

ElasticSearch
ES
elasticsearch博客:https://www.cnblogs.com/Neeo/p/10864123.html#elk
E: elastic
S: search
Lucene
Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
基于Lucene的搜索引擎,Java开发,包括:
- Lucene
- Solr
- elasticsearch
- katta
- compass
ElasticSearch
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
elasticsearch中,是以文档的形式存储数据。
文档要比数据表的行更加灵活。因为文档可以是多层次的,它(文档)鼓励你将属于一个逻辑实体的数据保存在同一个文档中,而不是散落在各个表的不同行中。这样查询效率很高,因为我们无需连接其他的表
优点:
- 分布式:节点对外表现对等,加入节点自动均衡
- elasticsearch完全支持Apache Lucene的接近实时的搜索
- 各节点组成对等的网络结构,当某个节点出现故障时会自动分配其他节点代替期进行工作
- 横向可扩展性,如果你需要增加一台服务器,只需要做点配置,然后启动就完事了
- 高可用:提供复制(replica)机制,一个分片可以设置多个复制,使得某台服务器宕机的情况下,集群仍旧可以照常运行,并会把由于服务器宕机丢失的复制恢复到其它可用节点上;这点也类似于HDFS的复制机制(HDFS中默认是3份复制)
缺点:
- 不支持事物
- 相对吃内存
前言
- 逻辑设计,我们可以把elasticsearch与关系型数据做个客观对比:
| Relational DB | Elasticsearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | types |
| 行(rows) | documents |
| 字段(columns) | fields |
elasticsearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档中又包含多个字段(列)。
- 物理设计
注意:当然,这里需要补充的是,从elasticsearch的第一个版本开始,每个文档都存储在一个索引中,并分配多个映射类型,映射类型用于表示被索引的文档或者实体的类型,但这也带来了一些问题(详情参见Removal of mapping types),导致后来在elasticsearch6.0.0版本中一个文档只能包含一个映射类型,而在7.0.0中,映射类型则将被弃用,到了8.0.0中则将完全被删除。
逻辑设计:文档、类型、索引
一个索引类型中,包含多个文档,比如说文档1,文档2。
当我们索引一篇文档时,可以通过这样的顺序找到它:索引▷类型▷文档ID,通过这个组合我们就能索引到某个具体的文档。
注意:ID不必是整数,实际上它是个字符串。
文档
elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档,elasticsearch中,文档有几个重要属性:
- 自我包含,一篇文档同时包含字段和对应的值,也就是同时包含
key:value - 可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的
- 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
- 文档是无模式的,也就是说,字段对应值的类型可以是不限类型的。
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整型。因为elasticsearch会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型(因此带来的问题),这也是为什么在elasticsearch中,类型有时候也称为映射类型。
类型
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。
类型中对于字段的定义称为映射,比如name映射为字符串类型。
我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么elasticsearch是怎么做的呢?elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型,elasticsearch就开始猜,如果这个值是18,那么elasticsearch会认为它是整型。
但是elasticsearch也可能猜不对,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用,别整什么幺蛾子。后面在讨论更多关于映射的东西。
索引
索引是映射类型的容器,elasticsearch中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。
我们来研究下分片是如何工作的。
物理设计:节点、分片
一个集群包含至少一个节点,而一个节点就是一个elasticsearch进程。节点内可以有多个索引。
默认的,如果你创建一个索引,那么这个索引将会有5个分片(primary shard,又称主分片)构成,而每个分片又有一个副本(replica shard,又称复制分片),这样,就有了10个分片。
那么这个索引是如何存储在集群中的呢?

