爬虫
基本操作
url发送http请求
requests
安装:pip3 install requests
使用:import requests
- requests.get
- encoding 默认的编码格式utf8,涉及不同的编码格式的时候可以自己指定
- content 字节内容
- text 解码后的文本内容
import requests
from bs4 import BeautifulSoup
response = requests.get('http://www.autohome.com.cn/news/')
response.encoding = 'gbk' # 用的是gb2312
print(response.content) # 查看的是字节内容
print(response.text) # 查看的是解码后的内容
BeautifulSoup
安装:pip3 install BeautifulSoup4
使用:from bs4 import BeautifulSoup
BeautifulSoup把所有的标签转换成对象,对象有find方法,标签对象下面的对象还有相应的find find_all()方法
标签.attrs() 获得是字典
.get() 获取字典中属性
bt4 response默认是编码是utf8,出现乱码尝试gbk
find_all 返回的是列表,列表中是对象
html.parser html解析器
tag.find(id=) id是唯一的
tag.find(name=) name找标签名
tag.find(class_= ) 找class
tag.find(attrs={'class':'xxx',id:'xxx'} ) attrs中没有name
find_all 用for循环把列表
对于找不到的会出现None,先判断 continue
soup = BeautifulSoup(response.text,'html.parser') # html.parser 是html解析器
tag = soup.find(attrs={'id':'auto-channel-lazyload-article'})
# tag = soup.find(class_ ='article')
h3 = tag.find(name = 'h3') # 通过对象继续find
print(h3)
获取汽车之家的新闻
获取的内容包含文章标题,文章超链接,文章图片等内容,获取下面所有的li,但是其中有的None,需要排除
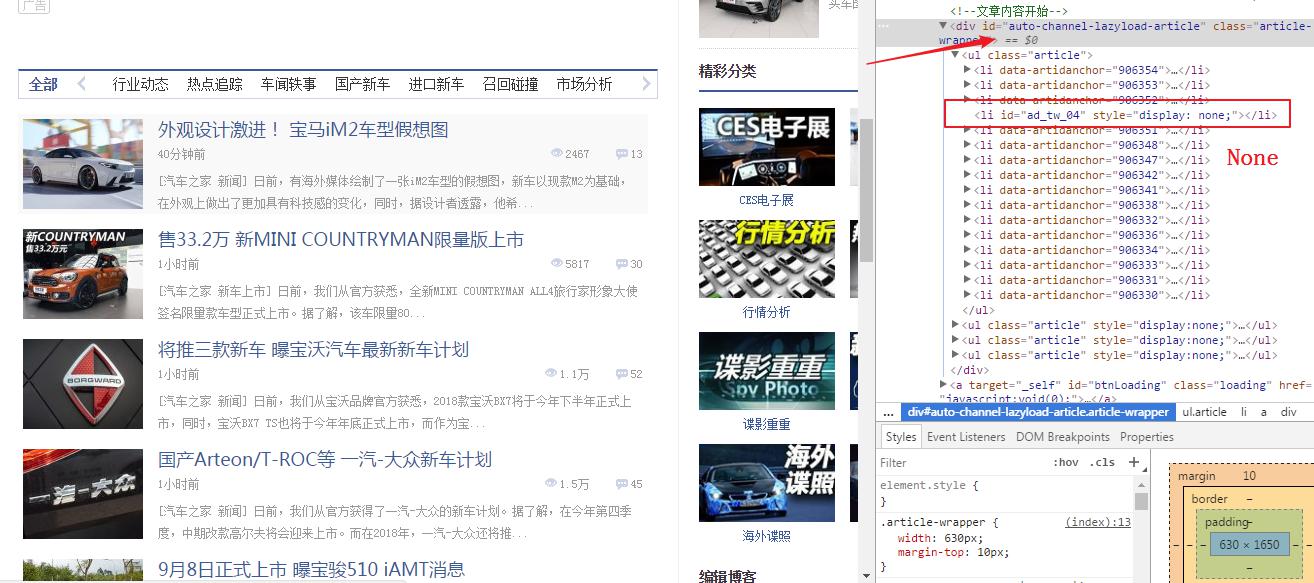
获取属性中的内容,由于属性是字典格式的,所以用[] 或者get取值
# url = li.find('a').attrs # 是字典类型
# url = li.find('a').attrs['href'] # 获取字典类型中的内容
url = li.find('a').get('href') # 获取字典类型中的内容
# 找所有的标题 简介url 图片
import requests
from bs4 import BeautifulSoup
import os
response = requests.get('http://www.autohome.com.cn/news/')
response.encoding = 'gbk'
soup = BeautifulSoup(response.text,'html.parser')
li_list = soup.find(id='auto-channel-lazyload-article').find_all('li') # 获取所有的li标签
for li in li_list:
title = li.find('h3') # 获取每个li标签中的h3标签
if not title:
continue # 清除没有h3标签的内容
title = title.text # 标题的文本内容
summary = li.find('p').text # 概要内容
# url = li.find('a').attrs # 是字典类型
# url = li.find('a').attrs['href'] # 获取字典类型中的内容
url = li.find('a').get('href') # 获取字典类型中的内容
img = li.find('img').get('src')
# print(title,summary,url,img)
# 重新向图片的地址发送请求并保存图片到本地
res = requests.get(img) # 获取图片的内容
img_name = os.path.split(img)[1].split('120x90_0_autohomecar__')[1] # 取出文件名
# img_name = title.replace('/','') # 或者用标题当做名字
img_file = "img/%s"%(img_name)
with open(img_file,'wb') as f:
f.write(res.content)
Python代码登录GitHub
响应头
是否有csrf_token
- 登录页面发送请求,获取csrf_token
