Python3 文件系统
今天学了python3 的文件系统,高大上啊~~~~
1、os模块和 os.path模块
os模块中文件目录和函数的使用方法
| 函数 | 使用方法 |
| getcwd() | 返回当前工作目录 |
| chdir(path) | 改变工作目录 |
| listdir(path='.') | 列举指定目录中的文件名(‘.’表示当前陌路‘..’表示上一级目录) |
| mkdir(path) | 创建单层目录,如果目录已存在则抛出异常 |
| makedirs(path) | 创建多层目录,如果目录已存在则抛出异常 注意:E:\\a\\c和E:\\a\\b不会冲突 |
| remove(path) | 删除文件 |
| rmdir(path) | 删除单层目录,如果该目录非空则抛出异常 |
| removedirs(path) | 递归删除目录,从子目录到父目录逐层尝试删除,遇到目录非空则抛出异常 |
| rename(old,new) | 将文件old重命名为new |
| system(commend) | 运行系统的shell命令 |
| walk(top) | 遍历top路径以下所有的子目录,返回一个三元组(路径,[包含目录],[包含文件]) |
| 以下是支持路径操作中常用到的一些定义,支持所有平台 | |
| os.curdir | 指代当前目录'.' 用os.curdir表示当前目录更准确(怡红院来者不拒哈哈哈) |
| os.pardir | 指代上一级目录‘..’ |
| os.sep | 输出操作系统特定的路径分割符(WIN下为'\\'Linux下为'/') |
| os.linesep | 当前操作系统下的行终止符(win下为'\r\n' Linux下为'\n') |
| os.name | 指代当前的操作系统(‘posix’ ‘nt’ ‘mac’ ‘os2’ ‘ce’ ‘java’)打到这到这觉得Python好好用... |
os.path模块中关于路径常用的函数使用方法
| 函数名 | 使用方法 |
| basename(path) | 去掉目录路径单独返回文件名 |
| dirname(path) | 去掉文件名单独返回目录路径 |
| join(path1[,path[,...]]) | 将path1和path2各部分组合成一个路径名 |
| split(path) |
分割文件名与路径,返回(f_path,f_name)形式的元组,如果都是目录,他也会将最后一个目录作为文件分离 ,且不会判断文件或者目录是否存在 |
| splitext(path) | 分离文件名和扩展名返回(f_name,f_ext)形式的元组
>>> import os |
| getsize(file) | 返回指定文件尺寸,大小为字节 |
| getatime(file) | 返回指定文件最近的访问时间(浮点型秒数,可用time模块的gmtime()和localtime()转换) |
| getctime(file) | 返回指定文件的创建时间(浮点型秒数,可用time模块的gmtime()和localtime()转换) |
| getmtime(file) | 返回指定文件最新修改时间(浮点型秒数,可用time模块的gmtime()和localtime()转换) |
| 以下函数返回True or False | |
| exists(path) | 判定指定路径(文件或目录)是否存在 |
| isabs(path) | 判断路径是否为绝对路径 绝对路径:E:\\A\\B\\text.txt 相对路径:A\\B\\text.tx |
| isdir(path) | 判断路径是否存在且一个目录 |
| isfile(path) | 判断路径是否存在且是一个文件 |
| islink(path) | 判断路径是否存在且是一个符号链接 |
| ismount(path) | 判断路径是否存在且是一个挂载点 :E:\\ C:\\ |
| samefile(path1,path2) | 判断两个路径是否指向同一个文件 |
例题:
1、统计当前目录下每个文件类型个数(改进版)
import os c=os.getcwd() name_in_file=os.listdir(c) def count_filetype(name): count=0 content=[]#用来存储该路径下所有扩展名 for each_name in name_in_file: Suffix=os.path.splitext(each_name) content.append(Suffix[1]) type_count=set(content)#集合里的元素是唯一的,这样就可以把相同的扩展名去掉得到文件含有的扩展名 #print(type_count) for Extension in type_count: for Splited_Ext in content: if Extension == Splited_Ext: if Extension=='': Extension='文件夹' count+=1 print('该文件夹下共有类型为【%s】的文件 %d 个'%(Extension,count)) count=0#统计完一次计数器清零 return 1 count_filetype(name_in_file)
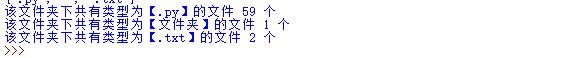
2、输入文件名搜索指定文件夹是否存在该文件
import os def Find_Aim_File(path,file_name): os.chdir(path)#1.改变工作路径 container = os.walk(os.getcwd())#2.获取当前工作路径,3.遍历该路径下所有子目录 for each in container: for each_name in each[2]: if each_name == file_name: print(each[0]+os.sep+each_name) Initial_direct=input('请输入查找的初始目录:') Target_File=input('请输入需要查找的目标文件:') Find_Aim_File(Initial_direct,Target_File)

3、计算工作目录下各个文件的大小
