Python实现百度贴吧自动顶贴机
开发这款小工具,我们需要做一些准备:
- url.txt:多个需要顶起的帖子地址。
- reply:多条随机回复的内容。
- selenium:浏览器自动化测试框架
首先,我们先使用pip完成selenium的安装。
示例代码:
pip install -U selenium接下来,我们添加对浏览器的支持,这里使用火狐浏览器。
对应Windows环境下的火狐浏览器,我们需要下载一个小程序:geckodriver.exe
下载地址:http://download.csdn.net/download/xingbb99/10245371
把下载下来的压缩包解压缩,将exe文件直接放在项目文件夹中。
这里需要注意,如果火狐浏览器不是默认安装的话,需要将浏览器的安装路径添加到系统环境变量的Path中。
完成以上准备,我们就可以进行编程了。
一、导入必需的模块
示例代码:
二、创建浏览器测试对象
示例代码:
三、定义将Cookie添加到测试对象的函数
Cookie的获取可以在火狐浏览器中打开贴吧地址后,按F12或右键菜单中选择【查看元素】,在打开的开发工具界面中,选择网络(NetWork),点开右侧收起的消息栏,点选【Cookie】复制其中的内容。
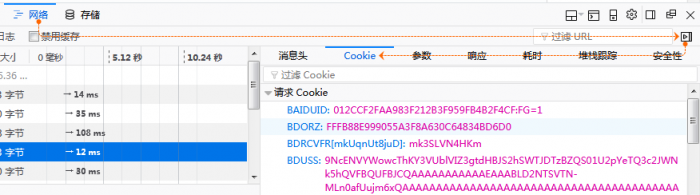
![]()
将Cookie内容存入变量,通过正则表达式获取字段并转换为字典后,添加到浏览器测试对象中。
示例代码:
示例代码:
五、定义写入评论并提交的函数
示例代码: def reply(): content = get_content() # 获取评论内容 js = "document.getElementById('ueditor_replace').innerHTML='%s'" % content # 编写js脚本 browser.execute_script(js) # 执行js脚本 browser.find_element_by_css_selector('.poster_submit').click() # 点击发表按钮
注意:请申请小号进行测试,以免封号。
示例代码:
完整代码
from selenium import webdriver # 导入网页内驱动模块 from selenium.webdriver.common.keys import Keys # 导入按键类 from selenium.webdriver.common.action_chains import ActionChains # 导入动作类 from random import choice from time import sleep import re ''' 想要学习Python?Python学习交流群:984632579满足你的需求,资料都已经上传群文件,可以自行下载! ''' profile = webdriver.FirefoxProfile(r'C:\Users\Administrator\AppData\Roaming\Mozilla\Firefox\Profiles\nczl01ld.default') browser = webdriver.Firefox(profile, timeout=300) # 使用profile可以实现自动登录 def cookie(): cookies = ''' BAIDUID = 012CCF2FAA983F21333F959FB4B2F4CF:FG=1; BDORZ = FFFB88E999055A3F86630C64834BD6D0; BDUSS = 9NcENVYWowcThKY3VUblVIZ3g...太长了此处省略一部分...S01U2AAABvKe1obyntaaG; BIDUPSID = 23A4C6D0C2851099D66FBFDBA99EDF3B; FP_UID = 0d8be11adc641cb5501f1e68270d8bea; H_PS_PSSID = 1457_21116_22072; MCITY = -131:; PSINO = 1; PSTM = 1506587758; ''' cookiesList = re.findall(r'([\S\s]*?)=([\S\s]*?);', cookies) for cookie in cookiesList: ck = {'name': cookie[0].strip(), 'value': cookie[1].strip()} browser.add_cookie(ck) # 添加cookie到浏览器测试对象 def get_content(): file = open('reply.txt', encoding='utf-8').readlines() # 读取所有评论 return choice(file).strip() # 随机获取一行评论并返回 def reply(): content = get_content() # 获取评论内容 js = "document.getElementById('ueditor_replace').innerHTML='%s'" % content # 编写js脚本 browser.execute_script(js) # 执行js脚本 browser.find_element_by_css_selector('.poster_submit').click() # 点击发表按钮 def main(): count = 0 for url in open('url.txt', encoding='utf-8').readlines(): # 逐行读取url文件 count += 1 if count >= 5: # 从url文件中的第5个地址开始回复 browser.get(url) # 打开地址 sleep(10) # 避免回复过快,地址打开后等待10秒钟。 cookie() # 添加cookie browser.execute_script("window.scrollTo(0,document.body.scrollHeight)") # 滚动到页面底部 reply() # 写入回复内容并提交 sleep(5) # 等待完成提交 ActionChains(browser).key_down(Keys.CONTROL).send_keys("w").key_up(Keys.CONTROL).perform() # 关闭网页 if __name__ == '__main__': main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号