

正则表达式
简介
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个 “规则字符串”,这个 “规则字符串” 用来表达对字符串的一种过滤逻辑。
正则表达式是用来匹配字符串非常强大的工具,在其他编程语言中同样有正则表达式的概念,Python 同样不例外,利用了正则表达式,我们想要从返回的页面内容提取出我们想要的内容就易如反掌了。
正则表达式的大致匹配过程是:
1. 依次拿出表达式和文本中的字符比较,
2. 如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。
3. 如果表达式中有量词或边界,这个过程会稍微有一些不同。
正则表达式语法规则
python中正则表达式的匹配规则
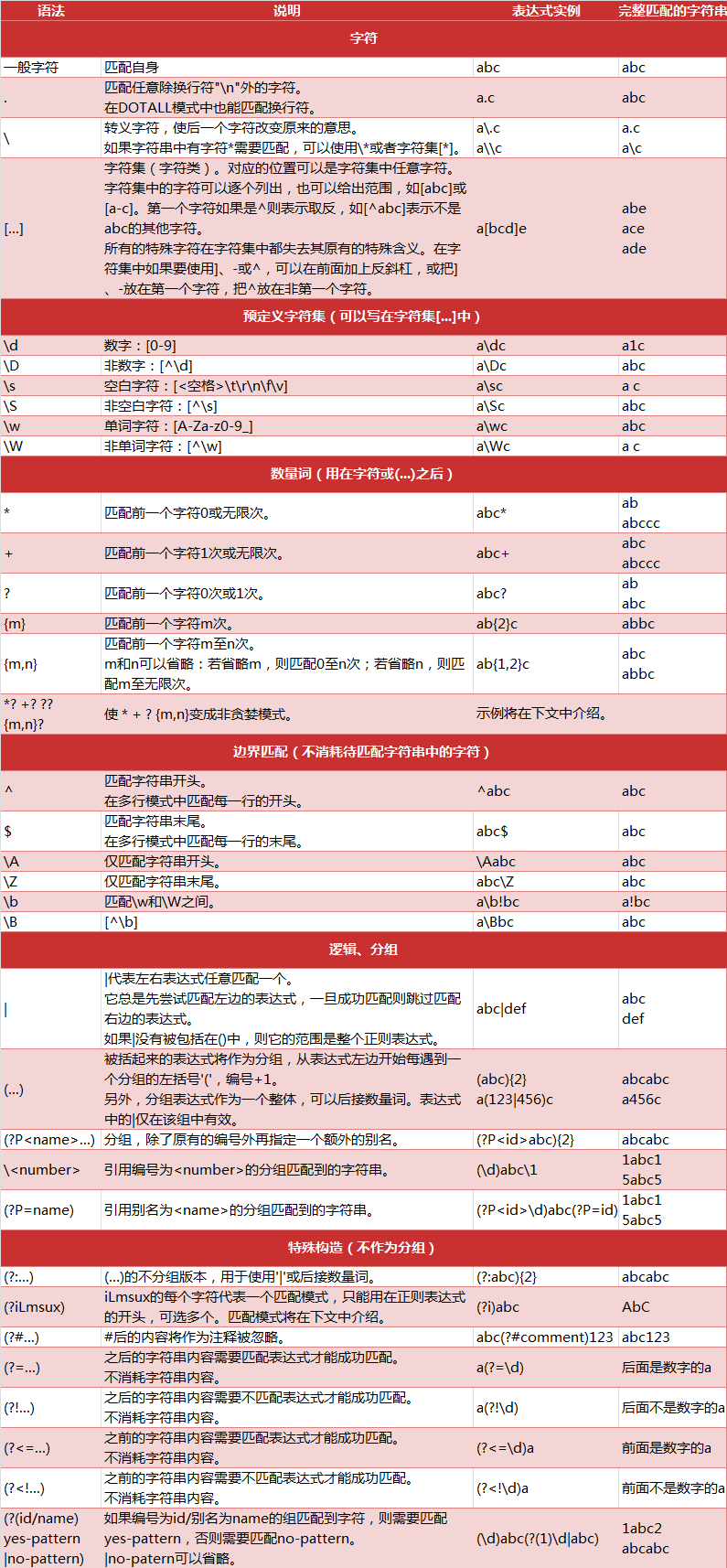
正则表达式相关注解
数量词的贪恋模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。
Python 里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;
非贪婪的则相反,总是尝试匹配尽可能少的字符。
例如:正则表达式”ab“如果用于查找” abbbc”,将找到”abbb”。而如果使用非贪婪的数量词”ab?”,将找到”a”。
注:我们一般使用非贪婪模式来提取。
反斜杠问题
与大多数编程语言相同,正则表达式里使用”\“作为转义字符,这就可能造成反斜杠困扰。
假如你需要匹配文本中的字符”\“,那么使用编程语言表示的正则表达式里将需要 4 个反斜杠”\\\\“:
前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python 里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用 r”\\“表示。同样,匹配一个数字的”\\d” 可以写成 r”\d”。
Python Re 模块
Python 自带了re模块,提供了对正则表达式的支持
方法
#返回pattern对象 re.compile(string[,flag]) #以下为匹配所用函数 re.match(pattern, string[, flags]) re.search(pattern, string[, flags]) re.split(pattern, string[, maxsplit]) re.findall(pattern, string[, flags]) re.finditer(pattern, string[, flags]) re.sub(pattern, repl, string[, count]) re.subn(pattern, repl, string[, count])
flags
七个方法中的 flags 同样是代表匹配模式的意思,如果在 pattern 生成时已经指明了 flags,那么在下面的方法中就不需要传入这个参数了
re.compile
re模块中包含一个重要函数是compile(pattern [, flags]) ,该函数根据包含的正则表达式的字符串创建模式对象。可以实现更有效率的匹配。在直接使用字符串表示的正则表达式进行search,match和findall操作时,python会将字符串转换为正则表达式对象。而使用compile完成一次转换之后,在每次使用模式的时候就不用重复转换。当然,使用re.compile()函数进行转换后,re.search(pattern, string)的调用方式就转换为 pattern.search(string)的调用方式。