import os c=os.getcwd()#返回当前工作目录 #使用os.curdir 表示当前目录更标准 List_File_Nname=os.listdir(c)#列举该目录下的文件名,返回一个列表 def Get_File_Size(list_file_name): for each_name in list_file_name: print("%s【%d Bytes】"%(each_name,os.path.getsize(each_name))) Get_File_Size(List_File_Nname)

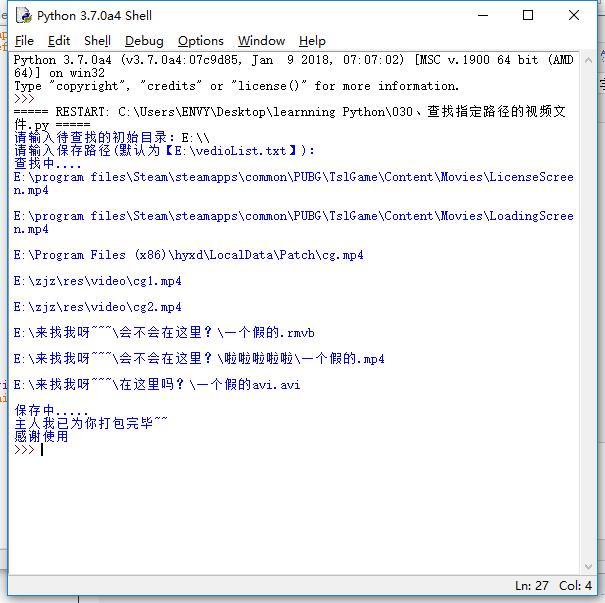
4、查找指定路径的视频文件,并保存路径为文本文档(AV没地方藏了doge脸)
import os def Find_Vedio(directory,save_path): flag=0 save_data=[] os.chdir(directory)#改变工作目录 container=os.walk((os.getcwd()))#获取当前工作目录#遍历该目录下所有子目录 for sub_directory in container: for each_file_name in sub_directory[2]: splited_file_name=os.path.splitext(each_file_name)#返回[文件名,扩展名] if splited_file_name[1] in ['.avi','.mp4','.rmvb']: #vedio_name=(sub_directory[0]+'\\'+each_file_name+'\n') vedio_name=(sub_directory[0]+os.sep+each_file_name+os.linesep)#改成这句使程序更标准 save_data.append(vedio_name) print(vedio_name) flag=1 save_txt=open(save_path,'w') print('保存中.....') save_txt.writelines(save_data) save_txt.close() print('主人我已为你打包完毕~~') if flag==0: print('真是不看片的好小伙!居然找不到!!!') print('请输入待查找的初始目录:',end='') while 1: initial_directory = input() print('请输入保存路径(默认为【E:\\vedioList.txt】):',end='') Savepath=input() if Savepath=='': Savepath='E:/vedioList.txt' if ':\\' not in initial_directory and ':\\'not in Savepath: print("格式错误请重新输入:",end='') continue else: print('查找中....') Find_Vedio(initial_directory,Savepath) print('感谢使用') break
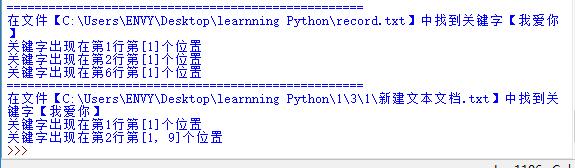
5、查找当前文件夹内文本文档内是否含有关键字并输出位置
import os path=os.getcwd() container=os.walk(path) def find_txt(path): txt_name_container=[]#存放文本文件文件名 for each_path in container:#each_path的格式为(路径,[包含目录],[包含文件]) for each_file_name in each_path[2]: splited_name=os.path.splitext(each_file_name)#将文件名和扩展名拆分返回一个列表 if splited_name[1]=='.txt': #file_path=each_path[0]+'\\'+each_file_name#得到文本文件路径 file_path=os.path.join(each_path[0],each_file_name)#上面这句话可以改成这一句 txt_name_container.append(file_path)#将文本文件路径存入列表 return txt_name_container def find_keyword(target_file_list,key_word,c): positions=[] flag=0 for each_file_name in target_file_list: row=0 txt_file=open(each_file_name)#以只读文本方式打开文件 for each_line in txt_file: if key_word in each_line: print('===================================================') print('在文件【%s】中找到关键字【%s】'%(each_file_name,key_word)) flag=1 txt_file.close() break if flag==0: print("没有在该文件夹中找到关键字!") break elif flag==1 and c in ['YES','yes','y','Y']: txt_file=open(each_file_name) for each_line in txt_file: end=len(each_line) #print(end) row+=1 for start in range(end): p=(each_line.find(key_word,start,end)+1) #print(p) if p!=0 and p not in positions: positions.append(p) if positions : print('关键字出现在第%d行第%s个位置'%(row,positions)) positions=[] txt_file.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号