Spider-天眼查字体反爬
字体反爬也就是自定义字体反爬,通过调用自定义的woff文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容!
1.思路
近期在爬取天眼查某公司详情页遇到了字体反爬,经过多次测试,终于解决了字体反爬
首先我们来看一下字体反爬

此图可以看出源代码数字跟页面显示的内容是不一样的,在调试器中看到它有一个类tyc-num
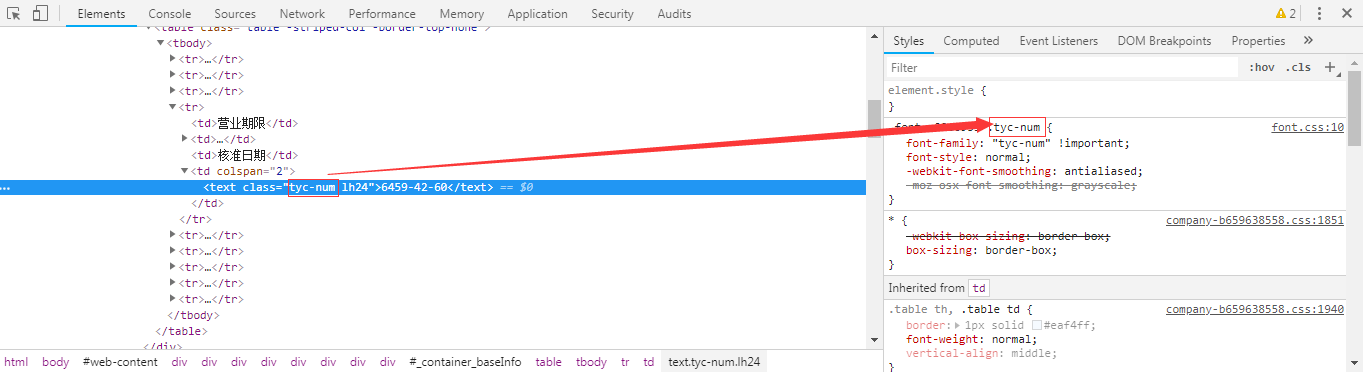
此图可以看出类tyc-num存放的是一个字体,通过network获取这个字体
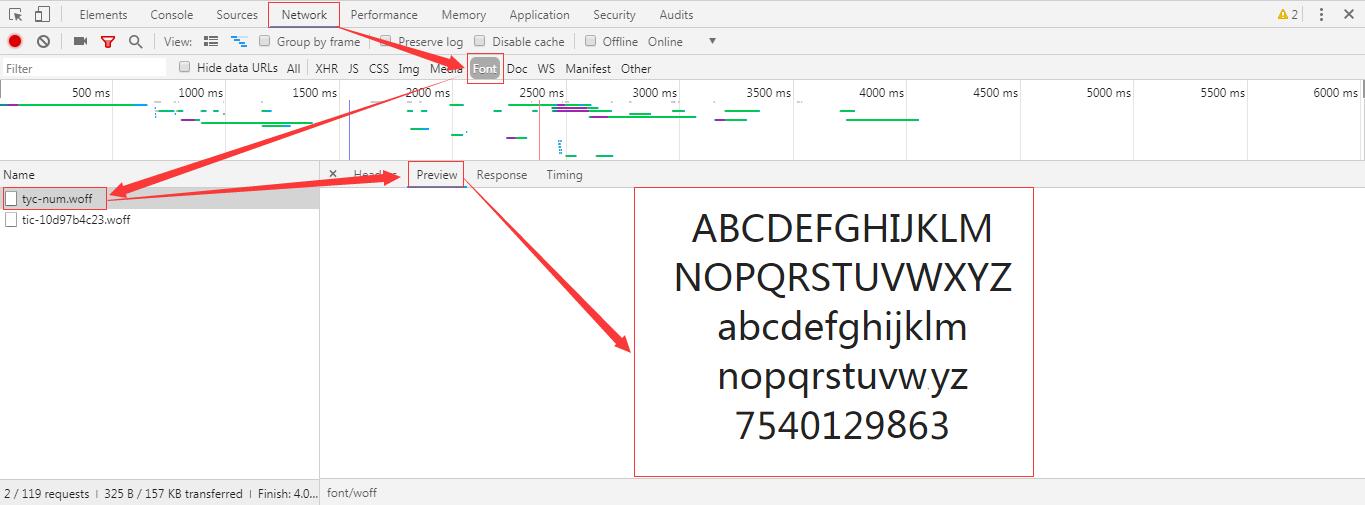
此图可以看出正常的字体数字是1234567890而现在显示的是7540129863它是顺序打乱的,把tyc-num.woff下载过来,下载过来之后发现windows是查看不了的,我用的是在线工具查看
在线工具链接:FontEditor
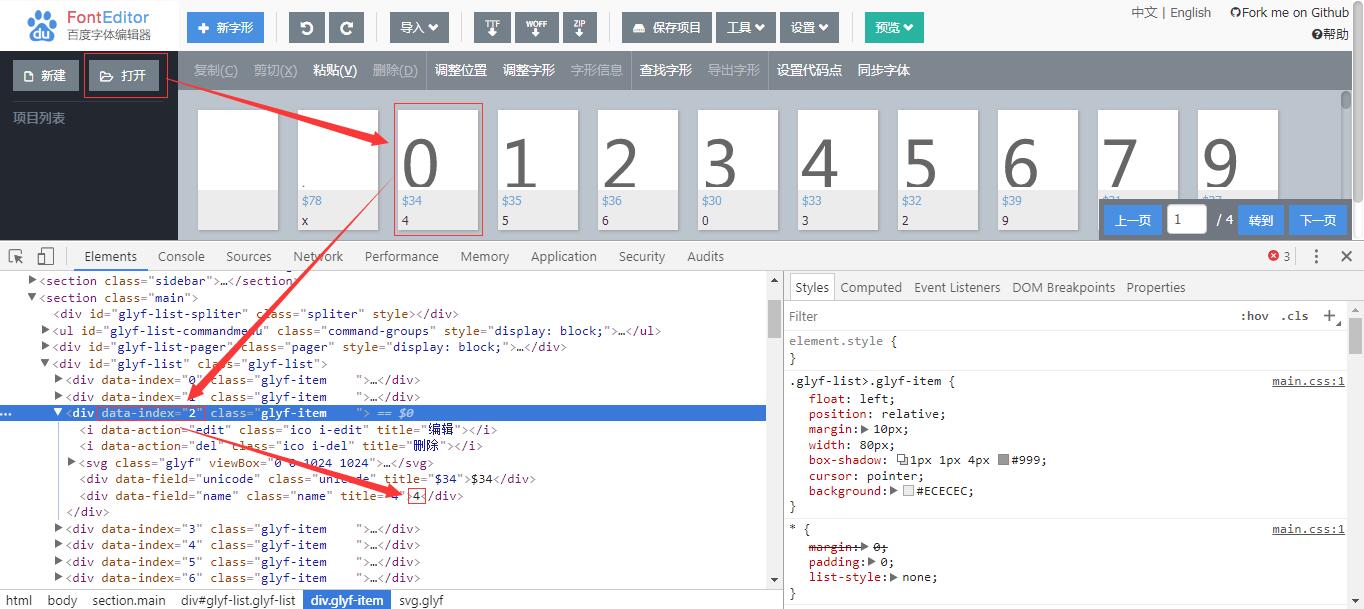
此图可以发现索引2对应的是4,说明第4个数字是0,通过Python对woff转换成xml
from fontTools.ttLib import TTFont font = TTFont('tyc-num.woff') font.saveXML('tyc-num.xml')
查看xml文件
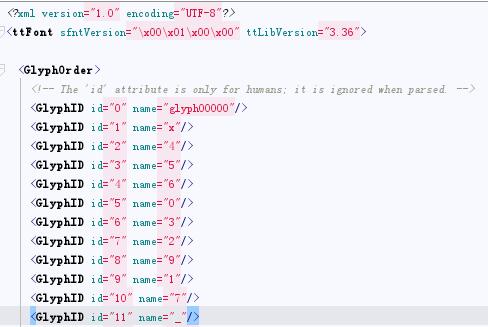
此图发现id2对应是4跟在线查看器是一样的,那就找到了对应关系
2.代码实现
安装 fontTools
pip install fontTools
上代码(代码更新2019-01-21|19:23:16) PS:发现某些公司时间还是对不上,代码更新了,上面思路是一样的