- 发送POST请求
用户名
密码
csrf_token
cookie
Github的登录方式
github在在发送get请求的时候服务端发送cookie到浏览器,第一次登录的时候需要带着cookie
把get和POST请求中的cookie整合,一起发送到客户端
有的网站是POST请求登录成功后服务端发送cookie
网站的登录模式:
- get 后获得cookie 携带cookie发送post 登录对cookie进行授权
- 直接post获得cookie然后携带cookie进行操作
cookie中的gpsd
import requests
from bs4 import BeautifulSoup
# 获取token
r1 = requests.get('https://github.com/login') # 发送get请求
s1 = BeautifulSoup(r1.text, 'html.parser') # beautiful 对象
token = s1.find(name='input', attrs={'name': "authenticity_token"}).get('value') # 找到隐藏的input标签 获取csrf_token attrs中的name是属型
r1_cookie_dict = r1.cookies.get_dict() # 获取get请求中的cookie
# 将用户名 密码 csrf_token 发送到服务端
"""
https://github.com/session
commit "Sign+in"
utf8 "✓"
authenticity_token "yUjcQ4Z1ReIvo1XL8Tc2Ecy5L7Y8G…AHrBMGjqzZr1MG7WiZolGKvpNg=="
login "aaa"
password "aaa"
"""
r2 = requests.post(
'https://github.com/session', # 发送请求的url
data={
"commit": "Sign+in",
"utf8": "✓",
"authenticity_token": token,
"login": "用户名",
"password": "密码",
},
cookies=r1_cookie_dict # 携带get请求中的cookie
)
r2_cookie_dict = r2.cookies.get_dict() # 获取登录后的cookie
cookie_dict = {}
cookie_dict.update(r1_cookie_dict)
cookie_dict.update(r2_cookie_dict) # 把cookie中的字典整合
# 任意操作其他页面
r3 = requests.get(
url='https://github.com/settings/emails',
cookies=cookie_dict
)
print(r3.text)
抽屉新热 点赞
抽屉的登录是通过ajax登录的。就是发送的ajax请求,用一个电话号码进行测试,在网络请求中获得Fromdata的数据知道了发送的数据格式,点赞是通过ajax发送的POST请求,成功后有返回值
抽屉的登录cookie是用gpsd即可
import requests
from bs4 import BeautifulSoup
# 获取cookie
r0 = requests.get('http://dig.chouti.com/')
r0_cookie_dict = r0.cookies.get_dict() # 从get请求中获取cookie字典
# 发送用户名 密码
r1 = requests.post(
url='http://dig.chouti.com/login',
data={
'phone':'86xxxxxxx', # 电话号码加86
'password':'woshiniba',
'oneMonth':1
},
cookies=r0_cookie_dict
)
r1_cookie_dict = r1.cookies.get_dict() # 获取登录后的cookie
# cookie_dict = {}
# cookie_dict.update(r0_cookie_dict)
# cookie_dict.update(r1_cookie_dict)
cookie_dict = {
'gpsd': r0_cookie_dict['gpsd'] # 这里实际只需要gpsd即可
}
r2 = requests.post(
url='http://dig.chouti.com/link/vote?linksId=13924821',
cookies=cookie_dict
)
print(r2.text)
结果:
{"result":{"code":"9999", "message":"推荐成功", "data":{"jid":"cdu_45792645155","likedTime":"1503918027683000","lvCount":"9","nick":"xxxxxxxxx","uvCount":"2601","voteTime":"小于1分钟前"}}}
