网络爬虫之Cookies解决
引言:在介绍Cookies前我们需要了解HTTP的一个特点叫做无状态。什么是无状态就是当你访问动态网站也就是需要登陆的网站时HTTP对事务处理是没有记忆能力的。就比如你想访问某个网站上个人信息的页面。直接发请求是访问不到的。必须在登陆状态下才能访问到。而Cookies里保存了登陆的凭证,有了他只需要在下次请求携带的Cookis发送请求而不需重新输入用户名,密码等登陆信息重新登陆。
如何处理Cookies呢:
手动处理:
通过抓包工具获取cookies值,将该值封装到headers中。(不推荐),因为cookie每次登陆都是动态变化的!!!
自动给处理:
创建一个session对象,使用对象进行模拟登陆(cookies就会被存储在session对象中),然后使用携带了cookies的session对象对网页发起请求就可以顺利获取到页面源码数据。
session对象的创建:
import request session = requests.Session()
下面对17汽车网中的个人信息网页进行一个爬取:
首先打开网页:https://www.17.com/user/login/
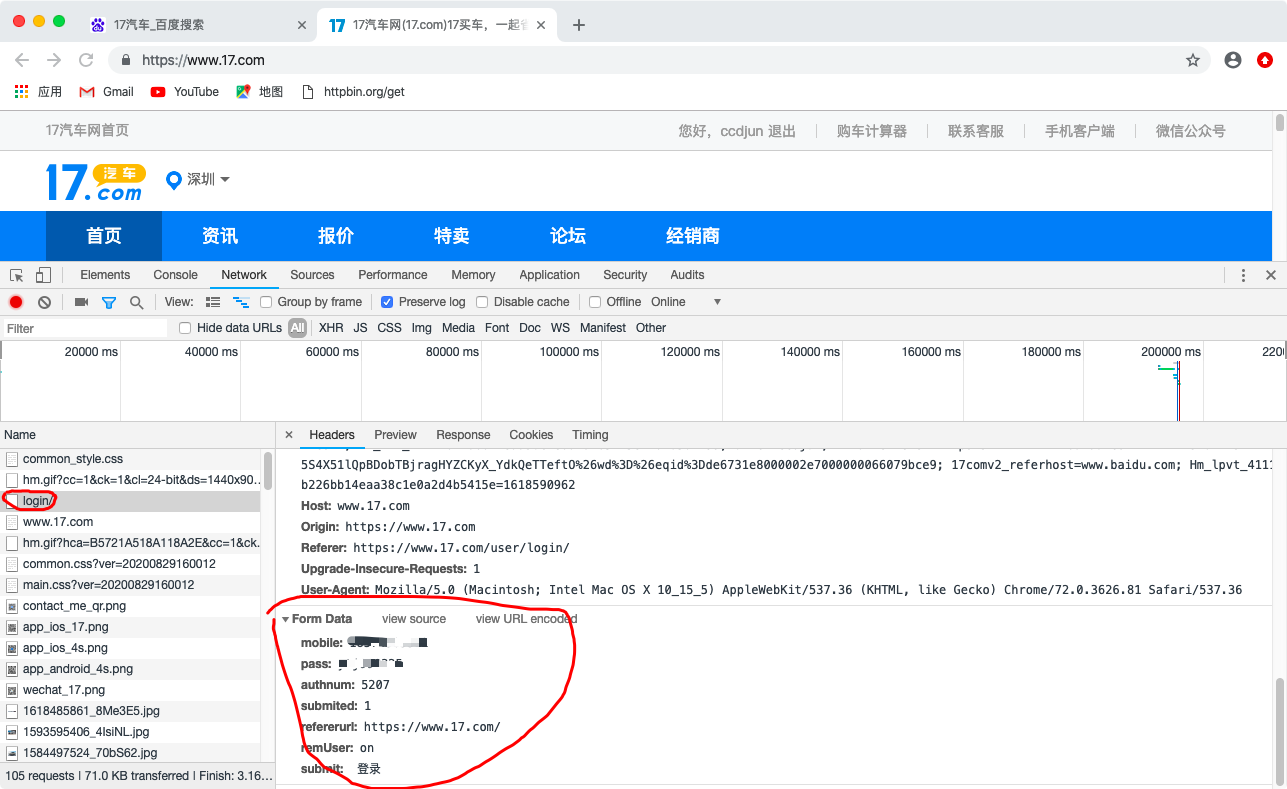
打开抓包工具勾选Preserver log按钮 然后输入账号密码登陆

登陆完成后会生成一个login/文件,请求类型是POST,From Data是携带的参数,第一个是账号,第二个是密码,这个可以直接构建。第三个是验证码需要动态获取。
整个代码逻辑应该是先模拟登陆17汽车网再对个人信息的详情页发起请求获取源码数据。其中账号密码是可以直接构建的就只有验证码是动态变化的这里我们调用打码平台解决。
整理好思路之后我们开始编写代码:
improt requests
from chaojiying import Chaojiying_Client from lxml import etree class Get_car(): headers = { 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36', } def __init__(self): self.session = requests.Session() self.path = './code.png' #验证码图片保存的路径 self.login_url = 'https://www.17.com/user/login/' #登陆页面 self.home_url = 'https://www.17.com/user/?type=my' #个人信息页面 self.codetype = 1902 #验证码类型 详情请参考超级鹰官方文档