#!/usr/bin/env python # -*- coding:utf-8 -*- from fontTools.ttLib import TTFont import re font = TTFont('tyc-num.woff') # 打开tyc-num.woff font.saveXML('tyc-num.xml') # 保存为tyc-num.xml with open('tyc-num.xml', 'r') as f: xml = f.read() # 读取tyc-num.xml赋值给xml GlyphID = re.findall(r'<GlyphID id="(.*?)" name="(\d+)"/>', xml) # 获得对应关系 GlyphIDNameLists = list(set([int(Gname) for Gid, Gname in GlyphID])) # 对应关系数量转换 # print(GlyphIDNameLists) DigitalDicts = {str(i): str(GlyphIDNameLists[i - 2]) for i in range(2, len(GlyphIDNameLists)+2)} # 数字对应关系的字典推导式 # print(DigitalDicts) GlyphIDDicts = {str(Gname): DigitalDicts[Gid] for Gid, Gname in GlyphID} # 通过数字对应关系生成源代码跟页面显示的字典推导式 print('-' * 39 + '数字对应关系的字典推导式' + '-' * 39) print(DigitalDicts) print('-' * 27 + '通过数字对应关系生成源代码跟页面显示的字典推导式' + '-' * 27) print(GlyphIDDicts)
代码运行结果

作者:枪林弹雨丶
若标题中有【转载】字样,则本文版权归原作者所有。若无转载字样,
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,
且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
请注意:作者五行缺钱,如果喜欢这篇文章,请随意打赏!



 浙公网安备 33010602011771号
浙公网安备 33010602011771号