主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。
实际上,一个分片是一个Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。
倒排索引
elasticsearch使用的是一种称为倒排索引的结构,采用Lucene倒排索作为底层。这种结构适用于快速的全文搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。
倒排列表(Posting List)记录了词条对应的文档集合,由倒排索引项(Posting)组成。
倒排索引项主要包含如下信息:
- 文档id,用于获取原始信息。
- 词条频率(TF,Term Frequency),记录该词条在文档中出现的次数,用于后续相关性算分。
- 位置(Position),记录词条在文档中的分词位置(多个),用于做短语搜索(Phrase Query)。
- 偏移(Offset),记录词条在文档的开始和结束位置,用于做高亮显示。
以搜索引擎为例:
| 文档id | 文档内容 |
|---|---|
| 1 | elasticsearch是最流行的搜索引擎 |
| 2 | Python是世界上最好的语言 |
| 3 | 搜索引擎是如何诞生的 |
上述文档的倒排索引列表是这样的:
| DocID | TF | Position | Offset |
|---|---|---|---|
| 1 | 1 | 2 | <18,22> |
| 3 | 1 | 0 | <0,4> |
关于文档1,DocID是1无需多说,TF是1表示搜索引擎在文档内容中出现一次,Position指的是分词后的位置,首先要说文档内容会被分为elasticsearch、最流行、搜索引擎3部分,从0开始计算,搜索引擎的Position是2;Offset是搜索引擎这个字符在文档中的位置。
文档3中搜索引擎在文档中出现一次(TF:1),并且出现在文档的开始位置(Position:0),那么Offset的位置就是<0,4>无疑了。
再比如说,现在有两个文档, 每个文档包含如下内容:
Study every day, good good up to forever # 文档1包含的内容
To forever, study every day, good good up # 文档2包含的内容为了创建倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者tokens),然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在哪个文档:
| term | doc_1 | doc_2 |
|---|---|---|
| Study | √ | × |
| To | × | √ |
| every | √ | √ |
| forever | √ | √ |
| day | √ | √ |
| study | × | √ |
| good | √ | √ |
| every | √ | √ |
| to | √ | × |
| up | √ | √ |
现在,我们试图搜索to forever,只需要查看包含每个词条的文档:
| term | doc_1 | doc_2 |
|---|---|---|
| to | √ | × |
| forever | √ | √ |
| total | 2 | 1 |
两个文档都匹配,但是第一个文档比第二个匹配程度更高。如果没有别的条件,现在,这两个包含关键字的文档都将返回。
再来看一个示例,比如我们通过博客标签来搜索博客文章。那么倒排索引列表就是这样的一个结构:
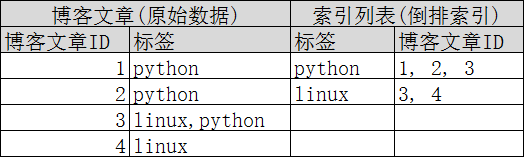
如果要搜索含有python标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快的多。只需要查看标签这一栏,然后获取相关的文章ID即可。
elasticsearch的索引和Lucene的索引对比
在elasticsearch中,索引这个词被频繁使用,这就是术语的使用。
并且elasticsearch将索引被分为多个分片,每份分片是一个Lucene的索引。所以一个elasticsearch索引是由多个Lucene索引组成的。
环境配置
elasticsearch for windows:Java环境配置
java
jdk安装一路下一步 配置JAVA_HOME 在系统变量里面新建一个变量名:JAVA_HOME,变量值:C:\Program Files\Java\jdk1.8.0_201 配置Path : 在系统变量的Path中,追加 %JAVA_HOME%\bin;
elasticsearch
解压到合适的目录中,合适:路径不要有中文 空格 特殊字符
启动安装目录中的bin目录下的 elasticsearch.bat
浏览器访问: http://127.0.0.1:9200/ --> json字符串 说明安装成功
kibana
解压到合适的目录中,合适:路径不要有中文 空格 特殊字符 启动安装目录中的bin目录下的 kibana.bat 浏览器访问: http://127.0.0.1:5601/ --> web页面 dev tools --> console
增删改查
创建文档
PUT zrq/doc/1 { "name":"nihao" }
返回
{ "_index" : "zrq", "_type" : "doc", "_id" : "1", "_version" : 3, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 2, "_primary_term" : 1 }
结果中的result则是操作类型,现在是created,表示第一次创建。如果我们再次点击执行该命令,那么result则会是updated。我们细心则会发现_version开始是1,现在你每点击一次就会增加一次。表示第几次更改。
查询所有索引
GET _cat/indices?v
展示当前集群中索引情况,包括,索引的健康状况、UUID、主副分片个数、大小等信息。
查询指定的索引信息
GET zrq/doc/_search
返回
{ "took" : 5, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : 2, "max_score" : 1.0, "hits" : [ { "_index" : "zrq", "_type" : "doc", "_id" : "2", "_score" : 1.0, "_source" : { "name" : "shuai" } }, { "_index" : "zrq", "_type" : "doc", "_id" : "1", "_score" : 1.0, "_source" : { "name" : "nihao" } } ] } }
查询文档信息
GET zrq/doc/1
删除所有
后追加文件
DELETE zrq
删除指定索引
DELETE zrq/doc/1
指定替换
POST zrq/doc/2/_update { "doc": { "age":[19] } }
全部替换
PUT全部替换
PUT zrq/doc/2 { pass }
查询的两种方式
字符串查询
GET zhifou/doc/_search?q=from:gu
还是使用GET命令,通过_serarch查询,查询条件是什么呢?条件是from属性是gu家的人都有哪些。最后,别忘了_search和from属性中间的英文分隔符?。
结构化查询
使用DSL方式
GET zhifou/doc/_search { "query": { "match": { "from": "gu" } } }
query条件
match 和 match_all
上例,查询条件是一步步构建出来的,将查询条件添加到match中即可,而match则是查询所有from字段的值中含有gu的结果就会返回。
sort
升降序 desc和asc
GET zrq/doc/_search { "query":{ "match_all": {} }, "sort": [ { "age": { "order": "asc" } } ] }
from
from 索引位置
size 拿取数量
GET zrq/doc/_search { "query":{ "match_all": {} }, "from":0, "size":2 }
_source选择字段
可以为下面两种方式
"_source": "{name}"
或 "_source": ["name","age"]
GET zrq/doc/_search { "query":{ "match_all": {} }, "from":0, "size":2,"_source": "{name}" }
elasticsearch之match系列
高亮查询
elasticsearch之布尔查询
elasticsearch之聚合函数
elasticsearch之mappings
elasticsearch mappings之dynamic的三种状态
elasticsearch之mappings的其他设置:index、copy_to、对象属性、settings

 浙公网安备 33010602011771号
浙公网安备 33010602011771号