def get_pic(self): page = self.session.get(url=self.login_url, headers=self.headers).text tree = etree.HTML(page) pic_url = 'https://www.17.com/' + tree.xpath('//*[@id="checkImg"]/@src')[0] pic = self.session.get(pic_url, headers=self.headers).content with open(self.path, mode='wb') as f: f.write(pic) chaojiying = Chaojiying_Client('username','passwd', 'id') # 超级鹰平台的账号密码以及软件id im = open(self.path, 'rb').read() # 本地图片文件路径 return chaojiying.PostPic(im,self.codetype)['pic_str'] #返回验证码 def get_data(self):
#构造POST请求的DATA参数 numb = self.get_pic() data = { 'mobile': 'username', #17汽车网账号 'pass': 'passwd', #17汽车网密码 'authnum': numb, #动态获取的验证码 'submited': '1', 'refererurl': '', 'remUser': 'on', 'submit': ' 登录', } return data def login(self):
#使用构造好的Data参数,进行POST请求发送 data = self.get_data() log_page = self.session.post(url=self.login_url,headers=self.headers, data=data).text with open('./login.html', mode='w', encoding='utf-8') as f: f.write(log_page) def get_home(self):
#登陆之后对个人信息页面源码获取并保存下来 home_page = self.session.get(url=self.home_url, headers=self.headers).text with open('./17汽车.html', mode='w',encoding='utf-8') as f: f.write(home_page) login = Get_car() login.get_pic() login.get_data() login.login() login.get_home()
这里构建了一个类,里面构造了获取验证码,构造data参数,模拟登陆,对个人信息页面爬取的四个方法。然后是实例化这个类并依次调用这四个方法。
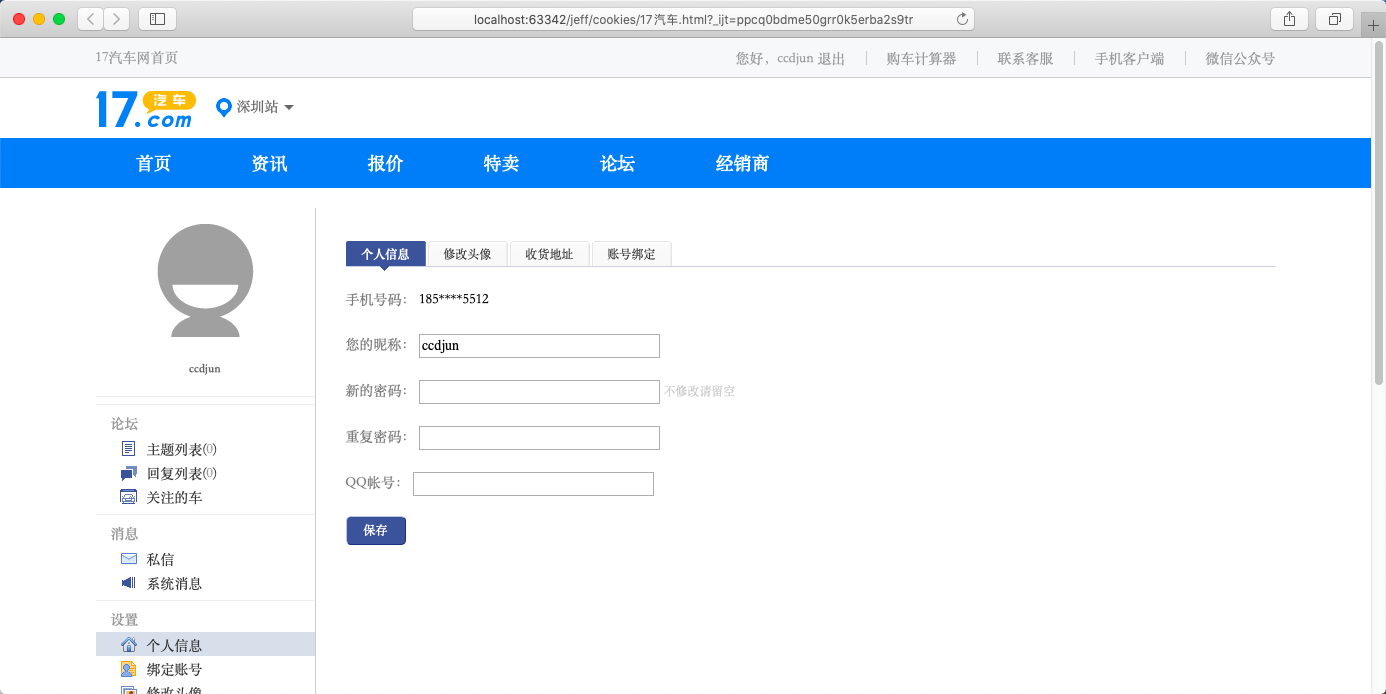
验证:
打开保存下来的17汽车.html文档并用浏览器对其访问
结果如下:
总结:
对于Cookie起到的就是一个验证用户的一个作用,我们只需将Cookie动态保存下来就可以保持登陆的状态从而达到对爬取需要验证登陆信息的页面。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号