Python 并发编程
1 为什么有操作系统
- 操作系统: 位于底层和应用软件之间
- 工作方式: 向下管理硬件 向上提供接口
1.1 操作系统进程切换:
- 出现IO操作(像time.sleep之类的)
- 固定时间(是操作系统控制的切换时间)
1.2进程的定义:
进程是一个程序在一个数据集谁给你的动态执行过程。
程序、数据集(程序过程中使用的资源)、进程控制块(切换的时候 保存状态)
进程并发的时候,如果是一个应用程序,会把资源进行传递
进程是通过进程切换,是共享的资源,保存的的时候保存的是进程的资源集
- 进程:
资源管理单位(容器) - 线程:
最小执行单位
1.3 并行和并发的区别:
串行是线程依次执行,运行期间独享内存
并行是每个线程占用一个内核
并发是有等待

** python的多线程:**
** 由于GIL,同一时刻,同一进程只能有一个线程被运行**
但是可以实现多进程的并发
import threading
import time
s = time.time()
def listen():
print("listen")
time.sleep(3)
print("listen end")
def blog():
print("blog")
time.sleep(5)
print("blog end")
if __name__ == '__main__':
t1 = threading.Thread(target=listen) # 实例化
t2 = threading.Thread(target=blog)
t1.start() # 使用start方法调用
t2.start()
# t1.join()
# t2.join() # t1 t2 接收后 才开始主线程
print(time.time()-s) # 总的时间
print("main ending")
'''
结果:
listen
blog
0.0
main ending # 这个是3个运行完毕
listen end
blog end
可以证明的是实现了线程的切换
'''
使用join 方法,主线程会等待其余的结束后才运行
import threading
import time
s = time.time()
def listen():
print("listen")
time.sleep(3)
print("listen end")
def blog():
print("blog")
time.sleep(5)
print("blog end")
if __name__ == '__main__':
t1 = threading.Thread(target=listen) # 实例化
t2 = threading.Thread(target=blog)
t1.start() # 使用start方法调用
t2.start()
t1.join()
t2.join() # t1 t2 接收后 才开始主线程
print(time.time()-s) # 总的时间
print("main ending")
'''
结果:
listen
blog
listen end
blog end
5.001286029815674 # 这里是线程2运行结束的时间
main ending # 最终运行主线程
'''
# 方式2 使用的是run方法
自己定义的类取执行
```python
import time
import threading
class MyThread(threading.Thread): # 继承
def __init__(self, num):
threading.Thread.__init__(self)
self.num = num
def run(self):
print("the num is %s" % self.num)
time.sleep(3)
t1 = MyThread(56) # 参数
t2 = MyThread(78)
t1.start()
t2.start()
print("ending") # 这是主线程
'''
结果:
the num is 56
the num is 78
ending
'''
1.4 join方法
t.join() 主线程等待对象等待完
t1.start()
t2.start()
t1.join()
t2.join()
如果是: 下面就是串行
t1.start()
t1.join()
t2.start()
t2.join()
1.5 守护线程
setDaemon
主线程结束了,子线程就结束了
线程开启之后就不能控制
有自他的子线程t1,t2的时候,t2是守护线程,主线程先等待t1,主线程结束后,守护线程关闭。
import threading
from time import ctime, sleep
import time
def Music(name):
print("Begin listening to {name}. {time}".format(name=name, time=ctime()))
sleep(3)
print("end listening {time}".format(time=ctime()))
def Blog(title):
print("Begin recording the {title}. {time}".format(
title=title, time=ctime()))
sleep(5)
print('end recording {time}'.format(time=ctime()))
threads = []
t1 = threading.Thread(target=Music, args=('music',))
t2 = threading.Thread(target=Blog, args=('blog',))
threads.append(t1)
threads.append(t2)
if __name__ == '__main__':
t1.setDaemon(True) # 把t2设置成守护线程
t2.setDaemon(True)
t1.start()
t2.start()
# for t in threads:
# t.setDaemon(True) #注意:一定在start之前设置
# t.start()
# for t in threads:
# t.join()
# t1.join()
# t2.join() # 考虑这三种join位置下的结果?
print("all over %s" % ctime())
1.6 其他的方法
Thread实例对象的方法
# isAlive(): 返回线程是否活动的。
# getName(): 返回线程名。
# setName(): 设置线程名。
threading模块提供的一些方法:
# threading.currentThread(): 返回当前的线程变量。
# threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
# threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
GIL 全局解释器锁
Global Interpreter Lock
加在CPython的解释器中,只有CPyhton中受到限制
阻止多线程并行
** python的多线程:**
** 由于GIL,同一时刻,同一进程只能有一个线程被运行**
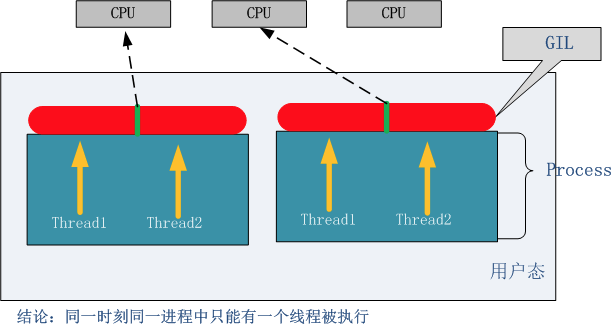
使用多进程的时候就可以突破这个限制
提高效率,用协程
- 对于IO密集型的提高效率,不使用CPU
使用time.sleep的
- 计算密集型,一直是在使用CPU,
import threading
import time
s = time.time()
def counter():
sum = 0
for i in range(50000000):
sum += i
if __name__ == '__main__':
# counter()
# counter()
t1 = threading.Thread(target=counter)
t2 = threading.Thread(target=counter)
t1.start()
t2.start()
t1.join()
t2.join()
print(time.time() - s)
'''
py2.7:
串行:10.5270001888
并发:15.7999999523
py3.:
串行:6.322361707687378
并发:6.371364593505859
Python3 的GIL已经进行了优化
'''
总结:
对于计算密集型的任务,Python多线程没有用
对于IO密集型的任务,Python多线程有用
Python使用多核: 开多进程
弊端: 内存开销大切换复杂
解决方案:
- 使用协程,是单线程还可以自己控制切换的此时
- **IO多路复用 ** 以后大多的的应用场景
- 终极思路:C模块实现多线程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号