使用 re.compile
其中,后一种调用方式中,pattern是用compile创建的模式对象。如下:
some_text = 'a,b,,,,c d' reObj = re.compile('[, ]+') print(reObj.split(some_text)) # 结果: ['a', 'b', 'c', 'd']
不使用 re.compile
在进行search,match等操作前不适用compile函数,会导致重复使用模式时,需要对模式进行重复的转换。降低匹配速度。而此种方法的调用方式,更为直观。如下:
import re some_text = 'a,b,,,,c d' re.split('[, ]+',some_text) # 结果:['a', 'b', 'c', 'd']
按位或运算符
re.I(全拼:IGNORECASE) # 忽略大小写(括号内是完整写法,下同) re.M(全拼:MULTILINE) # 多行模式,改变'^'和'$'的行为(参见上图) re.S(全拼:DOTALL) # 点任意匹配模式,改变'.'的行为 re.L(全拼:LOCALE) # 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定 re.U(全拼:UNICODE) # 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性 re.X(全拼:VERBOSE) # 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。
re.match(pattern, string[, flags])
这个方法将会从 string(我们要匹配的字符串)的开头开始,尝试匹配 pattern,一直向后匹配,如果遇到无法匹配的字符,立即返回 None,如果匹配未结束已经到达 string 的末尾,也会返回 None。两个结果均表示匹配失败,否则匹配 pattern 成功,同时匹配终止,不再对 string 向后匹配。下面我们通过一个例子理解一下
#导入re模块 import re # 将正则表达式编译成Pattern对象,注意hello前面的r的意思是“原生字符串” pattern = re.compile(r'hello') # 使用re.match匹配文本,获得匹配结果,无法匹配时将返回None result1 = re.match(pattern,'hello') result2 = re.match(pattern,'helloo CQC!') result3 = re.match(pattern,'helo CQC!') result4 = re.match(pattern,'hello CQC!') #如果1匹配成功 if result1: # 使用Match获得分组信息 print(result1.group()) else: print('1匹配失败!') #如果2匹配成功 if result2: # 使用Match获得分组信息 print(result2.group()) else: print('2匹配失败!') #如果3匹配成功 if result3: # 使用Match获得分组信息 print(result3.group()) else: print('3匹配失败!') #如果4匹配成功 if result4: # 使用Match获得分组信息 print(result4.group()) else: print('4匹配失败!')