requests Beautiful Soup使用
requests模块中的方法
参考:
http://www.cnblogs.com/wupeiqi/articles/6283017.html
请求方式
本质是requests.request('method',url,data)
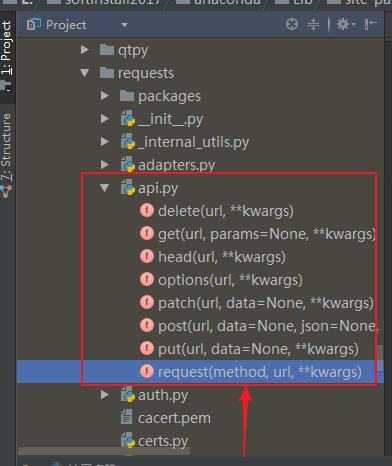
import requests
# 1. 调用关系
requests.get()
requests.post()
requests.put()
requests.request('post')
常用参数
参数分为get请求的和POST请求的参数
def request(method, url, **kwargs):
"""Constructs and sends a :class:`Request <Request>`.
:param method: method for the new :class:`Request` object.
:param url: URL for the new :class:`Request` object.
:param params: (optional) Dictionary or bytes to be sent in the query string for the :class:`Request`.
:param data: (optional) Dictionary, bytes, or file-like object to send in the body of the :class:`Request`.
:param json: (optional) json data to send in the body of the :class:`Request`.
:param headers: (optional) Dictionary of HTTP Headers to send with the :class:`Request`.
:param cookies: (optional) Dict or CookieJar object to send with the :class:`Request`.
:param files: (optional) Dictionary of ``'name': file-like-objects`` (or ``{'name': file-tuple}``) for multipart encoding upload.
``file-tuple`` can be a 2-tuple ``('filename', fileobj)``, 3-tuple ``('filename', fileobj, 'content_type')``
or a 4-tuple ``('filename', fileobj, 'content_type', custom_headers)``, where ``'content-type'`` is a string
defining the content type of the given file and ``custom_headers`` a dict-like object containing additional headers
to add for the file.
:param auth: (optional) Auth tuple to enable Basic/Digest/Custom HTTP Auth.
:param timeout: (optional) How long to wait for the server to send data
before giving up, as a float, or a :ref:`(connect timeout, read
timeout) <timeouts>` tuple.
:type timeout: float or tuple
:param allow_redirects: (optional) Boolean. Set to True if POST/PUT/DELETE redirect following is allowed.
:type allow_redirects: bool
:param proxies: (optional) Dictionary mapping protocol to the URL of the proxy.
:param verify: (optional) whether the SSL cert will be verified. A CA_BUNDLE path can also be provided. Defaults to ``True``.
:param stream: (optional) if ``False``, the response content will be immediately downloaded.
:param cert: (optional) if String, path to ssl client cert file (.pem). If Tuple, ('cert', 'key') pair.
