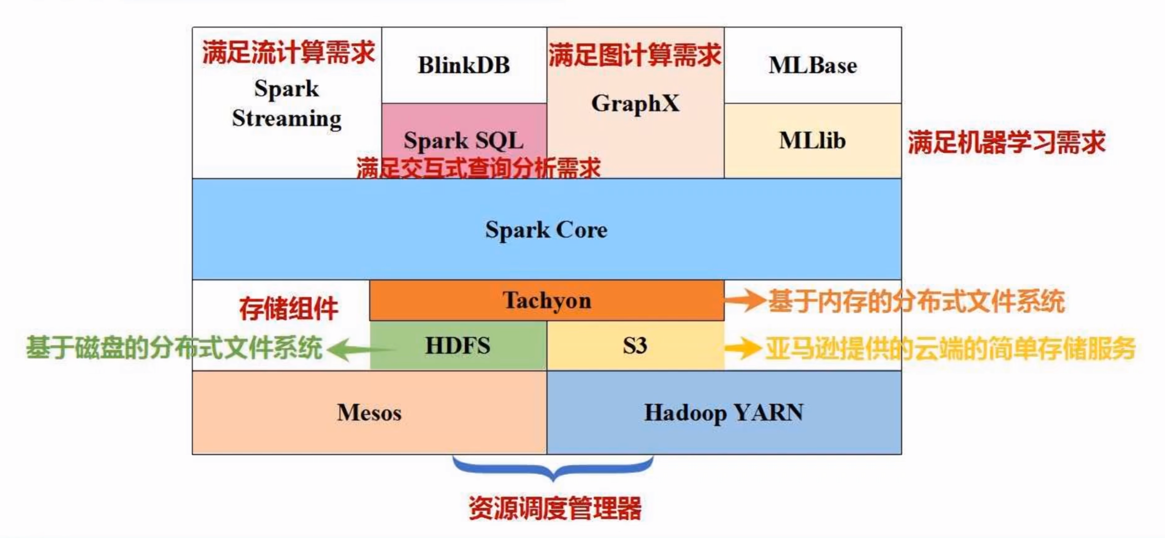
spark 基本概念和架构设计
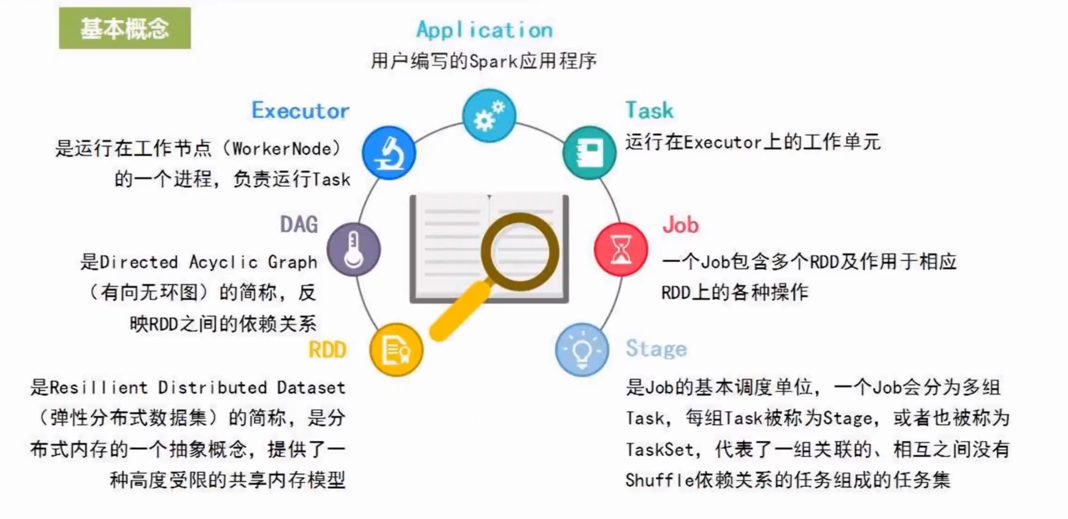
RDD运行原理及概念
惰性机制:只记录轨迹,需要“动作触发计算”
避免不必要的序列换和反序列化
窄依赖 :父对子 一对一 可流水线工作优化(map,filter,union)
宽依赖(Shuffle操作,写入磁盘):父对子 一对多 不可流水线优化(groupByKey)
1.RDD读取外部数据源进行创建
2.RDD讲过一系列转换(Transformation)操作,每一次都会产生不同的RDD供给下一次转换操作使用
3.最后一个RDD经过“动作”操作进行转换并输出到外部数据源
RDD运行原理