结果如下:
hello
hello
3匹配失败!
hello
re.search(pattern, string[, flags])
search 方法与 match 方法极其类似,区别在于 match () 函数只检测 re 是不是在 string 的开始位置匹配,search () 会扫描整个 string 查找匹配,match()只有在 0 位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match () 就返回 None。同样,search 方法的返回对象同样 match () 返回对象的方法和属性。我们用一个例子感受一下
#导入re模块 import re # 将正则表达式编译成Pattern对象 pattern = re.compile(r'world') # 使用search()查找匹配的子串,不存在能匹配的子串时将返回None # 这个例子中使用match()无法成功匹配 match = re.search(pattern,'hello world!') if match: # 使用Match获得分组信息 print(match.group()) ### 输出 ### # world
re.split(pattern, string[, maxsplit])
按照能够匹配的子串将 string 分割后返回列表。maxsplit 用于指定最大分割次数,不指定将全部分割。我们通过下面的例子感受一下。
import re pattern = re.compile(r'\d+') print(re.split(pattern,'one1two2three3four4')) ### 输出 ### # ['one', 'two', 'three', 'four', '']
re.findall(pattern, string[, flags])
搜索 string,以列表形式返回全部能匹配的子串。我们通过这个例子来感受一下
import re pattern = re.compile(r'\d+') print(re.findall(pattern,'one1two2three3four4')) ### 输出 ### # ['1', '2', '3', '4']
re.finditer(pattern, string[, flags])
搜索 string,返回一个顺序访问每一个匹配结果(Match 对象)的迭代器。我们通过下面的例子来感受一下
import re pattern = re.compile(r'\d+') for m in re.finditer(pattern,'one1two2three3four4'): print(m.group()) ### 输出 ### # 1 2 3 4
re.sub(pattern, repl, string[, count])
使用 repl 替换 string 中每一个匹配的子串后返回替换后的字符串。 当 repl 是一个字符串时,可以使用 \id 或 \g、\g 引用分组,但不能使用编号 0。 当 repl 是一个方法时,这个方法应当只接受一个参数(Match 对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。 count 用于指定最多替换次数,不指定时全部替换。
import re pattern = re.compile(r'(\w+) (\w+)') s = 'i say, hello world!' print(re.sub(pattern,r'\2 \1', s)) def func(m): return (m.group(1).title() + ' ' + m.group(2).title()) print(re.sub(pattern,func, s)) ### output ### # say i, world hello! # I Say, Hello World!
re.subn(pattern, repl, string[, count])
返回 (sub (repl, string [, count]), 替换次数)。
import re pattern = re.compile(r'(\w+) (\w+)') s = 'i say, hello world!' print(re.subn(pattern, r'\2 \1', s)) def func(m): return (m.group(1).title() + ' ' + m.group(2).title()) print(re.subn(pattern, func, s)) ### output ### # ('say i, world hello!', 2) # ('I Say, Hello World!', 2)
Python Re 模块的另一种使用方式
在上面我们介绍了 7 个工具方法,例如 match,search 等等,不过调用方式都是 re.match,re.search 的方式,其实还有另外一种调用方式,可以通过 pattern.match,pattern.search 调用,这样调用便不用将 pattern 作为第一个参数传入了,大家想怎样调用皆可。 函数 API 列表
match(string[, pos[, endpos]]) | re.match(pattern, string[, flags]) search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]) split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]) findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]) finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]) sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]) subn(repl, string[, count]) |re.sub(pattern, repl, string[, count])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号