:return: :class:`Response <Response>` object
:rtype: requests.Response
Usage::
>>> import requests
>>> req = requests.request('GET', 'http://httpbin.org/get')
<Response [200]>
"""
- get
request.get(
utl=''
params={'k1':'v1','nid':222} , url 后面的参数
cookies={},
headers={}, 请求头
)
- post POST有数据data 和json
request.get(
url=''
params={'k1':'v1','nid':222} , url 后面的参数
cookies={},
headers={} ,请求头
data={},
json={}
)
在向后台发送请求的时候注意:请求头。如果是Formdata数据,默认是application/x-www-form-urlencoded
post默认带请求头
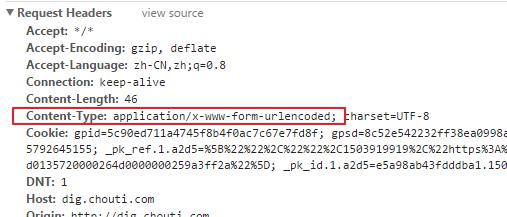
定制请求头发送json数据
data={} 默认的请求头是application/x-www-form-urlencoded
json={} 知己就把请求头发送过去了
requests.post(url='',data={},headers={'content-type': 'application/json'})
这样后台接收到的数据在request.body中
不常用参数
- auth 定制请求头 如路由器的配置 HttpBasicAuth
- timeout 请求超时 有两种
只有一个值的时候是等待数据的时间
有两个值的时候是一个元组,(连接时间,等待数据时间)
- allow_redirects 是否允许重定向
重定向 302 获取的数据是重定向网站的数据
当访问一个网站的时候,如果重定向到其他的网站,最终获取的是重定向后的网站的数据
- proxies 代理 防止封IP
格式是字典
需要用户名 密码的代理
def param_proxies():
# proxies = {
# "http": "61.172.249.96:80",
# "https": "http://61.185.219.126:3128",
# }
# proxies = {'http://10.20.1.128': 'http://10.10.1.10:5323'}
# ret = requests.get("http://www.proxy360.cn/Proxy", proxies=proxies)
# print(ret.headers)
# from requests.auth import HTTPProxyAuth
#
# proxyDict = {
# 'http': '77.75.105.165',
# 'https': '77.75.105.165'
# }
# auth = HTTPProxyAuth('username', 'mypassword')
#
# r = requests.get("http://www.google.com", proxies=proxyDict, auth=auth)
# print(r.text)
- stream
针对大的文件,一点点的获取数据
res.iter_content()
自动关闭上下文
from contextlib import closing
with closing()
def param_stream():
ret = requests.get('http://127.0.0.1:8000/test/', stream=True)
print(ret.content)
ret.close() # 关闭连接
# from contextlib import closing 自动关闭上下文
# with closing(requests.get('http://httpbin.org/get', stream=True)) as r:
# # 在此处理响应。
# for i in r.iter_content():
# print(i)
- verify
现在的网站Http https都能登录 证书
True 带证书
False 不带证书
知乎等网站可带可不带,证书就是对数据进行加密
- cert
证书是一个文件xxx.pem
def param_stream():
ret = requests.get('http://127.0.0.1:8000/test/', stream=True,cert='xxx.pem')
print(ret.content)
ret.close()
# from contextlib import closing
# with closing(requests.get('http://httpbin.org/get', stream=True)) as r:
# # 在此处理响应。
# for i in r.iter_content():
# print(i)
request的session
request 的session 可认为是一个容器
放的所有请求,用的时候直接用session携带
但是不推荐使用这个,遇到问题的时候找不到
import requests
session = requests.Session()
### 1、首先登陆任何页面,获取cookie
i1 = session.get(url="http://dig.chouti.com/help/service")
### 2、用户登陆,携带上一次的cookie,后台对cookie中的 gpsd 进行授权
i2 = session.post(
url="http://dig.chouti.com/login",
data={
'phone': "8615131255089",
'password': "xxxxxx",
'oneMonth': ""
}
)
i3 = session.post(
url="http://dig.chouti.com/link/vote?linksId=8589623",
)
print(i3.text)
Beautiful Soup模块中的方法
from bs4.elements import
高性能(Socket+select)
- twisted
- torando
- gevent
异步+协程
web版微信
Scrapy框架
提高竞争力:深入源码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号