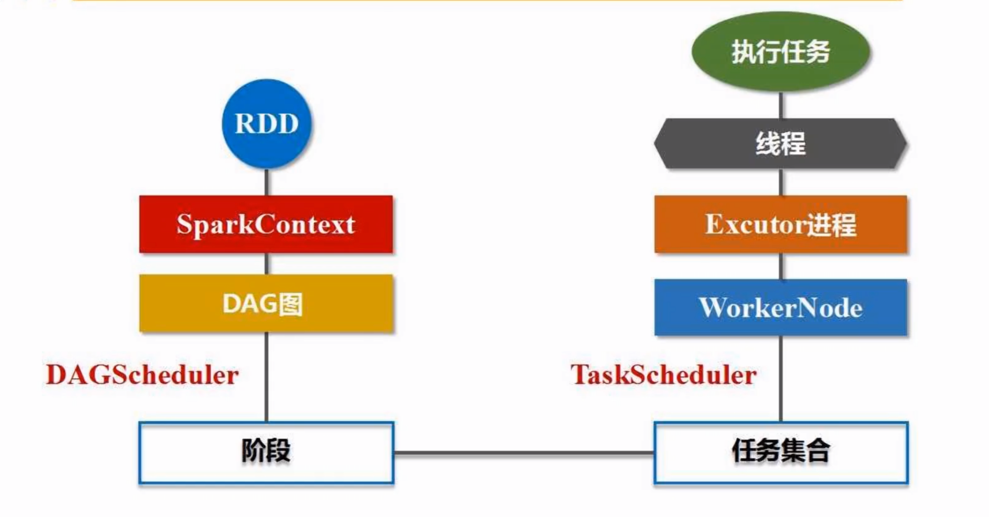
saprk 运行流程
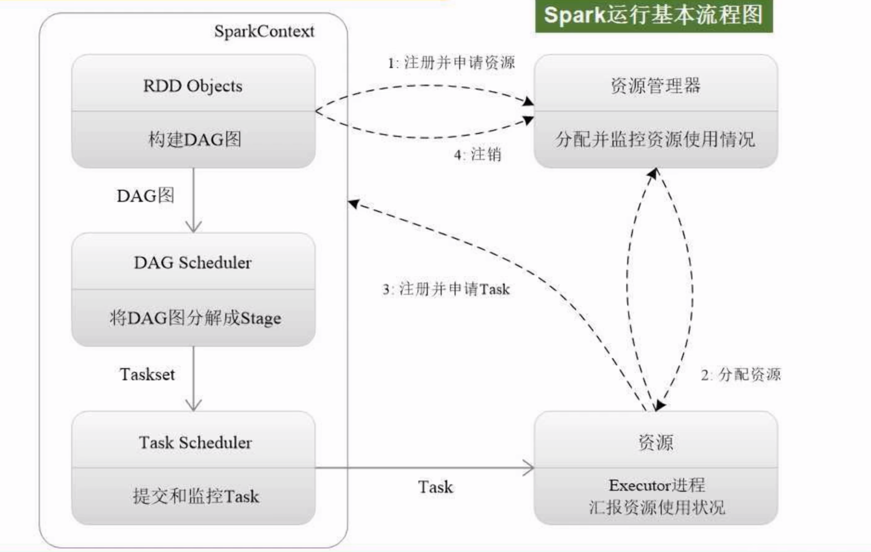
spark模式

Local
集群三种模式
Standalone : 使用Spark自带的集群资源管理器,效率较低
YARN:
Driver程序运行的节点不同
yarn-client模式:Driver运行在客户端上,此模式适用于调试,并且可以直接查看结果
yarn-cluster模式:Driver运行在NodeManager的ApplicationMaster上,此模式适用于生产环境
Mesos :集群资源管理器



 浙公网安备 33010602011771号
浙公网安备 33010602011771号